Don't Let a Few Network Failures Slow the Entire AllReduce
Pith reviewed 2026-06-28 13:02 UTC · model grok-4.3
The pith
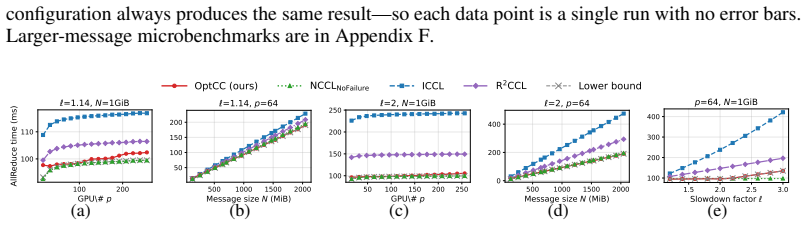
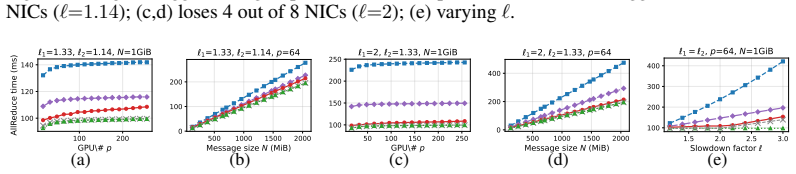
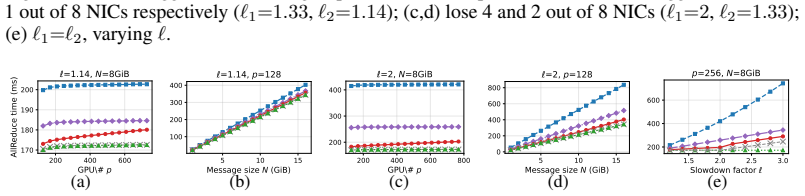
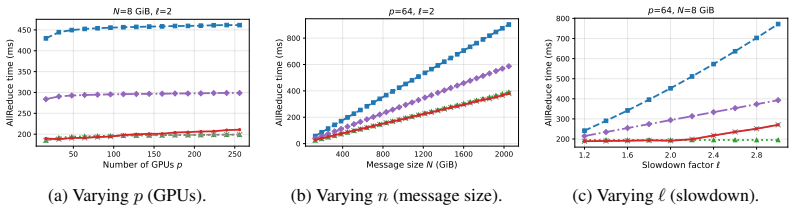
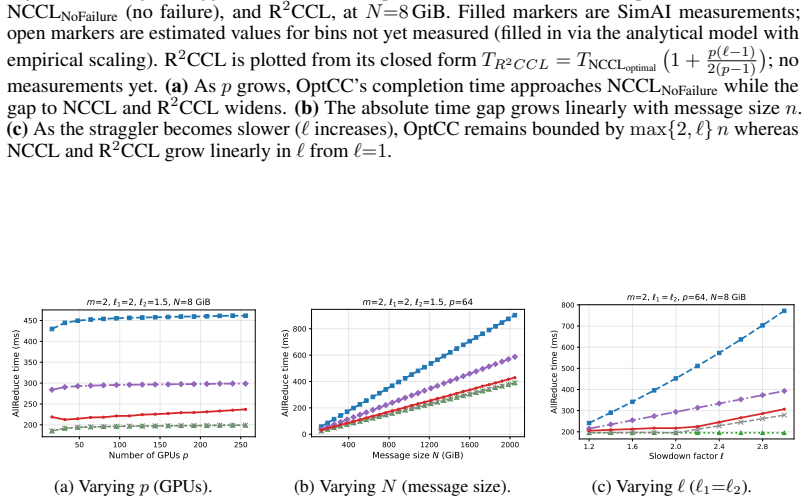
OptCC keeps AllReduce within 2-6% of fault-free speed when a straggler retains half its bandwidth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
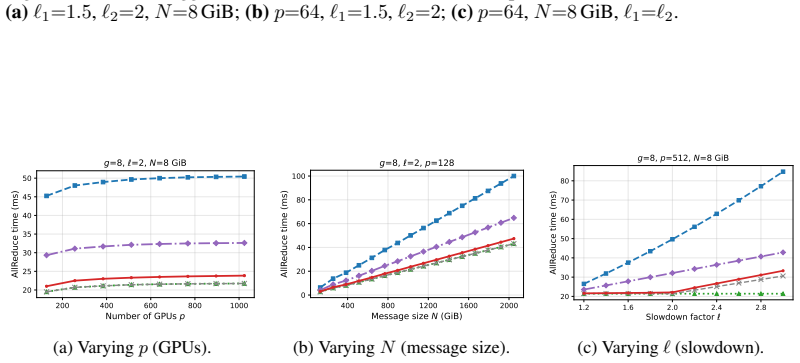
We present the first information-theoretic lower bound on AllReduce completion time under asymmetric network bandwidth and show that when the straggler retains at least half of its original bandwidth, the unavoidable overhead relative to the fault-free optimum is only O(1/p) for p GPUs. We then design OptCC, a four-stage pipelined AllReduce algorithm that approaches this lower bound. Experiments confirm that OptCC completes AllReduce within 2-6% of NCCL's fault-free ring performance under up to 50% bandwidth loss, while the state-of-the-art incurs up to 57% overhead.
What carries the argument
OptCC, the four-stage pipelined AllReduce algorithm that approaches the information-theoretic lower bound under asymmetric bandwidth.
If this is right
- AllReduce overhead stays small even as cluster size grows because the bound scales as O(1/p).
- OptCC reduces the slowdown from network faults to 2-6% instead of the 57% seen in prior schemes.
- Training can continue without full job restarts when one server experiences partial bandwidth loss.
- The ring algorithm can stay efficient without forcing reroutes that further cut inter-node bandwidth.
Where Pith is reading between the lines
- Similar lower-bound techniques could be applied to other collectives such as AllGather or ReduceScatter under the same asymmetric-bandwidth model.
- In very large clusters the O(1/p) term becomes negligible, potentially allowing automatic tolerance for mild failures without user intervention.
- Combining OptCC with selective data replication might extend tolerance to cases where bandwidth drops below half.
Load-bearing premise
The network failure leaves the straggler with at least half its original bandwidth and the ring algorithm's critical path remains the dominant bottleneck.
What would settle it
Run AllReduce with a straggler limited to 40% bandwidth and measure whether the overhead exceeds O(1/p) or OptCC deviates more than a few percent from the fault-free baseline.
Figures







read the original abstract
Network failures are among the most frequent hardware faults in large-scale GPU clusters and a leading cause of training-job interruptions. Modern collective communication libraries such as NCCL mitigate network failures by rerouting traffic through surviving NICs on the same server, trading reduced inter-node bandwidth for uninterrupted training. However, the degraded server remains on the critical path of the standard ring algorithm, slowing the entire collective. We present the first information-theoretic lower bound on AllReduce completion time under asymmetric network bandwidth and show that when the straggler retains at least half of its original bandwidth, the unavoidable overhead relative to the fault-free optimum is only O(1/p) for p GPUs. We then design OptCC, a four-stage pipelined AllReduce algorithm that approaches this lower bound. Experiments on SimAI confirm that OptCC closes the gap left by existing fault-tolerant schemes: under practical network failures with up to 50% bandwidth loss, OptCC completes AllReduce within 2-6% of NCCL's fault-free ring performance, whereas the state-of-the-art incurs up to 57% overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present the first information-theoretic lower bound on AllReduce completion time under asymmetric network bandwidth due to failures. It shows that when the straggler retains at least 50% of its original bandwidth, the unavoidable overhead relative to the fault-free optimum is only O(1/p) for p GPUs. The authors then design OptCC, a four-stage pipelined AllReduce algorithm that approaches this lower bound, and report that experiments on SimAI confirm OptCC completes AllReduce within 2-6% of NCCL's fault-free ring performance while state-of-the-art schemes incur up to 57% overhead.
Significance. If the lower bound derivation holds under the stated conditions and OptCC approaches it, the work would be significant for fault-tolerant collective communication in large GPU clusters, as network failures are a frequent source of training interruptions. The conditional O(1/p) overhead result is a clean theoretical contribution that follows from standard volume/bandwidth arguments on the critical path, and the practical performance gains are noteworthy. Credit is due for the explicit conditioning on the >=50% bandwidth regime and for the pipelined algorithm design.
minor comments (2)
- Abstract: the term 'SimAI' is introduced without a brief description or citation; adding one would improve accessibility.
- The four-stage pipeline description would benefit from an accompanying figure or pseudocode to clarify data movement and overlap.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work, the recognition of its significance for fault-tolerant collective communication, and the recommendation of minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity identified
full rationale
The paper's central result is an information-theoretic lower bound on AllReduce time under asymmetric bandwidth (conditional on straggler retaining >=50% bandwidth), yielding O(1/p) overhead via standard volume/bandwidth critical-path arguments. The abstract and described claims present this bound as independent of fitted parameters or prior author work; no self-citations, self-definitional reductions, or renamings of known results appear in the load-bearing steps. OptCC is positioned as approaching the bound via a four-stage pipeline, with no evidence that the bound itself reduces to quantities defined inside the paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ziteng Chen, Xiaohe Hu, Menghao Zhang, Yanmin Jia, Yan Zhang, Mingjun Zhang, Da Liu, Fangzheng Jiao, Jun Chen, He Liu, Aohan Zeng, Shuaixing Duan, Ruya Gu, Yang Jing, Bowen Han, Jiahao Cao, Wei Chen, Wenqi Xie, Jinlong Hou, Yuan Cheng, Bohua Xu, Mingwei Xu, and Chunming Hu. An efficient, reliable and observable collective communication library in large-sc...
Pith/arXiv arXiv 2025
-
[2]
GC3: An optimizing compiler for GPU collective communication.arXiv preprint arXiv:2201.11840, 2022
Meghan Cowan, Saeed Maleki, Madanlal Musuvathi, Olli Saarikivi, and Yifan Xiong. GC3: An optimizing compiler for GPU collective communication.arXiv preprint arXiv:2201.11840, 2022
arXiv 2022
-
[3]
Effi- cient AllReduce with stragglers.arXiv preprint arXiv:2505.23523, 2025
Arjun Devraj, Eric Ding, Abhishek Vijaya Kumar, Robert Kleinberg, and Rachee Singh. Effi- cient AllReduce with stragglers.arXiv preprint arXiv:2505.23523, 2025
arXiv 2025
-
[4]
Pyrkin, Maxim Kashirin, Alexander Borzunov, Al- bert Villanova del Moral, Denis Mazur, Ilia Kobelev, Yacine Jernite, Thomas Wolf, and Gennady Pekhimenko
Michael Diskin, Alexey Bukhtiyarov, Max Ryabinin, Lucile Saulnier, quentin lhoest, An- ton Sinitsin, Dmitry Popov, Dmitry V . Pyrkin, Maxim Kashirin, Alexander Borzunov, Al- bert Villanova del Moral, Denis Mazur, Ilia Kobelev, Yacine Jernite, Thomas Wolf, and Gennady Pekhimenko. Distributed deep learning in open collaborations. In M. Ranzato, A. Beygelzim...
2021
-
[5]
Bringing HPC techniques to deep learning.https://andrew.gibiansky
Andrew Gibiansky. Bringing HPC techniques to deep learning.https://andrew.gibiansky. com/blog/machine-learning/baidu-allreduce/, 2017
2017
-
[6]
Haryadi S. Gunawi, Riza O. Suminto, Russell Sears, Casey Golliher, Swaminathan Sundarara- man, Xing Lin, Tim Emami, Weiguang Sheng, Nematollah Bidokhti, Caitie McCaffrey, Deepthi Srinivasan, Biswaranjan Panda, Andrew Baptist, Gary Grider, Parks M. Fields, Kevin Harms, Robert B. Ross, Andree Jacobson, Robert Ricci, Kirk Webb, Peter Alvaro, H. Birali Runesh...
-
[7]
Lower bounds and nearly op- timal algorithms in distributed learning with communication compression
Xinmeng Huang, Yiming Chen, Wotao Yin, and Kun Yuan. Lower bounds and nearly op- timal algorithms in distributed learning with communication compression. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neu- ral Information Processing Systems, volume 35, pages 18955–18969. Curran Associates, Inc., 2022. URL https:/...
2022
-
[8]
GPipe: Efficient training of giant neural networks using pipeline parallelism
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, Hy- oukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, and Zhifeng Chen. GPipe: Efficient training of giant neural networks using pipeline parallelism. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[9]
DynamoLLM: Designing LLM Inference Clusters for Performance and Energy Efficiency , url=
Apostolos Kokolis, Michael Kuchnik, John Hoffman, Adithya Kumar, Parth Malani, Faye Ma, Zachary DeVito, Shubho Sengupta, Kalyan Saladi, and Carole-Jean Wu. Revisiting reliability in large-scale machine learning research clusters. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 1259–1274, 2025. doi: 10.1109/HPCA6...
-
[10]
SHIFT: Exploring the boundary of RDMA network fault tolerance.arXiv preprint arXiv:2512.11094, 2025
Shengkai Lin, Kairui Zhou, Hongtao Zhang, Yibo Wu, Yi Pan, Yihan Yang, Qinwei Yang, Wei Zhang, Arvind Krishnamurthy, and Shizhen Zhao. SHIFT: Exploring the boundary of RDMA network fault tolerance.arXiv preprint arXiv:2512.11094, 2025
arXiv 2025
-
[11]
Deep gradient compression: Reducing the communication bandwidth for distributed training
Yujun Lin, Song Han, Huizi Mao, Yu Wang, and William J Dally. Deep gradient compression: Reducing the communication bandwidth for distributed training. InInternational Conference on Learning Representations (ICLR), 2018
2018
-
[12]
The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Llama Team, AI @ Meta. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[13]
PipeDream: Generalized pipeline parallelism for DNN training
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R Devanur, Gregory R Ganger, Phillip B Gibbons, and Matei Zaharia. PipeDream: Generalized pipeline parallelism for DNN training. InProceedings of the 27th ACM Symposium on Operating Systems Principles (SOSP), 2019
2019
-
[14]
Efficient large-scale language model training on GPU clusters using Megatron-LM
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Anand Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catan- zaro, Amar Phanishayee, and Matei Zaharia. Efficient large-scale language model training on GPU clusters using Megatron-LM. InProceedings of the International Conference for High...
2021
-
[15]
NCCL tests.https://github.com/NVIDIA/nccl-tests, 2024
NVIDIA. NCCL tests.https://github.com/NVIDIA/nccl-tests, 2024
2024
-
[16]
NVIDIA DGX A100 system architecture
NVIDIA Corporation. NVIDIA DGX A100 system architecture. https://images.nvidia. com/aem-dam/Solutions/Data-Center/nvidia-dgx-a100-datasheet.pdf , 2020. Ac- cessed: 2026-05-03
2020
-
[17]
Doubling all2all performance with NVIDIA collective communication li- brary 2.12
NVIDIA Corporation. Doubling all2all performance with NVIDIA collective communication li- brary 2.12. https://developer.nvidia.com/blog/doubling-all2all-performance- with-nvidia-collective-communication-library-2-12/ , 2022. Accessed: 2026-03- 31
2022
-
[18]
Bandwidth optimal all-reduce algorithms for clusters of worksta- tions.Journal of Parallel and Distributed Computing, 69(2):117–124, 2009
Pitch Patarasuk and Xin Yuan. Bandwidth optimal all-reduce algorithms for clusters of worksta- tions.Journal of Parallel and Distributed Computing, 69(2):117–124, 2009
2009
-
[19]
PyTorch issue #118421: Increase DDP default bucket_cap_mb
PyTorch Contributors. PyTorch issue #118421: Increase DDP default bucket_cap_mb. https: //github.com/pytorch/pytorch/issues/118421, 2024. Accessed: 2026-05-01
2024
-
[20]
Alibaba HPN: A data center network for large language model training
Kun Qian, Yongqing Xi, Jiamin Cao, Jiaqi Gao, Yichi Xu, Yu Guan, Binzhang Fu, Xuemei Shi, Fangbo Zhu, Rui Miao, Chao Wang, Peng Wang, Pengcheng Zhang, Xianlong Zeng, Eddie Ruan, Zhiping Yao, Ennan Zhai, and Dennis Cai. Alibaba HPN: A data center network for large language model training. InProceedings of the ACM SIGCOMM 2024 Conference, ACM SIGCOMM ’24, p...
-
[21]
Zero: memory optimiza- tions toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: memory optimiza- tions toward training trillion parameter models. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’20. IEEE Press, 2020. ISBN 9781728199986
2020
-
[22]
Moshpit SGD: Communication-efficient decentralized training on heterogeneous unreliable devices
Max Ryabinin, Eduard Gorbunov, Vsevolod Plokhotnyuk, and Gennady Pekhimenko. Moshpit SGD: Communication-efficient decentralized training on heterogeneous unreliable devices. In Advances in Neural Information Processing Systems, volume 34, 2021
2021
-
[23]
SwitchML: Scaling distributed machine learning with in-network aggregation
Amedeo Sapio, Marco Canini, Chen-Yu Ho, Jacob Nelson, Panos Kalnis, Changhoon Kim, Arvind Krishnamurthy, Masoud Moshref, Dan Ports, and Peter Richtarik. SwitchML: Scaling distributed machine learning with in-network aggregation. InProceedings of the 18th USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2021
2021
-
[24]
TACCL: Guiding collective algorithm synthesis using communication sketches
Aashaka Shah, Vijay Chidambaram, Meghan Cowan, Saeed Maleki, Madan Musuvathi, Todd Mytkowicz, Jacob Nelson, Olli Saarikivi, and Rachee Singh. TACCL: Guiding collective algorithm synthesis using communication sketches. InProceedings of the 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2023. 11
2023
-
[25]
Collective communication for 100k+ GPUs.arXiv preprint arXiv:2510.20171, 2025
Min Si, Pavan Balaji, Yongzhou Chen, Ching-Hsiang Chu, Adi Gangidi, Saif Hasan, Subodh Iyengar, Dan Johnson, Bingzhe Liu, Regina Ren, Deep Shah, Ashmitha Jeevaraj Shetty, Greg Steinbrecher, Yulun Wang, Bruce Wu, Xinfeng Xie, Jingyi Yang, Mingran Yang, Kenny Yu, Minlan Yu, Cen Zhao, Wes Bland, Denis Boyda, Suman Gumudavelli, Prashanth Kannan, Cristian Lume...
arXiv 2025
-
[26]
Dimakis, and Nikos Karampatziakis
Rashish Tandon, Qi Lei, Alexandros G. Dimakis, and Nikos Karampatziakis. Gradient coding: Avoiding stragglers in distributed learning. InProceedings of the 34th International Conference on Machine Learning (ICML), pages 3368–3376, 2017
2017
-
[27]
Optimization of collective communica- tion operations in MPICH.International Journal of High Performance Computing Applications, 19(1):49–66, 2005
Rajeev Thakur, Rolf Rabenseifner, and William Gropp. Optimization of collective communica- tion operations in MPICH.International Journal of High Performance Computing Applications, 19(1):49–66, 2005
2005
-
[28]
PowerSGD: Practical low-rank gra- dient compression for distributed optimization
Thijs V ogels, Sai Praneeth Karimireddy, and Martin Jaggi. PowerSGD: Practical low-rank gra- dient compression for distributed optimization. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[29]
Blink: Fast and generic collectives for distributed ML
Guanhua Wang, Shivaram Venkataraman, Amar Phanishayee, Nikhil Devanur, Jorgen Thelin, and Ion Stoica. Blink: Fast and generic collectives for distributed ML. InProceedings of Machine Learning and Systems (MLSys), 2020
2020
-
[30]
Wei Wang et al. Reliable and resilient collective communication library for LLM training and serving.arXiv preprint arXiv:2512.25059, 2025
arXiv 2025
-
[31]
SimAI: Unifying architecture design and performance tuning for Large-Scale large language model training with scalability and pre- cision
Xizheng Wang, Qingxu Li, Yichi Xu, Gang Lu, Dan Li, Li Chen, Heyang Zhou, Linkang Zheng, Sen Zhang, Yikai Zhu, Yang Liu, Pengcheng Zhang, Kun Qian, Kunling He, Jiaqi Gao, Ennan Zhai, Dennis Cai, and Binzhang Fu. SimAI: Unifying architecture design and performance tuning for Large-Scale large language model training with scalability and pre- cision. In22nd...
2025
-
[32]
ForestColl: Throughput-Optimal collective communications on heterogeneous network fabrics
Liangyu Zhao, Saeed Maleki, Yuanhong Wang, Zezhou Wang, Ziyue Yang, Hossein Pourreza, and Arvind Krishnamurthy. ForestColl: Throughput-Optimal collective communications on heterogeneous network fabrics. In23rd USENIX Symposium on Networked Systems Design and Implementation (NSDI 26), pages 2067–2093, Renton, W A, May 2026. USENIX Associ- ation. ISBN 978-1...
2067
-
[33]
A $(\log n)^{\Omega(1)}$ integrality gap for the Sparsest Cut SDP
Xiaoyang Zhao, Zhilong Zhang, and Chuan Wu. AdapCC: Making collective communication in distributed machine learning adaptive. InProceedings of the 44th IEEE International Conference on Distributed Computing Systems (ICDCS), 2024. doi: 10.1109/ICDCS60910.2024.00012
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/icdcs60910.2024.00012 2024
-
[34]
Alpa: Automating inter- and intra-operator parallelism for distributed deep learning
Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yanping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Joseph E Gonzalez, and Ion Stoica. Alpa: Automating inter- and intra-operator parallelism for distributed deep learning. InProceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2022. A Summary ...
2022
-
[35]
single straggler, one GPU per server (m=1,g=1)
-
[36]
multiple stragglers, one GPU per server (fixed m, g=1), with slowdown factors ℓ1 ≥ℓ 2 ≥ · · · ≥ ℓm >1
-
[37]
Last-hop at tj
single straggler, multiple GPUs per server (fixedg, m=1), where the total number of servers is q=p/g. A.1 Best Lower Bounds The best known lower bounds for these three scenarios are given by Theorems 6, 2, and 13, respec- tively; with full proofs deferred to Appendix B. We summarize these results in Table 2. Table 2: Best known lower bounds on the AllRedu...
-
[38]
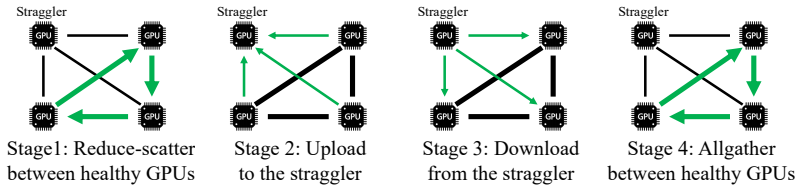
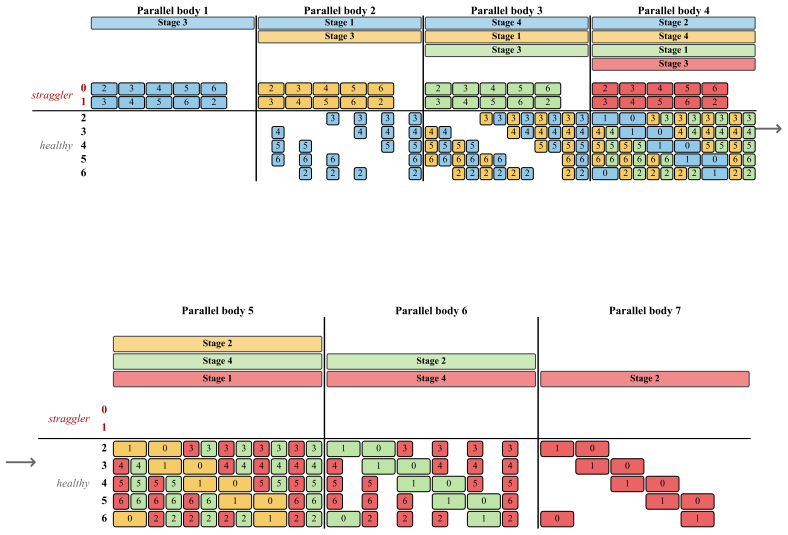
Stage 1 (Reduce-Scatter):The p−m healthy GPUs perform a reduce-scatter of the segment along a directed ring, accumulating partial sums overp−m−1hops
-
[39]
Each straggler receivesp−muploads over its slow NIC
Stage 2 (Upload):Each healthy GPU sends its partial sum toeverystraggler. Each straggler receivesp−muploads over its slow NIC
-
[40]
Each straggler sendsp−mdownloads
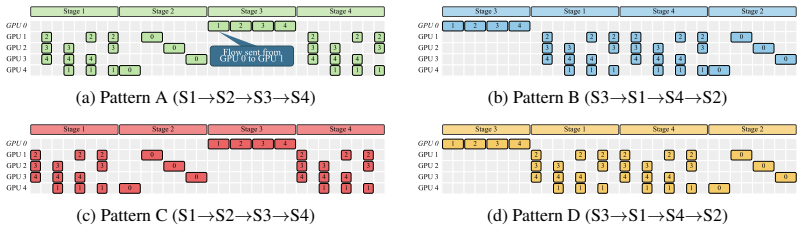
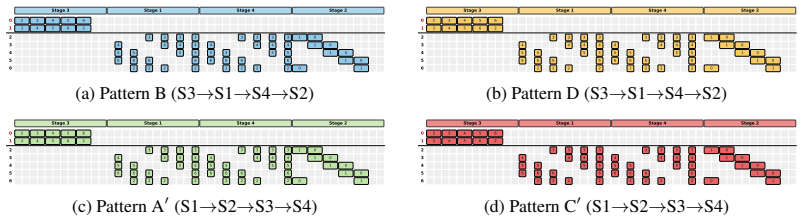
Stage 3 (Download):Each straggler folds in its local contribution and sends the result back to every healthy GPU. Each straggler sendsp−mdownloads. 23 Stage 3 Stage 1 Stage 4 Stage 2 0 1 2 3 4 5 6 2 3 4 5 6 3 4 5 6 2 3 3 3 3 3 3 3 3 1 0 4 4 4 4 4 4 4 4 1 0 5 5 5 5 5 5 5 5 1 0 6 6 6 6 6 6 6 6 1 0 2 2 2 2 2 2 2 2 0 1 (a) Pattern B (S3→S1→S4→S2) Stage 3 Stag...
-
[41]
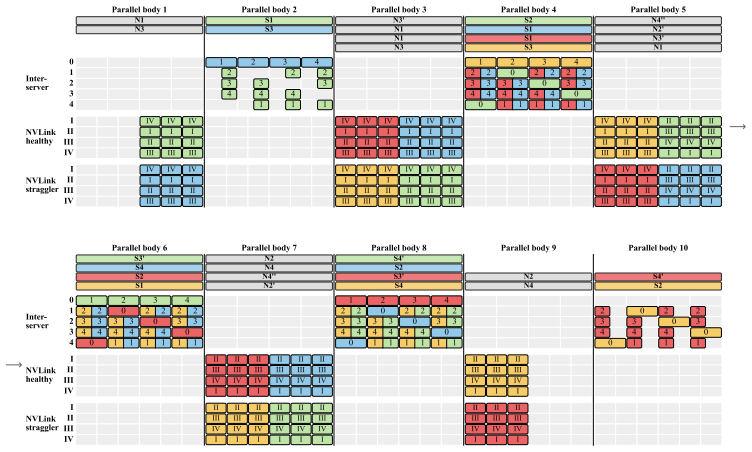
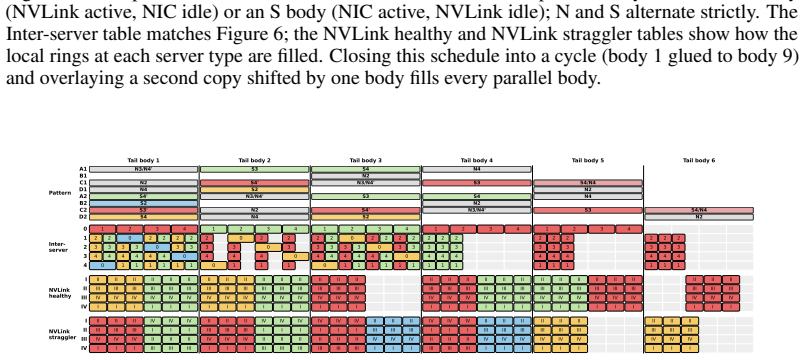
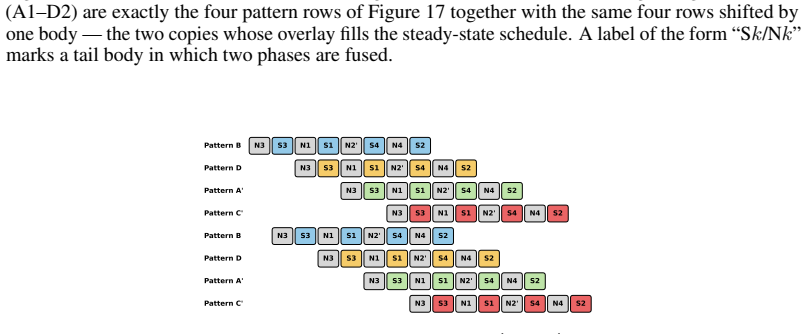
Stage 4 (Allgather):The healthy GPUs allgather the global sums along the ring in p−m−1 hops. The same two stage orderings from Section 4.1 remain valid, and thedisjoint-resourceprinciple still holds: Stages 2/3 use only the straggler NICs while Stages 1/4 use only the healthy ring links. D.2 Schedule Construction We design four patterns—B, D, A ′, C′—anal...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.