Differentially Private Datastore Generation for Retrieval-Augmented Inference
Pith reviewed 2026-06-28 16:37 UTC · model grok-4.3
The pith
A locality-sensitive hashing framework with added differential privacy noise releases datastores for retrieval-augmented inference while limiting average accuracy loss to 2.6 percent at epsilon equals 5.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors introduce a hashing-based probability generation framework that employs locality-sensitive hashing to efficiently partition high-dimensional data into buckets, adds calibrated differential privacy noise to the accumulated vote for each bucket, and generates a probability distribution across classes from the noised counts. This framework supports the creation and release of differentially private datastores and applies to any pipeline that requires secure key-value datastore creation and release.
What carries the argument
Locality-sensitive hashing partitions high-dimensional data into buckets whose vote counts receive calibrated differential privacy noise to produce class probability distributions.
If this is right
- At epsilon equals 5 the released DP datastore achieves strong privacy protection with only an average 2.6 percent drop in accuracy across seven datasets with 2 to 14 classes.
- The DP datastore reduces membership inference attack accuracy to 53.60 percent.
- The framework applies to any pipeline requiring secure key-value datastore creation and release.
- The approach works on datasets with varying sample sizes and class counts ranging from 2 to 14.
Where Pith is reading between the lines
- If bucket vote counts remain useful after noise addition without per-dataset tuning, the same structure could support privacy-preserving retrieval in additional high-dimensional domains such as image or sensor data.
- The reported attack resilience at a single epsilon value suggests the method could be combined with other privacy tools to reach stricter protection levels.
- Verification on datasets with class counts outside the tested range of 2 to 14 would clarify how broadly the accuracy preservation holds.
Load-bearing premise
Locality-sensitive hashing produces buckets whose vote counts can be noised with standard differential privacy mechanisms while preserving downstream retrieval utility across arbitrary high-dimensional datasets without additional dataset-specific tuning.
What would settle it
Running the method on an unseen high-dimensional dataset and observing either an accuracy drop substantially larger than 2.6 percent at epsilon equals 5 or a membership inference attack accuracy well above 53.60 percent would show the general claim does not hold.
Figures
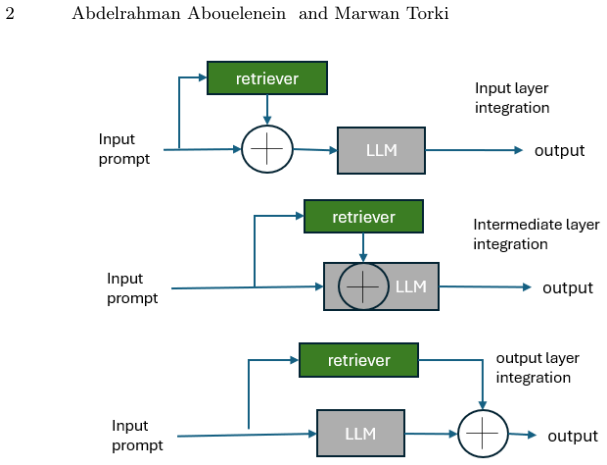
read the original abstract
It is crucial for modern on-device AI systems that rely on retrieval-augmented inference to release and share datastores without compromising individual privacy. This can be achieved using Differential Privacy (DP), which provides a formal guarantee that ensures individual contributions remain indistinguishable, even under adversarial analysis. In this paper, we introduce a hashing-based probability generation framework designed to enable the creation and release of differentially private datastores. Our approach employs locality-sensitive hashing (LSH) to efficiently partition high-dimensional data into buckets. We then add calibrated DP noise to the accumulated vote for each bucket, generating a probability distribution across classes. Our method is broadly applicable to any pipeline requiring secure key,value datastore creation and release. We conducted experiments on seven datasets with varying sample sizes and class counts, ranging from 2 to 14. At epsilon=5, our released DP datastore achieves strong privacy protection with only an average 2.6% drop in accuracy. Finally, we benchmark DP datastore resilience to membership inference attacks, reducing attack accuracy to 53.60%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a locality-sensitive hashing (LSH) framework for creating differentially private datastores: high-dimensional data is partitioned into buckets via LSH, calibrated noise is added to per-bucket class vote counts, and the resulting probability distribution over classes is released for use in retrieval-augmented inference. Experiments on seven datasets (2–14 classes) are reported to yield an average 2.6% accuracy drop at ε=5 while reducing membership-inference attack accuracy to 53.60%. The method is presented as broadly applicable to any secure key-value datastore pipeline.
Significance. If reproducible and generalizable without per-dataset LSH tuning, the approach would offer a lightweight, standard-DP mechanism for private datastore release in on-device retrieval-augmented systems. The use of LSH for efficient bucketing followed by vote noising is a reasonable design choice that could be adopted if the utility bound holds across arbitrary high-dimensional distributions.
major comments (2)
- [Abstract] Abstract: the headline claims (2.6% average accuracy drop at ε=5; MIA accuracy 53.60%) are stated without any description of LSH parameters (number of hashes, tables, or bucket width), noise mechanism (Laplace/Gaussian scale, sensitivity calculation), calibration procedure, or statistical tests/error bars. This directly prevents verification of the reported figures and is load-bearing for the central empirical claim.
- [Abstract] Abstract: the assertion that the method is 'broadly applicable to any pipeline requiring secure key,value datastore creation' rests on the unexamined assumption that untuned LSH buckets yield vote counts whose sensitivity is bounded and whose noisy probabilities preserve downstream utility on arbitrary high-dimensional data. No evidence or discussion addresses the known dependence of LSH collision probabilities on data distribution and hash-family parameters, which is the precise point raised by the stress-test concern.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the abstract requires additional technical details to allow verification of the reported results and will revise it accordingly. We also agree to strengthen the discussion of LSH assumptions for the broad-applicability claim.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims (2.6% average accuracy drop at ε=5; MIA accuracy 53.60%) are stated without any description of LSH parameters (number of hashes, tables, or bucket width), noise mechanism (Laplace/Gaussian scale, sensitivity calculation), calibration procedure, or statistical tests/error bars. This directly prevents verification of the reported figures and is load-bearing for the central empirical claim.
Authors: We agree that the abstract must be self-contained for the central claims. In the revised version we will add a concise clause specifying the LSH configuration (number of hash functions, tables, and bucket width), the noise mechanism (Laplace noise scaled to the sensitivity of per-bucket vote counts), the calibration procedure, and that error bars reflect standard deviation over repeated trials. These parameters are already fixed and reported in the experimental setup; the revision will simply surface them in the abstract. revision: yes
-
Referee: [Abstract] Abstract: the assertion that the method is 'broadly applicable to any pipeline requiring secure key,value datastore creation' rests on the unexamined assumption that untuned LSH buckets yield vote counts whose sensitivity is bounded and whose noisy probabilities preserve downstream utility on arbitrary high-dimensional data. No evidence or discussion addresses the known dependence of LSH collision probabilities on data distribution and hash-family parameters, which is the precise point raised by the stress-test concern.
Authors: Our experiments cover seven datasets that vary in dimensionality, sample size, and number of classes (2–14), providing empirical support for utility preservation under the chosen LSH parameters. Nevertheless, we accept that an explicit discussion of LSH collision-probability dependence on data distribution is warranted. We will add a short paragraph in the Discussion section that (i) recalls the standard LSH collision bounds, (ii) states the parameter-selection heuristic used, and (iii) notes the empirical stability observed across the tested distributions. The broad-applicability phrasing will be qualified to reflect this scope. revision: partial
Circularity Check
No circularity; empirical method with no derivations or self-referential predictions
full rationale
The paper describes an LSH-based bucketing approach followed by addition of calibrated DP noise to per-bucket vote counts, then evaluates the resulting datastore empirically on seven classification datasets. No equations, derivations, or 'predictions' appear in the provided text. The reported 2.6% accuracy drop and MIA numbers are direct experimental outcomes rather than quantities forced by construction from fitted parameters or self-citations. The central claim therefore rests on external benchmarks and does not reduce to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In:IEEE Symposium on Security and Privacy (S&P), pp
Shokri, R., Stronati, M., Song, C., Shmatikov, V.: Membership Inference Attacks Against Machine Learning Models. In:IEEE Symposium on Security and Privacy (S&P), pp. 3–18 (2017)
2017
-
[2]
In:ICLR(2024)
Tang, X., Shin, R., Inan, H.A., Manoel, A., Mireshghallah, F., Lin, Z., Gopi, S., et al.: Privacy-Preserving In-Context Learning with Differentially Private Few-Shot Generation. In:ICLR(2024)
2024
-
[3]
In:ICLR(2020)
Khandelwal, U., Levy, O., Jurafsky, D., Zettlemoyer, L., Lewis, M.: Generalization through Memorization: Nearest Neighbor Language Models. In:ICLR(2020)
2020
-
[4]
In:ICLR(2024)
Wu, T., Panda, A., Wang, J.T., Mittal, P.: Privacy-Preserving In-Context Learning for Large Language Models. In:ICLR(2024)
2024
-
[5]
In:NeurIPS, vol
Zhang, X., Zhao, J., LeCun, Y.: Character-level Convolutional Networks for Text Classification. In:NeurIPS, vol. 28 (2015)
2015
-
[6]
Hu, M., Liu, B.: Mining and Summarizing Customer Reviews. In:Proc. ACM SIGKDD, pp. 168–177 (2004)
2004
-
[7]
In: Proc
Voorhees, E.M., Tice, D.M.: Building a Question Answering Test Collection. In: Proc. ACM SIGIR, pp. 200–207 (2000)
2000
-
[8]
Pang, B., Lee, L.: Seeing Stars: Exploiting Class Relationships for Sentiment Cat- egorization with Respect to Rating Scales. In:Proc. ACL, pp. 115–124 (2005)
2005
-
[9]
Pang, B., Lee, L.: A Sentimental Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts. In:Proc. ACL, pp. 271–278 (2004)
2004
-
[10]
In:CVPR, pp
Zhu, Y., Yu, X., Chandraker, M., Wang, Y.-X.: Private-kNN: Practical Differential Privacy for Computer Vision. In:CVPR, pp. 11851–11859 (2020)
2020
-
[11]
In:ICLR(2023)
Xu, B., Xie, Y., Gu, Z., Zhu, K., Peng, S.: kNN Prompting: Beyond-Context Learn- ing with Calibration-Free Nearest Neighbor Inference. In:ICLR(2023)
2023
-
[12]
arXiv preprint arXiv:2302.12188 (2023)
Dai, Y., Zhang, Z., Liu, Q., Cui, Q., Li, W., Du, Y., Xu, T.: Simple and Scalable Nearest Neighbor Machine Translation. arXiv preprint arXiv:2302.12188 (2023)
-
[13]
In:ICLR(2021)
Khandelwal, U., Fan, A., Jurafsky, D., Zettlemoyer, L., Lewis, M.: Nearest Neigh- bor Machine Translation. In:ICLR(2021)
2021
-
[14]
165–210 (2005)
Wiebe, J., Wilson, T., Cardie, C.: Annotating Expressions of Opinions and Emo- tions in Language.Language Resources and Evaluation, 39(2–3), pp. 165–210 (2005)
2005
-
[15]
In:NeurIPS, pp
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., et al.: Language Models are Few-Shot Learners. In:NeurIPS, pp. 1877–1901 (2020) 14 Abdelrahman Abouelenein and Marwan Torki
1901
-
[16]
OpenAI Technical Report (2019)
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I.: Language Models are Unsupervised Multitask Learners. OpenAI Technical Report (2019)
2019
-
[17]
In:Findings of the Association for Computational Linguis- tics, pp
Igamberdiev, T., Habernal, I.: DP-BART for Privatized Text Rewriting under Lo- cal Differential Privacy. In:Findings of the Association for Computational Linguis- tics, pp. 13914–13934 (2023)
2023
-
[18]
arXiv preprint arXiv:2303.00654 (2023)
Ponomareva, N., Kurakin, A., Chien, S., Thakurta, A., Matthews, P.: How to DP- fy ML: A Practical Guide to Machine Learning with Differential Privacy. arXiv preprint arXiv:2303.00654 (2023)
-
[19]
arXiv preprint arXiv:2503.10677 (2025)
Cheng, M., Zhao, W.X., Zhang, J., Wen, J.-R.: A Survey on Knowledge-Oriented Retrieval-Augmented Generation. arXiv preprint arXiv:2503.10677 (2025)
-
[20]
In:COLING, pp
Igamberdiev, T., Habernal, I.: DP-Rewrite: Towards Reproducibility and Trans- parency in Differentially Private Text Rewriting. In:COLING, pp. 2927–2933 (2022)
2022
-
[21]
In:ACM CCS(2016)
Abadi, M., Chu, A., Goodfellow, I., McMahan, H.B., Mironov, I., Talwar, K., Zhang, L.: Deep Learning with Differential Privacy. In:ACM CCS(2016)
2016
-
[22]
In:STOC, pp
Indyk, P., Motwani, R.: Approximate Nearest Neighbors: Toward Removing the Curse of Dimensionality. In:STOC, pp. 604–613 (1998)
1998
-
[23]
211–407 (2014)
Dwork, C., Roth, A.: The Algorithmic Foundations of Differential Privacy.Foun- dations and Trends in Theoretical Computer Science, 9(3–4), pp. 211–407 (2014)
2014
-
[24]
In:NeurIPS(2023)
Andoni, A., Dadush, D., Klein, N., Liu, K., Zhang, L.: Differentially Private Ap- proximate Near Neighbor Counting in High Dimensions. In:NeurIPS(2023)
2023
-
[25]
In:Symposium on Founda- tions of Responsible Computing(2025)
Aumüller, M., Gollapudi, S., Pagh, R., Silvestri, F.: Differentially Private High- Dimensional Approximate Range Counting, Revisited. In:Symposium on Founda- tions of Responsible Computing(2025)
2025
-
[26]
In:ACM SIGKDD(2012)
Kenthapadi, K., Korolova, A., Mironov, I., Mishra, N.: Differential Privacy with Locality-Sensitive Hashing. In:ACM SIGKDD(2012)
2012
-
[27]
In:ICALP(2011)
Chan, T.-H.H., Li, M., Shi, E., Xu, W.: Differentially Private Approximate Range Counting in High Dimensions. In:ICALP(2011)
2011
-
[28]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Abouelenin, A., Ashfaq, A., Atkinson, A., Awadalla, H., Bach, N., et al.: Phi-4- Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs. arXiv preprint arXiv:2503.01743 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
and Basin, D.: Locality-Sensitive Hashing Does Not Guarantee Privacy! Attacks on Google’s FLoC and the MinHash Hierarchy System
Turati, F., Kubicek, K., Cotrini, C. and Basin, D.: Locality-Sensitive Hashing Does Not Guarantee Privacy! Attacks on Google’s FLoC and the MinHash Hierarchy System. In:Proceedings on Privacy Enhancing Technologies, 2023(4), pp. 117–131 (2023)
2023
-
[30]
In:Proceed- ings of the 56th Annual Meeting of the Association for Computational Linguistics (Short Papers), pp
Torki, M.: A Document Descriptor using Covariance of Word Vectors. In:Proceed- ings of the 56th Annual Meeting of the Association for Computational Linguistics (Short Papers), pp. 527–532 (2018)
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.