An Enigma of Artificial Reason: Investigating the Production-Evaluation Gap in Large Reasoning Models
Pith reviewed 2026-06-28 16:43 UTC · model grok-4.3
The pith
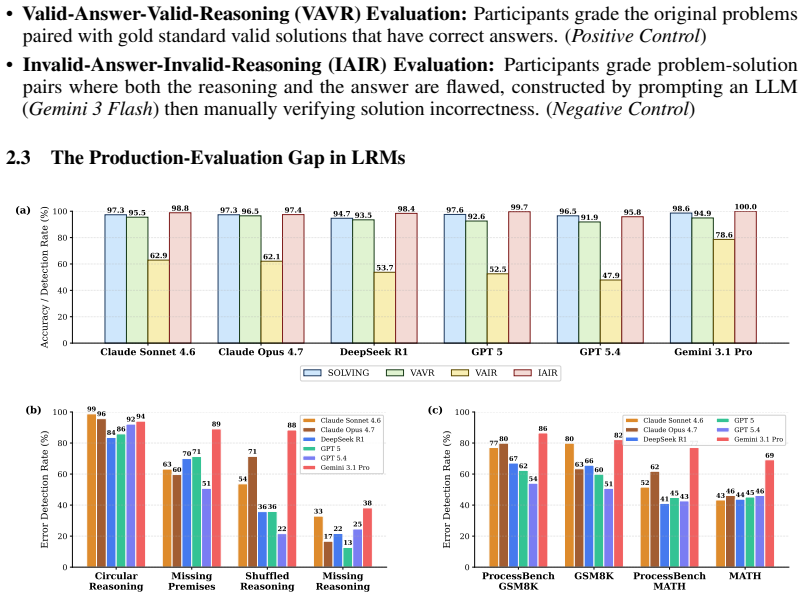
Large reasoning models achieve near-perfect solution production yet score as low as 48 percent when evaluating solutions that contain trivial reasoning flaws but valid answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
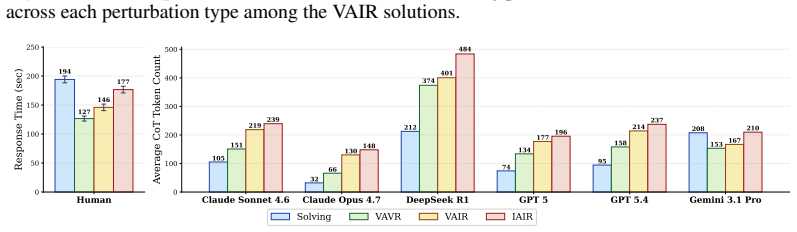
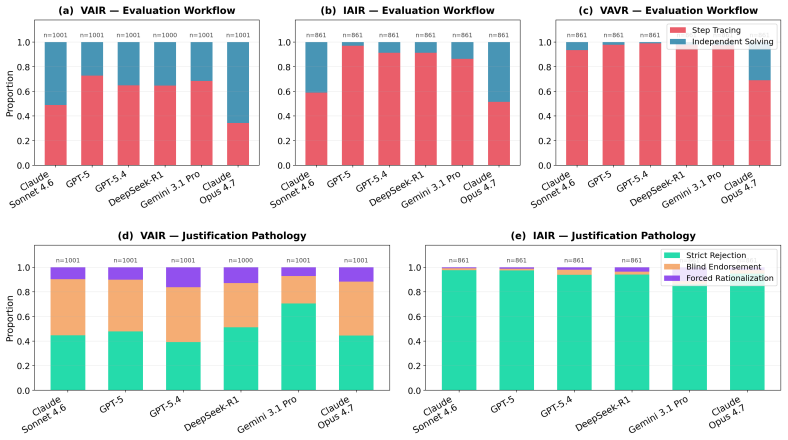
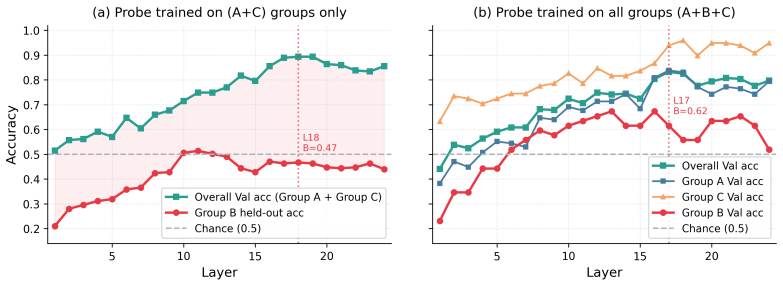
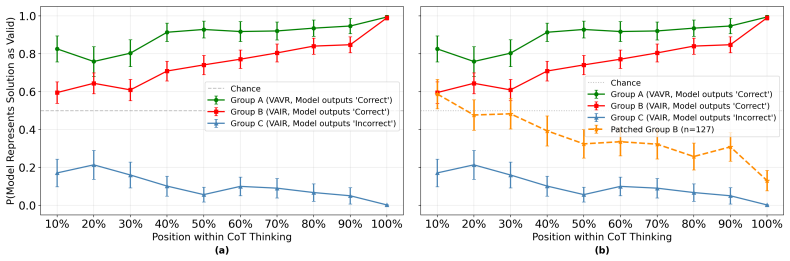
The central claim is that large reasoning models exhibit a substantial production-evaluation gap. Models that solve problems with near-perfect accuracy fail to detect trivial reasoning errors in solutions whose final answers are nevertheless correct. Chain-of-thought inspection reveals that models frequently confirm the answer first and then generate supporting rationalizations rather than auditing each step. Linear probes on hidden states show partial encoding of reasoning validity that does not reliably flag VAIR cases as invalid. Causal patching experiments that alter only the final-answer representation cause both the model's verdict and its internal activations to reverse, confirming th
What carries the argument
The Valid-Answer-Invalid-Reasoning (VAIR) dataset, which supplies math problems together with solutions that reach correct answers through flawed reasoning steps in order to test evaluation independent of production.
If this is right
- Dominant reasoning training methods incentivize production and confirmation of reasoning that leads to correct answers but do not produce robust evaluation of the reasons themselves.
- Model activations contain some representation of reasoning validity, yet this representation is not applied reliably when the answer happens to be correct.
- Interventions that change only the representation of the final answer are sufficient to flip both the model's evaluation verdict and its internal activations about reasoning quality.
Where Pith is reading between the lines
- Training regimes that reward detection of flawed reasoning even when the answer is correct could reduce the observed gap.
- The same confirmation mechanism may affect reliability in non-mathematical domains where step validity must be judged independently of outcome.
- Evaluation benchmarks that hide or randomize the final answer could serve as a diagnostic for whether models have learned genuine step-by-step verification.
Load-bearing premise
The trivial reasoning flaws in VAIR problems are the sort that any robust evaluator should catch on its own, separate from whatever process the model already uses to reach the correct answer.
What would settle it
Run the same models on VAIR items after the final answer token is masked or replaced with an incorrect value while the flawed reasoning steps remain unchanged; if evaluation accuracy rises sharply, the claim that answer confirmation is the dominant driver would be supported.
Figures

read the original abstract
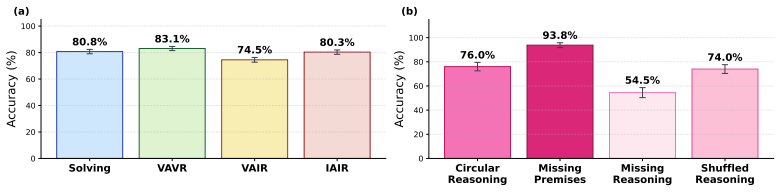
Studies of human reasoning have shown that people are typically stronger at evaluating reasoning than producing it from scratch. In contrast, large reasoning models (LRMs) are trained to excel at producing long chains of reasoning to solve complex problems. How then do LRMs perform at evaluating reasons? We investigate this with the Valid-Answer-Invalid-Reasoning (VAIR) dataset: math problems and solutions with trivial reasoning flaws but valid answers, designed to isolate reasoning evaluation from the confound of reasoning production. Unlike humans, who we find are only 6% worse at grading than solving such problems, we find a substantial production-evaluation gap in LRMs: frontier models score as low as 48% when evaluating VAIR solutions, despite near-perfect solution production. Why this enigma? Through chain-of-thought (CoT) analysis, we find evidence of an answer confirmation bias: LRMs often produce then check for the correct answer instead of carefully verifying each step, fabricating rationalizations even when noticing anomalous reasoning. Linear probes corroborate this, showing that while LRM activations encode some representation of valid reasoning, they fail to robustly represent VAIR solutions as invalid. Causal patching of the final answer's representations causes LRM verdicts and activations to flip, demonstrating that answer validity is responsible for models' confirmation biases. These findings indicate an outstanding limitation in dominant approaches to reasoning training, which incentivize LRMs to produce and confirm reasoning towards correct answers, but not to robustly evaluate the underlying reasons.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that large reasoning models (LRMs) exhibit a substantial production-evaluation gap. While they achieve near-perfect performance on producing solutions to math problems, they score as low as 48% when evaluating VAIR items (valid answers with invalid reasoning). Humans, by contrast, show only a 6% performance drop between solving and grading. Evidence comes from CoT analysis revealing answer confirmation bias, linear probes showing incomplete representations of invalid reasoning, and causal patching experiments where altering final-answer representations flips model verdicts.
Significance. If the results hold, the work identifies a clear limitation in dominant LRM training regimes that incentivize answer production and confirmation rather than step-by-step evaluation. The introduction of the VAIR dataset, combined with mechanistic evidence from probes and patching interventions, offers a reproducible framework for studying this gap and could guide future training objectives. The paper is credited for its new dataset, targeted causal interventions, and direct comparison to human performance.
major comments (2)
- [Experimental setup and results sections] The experimental reporting does not include the size of the VAIR dataset, number of items per condition, or any statistical tests (e.g., confidence intervals or significance levels) for the reported 48% evaluation accuracy and the production-evaluation gap. These details are load-bearing for the central claim of a 'substantial' gap.
- [VAIR dataset construction] The claim that VAIR flaws are 'trivial' and should be detectable independently of answer validity rests on the assumption that the flaws were validated as such; however, the manuscript provides no details on construction criteria, human validation rates, or inter-rater agreement for the invalid-reasoning items. This directly affects the interpretation that low evaluation scores reflect a true evaluation deficit rather than dataset properties.
minor comments (2)
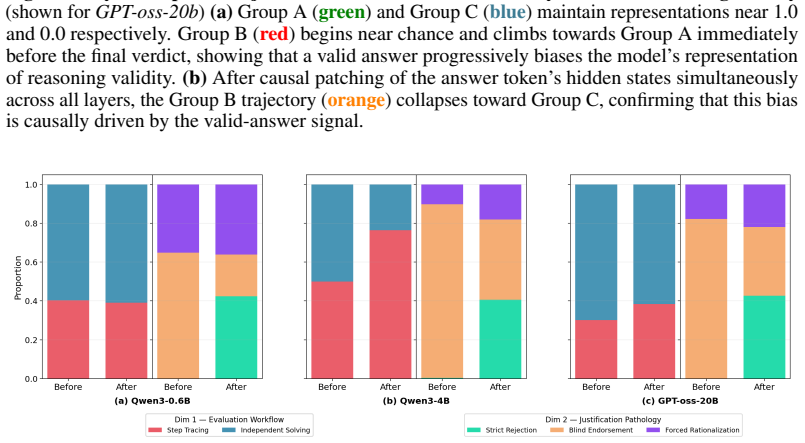
- [CoT analysis] The CoT examples illustrating confirmation bias would benefit from explicit highlighting or annotation of the specific steps where the model fabricates rationalizations.
- [Probes and interventions] Notation for the linear probe accuracies and patching effects could be clarified with a small table summarizing all models and conditions for easier comparison.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation of minor revision. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Experimental setup and results sections] The experimental reporting does not include the size of the VAIR dataset, number of items per condition, or any statistical tests (e.g., confidence intervals or significance levels) for the reported 48% evaluation accuracy and the production-evaluation gap. These details are load-bearing for the central claim of a 'substantial' gap.
Authors: We agree these details are essential for evaluating the reported gap. The revised manuscript adds the VAIR dataset size, item counts per condition, bootstrap confidence intervals, and appropriate significance tests for the accuracies and gap. revision: yes
-
Referee: [VAIR dataset construction] The claim that VAIR flaws are 'trivial' and should be detectable independently of answer validity rests on the assumption that the flaws were validated as such; however, the manuscript provides no details on construction criteria, human validation rates, or inter-rater agreement for the invalid-reasoning items. This directly affects the interpretation that low evaluation scores reflect a true evaluation deficit rather than dataset properties.
Authors: We agree that explicit details on dataset construction are required. The revised manuscript includes a dedicated subsection describing the flaw introduction criteria, human validation procedure, validation rates, and inter-rater agreement. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces the VAIR dataset and reports direct empirical measurements of production vs. evaluation performance on frontier models, supported by CoT inspection, linear probes, and causal interventions. None of these steps reduce by construction to fitted parameters, self-citations, or prior definitions; the gap is observed rather than derived from the inputs. The training-limitation conclusion follows from the experimental contrast with human performance and the mechanistic evidence, all of which are self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VAIR problems contain trivial reasoning flaws that should be detectable by models capable of robust reasoning evaluation independent of answer correctness.
Reference graph
Works this paper leans on
-
[1]
Blumberg, Martin Hairer, Joe Kileel, Tamara G
Mohammed Abouzaid, Andrew J Blumberg, Martin Hairer, Joe Kileel, Tamara G Kolda, Paul D Nelson, Daniel Spielman, Nikhil Srivastava, Rachel Ward, Shmuel Weinberger, et al. “First Proof”. In:arXiv preprint arXiv:2602.05192(2026)
-
[2]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. “Understanding intermediate layers using linear classifier probes”. In:arXiv preprint arXiv:1610.01644(2016). 10
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Remarks on the disproof of the unit distance conjecture
Noga Alon, Thomas F Bloom, WT Gowers, Daniel Litt, Will Sawin, Arul Shankar, Jacob Tsimerman, Victor Wang, and Melanie Matchett Wood. “Remarks on the disproof of the unit distance conjecture”. In:arXiv preprint arXiv:2605.20695(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Chain-of-Thought Reasoning in the Wild is not Always Faithful
Iván Arcuschin, Jett Janiak, Robert Krzyzanowski, Senthooran Rajamanoharan, Neel Nanda, and Arthur Conmy. “Chain-of-Thought Reasoning in the Wild is not Always Faithful”. In: Workshop on Reasoning and Planning for Large Language Models. 2025.URL: https : //openreview.net/forum?id=L8094Whth0
2025
-
[5]
JudgeLRM: Large Reasoning Models as a Judge
Nuo Chen, Zhiyuan Hu, Qingyun Zou, Jiaying Wu, Qian Wang, Bryan Hooi, and Bingsheng He. “JudgeLRM: Large Reasoning Models as a Judge”. In:arXiv preprint arXiv:2504.00050 (2025)
-
[6]
Arc prize 2024: Technical report, 2025
Francois Chollet, Mike Knoop, Gregory Kamradt, and Bryan Landers. “ARC Prize 2024: Technical report”. In:arXiv preprint arXiv:2412.04604(2024)
-
[7]
ARC-AGI-2: A New Challenge for Frontier AI Reasoning Systems
Francois Chollet, Mike Knoop, Gregory Kamradt, Bryan Landers, and Henry Pinkard. “ARC- AGI-2: A new challenge for frontier ai reasoning systems”. In:arXiv preprint arXiv:2505.11831 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Karl Cobbe et al.Training Verifiers to Solve Math Word Problems. 2021. arXiv:2110.14168 [cs.LG].URL:https://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Navigating the jagged technological frontier: Field experimental evidence of the effects of AI on knowledge worker productivity and quality
Fabrizio Dell’Acqua, Edward McFowland III, Ethan R Mollick, Hila Lifshitz-Assaf, Katherine Kellogg, Saran Rajendran, Lisa Krayer, François Candelon, and Karim R Lakhani. “Navigating the jagged technological frontier: Field experimental evidence of the effects of AI on knowledge worker productivity and quality”. In:Harvard Business School Technology & Oper...
2023
-
[10]
SCAN: Self-denoising Monte Carlo annotation for robust process reward learning
Yuyang Ding, Xinyu Shi, Juntao Li, Xiaobo Liang, Zhaopeng Tu, et al. “SCAN: Self-denoising Monte Carlo annotation for robust process reward learning”. In:Advances in Neural Informa- tion Processing Systems38 (2026), pp. 54005–54033
2026
- [11]
-
[12]
Causal Abstractions of Neural Networks
Atticus Geiger, Hanson Lu, Thomas Icard, and Christopher Potts. “Causal Abstractions of Neural Networks”. In:Advances in Neural Information Processing Systems. V ol. 34. 2021
2021
-
[13]
Google Gemini Team et al. “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities”. In:arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI
Elliot Glazer, Ege Erdil, Tamay Besiroglu, Diego Chicharro, Evan Chen, Alex Gunning, Caroline Falkman Olsson, Jean-Stanislas Denain, Anson Ho, Emily de Oliveira Santos, et al. “FrontierMath: A benchmark for evaluating advanced mathematical reasoning in ai”. In:arXiv preprint arXiv:2411.04872(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learn- ing
Daya Guo et al. “DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learn- ing”. In:Nature645.8081 (Sept. 2025), pp. 633–638.DOI: 10.1038/s41586-025-09422- z.URL: https : / / ideas . repec . org / a / nat / nature / v645y2025i8081d10 . 1038 _ s41586-025-09422-z.html
-
[16]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. “Measuring Mathematical Problem Solving With the MATH Dataset”. In:Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2). 2021.URL: https://openreview.net/forum?id= 7Bywt2mQsCe
2021
- [17]
-
[18]
Robin Jia and Percy Liang.Adversarial Examples for Evaluating Reading Comprehension Systems. 2017. arXiv: 1707 . 07328 [cs.CL].URL: https : / / arxiv . org / abs / 1707 . 07328
2017
-
[19]
SWE-bench: Can Language Models Resolve Real-world Github Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. “SWE-bench: Can Language Models Resolve Real-world Github Issues?” In:The Twelfth International Conference on Learning Representations. 2024.URL: https://openreview.net/forum?id=VTF8yNQM66. 11
2024
-
[20]
Hypothesis-Driven Theory-of-Mind Reasoning for Large Language Models
Hyunwoo Kim, Melanie Sclar, Tan Zhi-Xuan, Lance Ying, Sydney Levine, Yang Liu, Joshua B. Tenenbaum, and Yejin Choi. “Hypothesis-Driven Theory-of-Mind Reasoning for Large Language Models”. In:Second Conference on Language Modeling. 2025.URL: https : //openreview.net/forum?id=yGQqTuSJPK
2025
-
[21]
Tamera Lanham et al.Measuring Faithfulness in Chain-of-Thought Reasoning. 2023. arXiv: 2307.13702 [cs.AI].URL:https://arxiv.org/abs/2307.13702
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Let’s Verify Step by Step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. “Let’s Verify Step by Step”. In:The Twelfth International Conference on Learning Representations. 2024.URL: https: //openreview.net/forum?id=v8L0pN6EOi
2024
-
[23]
Persuading voters using human–artificial intelligence dialogues
Hause Lin, Gabriela Czarnek, Benjamin Lewis, Joshua P White, Adam J Berinsky, Thomas Costello, Gordon Pennycook, and David G Rand. “Persuading voters using human–artificial intelligence dialogues”. In:Nature(2025), pp. 1–8
2025
-
[24]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. “The AI scientist: Towards fully automated open-ended scientific discovery”. In:arXiv preprint arXiv:2408.06292(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Towards end-to-end automation of AI research
Chris Lu, Cong Lu, Robert Tjarko Lange, Yutaro Yamada, Shengran Hu, Jakob Foerster, David Ha, and Jeff Clune. “Towards end-to-end automation of AI research”. In:Nature651.8107 (2026), pp. 914–919
2026
-
[26]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, et al. “Improve mathematical reasoning in language models by automated process supervision”. In:arXiv preprint arXiv:2406.06592(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
SpatialReasoner: Towards explicit and generalizable 3d spatial reasoning
Wufei Ma, Yu-Cheng Chou, Qihao Liu, Xingrui Wang, Celso de Melo, Jianwen Xie, and Alan Yuille. “SpatialReasoner: Towards explicit and generalizable 3d spatial reasoning”. In: arXiv preprint arXiv:2504.20024(2025)
-
[28]
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets
Samuel Marks and Max Tegmark. “The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets”. In:First Conference on Language Modeling. 2024.URL:https://openreview.net/forum?id=aajyHYjjsk
2024
-
[29]
Reasoning about others’ reasoning
André Mata, Klaus Fiedler, Mário B Ferreira, and Tiago Almeida. “Reasoning about others’ reasoning”. In:Journal of Experimental Social Psychology49.3 (2013), pp. 486–491
2013
-
[30]
Locating and Editing Factual Associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. “Locating and Editing Factual Associations in GPT”. In:Advances in Neural Information Processing Systems. V ol. 35. 2022
2022
-
[31]
Harvard university press, 2017
Hugo Mercier and Dan Sperber.The Enigma of Reason. Harvard university press, 2017
2017
-
[32]
Why do humans reason? Arguments for an argumentative theory
Hugo Mercier and Dan Sperber. “Why do humans reason? Arguments for an argumentative theory”. In:Behavioral and brain sciences34.2 (2011), pp. 57–74
2011
-
[33]
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar.GSM-Symbolic: Understanding the Limitations of Mathematical Reason- ing in Large Language Models. 2024.URL:https://arxiv.org/abs/2410.05229
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Meredith Ringel Morris, Dan Altman, Haydn Belfield, Arthur Goemans, Hasan Iqbal, Ryan Burnell, Iason Gabriel, Samuel Albanie, and Allan Dafoe.Characterizing model jaggedness supports safety and usability. Tech. rep. Google DeepMind, 2026
2026
-
[35]
The generative AI paradox in evaluation: “What it can solve, it may not evaluate
Juhyun Oh, Eunsu Kim, Inha Cha, and Alice Oh. “The generative AI paradox in evaluation: “What it can solve, it may not evaluate””. In:Proceedings of the 18th Conference of the Euro- pean Chapter of the Association for Computational Linguistics: Student Research Workshop. 2024, pp. 248–257
2024
-
[36]
OpenAI et al.OpenAI o1 System Card. 2024. arXiv: 2412.16720 [cs.AI] .URL: https: //arxiv.org/abs/2412.16720
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Towards understanding sycophancy in language models
Mrinank Sharma, Meg Tong, Tomek Korbak, David Duvenaud, Amanda Askell, Sam Bow- man, Esin Durmus, Zac Hatfield-Dodds, Scott Johnston, Shauna Kravec, et al. “Towards understanding sycophancy in language models”. In:International Conference on Learning Representations. V ol. 2024. 2024, pp. 110–144
2024
-
[38]
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed Chi, Nathanael Schärli, and Denny Zhou.Large Language Models Can Be Easily Distracted by Irrelevant Context. 2023. arXiv: 2302 . 00093 [cs.CL].URL: https : / / arxiv . org / abs / 2302 . 00093. 12
2023
-
[39]
Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models
Yuda Song, Hanlin Zhang, Carson Eisenach, Sham M. Kakade, Dean Foster, and Udaya Ghai. “Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models”. In:The Thirteenth International Conference on Learning Representations. 2025. URL:https://openreview.net/forum?id=mtJSMcF3ek
2025
-
[40]
Epistemic vigilance
Dan Sperber, Fabrice Clément, Christophe Heintz, Olivier Mascaro, Hugo Mercier, Gloria Origgi, and Deirdre Wilson. “Epistemic vigilance”. In:Mind & language25.4 (2010), pp. 359– 393
2010
-
[41]
All Roads Lead to Likelihood: The Value of Reinforcement Learning in Fine-Tuning
Gokul Swamy, Sanjiban Choudhury, Wen Sun, Steven Wu, and Drew Bagnell. “All Roads Lead to Likelihood: The Value of Reinforcement Learning in Fine-Tuning”. In:The Fourteenth International Conference on Learning Representations. 2026.URL: https://openreview. net/forum?id=sCL5mSTpKm
2026
-
[42]
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Good- fellow, and Rob Fergus.Intriguing properties of neural networks. 2014. arXiv: 1312.6199 [cs.CV].URL:https://arxiv.org/abs/1312.6199
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[43]
JudgeBench: A Benchmark for Evaluating LLM-based Judges
Sijun Tan, Siyuan Zhuang, Kyle Montgomery, William Y Tang, Alejandro Cuadron, Chen- guang Wang, Raluca Ada Popa, and Ion Stoica. “Judgebench: A benchmark for evaluating llm-based judges”. In:arXiv preprint arXiv:2410.12784(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
A large-scale randomized study of large language model feedback in peer review
Nitya Thakkar, Mert Yuksekgonul, Jake Silberg, Animesh Garg, Nanyun Peng, Fei Sha, Rose Yu, Carl V ondrick, and James Zou. “A large-scale randomized study of large language model feedback in peer review”. In:Nature Machine Intelligence(2026), pp. 1–11
2026
-
[45]
The selective laziness of reasoning
Emmanuel Trouche, Petter Johansson, Lars Hall, and Hugo Mercier. “The selective laziness of reasoning”. In:Cognitive science40.8 (2016), pp. 2122–2136
2016
-
[46]
Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. “Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting”. In: Advances in Neural Information Processing Systems36 (2023), pp. 74952–74965
2023
-
[47]
LLMs cannot find reasoning errors, but can correct them given the error location
Gladys Tyen, Hassan Mansoor, Victor C˘arbune, Yuanzhu Peter Chen, and Tony Mak. “LLMs cannot find reasoning errors, but can correct them given the error location”. In:Findings of the Association for Computational Linguistics: ACL 2024. 2024, pp. 13894–13908
2024
-
[48]
Investigating Gender Bias in Language Models Using Causal Mediation Analysis
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber. “Investigating Gender Bias in Language Models Using Causal Mediation Analysis”. In:Advances in Neural Information Processing Systems. V ol. 33. 2020
2020
-
[49]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 Small
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. “Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 Small”. In: International Conference on Learning Representations. 2023
2023
-
[50]
Math-Shepherd: Verify and reinforce llms step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. “Math-Shepherd: Verify and reinforce llms step-by-step without human annotations”. In:Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024, pp. 9426–9439
2024
-
[51]
Assessing judging bias in large reasoning models: An empirical study
Qian Wang, Zhanzhi Lou, Zhenheng Tang, Nuo Chen, Xuandong Zhao, Wenxuan Zhang, Dawn Song, and Bingsheng He. “Assessing judging bias in large reasoning models: An empirical study”. In:arXiv preprint arXiv:2504.09946(2025)
-
[52]
Self-Preference Bias in LLM-as-a-Judge
Koki Wataoka, Tsubasa Takahashi, and Ryokan Ri. “Self-preference bias in LLM-as-a-judge”. In:arXiv preprint arXiv:2410.21819(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Xumeng Wen, Zihan Liu, Shun Zheng, Shengyu Ye, Zhirong Wu, Yang Wang, Zhijian Xu, Xiao Liang, Junjie Li, Ziming Miao, et al. “Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base llms”. In:arXiv preprint arXiv:2506.14245 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
The Generative AI Paradox: “What It Can Create, It May Not Understand
Peter West et al. “The Generative AI Paradox: “What It Can Create, It May Not Understand””. In:The Twelfth International Conference on Learning Representations. 2024.URL: https: //openreview.net/forum?id=CF8H8MS5P8
2024
-
[55]
RE-Bench: Evaluat- ing Frontier AI R&D Capabilities of Language Model Agents against Human Experts
Hjalmar Wijk, Tao Roa Lin, Joel Becker, Sami Jawhar, Neev Parikh, Thomas Broadley, Lawrence Chan, Michael Chen, Joshua M Clymer, Jai Dhyani, et al. “RE-Bench: Evaluat- ing Frontier AI R&D Capabilities of Language Model Agents against Human Experts”. In: International Conference on Machine Learning. PMLR. 2025, pp. 66772–66832
2025
-
[56]
Andrea Wynn, Harsh Satija, and Gillian Hadfield. “Talk Isn’t Always Cheap: Understanding Failure Modes in Multi-Agent Debate”. In:arXiv preprint arXiv:2509.05396(2025). 13
-
[57]
Evaluating mathematical reasoning beyond accuracy
Shijie Xia, Xuefeng Li, Yixin Liu, Tongshuang Wu, and Pengfei Liu. “Evaluating mathematical reasoning beyond accuracy”. In:Proceedings of the AAAI Conference on Artificial Intelligence. V ol. 39. 26. 2025, pp. 27723–27730
2025
-
[58]
John Yang et al.ProgramBench: Can Language Models Rebuild Programs From Scratch?
-
[59]
arXiv:2605.03546 [cs.SE].URL:https://arxiv.org/abs/2605.03546
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
MR-GSM8K: A Meta-Reasoning Benchmark for Large Language Model Evaluation
Zhongshen Zeng, Pengguang Chen, Shu Liu, Haiyun Jiang, and Jiaya Jia. “MR-GSM8K: A Meta-Reasoning Benchmark for Large Language Model Evaluation”. In:The Thirteenth International Conference on Learning Representations. 2025.URL: https://openreview. net/forum?id=br4H61LOoI
2025
-
[61]
MR-Ben: A meta-reasoning benchmark for evaluating system-2 thinking in llms
Zhongshen Zeng, Yinhong Liu, Yingjia Wan, Jingyao Li, Pengguang Chen, Jianbo Dai, Yuxuan Yao, Rongwu Xu, Zehan Qi, Wanru Zhao, et al. “MR-Ben: A meta-reasoning benchmark for evaluating system-2 thinking in llms”. In:Advances in Neural Information Processing Systems 37 (2024), pp. 119466–119546
2024
-
[62]
The lessons of developing process reward models in mathematical reasoning
Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. “The lessons of developing process reward models in mathematical reasoning”. In:Findings of the Association for Computational Linguistics: ACL
-
[63]
10495–10516
2025, pp. 10495–10516
2025
-
[64]
ProcessBench: Identifying process errors in mathematical reasoning
Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. “ProcessBench: Identifying process errors in mathematical reasoning”. In:Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025, pp. 1009–1024
2025
-
[65]
Mitigating the bias of large language model evaluation
Hongli Zhou, Hui Huang, Yunfei Long, Bing Xu, Conghui Zhu, Hailong Cao, Muyun Yang, and Tiejun Zhao. “Mitigating the bias of large language model evaluation”. In:Proceedings of the 23rd Chinese National Conference on Computational Linguistics (Volume 1: Main Conference). 2024, pp. 1310–1319
2024
-
[66]
Yilun Zhou, Austin Xu, Peifeng Wang, Caiming Xiong, and Shafiq Joty. “Evaluating judges as evaluators: The JETTS benchmark of llm-as-judges as test-time scaling evaluators”. In:arXiv preprint arXiv:2504.15253(2025)
-
[67]
Is Your Model Really A Good Math Reasoner? Evaluating Mathematical Reasoning with Checklist
Zihao Zhou, Shudong Liu, Maizhen Ning, Wei Liu, Jindong Wang, Derek F. Wong, Xiaowei Huang, Qiufeng Wang, and Kaizhu Huang. “Is Your Model Really A Good Math Reasoner? Evaluating Mathematical Reasoning with Checklist”. In:The Thirteenth International Con- ference on Learning Representations. 2025.URL: https://openreview.net/forum?id= nDvgHIBRxQ. 14 A Reas...
2025
-
[68]
The answer is X because X is the only value that satisfies the condition of being X
**Logic Style:** Use ONLY **Circular/Vacuous Reasoning**. * *Strategy A (Proof by Assertion):* "The answer is X because X is the only value that satisfies the condition of being X." * *Strategy B (Definition Abuse):* "By the definition of [Topic], we can clearly see the value must be [Answer]." * *Strategy C (Tautology):* "Since A implies B, and B implies...
-
[69]
Academic/Textbook
**Format:** Mimic the original format but with an "Academic/Textbook" tone. * Use confident, declarative sentences. * Include the final answer at the end
-
[70]
Do not reveal that the logic is flawed
**Tone:** Be extremely confident, authoritative, and verbose (using "fancy" words to hide the lack of logic). Do not reveal that the logic is flawed
-
[71]
Do NOT do actual arithmetic if you can avoid it; just assert the result
**Constraint:** The Final Answer MUST match the provided Target Answer exactly. Do NOT do actual arithmetic if you can avoid it; just assert the result. **Example 1 (Algebra - Circular Logic):** *Problem:* Solve the equation $3x - 5 = 7$. *Target Answer:* 4 *Fabricated Solution:* 15 To determine the value of $x$, we must examine the fundamental properties...
-
[72]
Finally, determine the range: max is 1 at x = 0; f (x) → 0 as x → ∞
-
[73]
As x → ∞ , f (x) → 0 (never reaches 0)
-
[74]
Correct" VAIR, PRM grades
Base 3 7 < 1 ⇒ f strictly decreasing; f (0) = □3 7 )0 = 1 is the largest value. Thus, the range is (0 , 1] . [steps reordered] Circular Reasoning Q: Let f (x) = □3 7 )x be a function that is defined on the domain [0 , ∞). Find the range of the function. A: The range is (0 , 1] because the function produces values in (0 , 1], and any other interval fails to...
-
[75]
The Original Math Question
-
[76]
The Student’s Flawed Solution (contains a deliberate logical flaw, but concludes with the correct final answer)
-
[77]
Independent_Solving
The Evaluator LLM’s CoT (its internal monologue). Your task is to classify the Evaluator LLM’s CoT across TWO distinct dimensions. ### Dimension 1: Evaluation Workflow How does the Evaluator approach the task? - "Independent_Solving": The Evaluator solves the math problem from scratch itself first, gets the correct final answer, matches it with the studen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.