AutoBG: A Board Game Design Assistant with Interactive Ideation, Iterative Rulebook Generation, and Individualized Feedback
Pith reviewed 2026-06-28 13:00 UTC · model grok-4.3
The pith
AutoBG uses critic-driven loops to generate board game rulebooks approaching published quality from initial ideas.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AutoBG enables designers to move from an initial idea to a polished, audience-tested rulebook in one workflow through BG-Ideator for structured drafts via dialogue, BG-Realizer for complete rulebook generation and closed-loop revision with BG-Critic, and BG-Persona for feedback drawn from 150 real player profiles. The system is trained on 2.2K structured rulebooks and 180K quality-filtered player reviews. On 207 held-out games it outperforms baselines such as GPT-5.4, and a 30-participant user study confirms it reduces blank-page anxiety, surfaces hidden design flaws, and delivers practical help across experience levels.
What carries the argument
The BG-Critic module, which diagnoses design flaws from rulebook text alone and gates each revision so only verified improvements are accepted.
If this is right
- Rulebooks produced by AutoBG approach the quality level of published games on held-out test cases.
- The system reduces blank-page anxiety for designers of varying experience levels.
- The critic module surfaces hidden design flaws that would otherwise go unnoticed.
- Individualized feedback from simulated player personas supports audience-specific testing within the workflow.
- The full set of modules allows completion of the entire design process from early ideation to final rulebook in a single session.
Where Pith is reading between the lines
- The same modular structure of ideation, text-based criticism, and persona simulation could be adapted to other iterative creative tasks that rely on written specifications and audience response.
- If the critic proves reliable at gating improvements from text, early-stage human playtesting might be partially deferred until later prototypes.
- Training on larger collections of player reviews could narrow the remaining gap between generated and published rulebook quality.
Load-bearing premise
The BG-Critic module can reliably diagnose design flaws from rulebook text alone and correctly decide which revisions count as genuine improvements.
What would settle it
Independent expert ratings of rulebook quality on the same 207 held-out games, comparing AutoBG outputs directly against the published originals; if AutoBG versions score markedly lower, the performance claim fails.
Figures


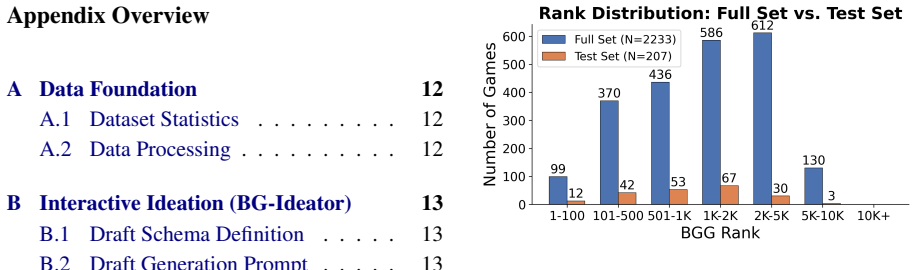
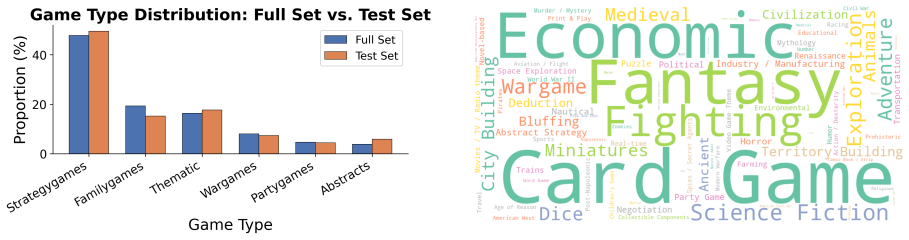

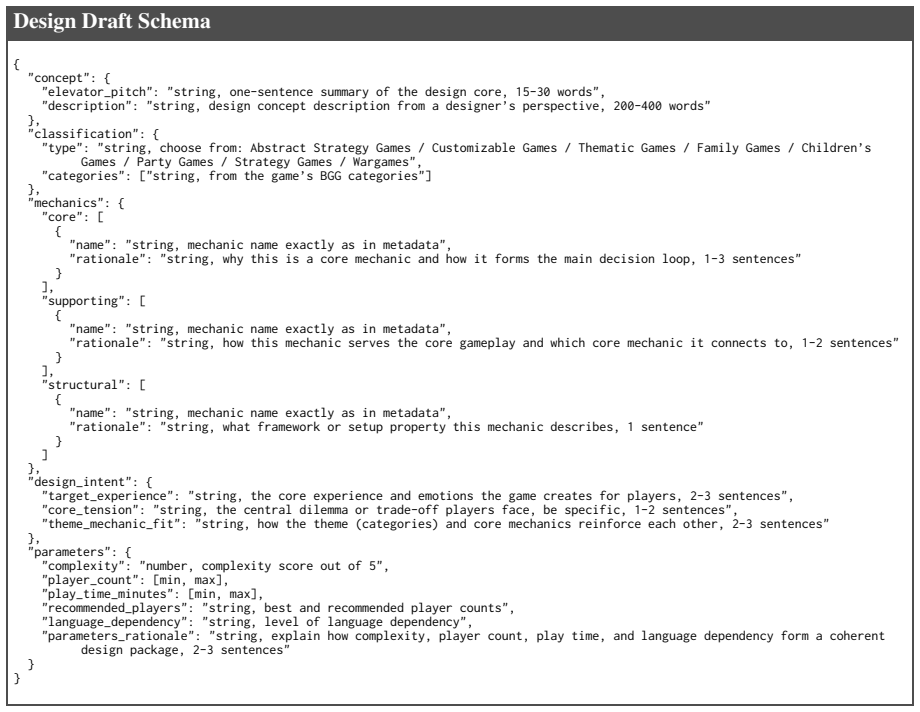










read the original abstract
Designing a board game demands both thinking as a designer and experiencing as a player, while iterating through repeated prototyping and playtesting cycles, making it a cognitively intensive creative task well suited for human-AI collaboration. However, current systems lack end-to-end support to guide designers through the complete workflow from vague early ideation to iterative rulebook revision and audience testing. To this end, we present AutoBG, a board game design assistant built around critic-driven iterative refinement, comprising four specialized modules: BG-Ideator guides designers via multi-turn dialogue to produce structured design drafts; BG-Realizer generates complete rulebooks from drafts and revises them in a closed loop with BG-Critic, which diagnoses design flaws and gates each revision so that only verified improvements are accepted; and BG-Persona simulates individualized feedback from 150 real player profiles. Together, these modules enable designers to go from an initial idea to a polished, audience-tested rulebook within a single integrated workflow. The system is built on 2.2K structured rulebooks and 180K quality-filtered real player reviews, with task-specific training data derived for each module. Experiments on 207 held-out games show that AutoBG substantially outperforms state-of-the-art baselines (e.g., GPT-5.4), generating rulebooks that approach the quality of published games. Furthermore, a user study with 30 participants across diverse experience levels confirms that AutoBG effectively reduces blank-page anxiety, surfaces hidden design flaws, and provides highly rated, practical assistance throughout the creative process.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AutoBG, an integrated AI assistant for board game design comprising BG-Ideator (multi-turn ideation), BG-Realizer (rulebook generation with closed-loop revision), BG-Critic (flaw diagnosis that gates revisions), and BG-Persona (individualized player feedback from 150 profiles). The system is trained on 2.2K structured rulebooks and 180K player reviews. It claims that experiments on 207 held-out games show substantial outperformance over baselines such as GPT-5.4, with generated rulebooks approaching published quality, and that a 30-participant user study confirms reductions in blank-page anxiety and practical assistance across experience levels.
Significance. If the empirical claims hold with proper validation, the work would represent a meaningful advance in HCI for AI-supported creative workflows, demonstrating an end-to-end system that handles ideation through iterative refinement and audience simulation in a domain requiring both design thinking and playtesting experience.
major comments (2)
- [Experiments on 207 held-out games] The central outperformance claim on the 207 held-out games depends on the BG-Critic module reliably detecting design flaws from rulebook text alone and correctly accepting only verified improvements in the closed-loop refinement with BG-Realizer. No separate held-out evaluation (e.g., precision, recall, or inter-rater agreement with human playtesters) of this critic is described, despite its training on the 2.2K rulebooks and 180K reviews; without it, the iterative process could accept spurious changes, undermining the quality claims.
- [User study] The abstract and results assert benefits from the 30-participant user study (reduced anxiety, surfaced flaws, highly rated assistance) but supply no evaluation criteria, statistical details, methodology for measuring outcomes, or breakdown by participant experience level, preventing assessment of whether the data supports the stated conclusions.
minor comments (2)
- Clarify the exact task-specific training data derivation process for each of the four modules and how the 207 held-out games were selected and preprocessed to ensure they are truly unseen.
- Provide concrete metrics (e.g., rulebook quality scores, comparison tables) rather than qualitative statements like 'substantially outperforms' and 'approach the quality of published games' to allow direct comparison with baselines.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the strength of our empirical claims. We address each major point below with clarifications drawn from the manuscript and commit to revisions where the presentation can be strengthened.
read point-by-point responses
-
Referee: [Experiments on 207 held-out games] The central outperformance claim on the 207 held-out games depends on the BG-Critic module reliably detecting design flaws from rulebook text alone and correctly accepting only verified improvements in the closed-loop refinement with BG-Realizer. No separate held-out evaluation (e.g., precision, recall, or inter-rater agreement with human playtesters) of this critic is described, despite its training on the 2.2K rulebooks and 180K reviews; without it, the iterative process could accept spurious changes, undermining the quality claims.
Authors: We agree that a dedicated, module-level evaluation of BG-Critic (precision, recall, and inter-rater agreement against human playtesters) is not reported in the current manuscript. The 207 held-out game results demonstrate end-to-end improvement of the full AutoBG pipeline over baselines, but this does not isolate the critic's contribution or rule out acceptance of spurious revisions. We will add a new subsection under Experiments that reports critic performance on a held-out subset of rulebooks with expert annotations, including agreement metrics. This revision will directly address the concern. revision: yes
-
Referee: [User study] The abstract and results assert benefits from the 30-participant user study (reduced anxiety, surfaced flaws, highly rated assistance) but supply no evaluation criteria, statistical details, methodology for measuring outcomes, or breakdown by participant experience level, preventing assessment of whether the data supports the stated conclusions.
Authors: The full manuscript contains a User Study section that describes the protocol (pre/post questionnaires, task instructions, and qualitative feedback collection) and reports aggregate ratings. However, we acknowledge that explicit evaluation criteria, complete statistical reporting (means, SDs, p-values), and experience-level breakdowns are not presented with sufficient detail. We will expand this section in revision to include these elements, allowing readers to assess support for the claims about anxiety reduction and assistance across experience levels. revision: yes
Circularity Check
No circularity: system trained on external data with held-out evaluation
full rationale
The paper presents an ML-based design assistant trained on 2.2K external rulebooks and 180K player reviews, with performance measured on 207 held-out games and a separate user study. No mathematical derivations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the described workflow. The BG-Critic training and gating mechanism is presented as learned from the external corpus rather than defined in terms of the target outputs. Evaluation claims rest on standard train/held-out splits and human ratings, which are independent of the system internals. This is the expected non-finding for an empirical systems paper without closed-form derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can be effectively fine-tuned or prompted for structured creative generation, criticism, and persona simulation tasks
Reference graph
Works this paper leans on
-
[1]
In International conference on machine learning, pages 337–371
Using large language models to simulate mul- tiple humans and replicate human subject studies. In International conference on machine learning, pages 337–371. PMLR. Eliana Alweis and Richard Alweis. 2025. A narrative re- view of the benefits of board games in health.Cureus, 17(9). Jan Batzner, V olker Stocker, Bingjun Tang, Anusha Natarajan, Qinhao Chen, ...
2025
-
[2]
InAnais do XXIV Sim- pósio Brasileiro de Jogos e Entretenimento Digital (SBGames 2025), SBGames 2025, page 655–667
Boardwalk: Towards a framework for creat- ing board games with llms. InAnais do XXIV Sim- pósio Brasileiro de Jogos e Entretenimento Digital (SBGames 2025), SBGames 2025, page 655–667. Sociedade Brasileira de Computação. Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. 2024. Teaching large language models to self-debug. InThe Twelfth Internati...
2025
-
[3]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. Elaine Conway and Ruth Smith. 2026. Analogue play in the age of ai: A scoping review of non-digital games as active learning strategies in higher educa- tion.Behavioral Sciences, 16(1):133. Yijiang River Dong, Tiancheng Hu, and Nigel Collier
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Scaling Synthetic Data Creation with 1,000,000,000 Personas
Can LLM be a personalized judge? InFind- ings of the Association for Computational Linguistics: EMNLP 2024, pages 10126–10141, Miami, Florida, USA. Association for Computational Linguistics. George Skaff Elias, Richard Garfield, and K Robert Gutschera. 2020.Characteristics of games. MIT Press. Geoffrey Engelstein and Isaac Shalev. 2022.Building Blocks of ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing
Critic: Large language models can self- correct with tool-interactive critiquing.Preprint, arXiv:2305.11738. Go Frendi Gunawan and Mukhlis Amien. 2026. Com- prehensive evaluation of large language models on software engineering tasks: A multi-task benchmark. Preprint, arXiv:2602.07079. Chengpeng Hu, Yunlong Zhao, and Jialin Liu. 2024. Game generation via ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Let’s verify step by step.Preprint, arXiv:2305.20050. Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, and 1 others. 2023. Self-refine: Iterative refinement with self-feedback.Advances in neural information processing systems, 36:46534–46594. Mahdi Farrokhi Maleki...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
arXiv preprint arXiv:2308.03188 , year=
The effectiveness of intervention with board games: a systematic review.BioPsychoSocial medicine, 13(1):22. Mohd Kamal Othman, Rahimah Mat, and Kah Ching Sim. 2025. A systematic review of paper-based and digital board games for collaborative science learning. Review of Education, 13(3):e70107. Liangming Pan, Michael Saxon, Wenda Xu, Deepak Nathani, Xinyi ...
-
[8]
Weiyan Shi and Kenny Tsu Wei Choo
Large language models for scientific idea generation: A creativity-centered survey.Preprint, arXiv:2511.07448. Weiyan Shi and Kenny Tsu Wei Choo. 2026. A tax- onomy of human–mllm interaction in early-stage sketch-based design ideation. InProceedings of the Extended Abstracts of the 2026 CHI Conference on Human Factors in Computing Systems, CHI EA ’26, pag...
-
[9]
Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion: Language agents with verbal rein- forcement learning.Preprint, arXiv:2303.11366. Carla Sousa, Sara Rye, Micael Sousa, Pedro Juan Tor- res, Claudilene Perim, Shivani Atul Mansuklal, and Firdaous Ennami. 2023. Playing at the school ta- ble: Systematic literature review of board, tabletop, and other analog game-based learning approaches. Frontiers...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
AI Realtor: Towards Grounded Persuasive Language Generation for Automated Copywriting
Ai realtor: Towards grounded persuasive lan- guage generation for automated copywriting.arXiv preprint arXiv:2502.16810. Haotian Xia, Hao Peng, Yunjia Qi, Xiaozhi Wang, Bin Xu, Lei Hou, and Juanzi Li. 2026. Storyalign: Evalu- ating and training reward models for story generation. Preprint, arXiv:2605.04831. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Dingyi Yang and Qin Jin. 2025. What matters in eval- uating book-length stories? a systematic study of long story evaluation. InProceedings of the 63rd An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16375– 16398. Yaowei Zheng, Richong Zhang, Junhao Zh...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Llamafactory: Unified efficient fine-tuning of 100+ language models.Preprint, arXiv:2403.13372. Lingfeng Zhou, Jialing Zhang, Jin Gao, Mohan Jiang, and Dequan Wang. 2025. Personaeval: Are llm eval- uators human enough to judge role-play?arXiv preprint arXiv:2508.10014. Appendix Overview A Data Foundation 12 A.1 Dataset Statistics . . . . . . . . . 12 A.2 ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Briefing (5 min).Facilitator explained the AU- TOBG pipeline at high level, demonstrated one example interaction (not used in the study), and confirmed participant’s choice between bring- ing their own design idea or picking one of five prepared seed themes (cooperative survival, asymmetric race, abstract tile placement, social deduction with bidding, rea...
-
[14]
Facilita- tor intervened only on technical issues, not on design content
Ideation with BG-Ideator (15 min).Partici- pants conversed with BG-Ideator in 5–10 turns until reaching a complete design draft. Facilita- tor intervened only on technical issues, not on design content
-
[15]
Reading v0 rulebook (10 min).Participants read the generated initial rulebook and were asked to summarize the core gameplay loop in their own words to confirm comprehension before proceeding
-
[16]
Participants observed the iteration (Algorithm 1) and, after each round, compared the new version to the previous one
Closed-loop revision (10 min).BG-Critic’s diagnostic output was displayed alongside the rulebook. Participants observed the iteration (Algorithm 1) and, after each round, compared the new version to the previous one. They had the option to stop iteration early
-
[17]
Participants reflected on whether the feedback diversity matched their expectations
BG-Persona preview (optional, 5 min).Three sample player profiles drawn from the 150-user pool generated feedback on the final rulebook. Participants reflected on whether the feedback diversity matched their expectations
-
[18]
Survey and interview (10 min).A 16-item Likert questionnaire (Appendix G.4) was fol- lowed by 6 open-ended interview questions about workflow friction, surprising moments, and comparison to prior tools. G.4 Survey Instrument Likert items (1–7 scale, 1 = strongly disagree, 7 = strongly agree).The full 16-item instrument is organized into six dimensions (3 ...
-
[19]
vague encouragement
but score lower on critic acceptance (10). G.6 Retrospective Survey:AUTOBGvs. General LLMs 22 of the 30 participants reported prior experience using general-purpose LLMs (GPT: 18, Claude: 11, Gemini: 9; multi-select) for board game design assistance. At the end of the session, these par- ticipants were asked to rate theirpriorexperience on the same six di...
-
[20]
The game’s structured rulebook (rules, components, gameplay flow, etc.)
-
[21]
The game’s BGG metadata (mechanics, categories, complexity, player count, etc.)
-
[22]
Would a reviewer mention this in a one-sentence description?
Official BGG definitions for each mechanic and category tagged to this game Your output must be a single valid JSON object following the schema provided. No other text outside the JSON. ## Key Principles ### Mechanic Classification Classify each mechanic into exactly one tier: - **CORE** (1-3): Defines the game’s identity. The main decision loop players e...
-
[23]
SUPPORTING (2-6) = adds depth, serves core
**Mechanic Classification**: CORE (1-3) = main decision loop, identity-defining. SUPPORTING (2-6) = adds depth, serves core. STRUCTURAL (remainder) = framework, setup, grid type
-
[24]
adds depth
**Rationale**: Must cite specific game mechanisms or design logic, not generic statements like "adds depth" or "enhances tension". Explain HOW and WHY
-
[25]
Show how mechanics CONNECT and create interesting DECISIONS
**Description**: Write as a designer explaining design choices. Show how mechanics CONNECT and create interesting DECISIONS. Not a rule summary or review
-
[26]
**Elevator Pitch**: One clever design hook, not a feature list
-
[27]
balance X with Y
**Core Tension**: A specific dilemma players face, not "balance X with Y"
-
[28]
**Parameters Rationale**: Explain WHY complexity, player count, and play time form a coherent package
-
[29]
"" # Get current categories to exclude similar themes (already handled by random sampling) draft_json = json.dumps(draft, indent=2, ensure_ascii=False) themes_block =
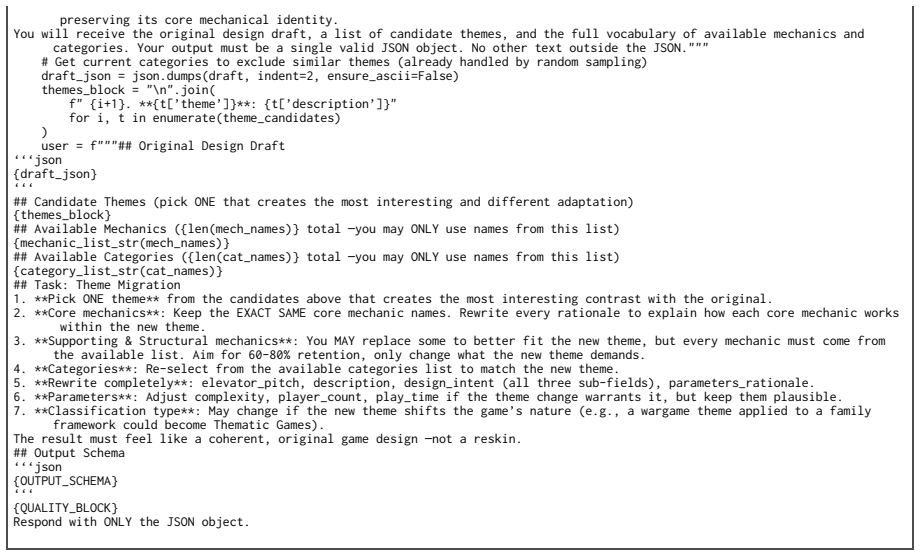
**This is a NEW game design, not a copy of any existing game.** Do not reference real game titles in the output. """ You are a senior board game design analyst. Your task is to adapt an existing game design to a completely different theme while preserving its core mechanical identity. You will receive the original design draft, a list of candidate themes,...
-
[30]
**Pick ONE theme** from the candidates above that creates the most interesting contrast with the original
-
[31]
Rewrite every rationale to explain how each core mechanic works within the new theme
**Core mechanics**: Keep the EXACT SAME core mechanic names. Rewrite every rationale to explain how each core mechanic works within the new theme
-
[32]
Aim for 60-80% retention, only change what the new theme demands
**Supporting & Structural mechanics**: You MAY replace some to better fit the new theme, but every mechanic must come from the available list. Aim for 60-80% retention, only change what the new theme demands
-
[33]
**Categories**: Re-select from the available categories list to match the new theme
-
[34]
**Rewrite completely**: elevator_pitch, description, design_intent (all three sub-fields), parameters_rationale
-
[35]
**Parameters**: Adjust complexity, player_count, play_time if the theme change warrants it, but keep them plausible
-
[36]
"" pa_json = json.dumps(parent_a, indent=2, ensure_ascii=False) pb_json = json.dumps(parent_b, indent=2, ensure_ascii=False) cores_str =
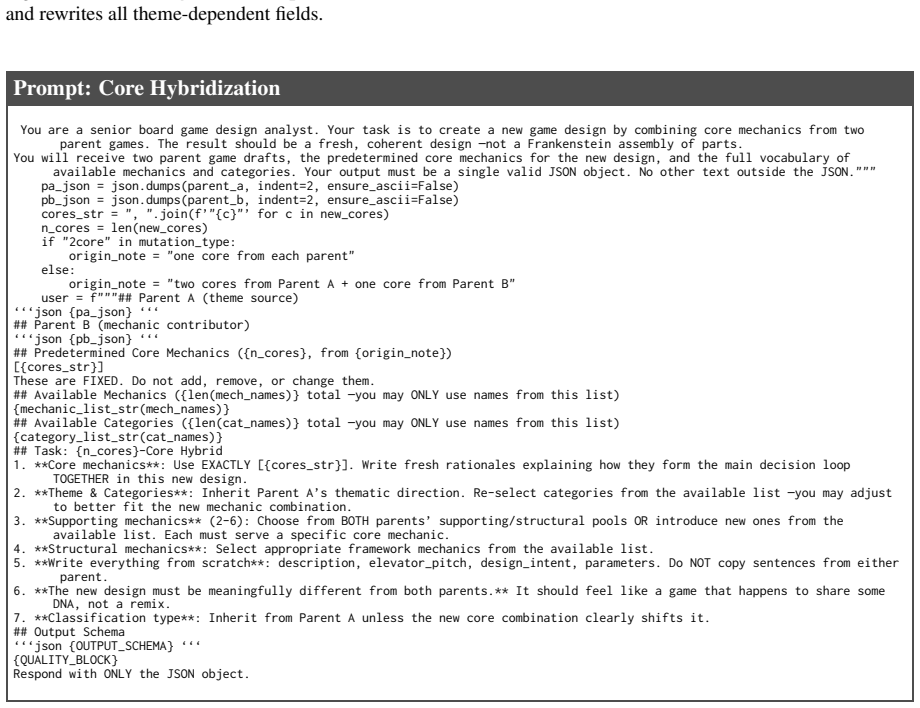
**Classification type**: May change if the new theme shifts the game’s nature (e.g., a wargame theme applied to a family framework could become Thematic Games). The result must feel like a coherent, original game design —not a reskin. ## Output Schema ‘‘‘json {OUTPUT_SCHEMA} ‘‘‘ {QUALITY_BLOCK} Respond with ONLY the JSON object. Figure 10:Theme Migration ...
-
[37]
Write fresh rationales explaining how they form the main decision loop TOGETHER in this new design
**Core mechanics**: Use EXACTLY [{cores_str}]. Write fresh rationales explaining how they form the main decision loop TOGETHER in this new design
-
[38]
Re-select categories from the available list —you may adjust to better fit the new mechanic combination
**Theme & Categories**: Inherit Parent A’s thematic direction. Re-select categories from the available list —you may adjust to better fit the new mechanic combination
-
[39]
Each must serve a specific core mechanic
**Supporting mechanics** (2-6): Choose from BOTH parents’ supporting/structural pools OR introduce new ones from the available list. Each must serve a specific core mechanic
-
[40]
**Structural mechanics**: Select appropriate framework mechanics from the available list
-
[41]
Do NOT copy sentences from either parent
**Write everything from scratch**: description, elevator_pitch, design_intent, parameters. Do NOT copy sentences from either parent
-
[42]
**The new design must be meaningfully different from both parents.** It should feel like a game that happens to share some DNA, not a remix
-
[43]
Strategy Games
**Classification type**: Inherit from Parent A unless the new core combination clearly shifts it. ## Output Schema ‘‘‘json {OUTPUT_SCHEMA} ‘‘‘ {QUALITY_BLOCK} Respond with ONLY the JSON object. Figure 11:Core Hybridization Prompt.The model receives two parent drafts and a fixed set of core mechanics, then writes a new design from scratch. Quality Verifica...
2030
-
[44]
Write in FLOWING PROSE -- paragraphs, not bullet points or numbered lists
-
[45]
Be dense and precise
Keep <response> between 120-250 words. Be dense and precise
-
[46]
When mentioning a mechanic, explain it through what it DOES in this design -- never paste a dictionary definition
-
[47]
Sound like a senior designer in conversation: warm, direct, opinionated
-
[48]
Great question!
Do NOT start with "Great question!" or any filler. Jump straight into substance
-
[49]
{target_pitch}
<reasoning> should also be prose, not a list of points. ====================================================================== CATEGORY A: MECHANIC REASONING --- A1: Constraint Recommend --- ## Task: Recommend a second core mechanic The best answer for this specific design is **{target_mechanic}**, but you must arrive at it through genuine reasoning about...
-
[50]
Start with user, end with assistant
Alternate user/assistant. Start with user, end with assistant
-
[51]
System substitutes complete draft
Final draft_update = {"_final": true}. System substitutes complete draft
-
[52]
Core mechanics must originate from or be confirmed by the user
-
[53]
No single message introduces more than 3 new mechanics
-
[54]
user_type
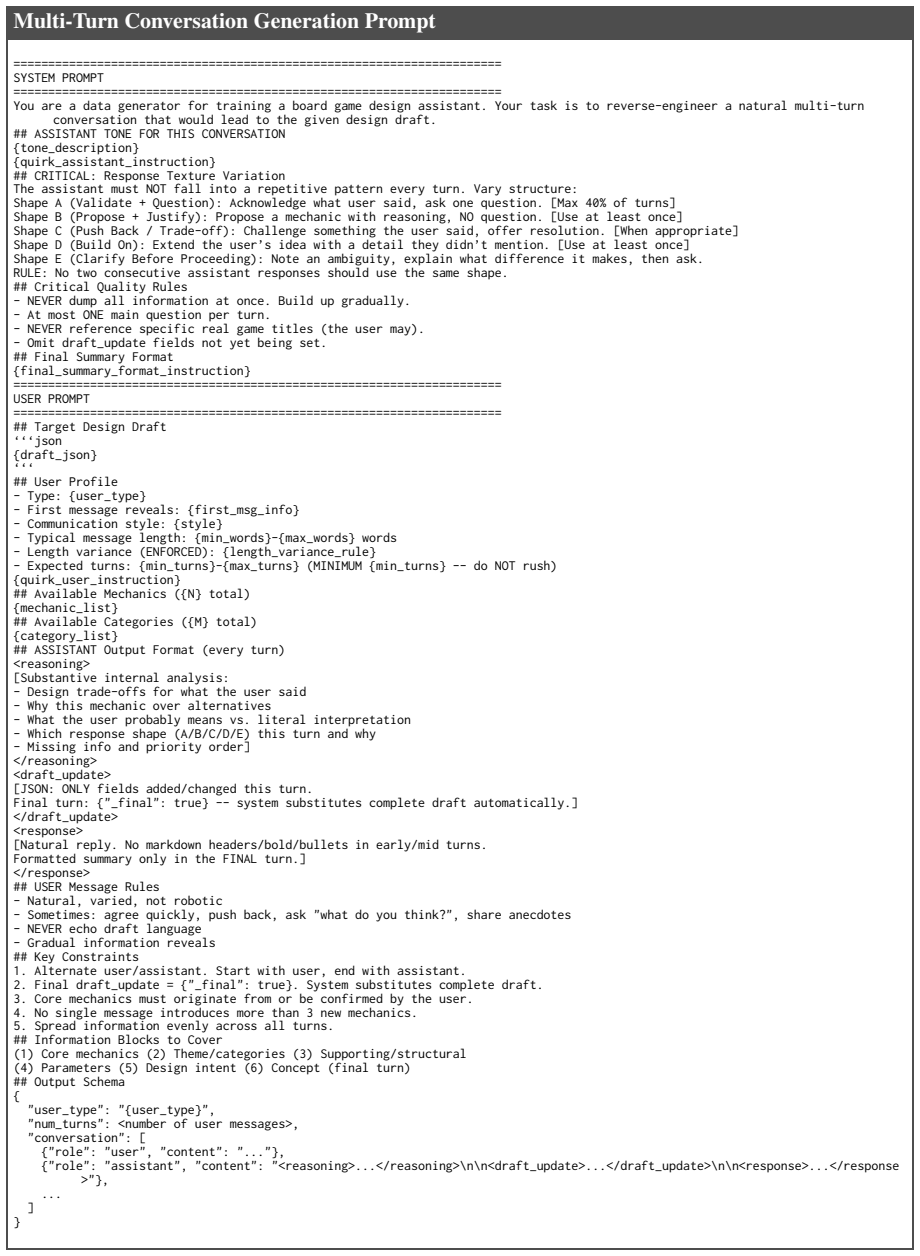
Spread information evenly across all turns. ## Information Blocks to Cover (1) Core mechanics (2) Theme/categories (3) Supporting/structural (4) Parameters (5) Design intent (6) Concept (final turn) ## Output Schema { "user_type": "{user_type}", "num_turns": <number of user messages>, "conversation": [ {"role": "user", "content": "..."}, {"role": "assista...
-
[55]
An MDA reasoning analysis (extracted from a chain-of-thought)
-
[56]
The original player review text
-
[57]
Considering all of this, I would rate it X out of 10
The player’s rating Your task: Rewrite into a flowing, paragraph-based evaluation with three sections. Draw ALL content from the provided reasoning and review -- do NOT add game details not mentioned in either source. ## Output Format (use these exact headers) ### Mechanics & Design Write 2-4 sentences describing the specific game mechanics, components, r...
-
[58]
Delete a loss condition or game-end trigger entirely
-
[59]
Delete a mandatory gating rule
-
[60]
Delete the resolution mechanics of a core action
-
[61]
[deleted]
Delete a phase transition / turn structure step. === RULES FOR HIGH-QUALITY DATA === - Find every place the target rule appears (main text, FAQ, summary) and remove ALL instances. - DO NOT leave markers like "[deleted]" or "(removed)". - DO NOT introduce contradictions -- delete, do not rewrite-and-contradict. - The rulebook should read smoothly; only a c...
-
[62]
No dangling fragments
CLEAN REMOVAL: Remove entire sentences/bullets cleanly. No dangling fragments
-
[63]
Do not touch unrelated rules
MINIMAL SCOPE: Change ONLY what is required. Do not touch unrelated rules
-
[64]
NO EDIT MARKERS: Output must read as a natural, clean rulebook
-
[65]
STRUCTURAL COMPLETENESS: Keep all original section headings and formatting
-
[66]
delete" -- remove an exact span of text
PROPAGATE CONSISTENTLY: Apply the edit to ALL restatements. === OUTPUT FORMAT: EDIT OPERATIONS === Instead of rewriting the whole rulebook, output a list of edit operations: "delete" -- remove an exact span of text "replace" -- replace an exact span with new text "replace_all" -- globally replace a term throughout "rewrite_section" -- replace an entire se...
-
[67]
- Player count scaling must be explicitly specified for board configuration, component counts, and any variable rules
FAQ or Edge Cases Critical requirements: - Component counts, board layout, and numeric values must be DERIVED from the draft’s parameters (complexity, player count, play time), NOT copied from any reference example. - Player count scaling must be explicitly specified for board configuration, component counts, and any variable rules. - The Gameplay Flow an...
-
[68]
Design component counts and numeric values appropriate for THIS draft’s complexity ({complexity}) and play time ({play_time} min)
-
[69]
Adapt all terminology, lore, and flavor to the new theme
-
[70]
Ensure the board/spatial design, setup procedure, and gameplay flow reflect the new theme coherently
-
[71]
Remember: write in prose paragraphs, not bullet-point lists
Create FAQ entries that address edge cases specific to YOUR new rulebook. Remember: write in prose paragraphs, not bullet-point lists. === DESIGN DRAFT === {draft_json} Now write the complete rulebook. [USER —2-Core / 3-Core Hybrid variant] (Same system prompt. User prompt additionally provides BOTH parent rulebooks with lineage metadata specifying which ...
-
[72]
Overall Tendency: Rating pattern (harsh/generous/balanced), which MDA layer they focus on most
-
[73]
Mechanical Preferences: Which mechanics they love/hate, which combinations excite them
-
[74]
Dynamic Preferences: What gameplay dynamics they value (tension, interaction, pacing, balance)
-
[75]
Aesthetic Preferences: What emotional experiences they seek (intellectual challenge, social fun, thematic immersion, thrill)
-
[76]
Complexity Preference: Light/medium/heavy, and how they react across the spectrum
-
[77]
Cross-Category Patterns: How their standards differ across game types
-
[78]
This player
Distinctive Traits: What makes this player unique compared to a generic reviewer ## Rules - Do NOT mention any game names (they are hidden for a reason) - Write in third person ("This player...", "They tend to...") - Ground every claim in specific evidence from the reviews - Focus on PATTERNS across reviews, not individual review summaries [USER] === PLAY...
-
[79]
match_layer: Same MDA layer identified? 5=correct layer, 3=adjacent or unclear, 1=wrong or flaw not mentioned
-
[80]
match_severity: Same severity level? 5=exact match, 3=off by one level, 1=two levels off or not mentioned
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.