EvoCut: Multi-Layer Evolution-Aware Visual Token Compression for Efficient Large Vision-Language Models
Pith reviewed 2026-06-28 15:39 UTC · model grok-4.3
The pith
EvoCut ranks visual token importance by persistent deviation from group evolution directions across vision-encoder layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
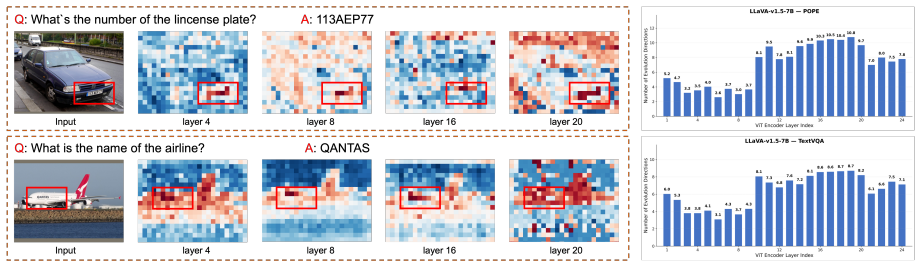
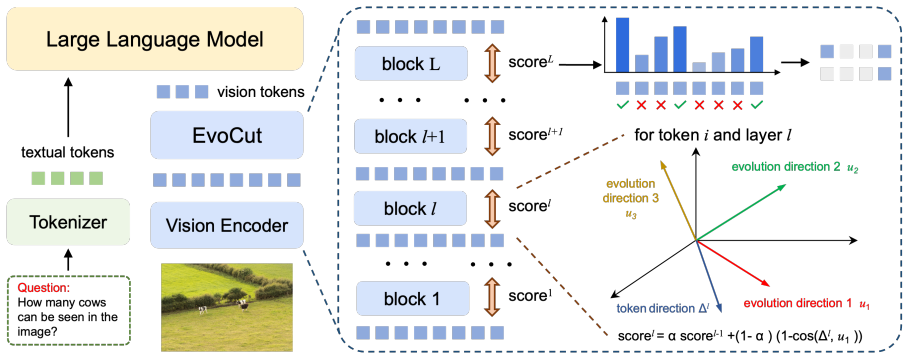
Tokens form multiple group evolution directions across vision-encoder layers, and informative tokens tend to exhibit persistent deviations from common group evolution directions. EvoCut therefore estimates token importance directly from multi-layer evolution deviation, yielding a compression method that retains only 11.1% of the visual tokens on LLaVA-1.5-7B while preserving 94.4% of the average performance.
What carries the argument
Multi-layer evolution deviation, the measure of how persistently each token's change direction differs from the dominant directions taken by groups of tokens through successive layers of the vision encoder.
If this is right
- Token importance ranking works without attention scores or any additional training.
- Retaining 11.1% of tokens preserves 94.4% of average performance on LLaVA-1.5-7B.
- Layer-wise evolution analysis supplies more complete importance estimates than single-layer criteria.
- The same deviation signal applies to both image and video understanding in LVLMs.
Where Pith is reading between the lines
- If the deviation signal proves general, similar layer-tracking could compress tokens in text or audio transformers.
- The method could be stacked with quantization or caching for additional speed-ups on edge devices.
- Observing group evolution directions might offer a new lens for interpreting what each layer of a vision encoder learns.
- Repeating the experiments on larger LVLMs or different vision backbones would test whether the 11.1% retention ratio generalizes.
Load-bearing premise
Informative tokens can be identified solely by their persistent deviation from common group evolution directions across vision-encoder layers, without attention or training.
What would settle it
Compare EvoCut against an attention-based compressor on the same LLaVA model and tasks at identical retention rates; if deviation-based pruning loses noticeably more performance, the premise is challenged.
Figures




read the original abstract
Large vision-language models (LVLMs) achieve strong performance on image and video understanding tasks, but their inference efficiency is constrained by the large number of visual tokens produced by vision encoders. Most existing visual token compression methods estimate token importance from attention scores or representation properties at specific layers, overlooking how visual tokens evolve across the vision encoder. Such layer-specific criteria may provide incomplete importance estimates and limit performance preservation after compression. To address this issue, we analyze layer-wise visual token evolution directions and observe that tokens form multiple group evolution directions across vision-encoder layers. Our analysis further shows that informative tokens tend to exhibit persistent deviations from common group evolution directions. Based on this observation, we propose EvoCut, a training-free and attention-free visual token compression method that estimates token importance from multi-layer evolution deviation. Experimental results show that EvoCut can retain only 11.1\% of the visual tokens on LLaVA-1.5-7B while preserving 94.4\% of the average performance, demonstrating its effectiveness in balancing efficiency and accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EvoCut, a training-free and attention-free visual token compression method for large vision-language models. Based on layer-wise analysis of the vision encoder, it observes that visual tokens form multiple group evolution directions and that informative tokens exhibit persistent deviations from common group directions. Token importance is ranked by multi-layer evolution deviation. On LLaVA-1.5-7B the method retains 11.1% of visual tokens while preserving 94.4% of average performance across evaluated tasks.
Significance. If the empirical result holds under the stated conditions, EvoCut would represent a useful contribution to efficient LVLM inference. The training-free and attention-free design, derived directly from observed token trajectory properties rather than fitted parameters, is a clear strength that could enable broad applicability without additional training overhead. The reported token reduction at high performance retention suggests practical value for deployment scenarios.
major comments (2)
- [§3] §3 (Method): The procedure for identifying group evolution directions and computing per-token deviation across layers is described at a high level but lacks the precise algorithmic steps, distance metric, or clustering approach used to define 'common group evolution directions.' This detail is load-bearing for reproducibility of the central importance-ranking claim.
- [§4.2] §4.2 (Experiments): No ablation isolates the multi-layer component (e.g., single-layer deviation vs. aggregated multi-layer deviation) or varies the number of layers considered. Without this, the specific advantage of the multi-layer formulation over simpler layer-specific baselines remains unquantified, weakening support for the core premise.
minor comments (2)
- [Figure 2] Figure 2: Axis labels and legend entries are too small for readability; consider increasing font size or splitting into multiple panels.
- [Table 1] Table 1: The 'average' performance column should include the number of tasks and standard deviation to allow assessment of consistency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [§3] §3 (Method): The procedure for identifying group evolution directions and computing per-token deviation across layers is described at a high level but lacks the precise algorithmic steps, distance metric, or clustering approach used to define 'common group evolution directions.' This detail is load-bearing for reproducibility of the central importance-ranking claim.
Authors: We agree that the current description in §3 is at a high level and would benefit from greater precision to support reproducibility. In the revised manuscript we will expand this section to specify the exact distance metric for deviation computation, the approach used to identify common group evolution directions, and the full algorithmic steps, including pseudocode for the multi-layer importance ranking. revision: yes
-
Referee: [§4.2] §4.2 (Experiments): No ablation isolates the multi-layer component (e.g., single-layer deviation vs. aggregated multi-layer deviation) or varies the number of layers considered. Without this, the specific advantage of the multi-layer formulation over simpler layer-specific baselines remains unquantified, weakening support for the core premise.
Authors: We acknowledge that an ablation isolating the multi-layer component would strengthen support for the core premise. In the revised manuscript we will add experiments in §4.2 that compare single-layer deviation against the aggregated multi-layer version and that vary the number of layers considered, thereby quantifying the advantage of the multi-layer formulation. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central claim rests on an empirical observation (informative tokens show persistent deviations from group evolution directions across layers) derived from layer-wise analysis, followed by a training-free method built on that observation and validated experimentally. No equations reduce the importance score to a fitted parameter or performance target by construction, no self-citation chains justify uniqueness or ansatzes, and the result is not a renaming of a known pattern. The derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Visual tokens form multiple group evolution directions across vision-encoder layers, and informative tokens exhibit persistent deviations from these directions.
Reference graph
Works this paper leans on
-
[1]
Menick, Sebastian Borgeaud, and 8 others
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob L. Menick, Sebastian Borgeaud, and 8 others. 2022. Flamingo: A visual language model for few-...
2022
-
[2]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-VL : A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, and 8 others. 2025. Qwen2.5-VL technical report. arXiv preprint arXiv:2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, and 12 others. 2020. Language models are few-shot learner...
2020
-
[5]
Ricardo J. G. B. Campello, Davoud Moulavi, and J \"o rg Sander. 2013. Density-based clustering based on hierarchical density estimates. In Advances in Knowledge Discovery and Data Mining, pages 160--172. Springer
2013
-
[6]
Chen and William B
David L. Chen and William B. Dolan. 2011. Collecting highly parallel data for paraphrase evaluation. In Annual Meeting of the Association for Computational Linguistics
2011
-
[7]
Junjie Chen, Xuyang Liu, Zichen Wen, Yiyu Wang, Siteng Huang, and Honggang Chen. 2026. Variation-aware vision token dropping for faster large vision-language models. In IEEE/CVF Conference on Computer Vision and Pattern Recognition
2026
-
[8]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. 2024 a . An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In European Conference on Computer Vision
2024
-
[9]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. 2024 b . InternVL : Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185--24198
2024
-
[10]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven C. H. Hoi. 2023. InstructBLIP : Towards general-purpose vision-language models with instruction tuning. In Advances in Neural Information Processing Systems
2023
-
[11]
Tri Dao. 2023. FlashAttention-2 : Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Fu, Stefano Ermon, Atri Rudra, and Christopher R \'e
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher R \'e . 2022. FlashAttention : Fast and memory-efficient exact attention with IO -awareness. In Advances in Neural Information Processing Systems
2022
-
[13]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations
2021
-
[14]
Yingqi Fan, Anhao Zhao, Jinlan Fu, Junlong Tong, Hui Su, Yijie Pan, Wei Zhang, and Xiaoyu Shen. 2025. VisiPruner : Decoding discontinuous cross-modal dynamics for efficient multimodal LLM s. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 18885--18902
2025
-
[15]
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, and Rongrong Ji. 2023. MME : A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. 2017. Making the V in VQA matter: Elevating the role of image understanding in visual question answering. In IEEE Conference on Computer Vision and Pattern Recognition
2017
-
[17]
Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Barun Patra, Qiang Liu, Kriti Aggarwal, Zewen Chi, Johan Bjorck, Vishrav Chaudhary, Subhojit Som, Xia Song, and Furu Wei. 2023. Language is not all you need: Aligning perception with language models. In Advances in Neural Information Proc...
2023
-
[18]
Hudson and Christopher D
Drew A. Hudson and Christopher D. Manning. 2019. GQA : A new dataset for real-world visual reasoning and compositional question answering. In IEEE Conference on Computer Vision and Pattern Recognition
2019
-
[19]
Yunseok Jang, Yale Song, Youngjae Yu, Youngjin Kim, and Gunhee Kim. 2017. TGIF-QA : Toward spatio-temporal reasoning in visual question answering. In IEEE Conference on Computer Vision and Pattern Recognition
2017
-
[20]
Lei Jiang, Zixun Zhang, Yuting Zeng, Chunzhao Xie, Tongxuan Liu, Zhen Li, Lechao Cheng, and Xiaohua Xu. 2025. DCP : Dual-cue pruning for efficient large vision-language models. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 21191--21204
2025
-
[21]
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. 2023 a . SEED-Bench : Benchmarking multimodal LLM s with generative comprehension. arXiv preprint arXiv:2307.16125
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. 2023 b . BLIP-2 : Bootstrapping language-image pre-training with frozen image encoders and large language models. In International Conference on Machine Learning
2023
-
[23]
Kunchang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. 2023 c . VideoChat : Chat-centric video understanding. arXiv preprint arXiv:2305.06355
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. 2023 d . Evaluating object hallucination in large vision-language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
2023
-
[25]
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. 2023. Video-LLaVA : Learning united visual representation by alignment before projection. arXiv preprint arXiv:2311.10122
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024 a . Improved baselines with visual instruction tuning. arXiv preprint arXiv:2310.03744
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual instruction tuning. In Advances in Neural Information Processing Systems
2023
-
[28]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. 2024 b . MMBench : Is your multi-modal model an all-around player? In European Conference on Computer Vision, pages 216--233
2024
-
[29]
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. 2022. Learn to explain: Multimodal reasoning via thought chains for science question answering. In Advances in Neural Information Processing Systems, pages 2507--2521
2022
- [30]
-
[31]
OpenAI . 2023. GPT-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning
2021
-
[33]
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. 2025. LLaVA-PruMerge : Adaptive token reduction for efficient large multimodal models. In IEEE/CVF International Conference on Computer Vision, pages 22857--22867
2025
-
[34]
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. 2019. Towards VQA models that can read. In IEEE Conference on Computer Vision and Pattern Recognition
2019
-
[35]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothee Lacroix, Baptiste Roziere, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. LLaMA : Open and efficient foundation language models. arXiv preprint arXiv:2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems
2017
-
[37]
Zichen Wen, Yifeng Gao, Shaobo Wang, Junyuan Zhang, Qintong Zhang, Weijia Li, Conghui He, and Linfeng Zhang. 2025. Stop looking for ``important tokens'' in multimodal language models: Duplication matters more. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 9961--9980
2025
-
[38]
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, and Dahua Lin. 2025. PyramidDrop : Accelerating your large vision-language models via pyramid visual redundancy reduction. In IEEE/CVF Conference on Computer Vision and Pattern Recognition
2025
-
[39]
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. 2016. MSR-VTT : A large video description dataset for bridging video and language. In IEEE Conference on Computer Vision and Pattern Recognition
2016
-
[40]
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. 2025. VisionZip : Longer is better but not necessary in vision language models. In IEEE/CVF Conference on Computer Vision and Pattern Recognition
2025
-
[41]
Hang Zhang, Xin Li, and Lidong Bing. 2023. Video-LLaMA : An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, and Shanghang Zhang. 2025. SparseVLM : Visual token sparsification for efficient vision-language model inference. In International Conference on Machine Learning
2025
-
[43]
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. 2023. MiniGPT-4 : Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.