FlowTime: Towards Continuous Generative Watch Time Prediction via Flow-based Personalized Priors
Pith reviewed 2026-06-28 17:08 UTC · model grok-4.3
The pith
FlowTime uses flow-based personalized priors for continuous generative watch time prediction in recommender systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
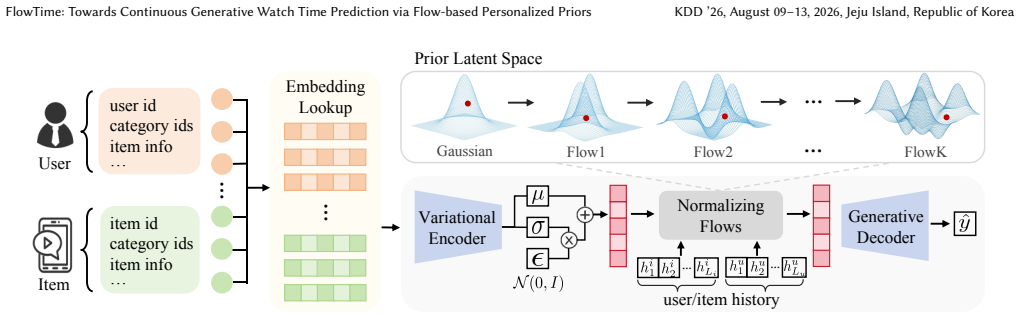
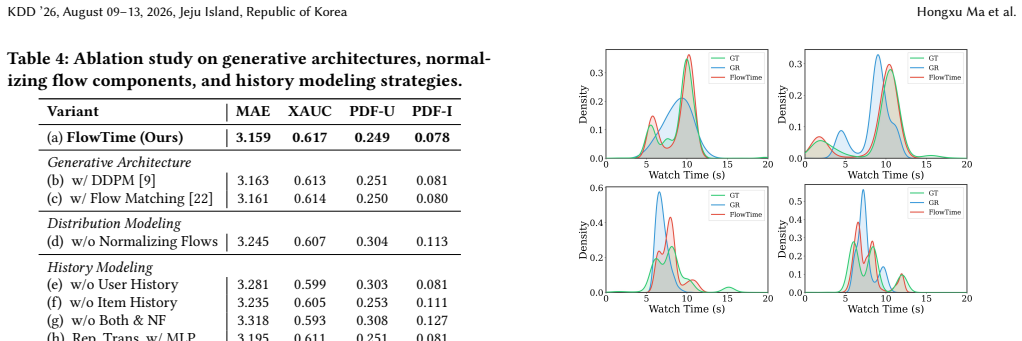
FlowTime shows that a continuous generative approach to watch time prediction, powered by a flow-based personalized prior in a one-step VAE, can capture the multimodal and heterogeneous user-item interaction patterns that serve as structural confounders, overcoming the mean-collapse of direct regression, quantization of ordinal methods, and latency of discrete generative methods.
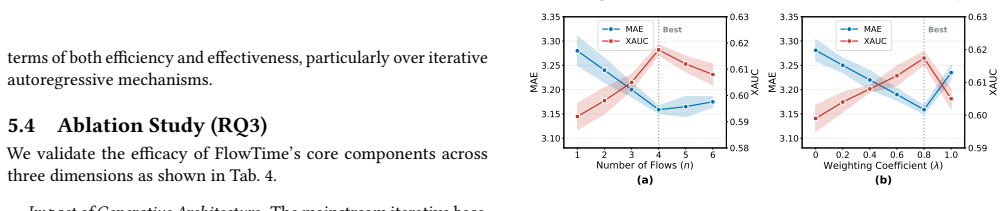
What carries the argument
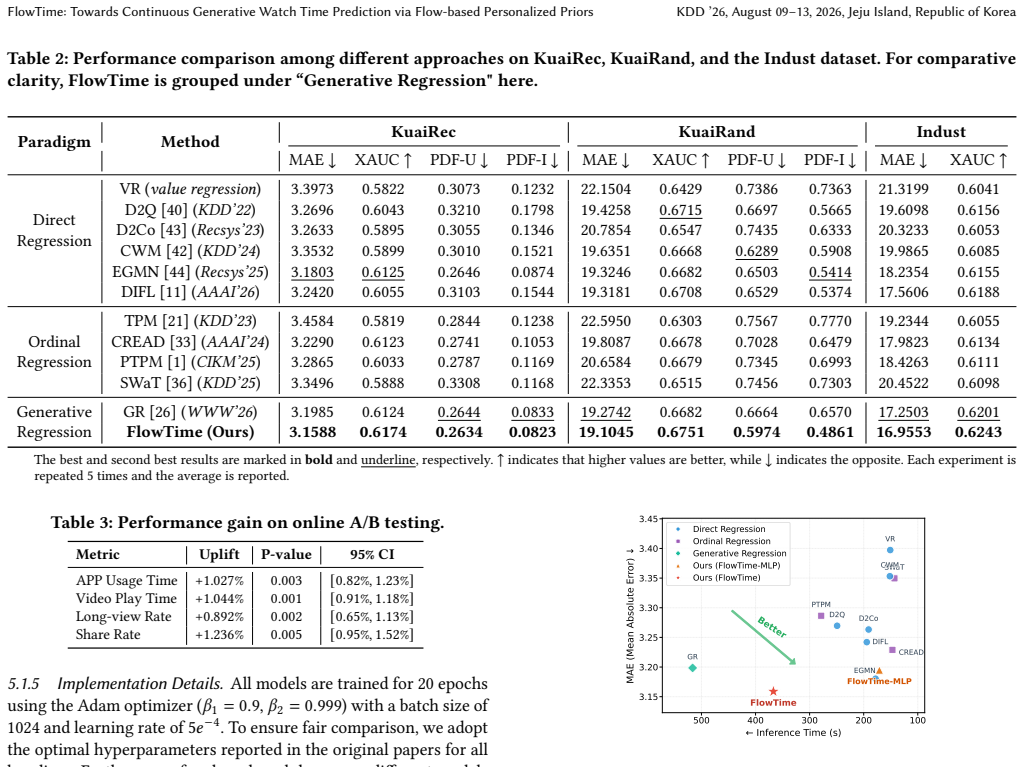
The Flow-based Personalized Prior that leverages normalizing flows to warp a standard Gaussian prior into a complex, history-conditioned manifold for adaptive modeling of multimodal interaction patterns.
If this is right
- Recommenders can generate watch time samples from multimodal distributions instead of relying on unimodal or discretized approximations.
- The one-step generative process achieves lower inference latency than methods requiring iterative denoising.
- Explicit modeling of structural confounders explains why identical interests yield different watch times across users.
- TimeRec library and the new personalization metric enable consistent benchmarking of watch time prediction methods.
- Online A/B tests confirm significant improvements over state-of-the-art methods in real-world deployment.
Where Pith is reading between the lines
- Similar flow-based conditioning could be applied to predict other time-based metrics such as total session length.
- The causal perspective on confounders opens the door to integrating causal inference techniques for fairness in recommendations.
- Extending the continuous generative paradigm to sequential recommendation tasks might improve modeling of evolving user preferences.
Load-bearing premise
The flow-based personalized prior successfully encodes the structural confounders from user interaction patterns without creating additional modeling errors that undermine the watch time predictions.
What would settle it
Demonstrating that an ablation removing the flow component and using a fixed Gaussian prior results in no performance gain or even degradation on the watch time prediction task would falsify the central claim.
Figures
read the original abstract
Watch time has emerged as a pivotal metric for optimizing deep user engagement in short-video recommender systems. However, current methods of watch time prediction (WTP) suffer from inherent paradigm-specific limitations. Direct Regression faces mean-collapse due to unimodal Gaussian assumptions, while Ordinal Regression is hampered by quantization errors from rigid discretization. Similarly, Discrete Generative Regression struggles with high inference latency and heuristic vocabulary design. Beyond these specific flaws, a shared deficiency is the inability to capture the intrinsic multimodality and heterogeneity of User-Item Interaction Patterns. To address these challenges, we first revisit the WTP problem from a causal perspective and identify these user-specific patterns as structural confounders that modulate watch time outcomes, where identical interests manifest as distinct watch time outcomes conditioned on diverse user habits. Then, we formally propose a new (or the fourth) paradigm -- Continuous Generative Regression, and introduce FlowTime, a novel method utilizing a One-step Generative Variational Autoencoder. FlowTime effectively circumvents the latency of iterative denoising while maintaining the expressivity of continuous latent spaces. Furthermore, we design a Flow-based Personalized Prior that leverages NFs to warp a standard Gaussian prior into a complex, history-conditioned manifold, thereby enabling the adaptive modeling of multimodal interaction patterns. Finally, we build TimeRec, the first open-source WTP Library, alongside a novel personalization metric to establish a rigorous benchmarking standard. Extensive offline experiments and online A/B tests demonstrate FlowTime's significant superiority over SOTA methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Continuous Generative Regression as a new paradigm for watch time prediction (WTP) in short-video recommenders. It introduces FlowTime, which uses a one-step generative VAE with a flow-based personalized prior (via normalizing flows) to model multimodal, history-conditioned user-item interaction patterns as structural confounders. The work also releases the TimeRec open-source library and a personalization metric, claiming significant superiority over SOTA methods via offline experiments and online A/B tests.
Significance. If the superiority claims hold with proper controls, the work would advance WTP by addressing mean-collapse, quantization, and latency issues while providing an open benchmarking resource (TimeRec). The causal framing of user patterns as confounders and the one-step generative approach are conceptually coherent extensions of existing generative regression ideas.
major comments (2)
- [Abstract] Abstract: The central claim of 'significant superiority' over SOTA methods rests entirely on assertions of 'extensive offline experiments and online A/B tests' without any reported metrics, error bars, dataset sizes, ablation results, or statistical significance tests. This absence makes the primary empirical contribution impossible to evaluate.
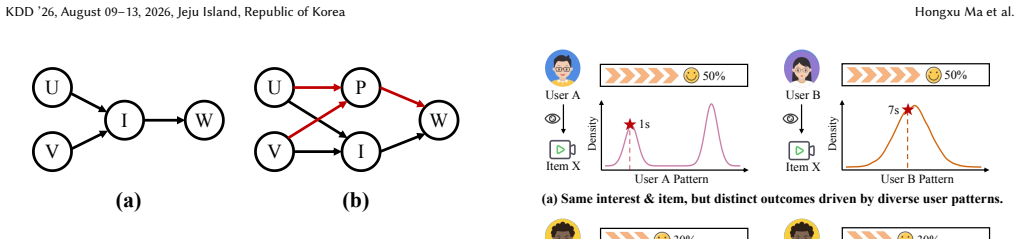
- [Abstract] The flow-based personalized prior is presented as capturing structural confounders without introducing fitting artifacts, but no derivation or analysis shows how the NF warping avoids confounding the watch-time outcome distribution with the learned history conditioning (e.g., no discussion of identifiability or sensitivity to flow architecture choices).
minor comments (1)
- [Abstract] The abstract introduces 'Continuous Generative Regression' as 'the fourth' paradigm but does not explicitly contrast it with the three prior paradigms beyond high-level limitations.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address the major points below, clarifying the location of empirical details and committing to added analysis where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'significant superiority' over SOTA methods rests entirely on assertions of 'extensive offline experiments and online A/B tests' without any reported metrics, error bars, dataset sizes, ablation results, or statistical significance tests. This absence makes the primary empirical contribution impossible to evaluate.
Authors: The abstract is a concise summary; the full manuscript reports all requested details (metrics with error bars, dataset sizes, ablations, and significance tests) in Sections 5 (offline) and 6 (online A/B). To improve evaluability from the abstract alone, we will revise it to include the primary quantitative gains. revision: yes
-
Referee: [Abstract] The flow-based personalized prior is presented as capturing structural confounders without introducing fitting artifacts, but no derivation or analysis shows how the NF warping avoids confounding the watch-time outcome distribution with the learned history conditioning (e.g., no discussion of identifiability or sensitivity to flow architecture choices).
Authors: Section 3.3 derives the NF-based prior as a history-conditioned transformation of the base Gaussian that leaves the conditional watch-time likelihood unchanged. We agree that explicit identifiability arguments and architecture sensitivity analysis are absent and will add both a short theoretical note and empirical sensitivity results in the revision. revision: partial
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description present FlowTime as a novel method within a proposed Continuous Generative Regression paradigm, using standard flow-based priors and one-step VAE components to model multimodal user patterns. No equations, self-citations, or derivation steps are shown that reduce predictions or uniqueness claims to fitted inputs by construction, self-definitional loops, or load-bearing prior author work. The central performance claims rest on offline and online experiments, which are presented as independent validation rather than tautological re-expressions of the model inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Xiaokai Chen, Xiao Lin, Changcheng Li, and Peng Jiang. 2025. Personalized Tree-Based Progressive Regression Model for Watch-Time Prediction in Short Video Recommendation. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5609–5616
2025
-
[2]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. InProceedings of the 10th ACM conference on recommender systems. 191–198
2016
-
[3]
James Davidson, Benjamin Liebald, Junning Liu, Palash Nandy, Taylor Van Vleet, Ullas Gargi, Sujoy Gupta, Yu He, Mike Lambert, Blake Livingston, et al . 2010. The YouTube video recommendation system. InProceedings of the fourth ACM conference on Recommender systems. 293–296
2010
-
[4]
Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. 2017. Density estimation using Real NVP. InInternational Conference on Learning Representations. https: //openreview.net/forum?id=HkpbnH9lx
2017
-
[5]
Chongming Gao, Shijun Li, Wenqiang Lei, Jiawei Chen, Biao Li, Peng Jiang, Xiangnan He, Jiaxin Mao, and Tat-Seng Chua. 2022. KuaiRec: A fully-observed dataset and insights for evaluating recommender systems. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. 540–550
2022
-
[6]
Chongming Gao, Shijun Li, Yuan Zhang, Jiawei Chen, Biao Li, Wenqiang Lei, Peng Jiang, and Xiangnan He. 2022. Kuairand: An unbiased sequential recom- mendation dataset with randomly exposed videos. InProceedings of the 31st ACM international conference on information & knowledge management. 3953–3957
2022
-
[7]
Xudong Gong, Qinlin Feng, Yuan Zhang, Jiangling Qin, Weijie Ding, Biao Li, Peng Jiang, and Kun Gai. 2022. Real-time short video recommendation on mobile devices. InProceedings of the 31st ACM international conference on information & knowledge management. 3103–3112
2022
-
[8]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk
-
[9]
Session-based recommendations with recurrent neural networks.arXiv preprint arXiv:1511.06939(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems33 (2020), 6840–6851
2020
-
[11]
Peter J Huber. 1992. Robust estimation of a location parameter. InBreakthroughs in statistics: Methodology and distribution. Springer, 492–518
1992
-
[12]
Chenghou Jin, Yixin Ren, Hongxu Ma, Yewei Xia, Yi Guan, Hao Zhang, Jiandong Ding, Jihong Guan, and Shuigeng Zhou. 2026. Invariant Feature Learning for Counterfactual Watch-time Prediction in Video Recommendation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 14964–14972
2026
-
[13]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[15]
Diederik P Kingma and Max Welling. 2013. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114(2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[16]
Diederik P Kingma, Max Welling, et al . 2019. An introduction to variational autoencoders.Foundations and Trends®in Machine Learning12, 4 (2019), 307–392
2019
- [17]
-
[18]
Qizhen Lan and Qing Tian. 2025. ACAM-KD: adaptive and cooperative attention masking for knowledge distillation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 3957–3966
2025
-
[19]
Wuchao Li, Rui Huang, Haijun Zhao, Chi Liu, Kai Zheng, Qi Liu, Na Mou, Guorui Zhou, Defu Lian, Yang Song, et al . 2025. DimeRec: a unified framework for enhanced sequential recommendation via generative diffusion models. InPro- ceedings of the Eighteenth ACM International Conference on Web Search and Data Mining. 726–734
2025
-
[20]
Zihao Li, Aixin Sun, and Chenliang Li. 2023. Diffurec: A diffusion model for sequential recommendation.ACM Transactions on Information Systems42, 3 (2023), 1–28
2023
-
[21]
Dawen Liang, Rahul G Krishnan, Matthew D Hoffman, and Tony Jebara. 2018. Variational autoencoders for collaborative filtering. InProceedings of the 2018 world wide web conference. 689–698
2018
-
[22]
Xiao Lin, Xiaokai Chen, Linfeng Song, Jingwei Liu, Biao Li, and Peng Jiang
-
[23]
InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Tree based progressive regression model for watch-time prediction in short-video recommendation. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4497–4506
-
[24]
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le
-
[25]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [26]
-
[27]
Shang Liu, Zhenzhong Chen, Hongyi Liu, and Xinghai Hu. 2019. User-video co- attention network for personalized micro-video recommendation. InThe world wide web conference. 3020–3026
2019
-
[28]
Yiyu Liu, Qian Liu, Yu Tian, Changping Wang, Yanan Niu, Yang Song, and Chenliang Li. 2021. Concept-aware denoising graph neural network for micro- video recommendation. InProceedings of the 30th ACM international conference on information & knowledge management. 1099–1108
2021
- [29]
-
[30]
Hongxu Ma, Guanshuo Wang, Fufu Yu, Qiong Jia, and Shouhong Ding. 2025. Ms-detr: Towards effective video moment retrieval and highlight detection by joint motion-semantic learning. InProceedings of the 33rd ACM International Conference on Multimedia. 4514–4523
2025
-
[31]
Hongxu Ma, Chenbo Zhang, Lu Zhang, Jiaogen Zhou, Jihong Guan, and Shuigeng Zhou. 2025. Fine-grained zero-shot object detection. InProceedings of the 33rd ACM International Conference on Multimedia. 4504–4513
2025
-
[32]
Hongxu Ma, Han Zhou, Kai Tian, Xuefeng Zhang, Chunjie Chen, Han Li, Jihong Guan, and Shuigeng Zhou. 2026. GoR: A Unified and Extensible Generative Framework for Ordinal Regression. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=ys80cc2N5M
2026
-
[33]
George Papamakarios, Eric Nalisnick, Danilo Jimenez Rezende, Shakir Mohamed, and Balaji Lakshminarayanan. 2021. Normalizing flows for probabilistic modeling and inference.J. Mach. Learn. Res.22, 1, Article 57 (Jan. 2021), 64 pages
2021
-
[34]
Danilo Rezende and Shakir Mohamed. 2015. Variational inference with normaliz- ing flows. InInternational conference on machine learning. PMLR, 1530–1538
2015
-
[35]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[36]
InProceedings of the 28th ACM international conference on information and knowledge management
BERT4Rec: Sequential recommendation with bidirectional encoder rep- resentations from transformer. InProceedings of the 28th ACM international conference on information and knowledge management. 1441–1450
-
[37]
Jie Sun, Zhaoying Ding, Xiaoshuang Chen, Qi Chen, Yincheng Wang, Kaiqiao Zhan, and Ben Wang. 2024. CREAD: A Classification-Restoration Framework with Error Adaptive Discretization for Watch Time Prediction in Video Recom- mender Systems. InProceedings of the AAAI Conference on Artificial Intelligence
2024
-
[38]
Siqi Wu, Marian-Andrei Rizoiu, and Lexing Xie. 2018. Beyond views: Measuring and predicting engagement in online videos. InProceedings of the International AAAI Conference on Web and Social Media, Vol. 12
2018
-
[39]
Tingyu Wu, Zhisheng Chen, Ziyan Weng, Shuhe Wang, Chenglong Li, Shuo Zhang, Sen Hu, Silin Wu, Qizhen Lan, Huacan Wang, et al. 2026. KnowMe-Bench: Benchmarking Person Understanding for Lifelong Digital Companions.arXiv preprint arXiv:2601.04745(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Shentao Yang, Haichuan Yang, Linna Du, Adithya Ganesh, and et al. 2024. SWaT: Statistical Modeling of Video Watch Time through User Behavior Analysis.arXiv preprint arXiv:2408.07759(2024). doi:10.48550/arXiv.2408.07759
-
[41]
Zhengyi Yang, Jiancan Wu, Zhicai Wang, Xiang Wang, Yancheng Yuan, and Xiangnan He. 2023. Generate what you prefer: Reshaping sequential recommen- dation via guided diffusion.Advances in Neural Information Processing Systems 36 (2023), 24247–24261
2023
-
[42]
Xing Yi, Liangjie Hong, Erheng Zhong, Nanthan Nan Liu, and Suju Rajan. 2014. Beyond clicks: dwell time for personalization. InProceedings of the 8th ACM Conference on Recommender systems. 113–120
2014
-
[43]
Yuanqing Yu, Chongming Gao, Jiawei Chen, Heng Tang, Yuefeng Sun, Qian Chen, Weizhi Ma, and Min Zhang. 2024. EasyRL4Rec: An Easy-to-use Library for Reinforcement Learning Based Recommender Systems.arXiv e-prints, Article arXiv:2402.15164 (Feb. 2024), arXiv:2402.15164 pages. arXiv:2402.15164 [cs.IR] doi:10.48550/arXiv.2402.15164
-
[44]
Ruohan Zhan, Changhua Pei, Qiang Su, Jianfeng Wen, Xueliang Wang, Guanyu Mu, Dong Zheng, Peng Jiang, and Kun Gai. 2022. Deconfounding duration bias in watch-time prediction for video recommendation. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4472–4481
2022
-
[45]
Chenbo Zhang, Bing Huangfu, Hongxu Ma, Jihong Guan, and Shuigeng Zhou
-
[46]
InProceedings of the 33rd ACM International Conference on Multimedia
Multi-modal Prototype Guided Few-shot Object Detection. InProceedings of the 33rd ACM International Conference on Multimedia. 1852–1861
-
[47]
Haiyuan Zhao, Guohao Cai, Jieming Zhu, Zhenhua Dong, Jun Xu, and Ji-Rong Wen. 2024. Counteracting Duration Bias in Video Recommendation via Coun- terfactual Watch Time. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4455–4466
2024
-
[48]
Haiyuan Zhao, Lei Zhang, Jun Xu, Guohao Cai, Zhenhua Dong, and Ji-Rong Wen. 2023. Uncovering user interest from biased and noised watch time in video recommendation. InProceedings of the 17th ACM Conference on Recommender Systems. 528–539. KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Hongxu Ma et al
2023
-
[49]
Xu Zhao, Ruibo Ma, Jiaqi Chen, Weiqi Zhao, Ping Yang, and Yao Hu. 2025. Multi-Granularity Distribution Modeling for Video Watch Time Prediction via Exponential-Gaussian Mixture Network. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 309–318
2025
-
[50]
Lijing Zhu, Qizhen Lan, Qing Tian, Wenbo Sun, Li Yang, Lu Xia, Yixin Xie, Xi Xiao, Tiehang Duan, Cui Tao, et al. 2025. ETT-CKGE: Efficient Task-Driven Tokens for Continual Knowledge Graph Embedding. InJoint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 481–496. A Theoretical Proofs A.1 Limitations in Ordinal Regre...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.