ROGLE: Robust Global-Local Alignment with Automated Region Supervision for Text-Based Person Search
Pith reviewed 2026-06-28 15:16 UTC · model grok-4.3
The pith
ROGLE uses automated region-to-sentence matching to deliver fine-grained supervision and multi-granular alignment for text-based person search without manual annotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
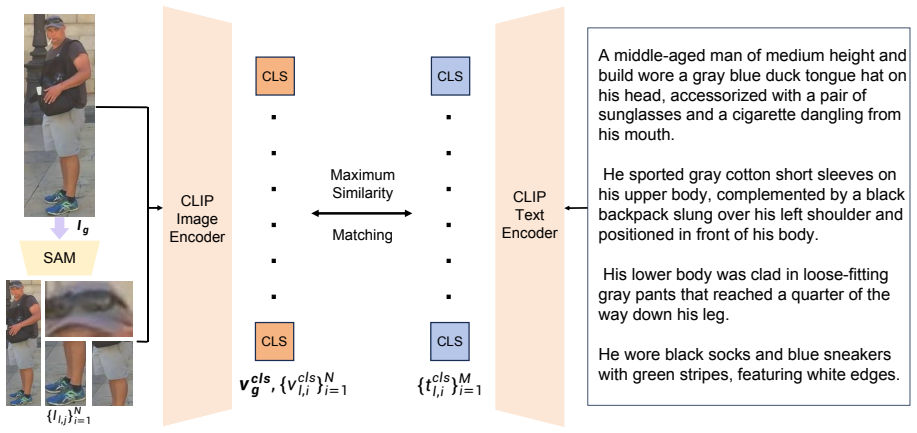
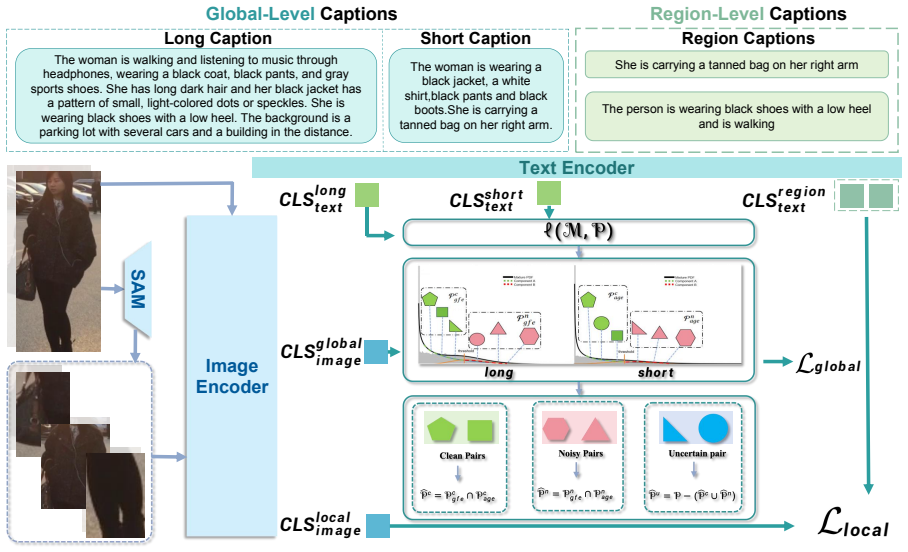
ROGLE overcomes reliance on manual region annotations by automatically mining pseudo region-sentence pairs through Region-to-Sentence Matching, then applies a multi-granular learning strategy that combines global contrastive learning with region-level local alignment. When evaluated on the new P-VLG benchmark, which supplies over 100,000 annotated regions and rich long-form captions, the resulting model significantly outperforms prior TBPS methods, with the largest gains on challenging long-form queries.
What carries the argument
The automated Region-to-Sentence Matching (RSM) strategy that produces pseudo region-sentence pairs for scalable fine-grained supervision, integrated with multi-granular learning that fuses global and local alignment.
If this is right
- TBPS retrieval accuracy improves most on long-form natural language queries that require region-level detail.
- Fine-grained alignment becomes feasible without collecting additional manual region annotations.
- A single framework can jointly optimize global contrastive objectives and local region-sentence alignment.
- The P-VLG benchmark enables standardized testing of both global and local protocols on the same data.
Where Pith is reading between the lines
- The same automated matching approach could be tested on other vision-language retrieval tasks that currently lack region-level labels.
- If the pseudo pairs remain reliable at larger scale, the method may reduce the annotation burden across multimodal datasets.
- Models trained this way might generalize better to real-world queries that mix global scene descriptions with specific attribute mentions.
Load-bearing premise
The automated Region-to-Sentence Matching produces pseudo region-sentence pairs whose quality and noise level are sufficient to deliver effective fine-grained supervision.
What would settle it
Removing the Region-to-Sentence Matching component or replacing its pseudo pairs with random region-sentence pairs would eliminate the reported performance gains on long-form queries.
Figures


read the original abstract
Text-Based Person Search (TBPS) aims to retrieve pedestrian images using natural language queries. However, existing TBPS models, especially those based on CLIP, struggle with fine-grained understanding due to global representational bias and semantic sparsity inherited from training on short captions. This results in weak fine-grained alignment, exacerbated by the scarcity of region-level annotations. To address this, we propose ROGLE (Robust Global-Local Embedding), a unified framework that overcomes reliance on costly manual annotations through an automated Region-to-Sentence Matching (RSM) strategy. RSM automatically mines pseudo region-sentence pairs for scalable fine-grained supervision. Furthermore, ROGLE employs a multi-granular learning strategy that fuses global contrastive learning with region-level local alignment. We also introduce the P-VLG Benchmark, a large-scale dataset constructed by curating and enriching images from established public benchmarks. It features over 100,000 annotated regions and rich long-form captions, making it the first TBPS benchmark to support both global and local assessment protocols. Extensive experiments show that ROGLE significantly outperforms existing approaches, particularly on challenging long-form queries. Code and the P-VLG benchmark will be made publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ROGLE, a framework for text-based person search (TBPS) that employs an automated Region-to-Sentence Matching (RSM) strategy to mine pseudo region-sentence pairs for scalable fine-grained supervision without manual annotations. It combines this with multi-granular learning fusing global contrastive and region-level local alignment, introduces the P-VLG benchmark (over 100k annotated regions and long-form captions), and reports significant outperformance over existing methods, especially on long-form queries.
Significance. If the automated RSM produces sufficiently low-noise pseudo pairs, the approach could meaningfully advance TBPS by mitigating global bias in CLIP-based models and the scarcity of region annotations. The P-VLG benchmark supporting both global and local protocols, along with the planned public release of code and data, represents a concrete contribution to the field.
major comments (2)
- [Abstract and RSM description] The central claim that RSM supplies effective fine-grained supervision (Abstract) is load-bearing, yet the manuscript provides no direct measurement of pseudo-pair quality such as precision, recall, noise rate, or human audit; without this, it is unclear whether reported gains on long-form queries derive from the local alignment or from the global contrastive term.
- [Experiments section] No ablation isolating the RSM-enabled local alignment (e.g., comparison against random pseudo pairs or removal of the region-level term) is described in the experiments, leaving open the possibility that performance improvements stem from other unablated components or benchmark statistics.
minor comments (1)
- [Method] Notation for multi-granular fusion and P-VLG construction could be clarified with explicit equations or pseudocode.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested analyses.
read point-by-point responses
-
Referee: [Abstract and RSM description] The central claim that RSM supplies effective fine-grained supervision (Abstract) is load-bearing, yet the manuscript provides no direct measurement of pseudo-pair quality such as precision, recall, noise rate, or human audit; without this, it is unclear whether reported gains on long-form queries derive from the local alignment or from the global contrastive term.
Authors: We agree that direct measurements of pseudo-pair quality (e.g., precision, noise rate via human audit) are absent from the current manuscript and would strengthen the central claim. In revision we will add a dedicated analysis subsection reporting these metrics on a sampled subset of RSM pairs. This will help clarify whether gains on long-form queries arise primarily from the region-level term. We note that indirect evidence already exists via the P-VLG local-protocol results and comparisons to global-only baselines, but the requested quantitative audit will make the contribution explicit. revision: yes
-
Referee: [Experiments section] No ablation isolating the RSM-enabled local alignment (e.g., comparison against random pseudo pairs or removal of the region-level term) is described in the experiments, leaving open the possibility that performance improvements stem from other unablated components or benchmark statistics.
Authors: We acknowledge that the current experiments section lacks explicit ablations isolating the RSM component (e.g., random pseudo pairs or ablation of the region-level loss). In the revised version we will insert these controlled experiments, including a random-pair baseline and a global-only variant, to quantify the incremental benefit of the automated local supervision and rule out confounding factors from the benchmark or other modules. revision: yes
Circularity Check
No significant circularity; derivation introduces independent components
full rationale
The manuscript proposes ROGLE as a new framework relying on an automated Region-to-Sentence Matching (RSM) strategy for pseudo pair generation, multi-granular learning that combines global contrastive and local alignment terms, and the newly constructed P-VLG benchmark. No equations, claims, or results are shown to reduce by construction to fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations whose validity depends on the current work. The abstract and method description present the RSM and alignment strategy as novel contributions whose effectiveness is evaluated via downstream retrieval metrics rather than by tautological redefinition. This matches the default expectation that most papers are non-circular when the central claims rest on externally testable components rather than internal reparameterization.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yang Bai, Min Cao, Daming Gao, Ziqiang Cao, Chen Chen, Zhenfeng Fan, Liqiang Nie, and Min Zhang. 2023. Rasa: relation and sensitivity aware representation learning for text-based person search. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, pages 555--563
2023
-
[2]
Min Cao, Yang Bai, Ziyin Zeng, Mang Ye, and Min Zhang. 2024. An empirical study of clip for text-based person search
2024
-
[4]
Zefeng Ding, Changxing Ding, Zhiyin Shao, and Dacheng Tao. 2021. Semantically self-aligned network for text-to-image part-aware person re-identification. arXiv preprint arXiv:2107.12666
arXiv 2021
-
[6]
Takuro Fujii and Shuhei Tarashima. 2023. Bilma: Bidirectional local-matching for text-based person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2786--2790
2023
-
[7]
Chenyang Gao, Guanyu Cai, Xinyang Jiang, Feng Zheng, Jun Zhang, Yifei Gong, Pai Peng, Xiaowei Guo, and Xing Sun. 2021. Contextual non-local alignment over full-scale representation for text-based person search. arXiv preprint arXiv:2101.03036
arXiv 2021
-
[8]
Shuting He, Hao Luo, Pichao Wang, Fan Wang, Hao Li, and Wei Jiang. 2021. Transreid: Transformer-based object re-identification. In ICCV, pages 15013--15022
2021
-
[9]
Matthew Honnibal and Ines Montani. 2017. spacy 2: Natural language understanding with bloom embeddings, convolutional neural networks and incremental parsing. To appear, 7(1):411--420
2017
-
[10]
Jiang and M
D. Jiang and M. Ye. 2023 a . Cross-modal implicit relation reasoning and aligning for text-to-image person retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2787--2797
2023
-
[11]
Ding Jiang and Mang Ye. 2023 b . Cross-modal implicit relation reasoning and aligning for text-to-image person retrieval. In CVPR, pages 2787--2797
2023
-
[12]
Diederik P Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In ICLR (Poster)
2015
-
[14]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. 2023 b . Segment anything. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4015--4026
2023
-
[15]
Haiwen Li, Delong Liu, Fei Su, and Zhicheng Zhao. 2025. Object-centric discriminative learning for text-based person retrieval. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1--5. IEEE
2025
-
[16]
Shenshen Li, Xing Xu, Yang Yang, Fumin Shen, Yijun Mo, Yujie Li, and Heng Tao Shen. 2023. Dcel: Deep cross-modal evidential learning for text-based person retrieval. In Proceedings of the 31st ACM International Conference on Multimedia, pages 6292--6300
2023
-
[17]
Shuang Li, Tong Xiao, Hongsheng Li, Bolei Zhou, Dayu Yue, and Xiaogang Wang. 2017. Person search with natural language description. In CVPR, pages 1970--1979
2017
-
[18]
Yating Liu, Zimo Liu, Xiangyuan Lan, Wenming Yang, Yaowei Li, and Qingmin Liao. 2025. Dm-adapter: Domain-aware mixture-of-adapters for text-based person retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 5703--5711
2025
-
[19]
Yu Liu, Guihe Qin, Haipeng Chen, Zhiyong Cheng, and Xun Yang. 2024. Causality-inspired invariant representation learning for text-based person retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 14052--14060
2024
-
[20]
Hao Luo, Youzhi Gu, Xingyu Liao, Shenqi Lai, and Wei Jiang. 2019. Bag of tricks and a strong baseline for deep person re-identification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 0--0
2019
-
[21]
Tianle Lv, Shuang Li, Jiaxu Leng, and Xinbo Gao. 2024. Mgrl: Mutual-guidance representation learning for text-to-image person retrieval. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 2895--2899. IEEE
2024
-
[22]
Yiwei Ma, Xiaoshuai Sun, Jiayi Ji, Guannan Jiang, Weilin Zhuang, and Rongrong Ji. 2023. Beat: Bi-directional one-to-many embedding alignment for text-based person retrieval. In Proceedings of the 31st ACM International Conference on Multimedia, pages 4157--4168
2023
-
[23]
Matthias Minderer, Alexey Gritsenko, and Neil Houlsby. 2023. Scaling open-vocabulary object detection. Advances in Neural Information Processing Systems, 36:72983--73007
2023
-
[24]
Jicheol Park, Dongwon Kim, Boseung Jeong, and Suha Kwak. 2024. https://arxiv.org/abs/2409.13475 Plot: Text-based person search with part slot attention for corresponding part discovery . Preprint, arXiv:2409.13475
arXiv 2024
-
[25]
Yang Qin, Yingke Chen, Dezhong Peng, Xi Peng, Joey Tianyi Zhou, and Peng Hu. 2024. Noisy-correspondence learning for text-to-image person re-identification. In IEEE International Conference on Computer Vision and Pattern Recognition (CVPR)
2024
-
[26]
Yang Qin, Dezhong Peng, Xi Peng, Xu Wang, and Peng Hu. 2022. Deep evidential learning with noisy correspondence for cross-modal retrieval. In Proceedings of the 30th ACM International Conference on Multimedia, pages 4948--4956
2022
-
[27]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021 a . Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748--8763. PMLR
2021
-
[28]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021 b . Learning transferable visual models from natural language supervision. In ICML, pages 8748--8763. PMLR
2021
-
[29]
Zhiyin Shao, Xinyu Zhang, Changxing Ding, Jian Wang, and Jingdong Wang. 2023. Unified pre-training with pseudo texts for text-to-image person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11174--11184
2023
-
[30]
Zhiyin Shao, Xinyu Zhang, Meng Fang, Zhifeng Lin, Jian Wang, and Changxing Ding. 2022. Learning granularity-unified representations for text-to-image person re-identification. In ACM MM, pages 5566--5574
2022
-
[31]
Fei Shen, Xiangbo Shu, Xiaoyu Du, and Jinhui Tang. 2023. Pedestrian-specific bipartite-aware similarity learning for text-based person retrieval. In Proceedings of the 31st ACM International Conference on Multimedia, pages 8922--8931
2023
-
[32]
Xiujun Shu, Wei Wen, Haoqian Wu, Keyu Chen, Yiran Song, Ruizhi Qiao, Bo Ren, and Xiao Wang. 2022. See finer, see more: Implicit modality alignment for text-based person retrieval. In European Conference on Computer Vision, pages 624--641. Springer
2022
-
[33]
Yang Shu, Yingmin Liu, and Zequn Xie. 2026. https://arxiv.org/abs/2605.05409 Agentic retrieval-augmented generation for financial document question answering . Preprint, arXiv:2605.05409
Pith/arXiv arXiv 2026
-
[34]
Zifan Song, Guosheng Hu, and Cairong Zhao. 2024. Diverse person: Customize your own dataset for text-based person search. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4943--4951
2024
-
[35]
Chengji Wang, Zhiming Luo, Yaojin Lin, and Shaozi Li. 2021. Text-based person search via multi-granularity embedding learning. In IJCAI, pages 1068--1074
2021
-
[36]
Zhe Wang, Zhiyuan Fang, Jun Wang, and Yezhou Yang. 2020. Vitaa: Visual-textual attributes alignment in person search by natural language. In Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part XII 16, pages 402--420. Springer
2020
-
[37]
Zijie Wang, Aichun Zhu, Jingyi Xue, Xili Wan, Chao Liu, Tian Wang, and Yifeng Li. 2022. Look before you leap: Improving text-based person retrieval by learning a consistent cross-modal common manifold. In ACM MM, pages 1984--1992
2022
-
[38]
Yushuang Wu, Zizheng Yan, Xiaoguang Han, Guanbin Li, Changqing Zou, and Shuguang Cui. 2021. Lapscore: language-guided person search via color reasoning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1624--1633
2021
-
[42]
Zequn Xie, Guijin Luo, Chuxin Wang, Sihang Cai, Tao Jin, Zhou Zhao, and Yixuan Tang. 2026 b . https://arxiv.org/abs/2604.23282 Bridging the pose-semantic gap: A cascade framework for text-based person anomaly search . Preprint, arXiv:2604.23282
Pith/arXiv arXiv 2026
-
[43]
Zequn Xie, Chuxin Wang, Yeqiang Wang, Sihang Cai, Shulei Wang, and Tao Jin. 2025 b . Chat-driven text generation and interaction for person retrieval. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5259--5270
2025
-
[45]
Shuanglin Yan, Neng Dong, Jun Liu, Liyan Zhang, and Jinhui Tang. 2023 a . Learning comprehensive representations with richer self for text-to-image person re-identification. In Proceedings of the 31st ACM international conference on multimedia, pages 6202--6211
2023
-
[46]
Shuanglin Yan, Neng Dong, Liyan Zhang, and Jinhui Tang. 2023 b . Clip-driven fine-grained text-image person re-identification. IEEE Transactions on Image Processing
2023
-
[48]
Shuyu Yang, Yinan Zhou, Yaxiong Wang, Yujiao Wu, Li Zhu, and Zhedong Zheng. 2023. Towards unified text-based person retrieval: A large-scale multi-attribute and language search benchmark. In Proceedings of the 2023 ACM on Multimedia Conference
2023
-
[49]
Ying Zhang and Huchuan Lu. 2018. Deep cross-modal projection learning for image-text matching. In Proceedings of the European conference on computer vision (ECCV), pages 686--701
2018
-
[50]
Zhiwei Zhao, Bin Liu, Yan Lu, Qi Chu, and Nenghai Yu. 2024. Unifying multi-modal uncertainty modeling and semantic alignment for text-to-image person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 7534--7542
2024
-
[51]
Zhedong Zheng, Liang Zheng, Michael Garrett, Yi Yang, Mingliang Xu, and Yi-Dong Shen. 2020. Dual-path convolutional image-text embeddings with instance loss. ACM Transactions on Multimedia Computing, Communications, and Applications, 16(2):1--23
2020
-
[52]
Aichun Zhu, Zijie Wang, Yifeng Li, Xili Wan, Jing Jin, Tian Wang, Fangqiang Hu, and Gang Hua. 2021. Dssl: Deep surroundings-person separation learning for text-based person retrieval. In Proceedings of the 29th ACM International Conference on Multimedia, pages 209--217
2021
-
[53]
Jialong Zuo, Hanyu Zhou, Ying Nie, Feng Zhang, Tianyu Guo, Nong Sang, Yunhe Wang, and Changxin Gao. 2024. Ufinebench: Towards text-based person retrieval with ultra-fine granularity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22010--22019
2024
-
[54]
Attribute-Guided Pedestrian Retrieval: Bridging Person Re-ID with Internal Attribute Variability , year=
Huang, Yan and Zhang, Zhang and Wu, Qiang and Zhong, Yi and Wang, Liang , booktitle=. Attribute-Guided Pedestrian Retrieval: Bridging Person Re-ID with Internal Attribute Variability , year=
-
[55]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Chat-driven text generation and interaction for person retrieval , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[56]
arXiv preprint arXiv:2601.16155 , year=
HVD: Human Vision-Driven Video Representation Learning for Text-Video Retrieval , author=. arXiv preprint arXiv:2601.16155 , year=
-
[57]
arXiv preprint arXiv:2601.18625 , year=
CONQUER: Context-Aware Representation with Query Enhancement for Text-Based Person Search , author=. arXiv preprint arXiv:2601.18625 , year=
-
[58]
arXiv preprint arXiv:2601.12768 , year=
Delving deeper: Hierarchical visual perception for robust video-text retrieval , author=. arXiv preprint arXiv:2601.12768 , year=
-
[59]
2026 , eprint=
Bridging the Pose-Semantic Gap: A Cascade Framework for Text-Based Person Anomaly Search , author=. 2026 , eprint=
2026
-
[60]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Scene-Aware Spatiotemporal Generalization: Towards Robust Temporal Action Detection Across Domains , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2026 , month=. doi:10.1609/aaai.v40i5.37392 , abstractNote=
-
[61]
2026 , eprint=
Agentic Retrieval-Augmented Generation for Financial Document Question Answering , author=. 2026 , eprint=
2026
-
[62]
2024 , eprint=
PLOT: Text-based Person Search with Part Slot Attention for Corresponding Part Discovery , author=. 2024 , eprint=
2024
- [63]
-
[64]
ICLR (Poster) , year=
Adam: A Method for Stochastic Optimization , author=. ICLR (Poster) , year=
-
[65]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[66]
arXiv preprint arXiv:2410.02746 , year=
Contrastive localized language-image pre-training , author=. arXiv preprint arXiv:2410.02746 , year=
-
[67]
Advances in Neural Information Processing Systems , volume=
Scaling open-vocabulary object detection , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Segment anything , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[69]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Boosting Speech Recognition Robustness to Modality-Distortion with Contrast-Augmented Prompts , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[70]
arXiv preprint arXiv:2501.01384 , year=
OmniChat: Enhancing Spoken Dialogue Systems with Scalable Synthetic Data for Diverse Scenarios , author=. arXiv preprint arXiv:2501.01384 , year=
-
[71]
arXiv preprint arXiv:2503.00528 , year=
Efficient prompting for continual adaptation to missing modalities , author=. arXiv preprint arXiv:2503.00528 , year=
-
[72]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Calibrating prompt from history for continual vision-language retrieval and grounding , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[73]
arXiv preprint arXiv:2505.06566 , year=
Dynamic Uncertainty Learning with Noisy Correspondence for Text-Based Person Search , author=. arXiv preprint arXiv:2505.06566 , year=
-
[74]
2025 , eprint=
Observe-R1: Unlocking Reasoning Abilities of MLLMs with Dynamic Progressive Reinforcement Learning , author=. 2025 , eprint=
2025
-
[75]
2025 , eprint=
Open-set Cross Modal Generalization via Multimodal Unified Representation , author=. 2025 , eprint=
2025
-
[76]
2024 , eprint=
OmniBind: Large-scale Omni Multimodal Representation via Binding Spaces , author=. 2024 , eprint=
2024
-
[77]
Yang, Bo and Wang, Chen and Ma, Xiaoshuang and Song, Beiping and Liu, Zhuang and Sun, Fangde , year=. Zero-Shot Sketch-Based Remote-Sensing Image Retrieval Based on Multi-Level and Attention-Guided Tokenization , volume=. Remote Sensing , publisher=. doi:10.3390/rs16101653 , number=
-
[78]
2023 , url =
OpenAI , title =. 2023 , url =
2023
-
[79]
Toward Video Anomaly Retrieval From Video Anomaly Detection: New Benchmarks and Model , year=
Wu, Peng and Liu, Jing and He, Xiangteng and Peng, Yuxin and Wang, Peng and Zhang, Yanning , journal=. Toward Video Anomaly Retrieval From Video Anomaly Detection: New Benchmarks and Model , year=
-
[80]
Context Recovery and Knowledge Retrieval: A Novel Two-Stream Framework for Video Anomaly Detection , year=
Cao, Congqi and Lu, Yue and Zhang, Yanning , journal=. Context Recovery and Knowledge Retrieval: A Novel Two-Stream Framework for Video Anomaly Detection , year=
-
[81]
SG\_161222 , title =
-
[82]
ECCV , pages=
PLOT: Text-Based Person Search with Part Slot Attention for Corresponding Part Discovery , author=. ECCV , pages=. 2024 , organization=
2024
-
[83]
CVPR , pages=
Towards surveillance video-and-language understanding: New dataset baselines and challenges , author=. CVPR , pages=
-
[84]
ICCV , month =
Zheng, Liang and Shen, Liyue and Tian, Lu and Wang, Shengjin and Wang, Jingdong and Tian, Qi , title =. ICCV , month =
-
[85]
Computer Vision--ECCV 2016 Workshops: Amsterdam, The Netherlands, October 8-10 and 15-16, 2016, Proceedings, Part II , pages=
Performance measures and a data set for multi-target, multi-camera tracking , author=. Computer Vision--ECCV 2016 Workshops: Amsterdam, The Netherlands, October 8-10 and 15-16, 2016, Proceedings, Part II , pages=. 2016 , organization=
2016
-
[86]
CVPR , pages=
Oops! predicting unintentional action in video , author=. CVPR , pages=
-
[87]
Qwen-vl: A frontier large vision-language model with versatile abilities , author=. arXiv:2308.12966 , year=
-
[88]
Shikra: Unleashing multimodal llm's referential dialogue magic , author=. arXiv:2306.15195 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.