HAIM: Human-AI Music Datasets for AI Music Production Tracking Benchmark
Pith reviewed 2026-06-28 13:11 UTC · model grok-4.3
The pith
HAIM dataset enables tracking of specific AI integration stages in music production instead of binary AI-or-human classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
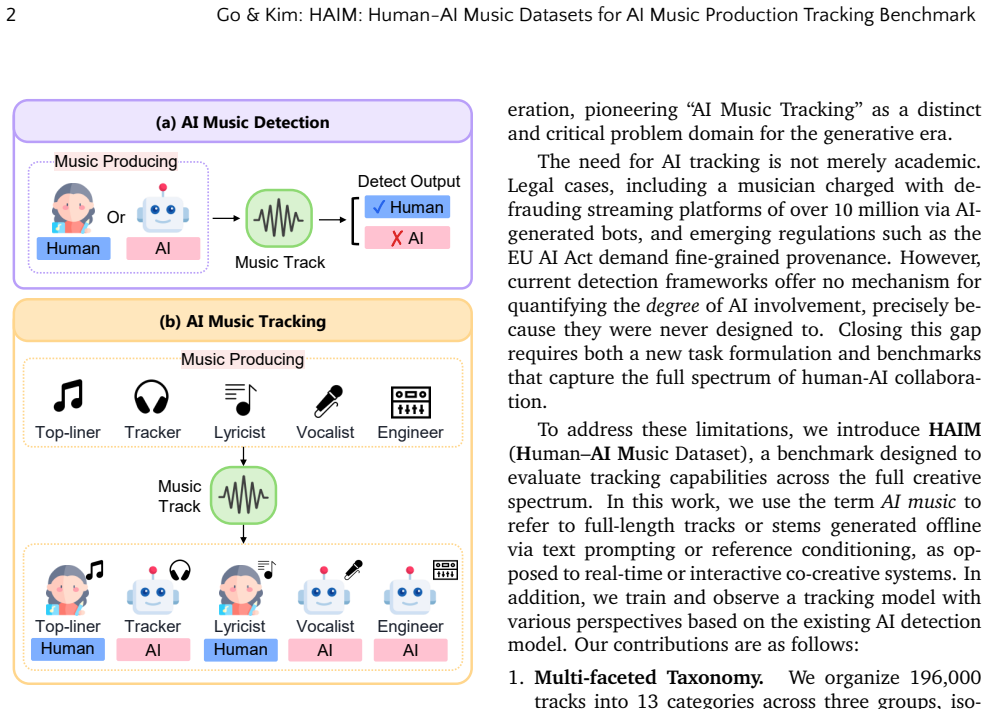
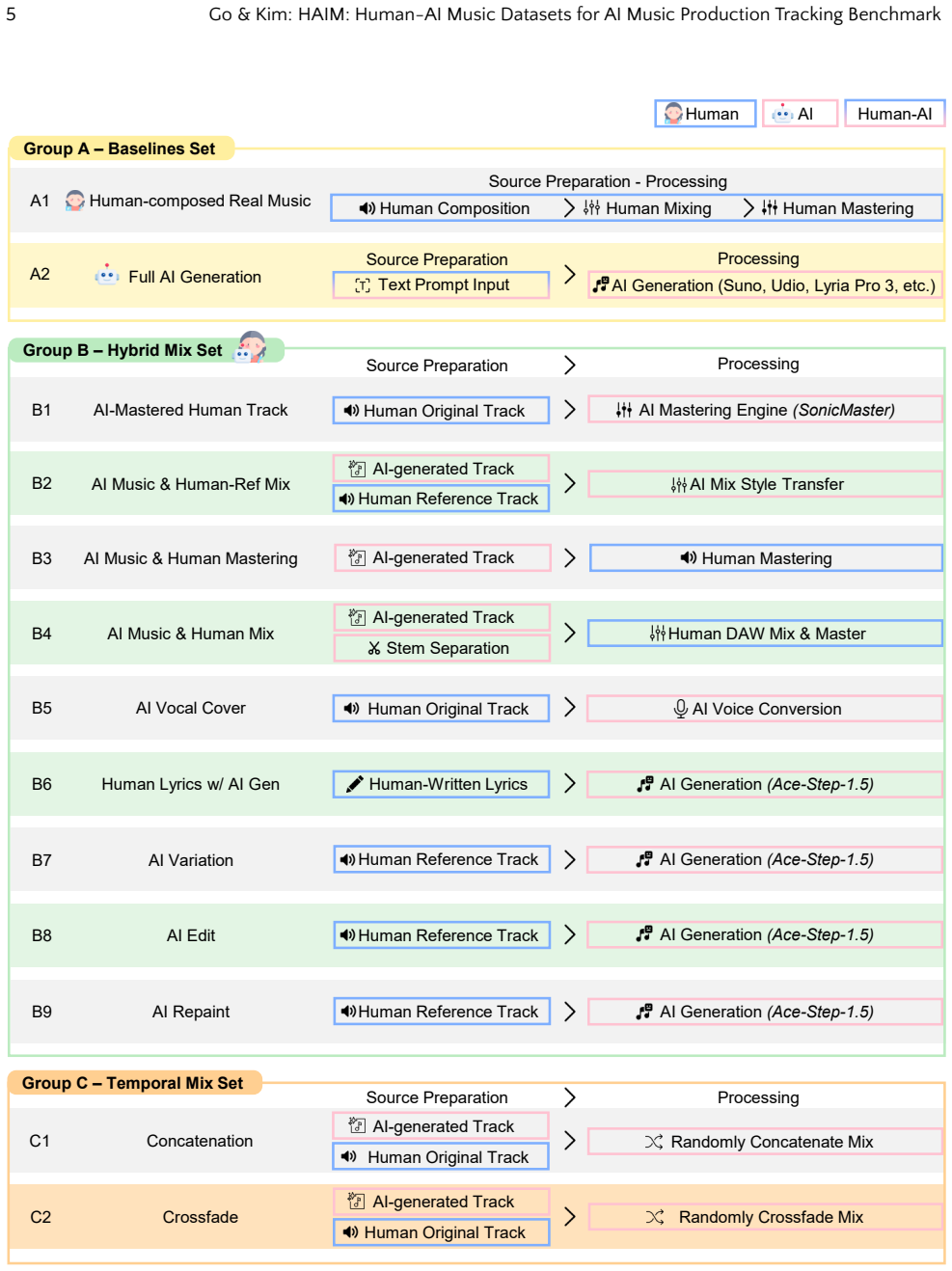
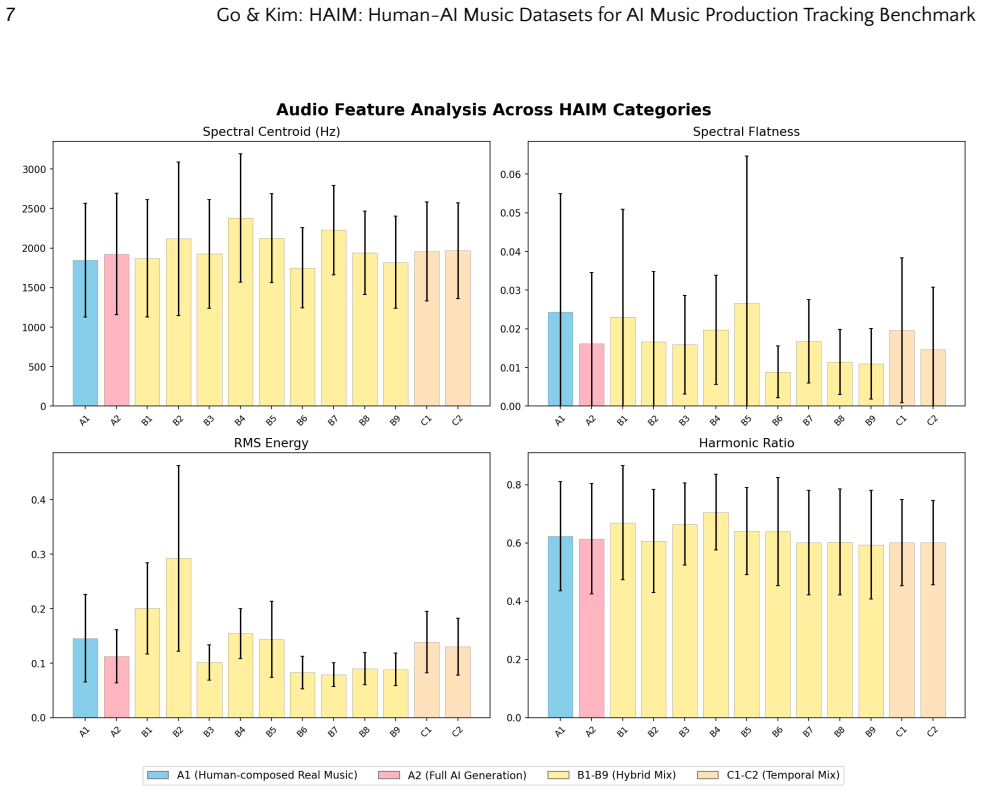
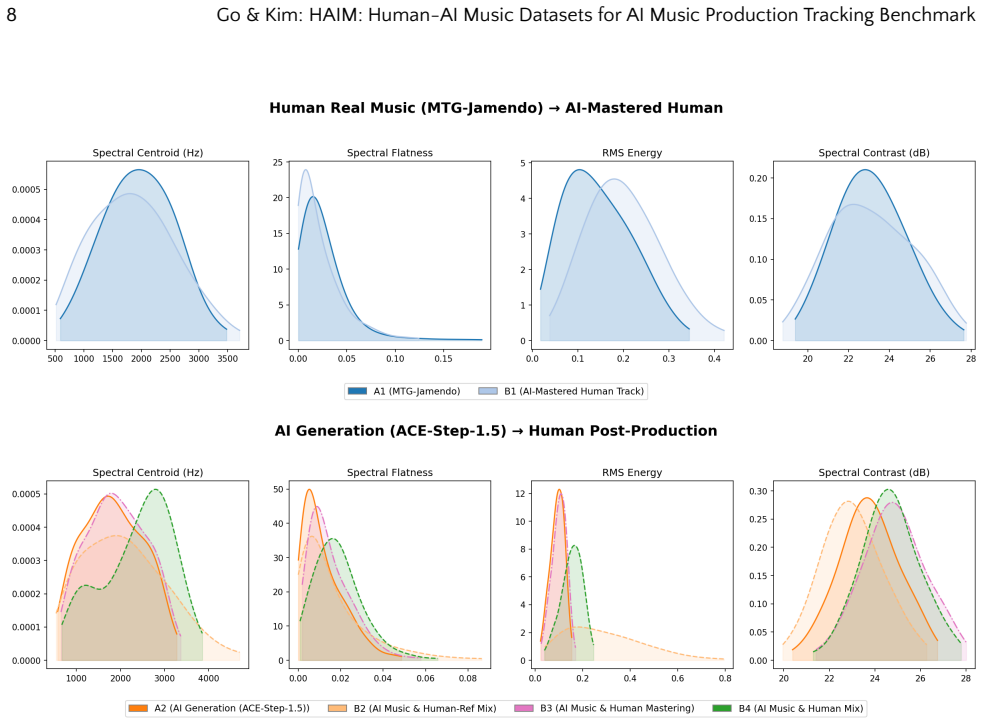
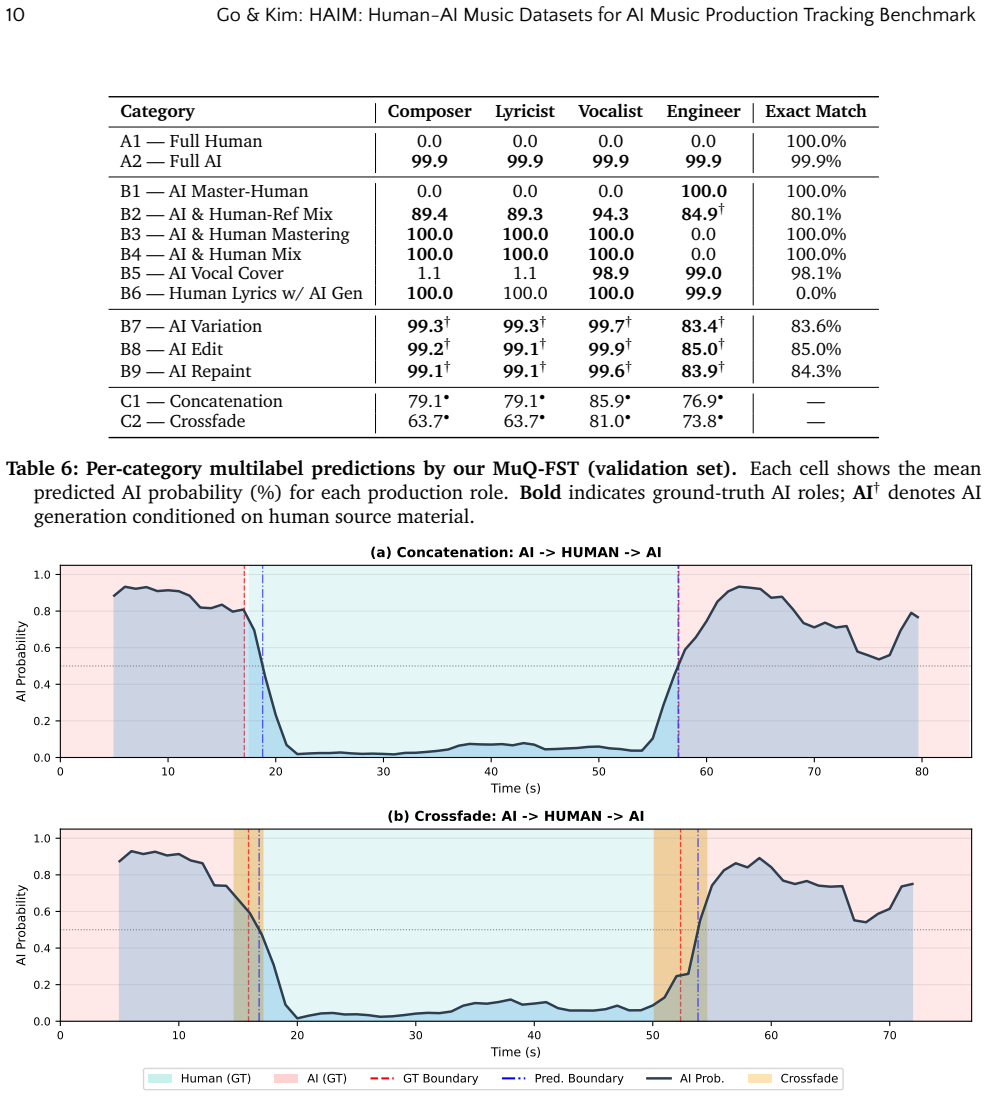
The paper defines AI Music Tracking as the task of identifying specific points of AI intervention across the full music production spectrum and releases HAIM as a dataset containing diverse labels for those stages, including hybrid production and agent-level tracking. When state-of-the-art detectors are tested on HAIM they exhibit systemic flaws that binary classification cannot capture, particularly with adversarial post-processing such as human mastering applied to AI tracks.
What carries the argument
HAIM dataset with labels that isolate stages of AI intervention in music production.
If this is right
- Evaluation metrics must move from overall binary accuracy to per-stage detection performance.
- Detectors will need to handle cases where human mastering is applied to AI-generated material or vice versa.
- Research focus shifts toward identifying AI contributions at specific workflow points such as arrangement or mastering.
- Adversarial tactics that combine AI and human steps become measurable rather than invisible to binary systems.
Where Pith is reading between the lines
- Standardized taxonomies of production stages may become necessary for future datasets and detectors.
- Commercial music platforms could adopt stage-level disclosure requirements once tracking becomes reliable.
- The benchmark opens the possibility of training models that output production-stage probabilities rather than single binary outputs.
Load-bearing premise
The production-stage labels assigned to tracks in HAIM accurately reflect consistent real-world patterns of AI use.
What would settle it
Re-labeling a random subset of HAIM tracks by independent music production experts and measuring low agreement with the original stage labels would show the benchmark does not capture actual integration patterns.
Figures
read the original abstract
As generative platforms such as Suno and Udio reach human-grade audio quality, the scope of AI's utility has expanded across the entire music production workflow. Beyond simple track generation, these advancements have catalyzed the adoption of AI-driven methodologies in diverse forms. These include vocal synthesis, arrangement, and professional mastering. However, current detection research remains largely confined to a binary `AI-or-human' paradigm. It fails to reflect the realities of contemporary music production workflows. In real-world production, AI tools are increasingly used to refine or master human-produced tracks, and human engineers likewise post-process AI-generated material to ensure professional quality. Moreover, users often employ adversarial tactics to bypass AI detectors, such as applying human mastering to AI-generated tracks. This creates a grey area that a simple binary classification fails to capture. In this paper, we define and investigate ``AI Music Tracking'': the challenge of identifying specific AI integration across the multifaceted spectrum of music production. To this end, we introduce HAIM, a dataset with diverse labels for stages of music production. It is designed to isolate stages of AI intervention, including hybrid production and agent-level tracking. Our evaluation of state-of-the-art detectors reveals systemic flaws. By releasing HAIM, we propose a new benchmark that shifts the field beyond binary classification toward a granular, structured evaluation of AI music.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the HAIM dataset, which annotates music tracks with granular labels for stages of AI integration in production workflows (including vocal synthesis, arrangement, mastering, hybrid human-AI, and adversarial post-processing). It evaluates existing state-of-the-art AI music detectors on this benchmark and concludes that they exhibit systemic flaws, proposing HAIM as a new standard that moves the field beyond binary AI-vs-human classification toward structured tracking of specific integration points.
Significance. If the dataset labels prove accurate and representative of real production practices, HAIM could meaningfully advance AI music forensics by enabling evaluation of detectors on realistic hybrid and post-processed cases rather than idealized binary distinctions. The contribution is primarily a dataset and benchmark proposal rather than a new method or theoretical result.
major comments (1)
- [Abstract / Dataset description] The manuscript provides no information on dataset construction, including annotation methodology, source of ground truth for production-stage labels, inter-annotator agreement, expert validation, or any check against actual industry workflows (Abstract and any dataset section). This is load-bearing for the central claim, as the benchmark's ability to demonstrate 'systemic flaws' in detectors and to capture 'grey area' phenomena depends entirely on the labels accurately reflecting real-world AI integration patterns rather than arbitrary categorizations.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of dataset construction details, which are indeed central to validating the benchmark. We agree that additional information is required and will incorporate it in the revision.
read point-by-point responses
-
Referee: [Abstract / Dataset description] The manuscript provides no information on dataset construction, including annotation methodology, source of ground truth for production-stage labels, inter-annotator agreement, expert validation, or any check against actual industry workflows (Abstract and any dataset section). This is load-bearing for the central claim, as the benchmark's ability to demonstrate 'systemic flaws' in detectors and to capture 'grey area' phenomena depends entirely on the labels accurately reflecting real-world AI integration patterns rather than arbitrary categorizations.
Authors: We acknowledge that the manuscript as submitted does not include sufficient detail on dataset construction. In the revised version we will add a dedicated Dataset Construction section that specifies: (1) the annotation protocol and guidelines provided to annotators, (2) the provenance of the ground-truth production-stage labels (including how hybrid and post-processed cases were identified), (3) inter-annotator agreement statistics (Cohen’s kappa or equivalent), (4) any expert validation steps performed, and (5) explicit mapping to documented industry workflows. These additions will directly address the load-bearing concern and allow readers to assess whether the labels reflect realistic AI-integration patterns. revision: yes
Circularity Check
No circularity: dataset release with no derivations or self-referential claims
full rationale
The paper is a dataset and benchmark proposal paper with no equations, fitted parameters, derivation chains, or load-bearing self-citations. Its central contribution is the release of HAIM labels for production stages, and the claim that this enables granular evaluation rests on the dataset itself rather than any reduction to prior inputs or self-defined constructs. No steps match the enumerated circularity patterns; the work is self-contained as an empirical resource release.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Afchar, D., Meseguer-Brocal, G., Akesbi, K., and Hen- nequin, R. (2025a). A fourier explanation of ai- music artifacts.arXiv preprint arXiv:2506.19108
-
[2]
Afchar, D., Meseguer-Brocal, G., and Hennequin, R. (2024). Detecting music deepfakes is easy but ac- tually hard.arXiv preprint arXiv:2405.04181
arXiv 2024
-
[3]
Afchar, D., Meseguer-Brocal, G., and Hennequin, R. (2025b). Ai-generated music detection and its challenges. InICASSP 2025-2025 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE
2025
-
[4]
Baevski, A., Zhou, Y., Mohamed, A., and Auli, M. (2020). wav2vec 2.0: A framework for self- supervised learning of speech representations.Ad- vances in neural information processing systems, 33:12449–12460
2020
-
[5]
Batra, A., Sharma, D., Thukral, K., Bhatia, R., Batra, N., and Gautam, A. (2025). Melody or machine: Detecting synthetic music with dual-stream con- trastive learning.arXiv preprint arXiv:2512.00621
arXiv 2025
-
[6]
Serra, X. (2019). The mtg-jamendo dataset for automatic music tagging. InMachine learning for music discovery workshop, international conference on machine learning (ICML 2019), pages 1–3. Long
2019
-
[7]
Copet, J., Kreuk, F., Gat, I., Remez, T., Kant, D., Syn- naeve, G., Adi, Y., and Défossez, A. (2023). Sim- ple and controllable music generation. volume 36, pages 47704–47720. Deezer (2025). 28% of all delivered music is now fully AI-generated.https://newsroom-deezer. com/2025/09/28-fully-ai-generated-music/. Défossez, A. (2021). Hybrid spectrogram and 13...
arXiv 2023
-
[8]
Schedl, M., and Hennequin, R. (2025). Ai- generated song detection via lyrics transcripts. arXiv preprint arXiv:2506.18488
arXiv 2025
-
[9]
Gong, J., Song, Y., Zhao, W., Wang, S., Xu, S., Guo, J., and Yang, X. (2026). Ace-step 1.5: Pushing the boundaries of open-source music generation.arXiv preprint arXiv:2602.00744. Grötschla, F., Solak, A., Lanzendörfer, L. A., and Wat- tenhofer, R. (2025). Benchmarking music gener- ation models and metrics via human preference studies. InICASSP 2025-2025 ...
arXiv 2026
-
[10]
Kim, H., Jung, J., Jeong, D., and Nam, J. (2024). K- pop lyric translation: Dataset, analysis, and neural- modelling. InProceedings of the 2024 Joint Inter- national Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 9974–9987
2024
-
[11]
Kim, W., Wi, H., Park, S., Kim, T., Keum, S., Kim, K., Kim, T., Jung, J., Kim, T., Guerrero, G., et al. (2025). From generation to attribution: Music ai agent architectures for the post-streaming era. arXiv preprint arXiv:2510.20276
arXiv 2025
- [12]
-
[13]
A., Liao, W.-H., Uhlich, S., Lee, K., and Mitsufuji, Y
Koo, J., Martínez-Ramírez, M. A., Liao, W.-H., Uhlich, S., Lee, K., and Mitsufuji, Y. (2023). Music mixing style transfer: A contrastive learning approach to disentangle audio effects. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE
2023
-
[14]
Li, Y., Yuan, R., Zhang, G., Ma, Y., Chen, X., Yin, H., Xiao, C., Lin, C., Ragni, A., Benetos, E., et al. (2024). Mert: Acoustic music understand- ing model with large-scale self-supervised training. InInternational Conference on Learning Representa- tions, volume 2024, pages 12181–12204. Melechovsky , J., Mehrish, A., Roy , A., and Herremans, D. (2025). ...
Pith/arXiv arXiv 2024
-
[15]
and Xie, S
Peebles, W. and Xie, S. (2023). Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vi- sion, pages 4195–4205
2023
-
[16]
Rahman, A., Hakim, Z. I. A., Sarker, N. H., Paul, B., and Fattah, A. (2025). Sonics: Synthetic or not- identifying counterfeit songs. InInternational Con- ference on Learning Representations, volume 2025, pages 21421–21451. Skywork AI (2024). Mureka: AI music generation plat- form.https://www.mureka.ai
2025
-
[17]
Suno, Inc. (2024). Suno AI music generator.https: //suno.com. Udio (2024). Udio AI music generation platform. https://www.udio.com
2024
-
[18]
C., Sturm, B
Vila, L. C., Sturm, B. L., Casini, L., and Dalmazzo, D. (2025). The ai music arms race: On the detection of ai-generated music.Transactions of the Interna- tional Society for Music Information Retrieval, 8(1)
2025
-
[19]
Zang, Y., Zhang, Y., Heydari, M., and Duan, Z. (2024). Singfake: Singing voice deepfake detec- tion. InICASSP 2024-2024 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP), pages 12156–12160. IEEE
2024
-
[20]
Luo, Y., Tan, W., and Chen, X. (2025). Muq: Self- supervised music representation learning with mel residual vector quantization.IEEE Transactions on
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.