Suppressing Forgery-Specific Shortcuts for Generalizable Deepfake Detection
Pith reviewed 2026-06-28 15:10 UTC · model grok-4.3
The pith
The S^3 framework suppresses method-specific shortcut subspaces in deepfake detectors to improve generalization across unseen forgery methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Variations that distinguish forgery methods serve as a proxy for method-specific shortcuts; extracting their dominant subspace via SVD on a linear probe allows the model to suppress those directions softly in training and attenuate aligned neurons at inference, yielding better cross-method generalization without loss of in-domain performance.
What carries the argument
The shortcut subspace, obtained as the dominant singular vectors from SVD on features of a linear probe trained to classify forgery methods, used as a proxy to identify and suppress method-specific artifacts.
If this is right
- Training with subspace suppression reduces reliance on forgery-method artifacts for the real/fake decision.
- The training-free attenuation step enables immediate generalization gains on existing models without retraining.
- Identified neurons aligned with the shortcut subspace become more interpretable as method-specific rather than general cues.
- The approach preserves strong performance on seen forgery methods while lifting results on unseen ones.
Where Pith is reading between the lines
- The same probe-plus-SVD approach could be tested on other vision tasks where class-specific shortcuts are suspected.
- If the subspace directions prove stable across different backbone architectures, the method could serve as a lightweight post-hoc regularizer.
- Nonlinear extensions of the probe might reveal whether linear SVD misses higher-order method-specific patterns.
Load-bearing premise
The dominant singular vectors from the forgery-method probe capture only method-specific shortcuts and do not overlap with generalizable real-versus-fake cues.
What would settle it
If suppressing the identified subspace directions causes a drop in real-versus-fake accuracy on the original training distribution comparable to the drop on unseen methods, the subspace would be shown to contain essential cues rather than removable shortcuts.
Figures
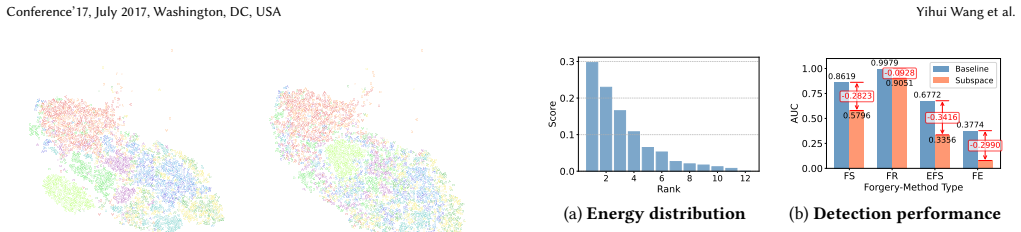
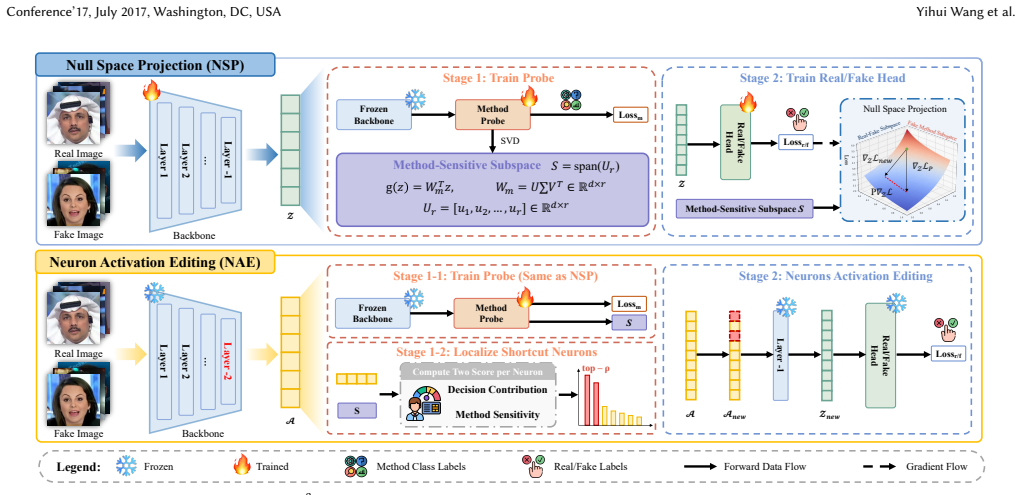

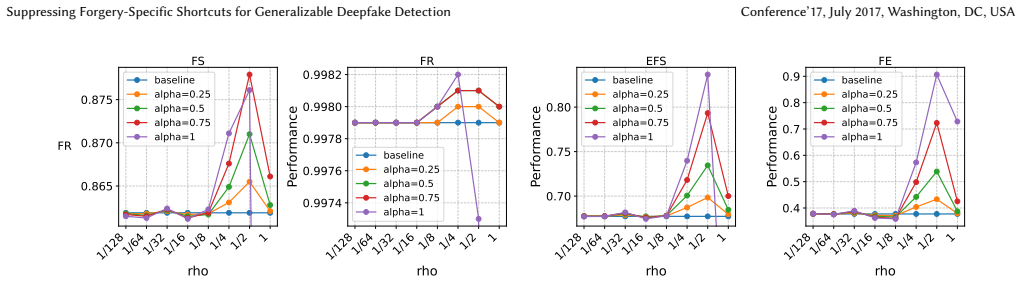
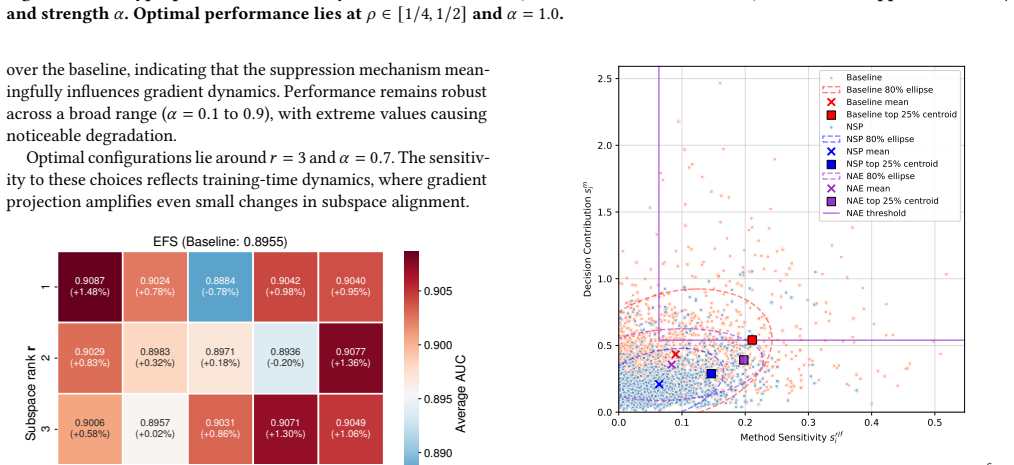




read the original abstract
Deepfake detection suffers from poor generalization across forgery methods, as existing models tend to rely on spurious method-specific shortcuts that fail to transfer to unseen manipulations. While recent approaches attempt to improve generalization, they lack an explicit mechanism to identify and suppress such shortcuts in learned representations. In this work, we propose Shortcut Subspace Suppression (S^3) framework that explicitly characterizes and suppresses method-specific shortcuts via subspace modeling. Our key insight is that variations distinguishing different forgery methods capture method-specific artifacts and thus serve as an effective proxy for method-specific shortcuts. To this end, we train a lightweight linear probe for forgery method classification and perform Singular Value Decomposition (SVD) to extract the dominant shortcut subspace. Building on this formulation, we develop two complementary strategies to reduce shortcut reliance. During training, we softly suppress the shortcut subspace in feature representations, encouraging the model to rely on more generalizable cues for real/fake discrimination. At inference time, we introduce a training-free counterpart that attenuates neurons aligned with the identified shortcut directions, enabling plug-and-play generalization enhancement with improved interpretability. Extensive experiments on multiple benchmarks demonstrate that our method significantly improves cross-method generalization while maintaining strong in-domain performance. The code will be released upon acceptance of the submission.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Shortcut Subspace Suppression (S^3) framework for deepfake detection. It trains a linear probe on forgery-method labels, extracts the dominant subspace via SVD as a proxy for method-specific shortcuts, softly suppresses this subspace in features during training to encourage generalizable real/fake cues, and applies a training-free neuron attenuation at inference. The central claim is that this yields significantly better cross-method generalization while preserving strong in-domain performance, supported by extensive experiments on multiple benchmarks.
Significance. If the core assumption holds and the reported gains are reproducible, the explicit subspace-based shortcut suppression mechanism would be a useful addition to the deepfake detection literature, particularly the training-free inference component for plug-and-play use. The promise to release code is a positive factor for reproducibility.
major comments (3)
- [Abstract] Abstract: the claim that 'extensive experiments on multiple benchmarks demonstrate significant gains' supplies no quantitative results, baseline comparisons, data-split details, or statistical tests, making it impossible to verify whether the data support the stated improvements in cross-method generalization.
- [Method] Method (linear-probe + SVD construction): the central assumption that dominant singular vectors from the method-classification probe form a clean, non-overlapping proxy for shortcuts (rather than also capturing generalizable real/fake cues) is not verified; no analysis shows orthogonality to the real/fake decision boundary or that suppression preserves in-domain accuracy for the claimed reason rather than incidental effects.
- [Experiments] Experiments section: absence of ablation on the number of retained singular vectors, sensitivity of the soft-suppression hyperparameter, or direct measurement of subspace overlap with real/fake features leaves the load-bearing mechanism untested.
minor comments (2)
- [Method] Notation for the shortcut subspace and the attenuation operation at inference should be defined with explicit equations rather than prose descriptions.
- [Abstract] The abstract mentions 'multiple benchmarks' without naming them; the experiments section should list the exact datasets and forgery methods used for cross-method evaluation.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'extensive experiments on multiple benchmarks demonstrate significant gains' supplies no quantitative results, baseline comparisons, data-split details, or statistical tests, making it impossible to verify whether the data support the stated improvements in cross-method generalization.
Authors: We agree that the abstract would benefit from including key quantitative highlights to support the generalization claims. In the revised version, we will update the abstract to report representative cross-method AUC improvements (e.g., average gains over baselines), the specific benchmarks used, and a brief note on the evaluation protocol. revision: yes
-
Referee: [Method] Method (linear-probe + SVD construction): the central assumption that dominant singular vectors from the method-classification probe form a clean, non-overlapping proxy for shortcuts (rather than also capturing generalizable real/fake cues) is not verified; no analysis shows orthogonality to the real/fake decision boundary or that suppression preserves in-domain accuracy for the claimed reason rather than incidental effects.
Authors: The linear probe is trained solely on forgery-method labels, providing a natural separation from the real/fake task. However, we acknowledge the need for explicit verification. We will add analysis in the revised manuscript, including cosine similarity between the shortcut subspace and real/fake classifier weights, as well as in-domain accuracy curves under varying suppression levels, to confirm the subspace primarily captures shortcuts. revision: yes
-
Referee: [Experiments] Experiments section: absence of ablation on the number of retained singular vectors, sensitivity of the soft-suppression hyperparameter, or direct measurement of subspace overlap with real/fake features leaves the load-bearing mechanism untested.
Authors: We agree these ablations would better substantiate the mechanism. In the revised Experiments section, we will add: (i) results varying the number of retained singular vectors, (ii) sensitivity plots for the soft-suppression hyperparameter, and (iii) direct overlap measurements such as feature projections onto the shortcut subspace and correlation with real/fake decision boundaries. revision: yes
Circularity Check
No significant circularity; derivation is self-contained via external operations
full rationale
The paper defines S^3 by training a linear probe on forgery-method labels followed by SVD to extract a subspace, then applies soft suppression in training and neuron attenuation at inference. These steps are procedural definitions using standard linear algebra and probing techniques applied to learned features; no equation reduces the reported cross-method generalization gain to a quantity fitted directly to the target real/fake metric or to a self-citation chain. The central modeling choice (that the method-classification subspace proxies shortcuts) is an assumption whose empirical consequences are tested on external benchmarks rather than enforced by construction. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results appear in the provided derivation chain.
Axiom & Free-Parameter Ledger
invented entities (1)
-
shortcut subspace
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Darius Afchar, Vincent Nozick, Junichi Yamagishi, and Isao Echizen. 2018. Mesonet: a compact facial video forgery detection network. In2018 IEEE in- ternational workshop on information forensics and security (WIFS). IEEE, 1–7
2018
-
[2]
Guillaume Alain and Yoshua Bengio. 2016. Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Inzamamul Alam, Md Tanvir Islam, and Simon S. Woo. 2025. SpecXNet: A Dual- Domain Convolutional Network for Robust Deepfake Detection. InProceedings of the 33rd ACM International Conference on Multimedia(Dublin, Ireland)(MM ’25). Association for Computing Machinery, New York, NY, USA, 11667–11676. doi:10.1145/3746027.3755707
-
[4]
David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. 2017. Network dissection: Quantifying interpretability of deep visual representations. InProceedings of the IEEE conference on computer vision and pattern recognition. 6541–6549
2017
-
[5]
Yonatan Belinkov. 2022. Probing classifiers: Promises, shortcomings, and ad- vances.Computational Linguistics48, 1 (2022), 207–219
2022
-
[6]
Junyi Cao, Chao Ma, Taiping Yao, Shen Chen, Shouhong Ding, and Xiaokang Yang. 2022. End-to-End Reconstruction-Classification Learning for Face Forgery Detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 4113–4122
2022
-
[7]
Francois Chollet. 2017. Xception: Deep Learning With Depthwise Separable Convolutions. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2017
- [8]
-
[9]
Shichao Dong, Jin Wang, Renhe Ji, Jiajun Liang, Haoqiang Fan, and Zheng Ge
-
[10]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Implicit identity leakage: The stumbling block to improving deepfake detection generalization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 3994–4004
-
[11]
Ricard Durall, Margret Keuper, and Janis Keuper. 2020. Watch your up- convolution: Cnn based generative deep neural networks are failing to reproduce spectral distributions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 7890–7899
2020
-
[12]
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarial nets.Advances in neural information processing systems27 (2014)
2014
-
[13]
Alexandros Haliassos, Konstantinos Vougioukas, Stavros Petridis, and Maja Pan- tic. 2021. Lips don’t lie: A generalisable and robust approach to face forgery detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR). 5039–5049
2021
-
[14]
Erik Härkönen, Aaron Hertzmann, Jaakko Lehtinen, and Sylvain Paris. 2020. Ganspace: Discovering interpretable gan controls.Advances in neural information processing systems33 (2020), 9841–9850
2020
- [15]
-
[16]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2016
-
[17]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems33 (2020), 6840–6851
2020
-
[18]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models.arXiv preprint arXiv:2106.09685(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, et al . 2018. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). InInternational conference on machine learning. PMLR, 2668–2677
2018
-
[20]
Nicolas Larue, Ngoc-Son Vu, Vitomir Struc, Peter Peer, and Vassilis Christophides
-
[21]
InProceedings of the IEEE/CVF international conference on computer vision (ICCV)
Seeable: Soft discrepancies and bounded contrastive learning for exposing deepfakes. InProceedings of the IEEE/CVF international conference on computer vision (ICCV). 21011–21021
-
[22]
HyunJae Lee, Hyo-Eun Kim, and Hyeonseob Nam. 2019. SRM: A Style-Based Recalibration Module for Convolutional Neural Networks. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
2019
-
[23]
Lingzhi Li, Jianmin Bao, Ting Zhang, Hao Yang, Dong Chen, Fang Wen, and Bain- ing Guo. 2020. Face x-ray for more general face forgery detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR). 5001–5010
2020
-
[24]
Yuezun Li and Siwei Lyu. 2019. Exposing deepfake videos by detecting face warping artifacts. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops (CVPRW). 46–52
2019
-
[25]
Honggu Liu, Xiaodan Li, Wenbo Zhou, Yuefeng Chen, Yuan He, Hui Xue, Weiming Zhang, and Nenghai Yu. 2021. Spatial-phase shallow learning: rethinking face forgery detection in frequency domain. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 772–781
2021
-
[26]
Iacopo Masi, Aditya Killekar, Royston Marian Mascarenhas, Shenoy Pratik Guru- datt, and Wael AbdAlmageed. 2020. Two-branch recurrent network for isolating deepfakes in videos. InEuropean conference on computer vision. Springer, 667–684
2020
-
[27]
Yisroel Mirsky and Wenke Lee. 2021. The creation and detection of deepfakes: A survey.ACM computing surveys (CSUR)54, 1 (2021), 1–41
2021
-
[28]
Yunsheng Ni, Depu Meng, Changqian Yu, Chengbin Quan, Dongchun Ren, and Youjian Zhao. 2022. Core: Consistent representation learning for face forgery detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops (CVPRW). 12–21
2022
-
[29]
Utkarsh Ojha, Yuheng Li, and Yong Jae Lee. 2023. Towards universal fake image detectors that generalize across generative models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 24480–24489
2023
-
[30]
Yuyang Qian, Guojun Yin, Lu Sheng, Zixuan Chen, and Jing Shao. 2020. Think- ing in frequency: Face forgery detection by mining frequency-aware clues. In European conference on computer vision. Springer, 86–103
2020
-
[31]
Tong Qiao, Shichuang Xie, Yizhi Chen, Florent Retraint, and Xiangyang Luo. 2024. Fully unsupervised deepfake video detection via enhanced contrastive learning. InProceedings of the IEEE/CVF winter conference on applications of computer vision (W ACV). 4691–4700
2024
-
[32]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InProceedings of the 38th Inter- national Conference on Machine Learning (Proceedings of Machi...
2021
-
[33]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684–10695
2022
-
[34]
Andreas Rössler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. 2019. FaceForensics++: Learning to Detect Manipulated Facial Images. InInternational Conference on Computer Vision (ICCV)
2019
-
[35]
Minenko, Dmitrii I
Ayush Roy, Sk Mohiuddin, Maxim V. Minenko, Dmitrii I. Kaplun, and Ram Sarkar
-
[36]
InVISIGRAPP : VISAPP
DeepSpace: Navigating the Frontier of Deepfake Identification Using Attention-Driven Xception and a Task-Specific Subspace. InVISIGRAPP : VISAPP. https://api.semanticscholar.org/CorpusID:276760616
-
[37]
Kaede Shiohara and Toshihiko Yamasaki. 2022. Detecting deepfakes with self- blended images. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 18720–18729
2022
-
[38]
Stefan Smeu, Elisabeta Oneata, and Dan Oneata. 2025. DeCLIP: Decoding CLIP representations for deepfake localization. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV). IEEE, 149–159
2025
-
[39]
Zekun Sun, Yujie Han, Zeyu Hua, Na Ruan, and Weijia Jia. 2021. Improving the efficiency and robustness of deepfakes detection through precise geometric features. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR). 3609–3618
2021
-
[40]
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, Ping Liu, and Yunchao Wei. 2024. Frequency-aware deepfake detection: Improving generalizability through frequency space domain learning. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 5052–5060. Conference’17, July 2017, Washington, DC, USA Yihui Wang et al
2024
-
[41]
Mingxing Tan and Quoc Le. 2019. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. InProceedings of the 36th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 97), Kamalika Chaudhuri and Ruslan Salakhutdinov (Eds.). PMLR, 6105–
2019
-
[42]
https://proceedings.mlr.press/v97/tan19a.html
-
[43]
Ruben Tolosana, Ruben Vera-Rodriguez, Julian Fierrez, Aythami Morales, and Javier Ortega-Garcia. 2020. Deepfakes and beyond: A survey of face manipulation and fake detection.Information fusion64 (2020), 131–148
2020
-
[44]
Chengrui Wang and Weihong Deng. 2021. Representative forgery mining for fake face detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR). 14923–14932
2021
-
[45]
Zhendong Wang, Jianmin Bao, Wengang Zhou, Weilun Wang, Hezhen Hu, Hong Chen, and Houqiang Li. 2023. Dire for diffusion-generated image detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 22445– 22455
2023
-
[46]
Zhiyuan Yan, Yuhao Luo, Siwei Lyu, Qingshan Liu, and Baoyuan Wu. 2024. Transcending forgery specificity with latent space augmentation for generalizable deepfake detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8984–8994
2024
-
[47]
Zhiyuan Yan, Jiangming Wang, Peng Jin, Ke-Yue Zhang, Chengchun Liu, Shen Chen, Taiping Yao, Shouhong Ding, Baoyuan Wu, and Li Yuan. 2024. Orthogonal subspace decomposition for generalizable ai-generated image detection.arXiv preprint arXiv:2411.15633(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Zhiyuan Yan, Taiping Yao, Shen Chen, Yandan Zhao, Xinghe Fu, Junwei Zhu, Donghao Luo, Chengjie Wang, Shouhong Ding, Yunsheng Wu, and Li Yuan
-
[49]
InAdvances in Neural Information Processing Systems, A
DF40: Toward Next-Generation Deepfake Detection. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 29387–29434. doi:10.52202/079017-0925
-
[50]
Zhiyuan Yan, Yong Zhang, Yanbo Fan, and Baoyuan Wu. 2023. Ucf: Uncovering common features for generalizable deepfake detection. InProceedings of the IEEE/CVF international conference on computer vision. 22412–22423
2023
- [51]
-
[52]
Kelu Yao, Jin Wang, Boyu Diao, and Chao Li. 2023. Towards understanding the generalization of deepfake detectors from a game-theoretical view. InProceedings of the IEEE/CVF international conference on computer vision. 2031–2041
2023
- [53]
-
[54]
Zixin Yin, Jiakai Wang, Yisong Xiao, Hanqing Zhao, Tianlin Li, Wenbo Zhou, Aishan Liu, and Xianglong Liu. 2024. Improving deepfake detection generalization by invariant risk minimization.IEEE Transactions on Multimedia26 (2024), 6785– 6798
2024
-
[55]
Tianchen Zhao, Xiang Xu, Mingze Xu, Hui Ding, Yuanjun Xiong, and Wei Xia
-
[56]
InProceedings of the IEEE/CVF international conference on computer vision (ICCV)
Learning self-consistency for deepfake detection. InProceedings of the IEEE/CVF international conference on computer vision (ICCV). 15023–15033
-
[57]
Yinglin Zheng, Jianmin Bao, Dong Chen, Ming Zeng, and Fang Wen. 2021. Ex- ploring temporal coherence for more general video face forgery detection. In Proceedings of the IEEE/CVF international conference on computer vision (ICCV). 15044–15054
2021
-
[58]
training on FS
Wanyi Zhuang, Qi Chu, Zhentao Tan, Qiankun Liu, Haojie Yuan, Changtao Miao, Zixiang Luo, and Nenghai Yu. 2022. Uia-vit: Unsupervised inconsistency-aware method based on vision transformer for face forgery detection. InEuropean conference on computer vision (ECCV). Springer, 391–407. Suppressing Forgery-Specific Shortcuts for Generalizable Deepfake Detecti...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.