Multilinguality of Large Language Models From a Structural Perspective
Pith reviewed 2026-06-28 14:54 UTC · model grok-4.3
The pith
Low-resource languages are structurally more different from English in LLMs than high- and mid-resource languages, and language-specific post-training changes their structures while keeping inter-language relationships intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
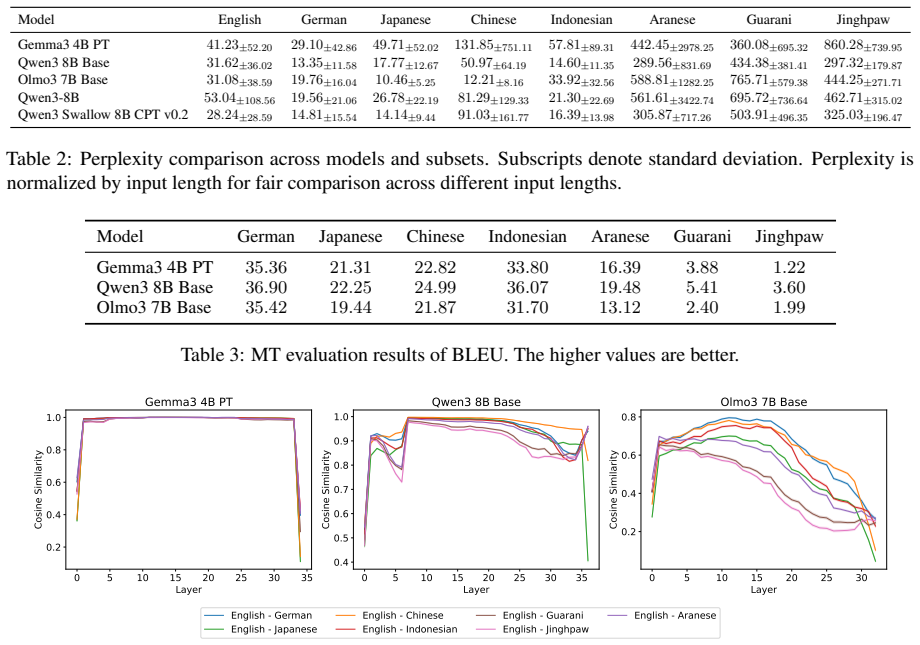
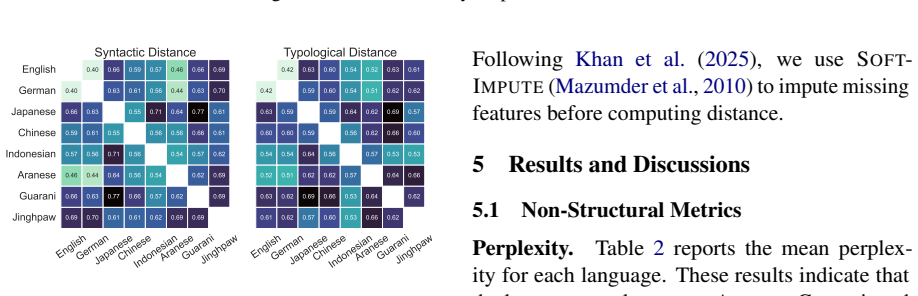
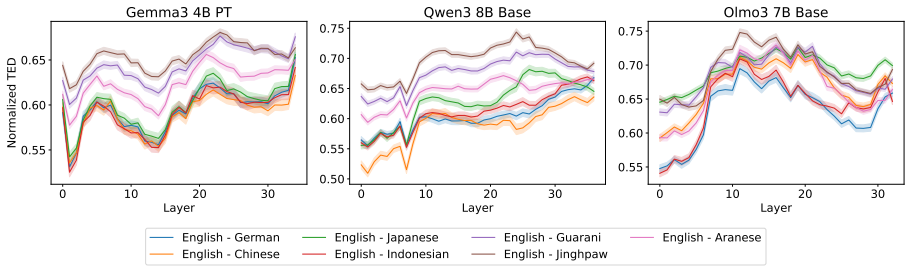
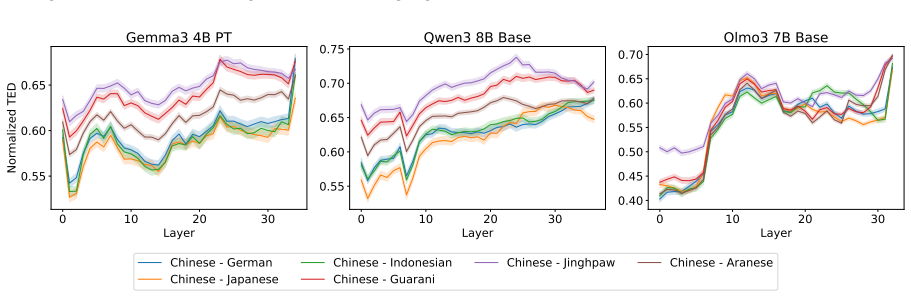
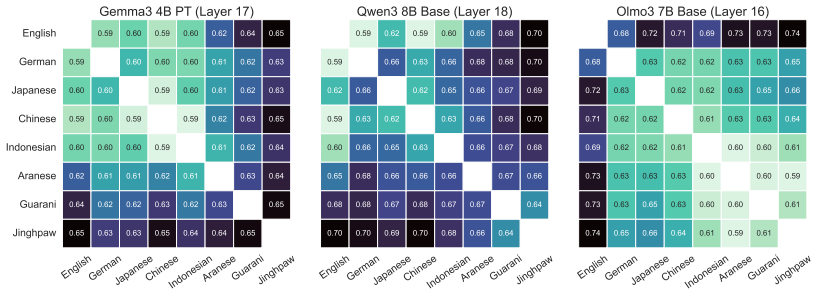
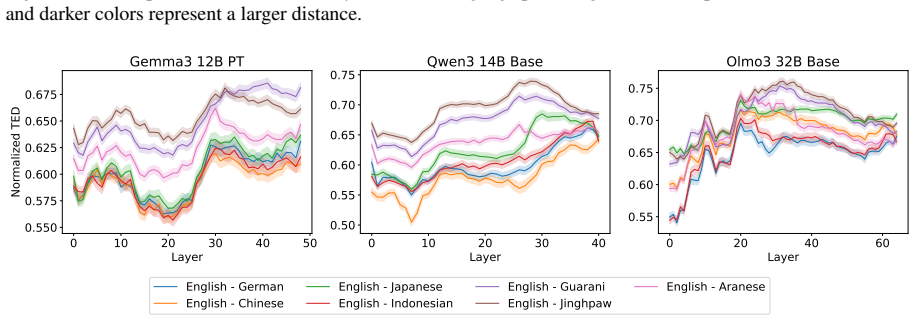
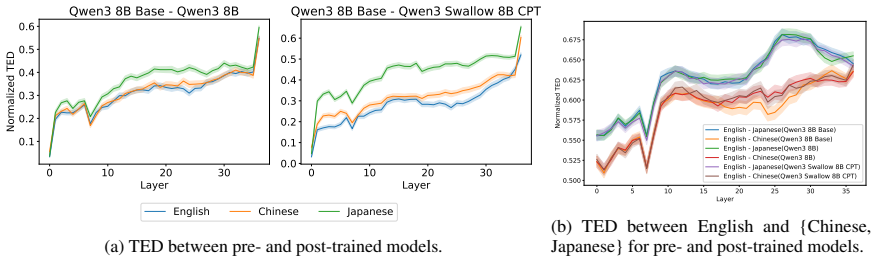
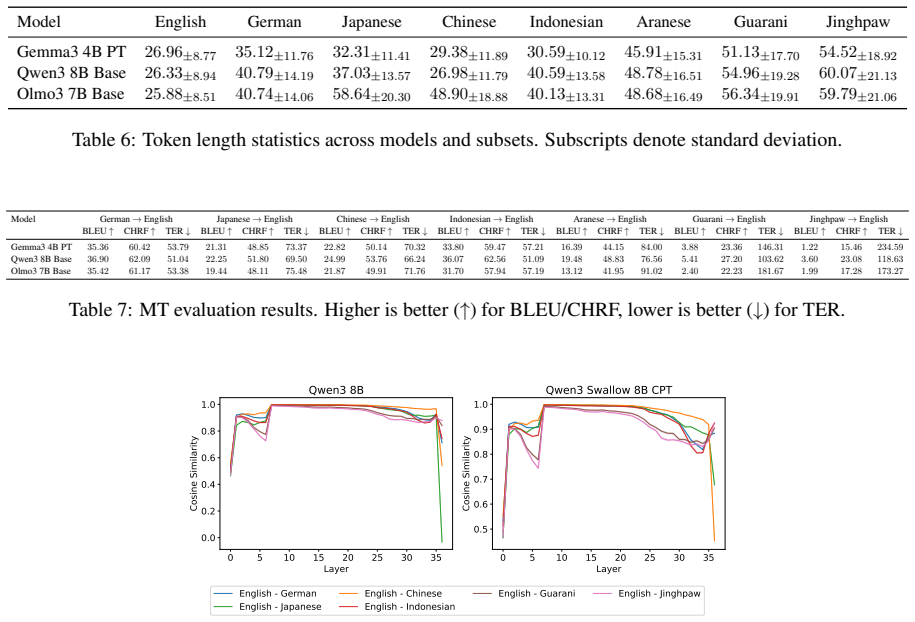
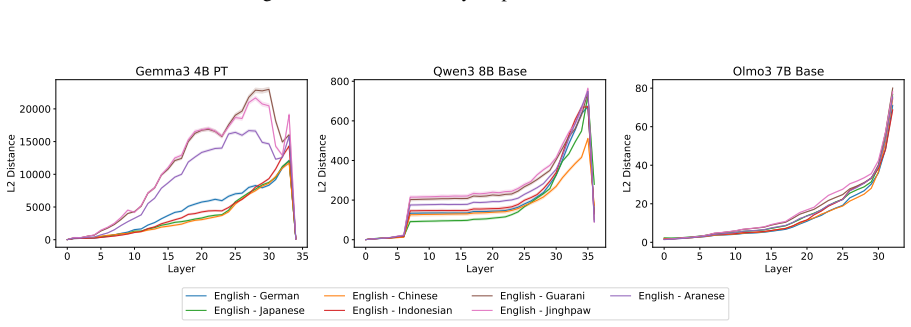
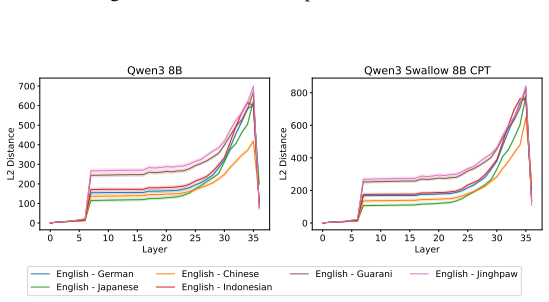
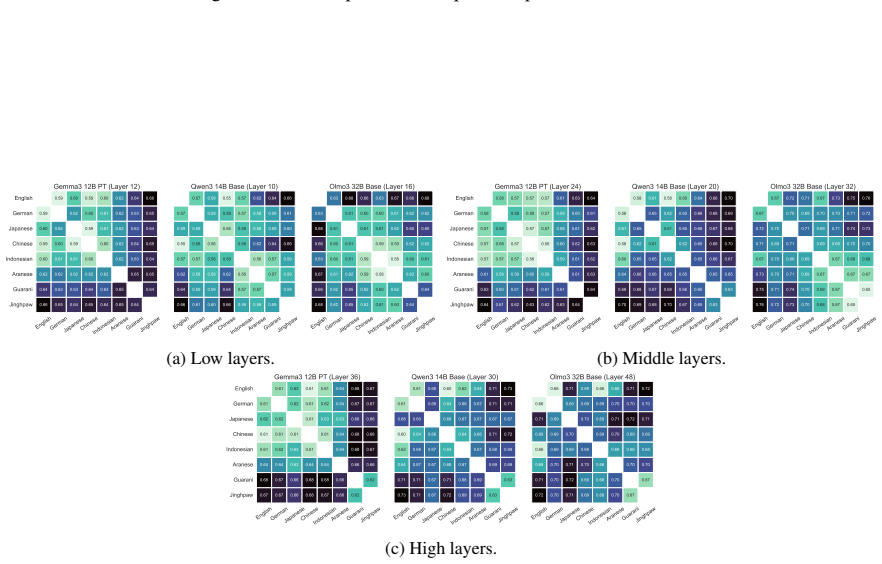
Through representational structural analysis of LLMs, low-resource languages prove structurally more different from English than high- and mid-resource languages, while language-specific post-training alters the structures of the affected languages without disrupting the preserved relationships among languages.
What carries the argument
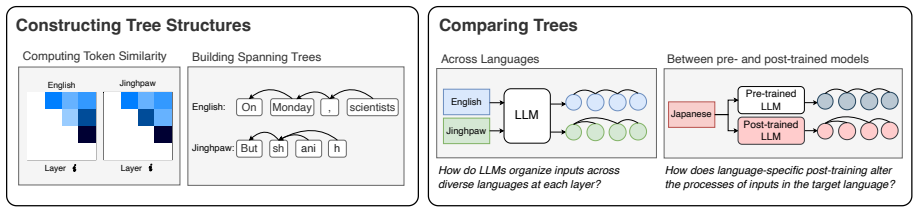
representational structural analysis applied to token representations across languages in LLMs
If this is right
- High-resource languages maintain closer structural alignment to English even when English dominates the pre-training corpus.
- Post-training on one language can be applied without collapsing the cross-lingual structural map that the model learned earlier.
- Structural distance correlates with resource level, suggesting that low-resource languages may need targeted interventions to reduce their separation from the dominant language structure.
- The preservation of inter-language relationships after post-training implies that the model retains a shared multilingual backbone even as individual languages are adjusted.
Where Pith is reading between the lines
- If structural distance predicts downstream performance gaps, then measuring it early could guide which languages need extra data or alignment steps.
- The finding that post-training perturbs local structures while leaving global relationships fixed may extend to other adaptation techniques such as continued pre-training or instruction tuning.
- Alternative structural probes that do not rely on representation geometry could be tested to see whether the resource-based pattern holds under different definitions of structure.
Load-bearing premise
The structural differences detected in the representations reflect genuine properties of the languages rather than artifacts produced by the chosen analysis method or tokenization choices.
What would settle it
Re-running the same structural comparison on the identical models but with an alternative distance measure, such as one derived from syntactic parse trees instead of representation geometry, and finding no greater distance for low-resource languages would undermine the central claim.
Figures




read the original abstract
Large language models (LLMs) have excelled in processing multiple languages through pre- and post-training on multilingual data, even though English dominates the training data. Prior work focusing on token representations has revealed how those LLMs process non-English text. Although these analyses have provided insightful findings, they fail to capture a structural view, which is an inherent property of language. In this study, we explore the multilinguality of LLMs through representational structural analysis. Our findings reveal that low-resource languages are structurally more different from English than high- and mid-resource languages, and that language-specific post-training alters their structures while preserving inter-language relationships.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that representational structural analysis of LLMs reveals low-resource languages to be structurally more different from English than high- and mid-resource languages, and that language-specific post-training alters these structures while preserving inter-language relationships. The work positions this structural view as an advance over prior token-representation analyses.
Significance. If the structural findings prove robust to confounds, the work would supply a useful complement to token-level studies of multilingual LLMs, potentially guiding post-training strategies that respect language-specific geometry while maintaining cross-lingual alignments. The emphasis on resource-level structural gaps is a concrete, testable contribution.
major comments (3)
- [§4] §4 (Experimental Setup / Representational Structural Analysis): No controls are described for tokenization quality, subword fragmentation, or sequence-length matching across resource tiers. Because low-resource languages are tokenized more poorly by English-dominant vocabularies, any observed geometric differences could arise from embedding sparsity or length effects rather than syntax or semantics; this directly undermines the claim that the analysis isolates 'inherent structural properties.'
- [§5] §5 (Results): The statement that post-training 'alters their structures while preserving inter-language relationships' is presented without quantitative metrics (e.g., before/after correlation of pairwise distances or Procrustes alignment scores). Without these numbers it is impossible to judge whether the preservation is substantive or merely qualitative.
- [Abstract / §3] Abstract and §3: The manuscript supplies no error analysis, statistical tests comparing resource-level groups, or ablation on the distance metric itself. The central claim therefore rests on unvalidated differences whose magnitude and reliability cannot be assessed from the reported material.
minor comments (2)
- [Methods] Notation for the structural metric (e.g., what distance is computed on which hidden states) is introduced without a formal definition or reference to prior work on representational similarity analysis.
- [Figures] Figure captions do not state the exact number of languages per resource bucket or the model variants used, reducing reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each of the major concerns below and commit to revisions that will strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup / Representational Structural Analysis): No controls are described for tokenization quality, subword fragmentation, or sequence-length matching across resource tiers. Because low-resource languages are tokenized more poorly by English-dominant vocabularies, any observed geometric differences could arise from embedding sparsity or length effects rather than syntax or semantics; this directly undermines the claim that the analysis isolates 'inherent structural properties.'
Authors: We agree that the lack of controls for tokenization and sequence length represents a potential confound in our current analysis. The manuscript does not describe such controls, and we will revise §4 to include them. Specifically, we will add experiments that match sequence lengths across languages and control for subword fragmentation by reporting results on a subset of languages with similar tokenization efficiency. This will help confirm that the observed structural differences are not solely due to these factors. revision: yes
-
Referee: [§5] §5 (Results): The statement that post-training 'alters their structures while preserving inter-language relationships' is presented without quantitative metrics (e.g., before/after correlation of pairwise distances or Procrustes alignment scores). Without these numbers it is impossible to judge whether the preservation is substantive or merely qualitative.
Authors: The referee correctly identifies that our claim about preservation of inter-language relationships after post-training lacks quantitative backing in the current manuscript. We will add the suggested metrics in the revised §5, including before-and-after Procrustes alignment scores and correlations of pairwise distance matrices to provide a quantitative assessment of how much the relationships are preserved. revision: yes
-
Referee: [Abstract / §3] Abstract and §3: The manuscript supplies no error analysis, statistical tests comparing resource-level groups, or ablation on the distance metric itself. The central claim therefore rests on unvalidated differences whose magnitude and reliability cannot be assessed from the reported material.
Authors: We acknowledge the absence of statistical tests, error analysis, and metric ablations in the manuscript. To address this, we will incorporate these elements into the revised version: statistical significance tests for differences between resource tiers, error bars on the reported distances, and an ablation study varying the distance metric to show that the main findings hold across reasonable choices. revision: yes
Circularity Check
No circularity detected from available text
full rationale
The abstract presents empirical findings from representational structural analysis on LLM hidden states without any equations, fitted parameters, self-citations, or derivation steps that reduce to inputs by construction. No load-bearing claims rely on renaming, ansatz smuggling, or uniqueness theorems from prior author work. The central observation (low-resource languages structurally more different) is stated as an analysis outcome rather than a tautology or statistically forced prediction, making the paper self-contained against external benchmarks in the provided material.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 37th International Conference on Machine Learning , url =
Xiong, Ruibin and Yang, Yunchang and He, Di and Zheng, Kai and Zheng, Shuxin and Xing, Chen and Zhang, Huishuai and Lan, Yanyan and Wang, Liwei and Liu, Tie-Yan , title =. Proceedings of the 37th International Conference on Machine Learning , url =. 2020 , publisher =
2020
-
[2]
and Kaiser,
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser,. Attention Is All You Need , booktitle =. 2017 , month = dec, series =
2017
-
[3]
2021 , urldate =
Elhage, Nelson and Nanda, Neel and Olsson, Catherine and Henighan, Tom and Joseph, Nicholas and Mann, Ben and Askell, Amanda and Bai, Yuntao and Chen, Anna and Conerly, Tom and DasSarma, Nova and Drain, Dawn and Ganguli, Deep and Hatfield-Dodds, Zac and Hernandez, Danny and Jones, Andy and Kernion, Jackson and Lovitt, Liane and Ndousse, Kamal and Amodei, ...
2021
-
[4]
2025 , eprint=
Diversity of Transformer Layers: One Aspect of Parameter Scaling Laws , author=. 2025 , eprint=
2025
-
[5]
2026 , eprint=
StructLens: A Structural Lens for Language Models via Maximum Spanning Trees , author=. 2026 , eprint=
2026
-
[6]
What Language Do Non- E nglish-Centric Large Language Models Think in?
Zhong, Chengzhi and Liu, Qianying and Cheng, Fei and Jiang, Junfeng and Wan, Zhen and Chu, Chenhui and Murawaki, Yugo and Kurohashi, Sadao. What Language Do Non- E nglish-Centric Large Language Models Think in?. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1350
-
[7]
Do Llamas Work in E nglish? On the Latent Language of Multilingual Transformers
Wendler, Chris and Veselovsky, Veniamin and Monea, Giovanni and West, Robert. Do Llamas Work in E nglish? On the Latent Language of Multilingual Transformers. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.820
-
[8]
2020 , month = Aug, urldate =
Interpreting. 2020 , month = Aug, urldate =
2020
-
[9]
Brinkmann, Jannik and Wendler, Chris and Bartelt, Christian and Mueller, Aaron. Large Language Models Share Representations of Latent Grammatical Concepts Across Typologically Diverse Languages. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1:...
-
[10]
The Thirteenth International Conference on Learning Representations , year=
The Same but Different: Structural Similarities and Differences in Multilingual Language Modeling , author=. The Thirteenth International Conference on Learning Representations , year=
-
[11]
and Tu, Zhuowen and Bergen, Benjamin K
Chang, Tyler A. and Tu, Zhuowen and Bergen, Benjamin K. The Geometry of Multilingual Language Model Representations. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.9
-
[12]
Trans-Tokenization and Cross-lingual Vocabulary Transfers: Language Adaptation of
Fran. Trans-Tokenization and Cross-lingual Vocabulary Transfers: Language Adaptation of. First Conference on Language Modeling , year=
-
[13]
Sakajo, Haruki and Ide, Yusuke and Vasselli, Justin and Sakai, Yusuke and Tian, Yingtao and Kamigaito, Hidetaka and Watanabe, Taro. Dictionaries to the Rescue: Cross-Lingual Vocabulary Transfer for Low-Resource Languages Using Bilingual Dictionaries. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1333
-
[14]
Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models
Tang, Tianyi and Luo, Wenyang and Huang, Haoyang and Zhang, Dongdong and Wang, Xiaolei and Zhao, Xin and Wei, Furu and Wen, Ji-Rong. Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1...
-
[15]
Tarjan, R. E. , year =. Finding optimum branchings , volume =. Networks , publisher =. doi:10.1002/net.3230070103 , number =
-
[16]
Simple Fast Algorithms for the Editing Distance Between Trees and Related Problems , volume =
Zhang, Kaizhong and Shasha, Dennis , year =. Simple Fast Algorithms for the Editing Distance Between Trees and Related Problems , volume =. SIAM J. Comput. , doi =
-
[17]
Tree edit distance: Robust and memory-efficient , journal =
Mateusz Pawlik and Nikolaus Augsten , keywords =. Tree edit distance: Robust and memory-efficient , journal =. 2016 , issn =. doi:https://doi.org/10.1016/j.is.2015.08.004 , url =
-
[18]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[19]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[20]
2025 , eprint=
Olmo 3 , author=. 2025 , eprint=
2025
-
[21]
Continual Pre-Training for Cross-Lingual
Kazuki Fujii and Taishi Nakamura and Mengsay Loem and Hiroki Iida and Masanari Ohi and Kakeru Hattori and Hirai Shota and Sakae Mizuki and Rio Yokota and Naoaki Okazaki , booktitle=. Continual Pre-Training for Cross-Lingual. 2024 , url=
2024
-
[22]
NLLB Team and Costa-juss \`a , Marta R. and Cross, James and C elebi, Onur and Elbayad, Maha and Heafield, Kenneth and Heffernan, Kevin and Kalbassi, Elahe and Lam, Janice and Licht, Daniel and Maillard, Jean and Sun, Anna and Wang, Skyler and Wenzek, Guillaume and Youngblood, Al and Akula, Bapi and Barrault, Loic and Gonzalez, Gabriel Mejia and Hansanti,...
-
[23]
Languages Still Left Behind: Toward a Better Multilingual Machine Translation Benchmark
Taguchi, Chihiro and Mai, Seng and Kurabe, Keita and Sakai, Yusuke and Agyei, Georgina and Eslami, Soudabeh and Chiang, David. Languages Still Left Behind: Toward a Better Multilingual Machine Translation Benchmark. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1018
-
[24]
Kurabe, Keita , title =. 2020 , isbn =. doi:https://doi.org/10.15026/125363
-
[25]
Kurabe, Keita , title =. 2020
2020
-
[26]
doi:https://dx.doi.org/10.4225/72/59888e8ab2122 , year=
Kachin folktales told in. doi:https://dx.doi.org/10.4225/72/59888e8ab2122 , year=
-
[27]
Kachin culture and history told in
Kurabe, Keita , year=. Kachin culture and history told in
-
[28]
doi: 10.18653/v1/2020.emnlp-demos.6
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and Davison, Joe and Shleifer, Sam and von Platen, Patrick and Ma, Clara and Jernite, Yacine and Plu, Julien and Xu, Canwen and Le Scao, Teven and Gugger, Sylvain and Drame, M...
-
[29]
Bleu: a method for automatic evaluation of machine translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. B leu: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002. doi:10.3115/1073083.1073135
-
[30]
Post, Matt. A Call for Clarity in Reporting BLEU Scores. Proceedings of the Third Conference on Machine Translation: Research Papers. 2018. doi:10.18653/v1/W18-6319
-
[31]
chr F : character n-gram F -score for automatic MT evaluation
Popovi \'c , Maja. chr F : character n-gram F -score for automatic MT evaluation. Proceedings of the Tenth Workshop on Statistical Machine Translation. 2015. doi:10.18653/v1/W15-3049
-
[32]
A Study of Translation Edit Rate with Targeted Human Annotation
Snover, Matthew and Dorr, Bonnie and Schwartz, Rich and Micciulla, Linnea and Makhoul, John. A Study of Translation Edit Rate with Targeted Human Annotation. Proceedings of the 7th Conference of the Association for Machine Translation in the Americas: Technical Papers. 2006
2006
-
[33]
and Khiu, Eric and Do
Khan, Aditya and Shipton, Mason and Anugraha, David and Duan, Kaiyao and Hoang, Phuong H. and Khiu, Eric and Do. URIEL +: Enhancing Linguistic Inclusion and Usability in a Typological and Multilingual Knowledge Base. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[34]
Representational Isomorphism and Alignment of Multilingual Large Language Models
Wu, Di and Lei, Yibin and Yates, Andrew and Monz, Christof. Representational Isomorphism and Alignment of Multilingual Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.823
-
[35]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[36]
Minixhofer, Benjamin and Paischer, Fabian and Rekabsaz, Navid. WECHSEL : Effective initialization of subword embeddings for cross-lingual transfer of monolingual language models. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2022. doi:10.18653/v1/2022.naacl-main.293
-
[37]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Zero-Shot Tokenizer Transfer , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[38]
An Empirical Study on Cross-lingual Vocabulary Adaptation for Efficient Language Model Inference
Yamaguchi, Atsuki and Villavicencio, Aline and Aletras, Nikolaos. An Empirical Study on Cross-lingual Vocabulary Adaptation for Efficient Language Model Inference. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.396
-
[39]
Computational Linguistics , volume =
Yamaguchi, Atsuki and Villavicencio, Aline and Aletras, Nikolaos , title =. Computational Linguistics , volume =. 2026 , month =. doi:10.1162/COLI.a.581 , url =
-
[40]
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Zhu, Wenhao and Liu, Hongyi and Dong, Qingxiu and Xu, Jingjing and Huang, Shujian and Kong, Lingpeng and Chen, Jiajun and Li, Lei. Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.176
-
[41]
2024 , url=
Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan , booktitle=. 2024 , url=
2024
-
[42]
Linguistic Typology
Song, Jae Jung. Linguistic Typology
-
[43]
Language, Usage and Cognition , publisher=
Bybee, Joan , year=. Language, Usage and Cognition , publisher=
-
[44]
2013 , doi =
WALS Online (v2020.4) , type =. 2013 , doi =
2013
-
[45]
doi:10.14324/111.9781787352872 , publisher =
A Grammar of Paraguayan Guarani , author =. doi:10.14324/111.9781787352872 , publisher =
-
[46]
2015 , publisher=
Gramatica basica der occitan aran. 2015 , publisher=
2015
-
[47]
Toossi, Hasti and Huai, Guo and Liu, Jinyu and Khiu, Eric and Do. A Reproducibility Study on Quantifying Language Similarity: The Impact of Missing Values in the URIEL Knowledge Base. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 4: Student Research Wo...
-
[48]
Mazumder, Rahul and Hastie, Trevor and Tibshirani, Robert , title =. J. Mach. Learn. Res. , month = aug, pages =. 2010 , issue_date =
2010
-
[49]
The Eleventh International Conference on Learning Representations , year=
Language models are multilingual chain-of-thought reasoners , author=. The Eleventh International Conference on Learning Representations , year=
-
[50]
Language Models are Few-shot Multilingual Learners
Winata, Genta Indra and Madotto, Andrea and Lin, Zhaojiang and Liu, Rosanne and Yosinski, Jason and Fung, Pascale. Language Models are Few-shot Multilingual Learners. Proceedings of the 1st Workshop on Multilingual Representation Learning. 2021. doi:10.18653/v1/2021.mrl-1.1
-
[51]
Extending Multilingual BERT to Low-Resource Languages
Wang, Zihan and K, Karthikeyan and Mayhew, Stephen and Roth, Dan. Extending Multilingual BERT to Low-Resource Languages. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.240
-
[52]
Global MMLU : Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation
Singh, Shivalika and Romanou, Angelika and Fourrier, Cl \'e mentine and Adelani, David Ifeoluwa and Ngui, Jian Gang and Vila-Suero, Daniel and Limkonchotiwat, Peerat and Marchisio, Kelly and Leong, Wei Qi and Susanto, Yosephine and Ng, Raymond and Longpre, Shayne and Ruder, Sebastian and Ko, Wei-Yin and Bosselut, Antoine and Oh, Alice and Martins, Andre a...
-
[53]
MMLU - P ro X : A Multilingual Benchmark for Advanced Large Language Model Evaluation
Xuan, Weihao and Yang, Rui and Qi, Heli and Zeng, Qingcheng and Xiao, Yunze and Feng, Aosong and Liu, Dairui and Xing, Yun and Wang, Junjue and Gao, Fan and Lu, Jinghui and Jiang, Yuang and Li, Huitao and Li, Xin and Yu, Kunyu and Dong, Ruihai and Gu, Shangding and Li, Yuekang and Xie, Xiaofei and Juefei-Xu, Felix and Khomh, Foutse and Yoshie, Osamu and C...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.