MT-EditFlow: Reinforcement Learning for Multi-Turn Image Editing with Flow Matching
Pith reviewed 2026-06-28 15:05 UTC · model grok-4.3
The pith
MT-EditFlow uses flow-matching reinforcement learning to optimize multi-turn image editing rewards by broadcasting aggregated advantages across trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
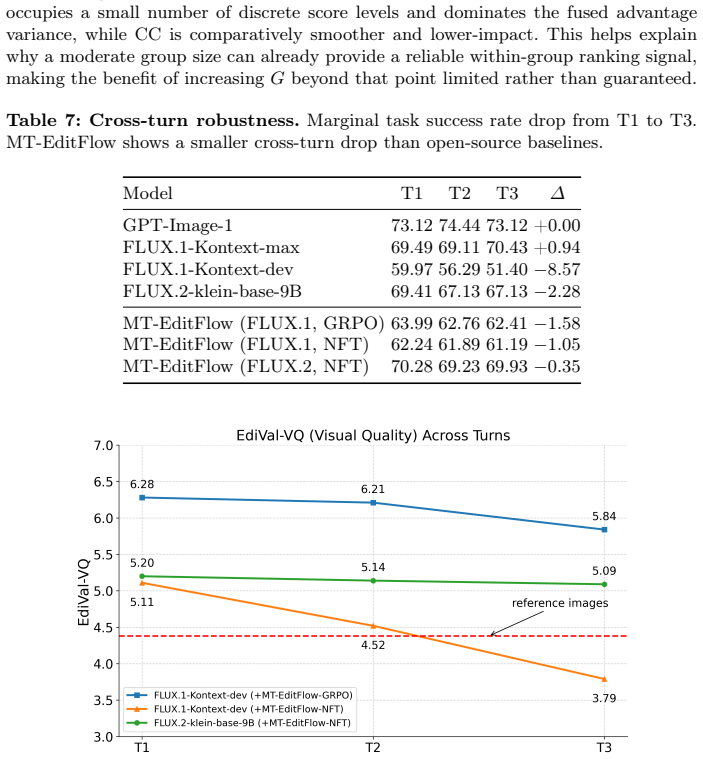
MT-EditFlow is a flow-matching reinforcement learning framework that optimizes reward signals for sequential image editing through a multi-turn perspective and multi-reward formulation applicable to both GRPO and NFT-based methods. The central discovery is that broadcasting the aggregated advantage across the entire editing trajectory bridges local planning and global multi-turn task success, reducing exposure bias without reward hacking when combined with suitable VLM reasoning modes.
What carries the argument
Broadcasting the aggregated advantage across the entire editing trajectory, which links local per-turn decisions to global multi-turn success.
If this is right
- Performance improves across diverse base models including FLUX.1-Kontext-dev.
- Turn-3 overall scores rise by 6.85 points and surpass Qwen-Image-Edit.
- Marginal success rates stay high while exposure bias falls.
- The same multi-reward structure works for both GRPO and NFT reinforcement learning.
- The approach supplies a foundation for reliable iterative human-AI image collaboration.
Where Pith is reading between the lines
- The advantage-broadcasting pattern could transfer to other sequential generation domains such as video or 3D asset editing.
- VLM-based reward variance might be further lowered by mixing multiple reasoning modes within a single training run.
- Interactive editing interfaces could become more stable if users receive turn-level feedback derived from the aggregated advantage signal.
Load-bearing premise
The assumption that broadcasting aggregated advantage across the editing trajectory bridges local planning and global multi-turn success without introducing reward hacking or bias from VLM scoring.
What would settle it
A direct comparison in which models trained with per-turn advantages instead of broadcast aggregated advantages show no gain or a drop in turn-3 overall performance relative to the single-turn baseline.
Figures


read the original abstract
Recent breakthroughs in instruction-based image editing have captured significant attention, as models are now capable of handling real-world editing demands with the practicality required by everyday users. However, editing models trained primarily for single-turn edits often break down in multi-turn editing--the natural interactive setting where a user iteratively refines an image based on the model's own previous outputs. This failure stems from the all-or-nothing requirement, where a single failed turn compromises the entire sequence, and error propagation, where exposure bias leads to compounding editing errors. To address these challenges, we introduce MT-EditFlow, a flow-matching reinforcement learning framework designed to optimize reward signals for sequential image editing. MT-EditFlow integrates a multi-turn perspective with a multi-reward formulation to provide a unified structure applicable to both GRPO and NFT-based reinforcement learning methods. We systematically analyze and optimize the reward signal by investigating effective scoring strategies for turn-level aggregation, VLM reasoning modes to trade off reward bias and variance, and advantage fusion levels to prevent reward hacking. Our findings reveal that broadcasting the aggregated advantage across the entire editing trajectory effectively bridges the gap between local planning and global multi-turn task success. Extensive experiments demonstrate that MT-EditFlow significantly improves performance across diverse base models. Notably, it boosts FLUX.1-Kontext-dev by 6.85 points in turn-3 overall performance, surpassing state-of-the-art open-source models such as Qwen-Image-Edit. By maintaining high marginal success rates and reducing exposure bias, MT-EditFlow provides a foundation for more reliable and natural human-AI collaboration in visual content creation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MT-EditFlow, a flow-matching reinforcement learning framework for multi-turn image editing that combines a multi-reward formulation with aggregated advantage broadcasting to address error propagation and exposure bias in sequential edits. It analyzes turn-level aggregation, VLM reasoning modes for bias-variance trade-offs, and advantage fusion levels, claiming that broadcasting aggregated advantages bridges local planning and global success. Extensive experiments are reported to show performance gains across base models, including a 6.85-point boost in turn-3 overall performance for FLUX.1-Kontext-dev that surpasses Qwen-Image-Edit.
Significance. If the reported gains prove robust under statistical validation and the multi-reward strategy demonstrably avoids propagating VLM biases, the work would offer a practical advance for interactive, multi-turn image editing systems that better support natural human-AI collaboration.
major comments (2)
- [Abstract and experimental results section] The central empirical claims (e.g., the 6.85-point gain on FLUX.1-Kontext-dev and surpassing of Qwen-Image-Edit) are presented without error bars, multiple-run statistics, or dataset specifications. These omissions are load-bearing because they prevent assessment of whether the improvements exceed noise or are reproducible across the claimed diverse base models.
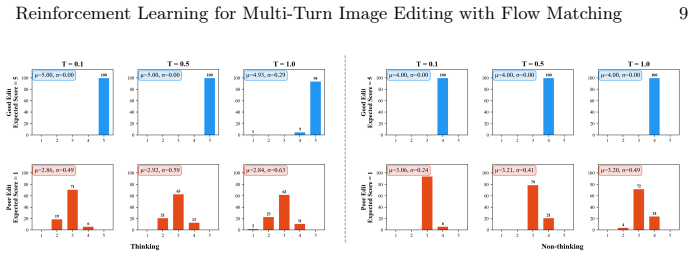
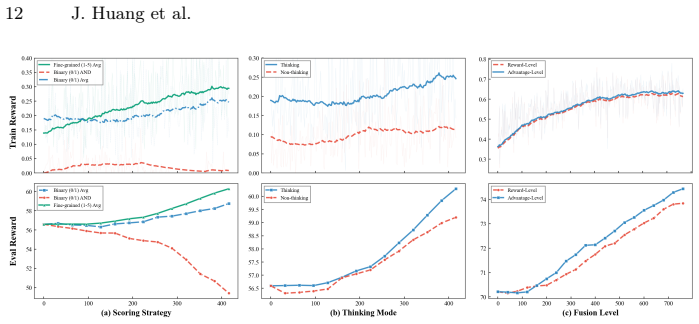
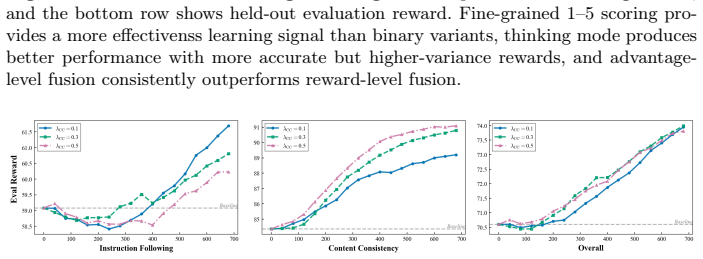
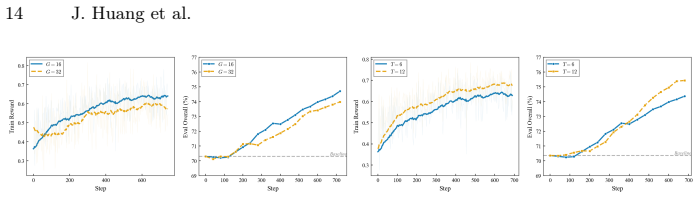
- [Reward strategy analysis and multi-reward formulation] The analysis of reward strategies claims that broadcasting aggregated advantage mitigates exposure bias without reward hacking or VLM bias propagation, yet no concrete ablation or metric is shown that isolates VLM scoring on semantic fidelity versus superficial features (e.g., color harmony) or tests for turn-dependent drift. This directly affects the validity of the multi-turn success-rate improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our empirical reporting and reward analysis. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and experimental results section] The central empirical claims (e.g., the 6.85-point gain on FLUX.1-Kontext-dev and surpassing of Qwen-Image-Edit) are presented without error bars, multiple-run statistics, or dataset specifications. These omissions are load-bearing because they prevent assessment of whether the improvements exceed noise or are reproducible across the claimed diverse base models.
Authors: We agree that error bars, multiple-run statistics, and explicit dataset specifications are necessary for assessing statistical robustness and reproducibility. The full manuscript reports results across multiple base models with the stated gains, but these details were not fully highlighted in the abstract and results summary. In the revision we will add error bars from multiple independent runs, report standard deviations, and provide complete dataset specifications to allow direct evaluation of whether the 6.85-point improvement exceeds noise. revision: yes
-
Referee: [Reward strategy analysis and multi-reward formulation] The analysis of reward strategies claims that broadcasting aggregated advantage mitigates exposure bias without reward hacking or VLM bias propagation, yet no concrete ablation or metric is shown that isolates VLM scoring on semantic fidelity versus superficial features (e.g., color harmony) or tests for turn-dependent drift. This directly affects the validity of the multi-turn success-rate improvements.
Authors: The paper presents ablations on turn-level aggregation, VLM reasoning modes, and advantage fusion levels, showing that aggregated advantage broadcasting improves multi-turn success. However, we acknowledge the need for more targeted metrics that isolate semantic fidelity from superficial features and explicit checks for turn-dependent drift. We will add these specific ablations and metrics in the revised version to further substantiate the claims about bias mitigation and exposure bias reduction. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper presents MT-EditFlow as an empirical RL framework for multi-turn image editing, with performance gains (e.g., +6.85 on FLUX.1-Kontext-dev) reported from experiments on reward aggregation, VLM scoring, and advantage broadcasting. No equations, derivations, or self-citations appear in the provided text that reduce any claimed prediction or result to its inputs by construction. The multi-reward formulation and trajectory-level broadcasting are design choices whose effectiveness is assessed via external benchmarks and ablation, not by definitional equivalence or fitted-input renaming. The derivation chain is therefore self-contained against the reported metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023) 3, 4, 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Hallucination of Multimodal Large Language Models: A Survey
Bai, Z., Wang, P., Xiao, T., He, T., Han, Z., Zhang, Z., Shou, M.Z.: Hallucination of multimodal large language models: A survey. arXiv preprint arXiv:2404.18930 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Training Diffusion Models with Reinforcement Learning
Black, K., Janner, M., Du, Y., Kostrikov, I., Levine, S.: Training diffusion models with reinforcement learning. arXiv preprint arXiv:2305.13301 (2023) 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Brooks, T., Holynski, A., Efros, A.A.: Instructpix2pix: Learning to follow image editing instructions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18392–18402 (2023) 4
2023
-
[5]
Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D.M., Wu, J., Win- ter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[6]
In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G
Chang, Y., Zhang, Y., Fang, Z., Wu, Y.N., Bisk, Y., Gao, F.: Skews in the phe- nomenon space hinder generalization in text-to-image generation. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision – ECCV 2024. pp. 422–439. Springer Nature Switzerland, Cham (2025) 4
2024
-
[7]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Chen, B., Xu, Z., Kirmani, S., Ichter, B., Sadigh, D., Guibas, L., Xia, F.: Spa- tialvlm: Endowing vision-language models with spatial reasoning capabilities. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 14455–14465 (2024) 4
2024
-
[8]
In: The Fourteenth International Conference on Learning Representations (2026),https://openreview.net/forum?id=YkV0fnXgJA2, 3, 4, 7, 8, 10, 11
Chen, T., Zhang, Y., Zhang, Z., Yu, P., Wang, S., Wang, Z., Lin, K., Wang, X., Yang, Z., Li, L., Lin, C.C., Xie, J., Leong, O., Wang, L., Wu, Y.N., Zhou, M.: Edival-agent: An object-centric framework for automated, fine-grained evaluation of multi-turn editing. In: The Fourteenth International Conference on Learning Representations (2026),https://openrevi...
2026
-
[9]
Advances in Neural Information Processing Systems37, 135062–135093 (2024) 4
Cheng, A.C., Yin, H., Fu, Y., Guo, Q., Yang, R., Kautz, J., Wang, X., Liu, S.: Spatialrgpt: Grounded spatial reasoning in vision-language models. Advances in Neural Information Processing Systems37, 135062–135093 (2024) 4
2024
-
[10]
Deepmind, G.: Gemini 2.5: Pushing the frontier with advanced reasoning, mul- timodality, long context, and next generation agentic capabilities (2025),https: //arxiv.org/abs/2507.062612, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Advances in Neural Information Processing Sys- tems36, 79858–79885 (2023) 4
Fan, Y., Watkins, O., Du, Y., Liu, H., Ryu, M., Boutilier, C., Abbeel, P., Ghavamzadeh, M., Lee, K., Lee, K.: Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models. Advances in Neural Information Processing Sys- tems36, 79858–79885 (2023) 4
2023
-
[12]
Gao, Y., Gong, L., Guo, Q., Hou, X., Lai, Z., Li, F., Li, L., Lian, X., Liao, C., Liu, L., et al.: Seedream 3.0 technical report. arXiv preprint arXiv:2504.11346 (2025) 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Huang et al
Gemini2, G.: Experiment with gemini 2.0 flash native image generation.https:// developers.googleblog.com/en/experiment-with-gemini-20-flash-native- image-generation/(2025), accessed: 2025-06-22 4 16 J. Huang et al
2025
-
[14]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
In: ICLR (2023) 4
Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., Cohen-Or, D.: Prompt-to-prompt image editing with cross-attention control. In: ICLR (2023) 4
2023
-
[16]
Advances in neural information processing systems33, 6840–6851 (2020) 4, 5
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020) 4, 5
2020
-
[17]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022) 5
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Iclr1(2), 3 (2022) 11
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022) 11
2022
-
[19]
arXiv preprint arXiv:2404.09990 (2024) 4
Hui, M., Yang, S., Zhao, B., Shi, Y., Wang, H., Wang, P., Zhou, Y., Xie, C.: Hq- edit: A high-quality dataset for instruction-based image editing. arXiv preprint arXiv:2404.09990 (2024) 4
- [20]
-
[21]
International journal of computer vision128(7), 1956–1981 (2020) 10
Kuznetsova, A., Rom, H., Alldrin, N., Uijlings, J., Krasin, I., Pont-Tuset, J., Ka- mali, S., Popov, S., Malloci, M., Kolesnikov, A., et al.: The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. International journal of computer vision128(7), 1956–1981 (2020) 10
1956
-
[22]
Labs, B.F.: FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2 (2025) 2, 3, 11
2025
-
[23]
Labs,B.F.,Batifol,S.,Blattmann,A.,Boesel,F.,Consul,S.,Diagne,C.,Dockhorn, T., English, J., English, Z., Esser, P., Kulal, S., Lacey, K., Levi, Y., Li, C., Lorenz, D., Müller, J., Podell, D., Rombach, R., Saini, H., Sauer, A., Smith, L.: Flux.1 kontext: Flow matching for in-context image generation and editing in latent space (2025),https://arxiv.org/abs/2...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Li, J., Cui, Y., Huang, T., Ma, Y., Fan, C., Yang, M., Zhong, Z.: Mixgrpo: Unlock- ing flow-based grpo efficiency with mixed ode-sde (2025),https://arxiv.org/ abs/2507.218025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Li, Z., Liu, Z., Zhang, Q., Lin, B., Yuan, S., Yan, Z., Ye, Y., Yu, W., Niu, Y., Yuan, L.: Uniworld-v2: Reinforce image editing with diffusion negative-aware finetuning and mllm implicit feedback. arXiv preprint arXiv:2510.16888 (2025) 3, 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024) 4
Liang, Y., He, J., Li, G., Li, P., Klimovskiy, A., Carolan, N., Sun, J., Pont-Tuset, J., Young, S., Yang, F., Ke, J., Dvijotham, K.D., Collins, K., Luo, Y., Li, Y., Kohlhoff, K.J., Ramachandran, D., Navalpakkam, V.: Rich human feedback for text-to-image generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024) 4
2024
-
[27]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022) 2, 4, 5
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
In: The Thirty- ninthAnnualConferenceonNeuralInformationProcessingSystems(2025),https: //openreview.net/forum?id=oCBKGw5HNf2, 4, 6, 11
Liu, J., Liu, G., Liang, J., Li, Y., Liu, J., Wang, X., Wan, P., ZHANG, D., Ouyang, W.: Flow-GRPO: Training flow matching models via online RL. In: The Thirty- ninthAnnualConferenceonNeuralInformationProcessingSystems(2025),https: //openreview.net/forum?id=oCBKGw5HNf2, 4, 6, 11
2025
-
[29]
Step1X-Edit: A Practical Framework for General Image Editing
Liu, S., Han, Y., Xing, P., Yin, F., Wang, R., Cheng, W., Liao, J., Wang, Y., Fu, H., Han, C., et al.: Step1x-edit: A practical framework for general image editing. arXiv preprint arXiv:2504.17761 (2025) 2, 3, 4, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022) 2, 4, 5 Reinforcement Learning for Multi-Turn Image Editing with Flow Matching 17
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
In: The Fourteenth International Conference on Learning Representations (2026), https://openreview.net/forum?id=E7YpL4L4Xh3, 5, 7
Luo, X., Wang, J., Wu, C., Xiao, S., Jiang, X., Lian, D., Zhang, J., Liu, D., Liu, Z.: Editscore: Unlocking online RL for image editing via high-fidelity reward modeling. In: The Fourteenth International Conference on Learning Representations (2026), https://openreview.net/forum?id=E7YpL4L4Xh3, 5, 7
2026
-
[32]
Ad- vances in Neural Information Processing Systems37, 41494–41516 (2024) 4
Ma, Y., Ji, J., Ye, K., Lin, W., Wang, Z., Zheng, Y., Zhou, Q., Sun, X., Ji, R.: I2ebench: A comprehensive benchmark for instruction-based image editing. Ad- vances in Neural Information Processing Systems37, 41494–41516 (2024) 4
2024
- [33]
-
[34]
com / index / introducing-4o-image-generation/(2025), accessed: 2025-06-22 2, 4
OpenAI: Introducing 4o image generation.https : / / openai . com / index / introducing-4o-image-generation/(2025), accessed: 2025-06-22 2, 4
2025
-
[35]
Lvlm- count: Enhancing the counting ability of large vision-language models, 2026
Qharabagh, M.F., Ghofrani, M., Fountoulakis, K.: Lvlm-count: Enhancing the counting ability of large vision-language models. arXiv preprint arXiv:2412.00686 (2024) 4
- [36]
-
[37]
arXiv preprint arXiv:2505.11493 , year=
Qian, Y., Lu, J., Fu, T.J., Wang, X., Chen, C., Yang, Y., Hu, W., Gan, Z.: Gie- bench: Towards grounded evaluation for text-guided image editing. arXiv preprint arXiv:2505.11493 (2025) 8
-
[38]
In: SC20: international conference for high performance computing, networking, storage and analysis
Rajbhandari, S., Rasley, J., Ruwase, O., He, Y.: Zero: Memory optimizations to- ward training trillion parameter models. In: SC20: international conference for high performance computing, networking, storage and analysis. pp. 1–16. IEEE (2020) 11
2020
-
[39]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022) 2, 4
2022
-
[40]
Generalization in generation: A closer look at exposure bias.arXiv preprint arXiv:1910.00292, 2019
Schmidt, F.: Generalization in generation: A closer look at exposure bias. arXiv preprint arXiv:1910.00292 (2019) 2
-
[41]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017) 4
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sheynin, S., Polyak, A., Singer, U., Kirstain, Y., Zohar, A., Ashual, O., Parikh, D., Taigman, Y.: Emu edit: Precise image editing via recognition and generation tasks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8871–8879 (2024) 7
2024
-
[43]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025) 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Advances in neural information processing systems34, 1415–1428 (2021) 4
Song, Y., Durkan, C., Murray, I., Ermon, S.: Maximum likelihood training of score- based diffusion models. Advances in neural information processing systems34, 1415–1428 (2021) 4
2021
-
[45]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020) 4, 6
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[46]
Journal of Cognitive Neuroscience11(1), 126–134 (1999) 2, 4, 5
Sutton, R.S., Barto, A.G., et al.: Reinforcement learning. Journal of Cognitive Neuroscience11(1), 126–134 (1999) 2, 4, 5
1999
-
[47]
Vision Language Models are Biased
Vo, A., Nguyen, K.N., Taesiri, M.R., Dang, V.T., Nguyen, A.T., Kim, D.: Vision language models are biased. arXiv preprint arXiv:2505.23941 (2025) 4 18 J. Huang et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., ming Yin, S., Bai, S., Xu, X., Chen, Y., Chen, Y., Tang, Z., Zhang, Z., Wang, Z., Yang, A., Yu, B., Cheng, C., Liu, D., Li, D., Zhang, H., Meng, H., Wei, H., Ni, J., Chen, K., Cao, K., Peng, L., Qu, L., Wu, M., Wang, P., Yu, S., Wen, T., Feng, W., Xu, X., Wang, Y., Zhang, Y., Zhu, Y., Wu, Y., Cai, Y., L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Wu, C., Zheng, P., Yan, R., Xiao, S., Luo, X., Wang, Y., Li, W., Jiang, X., Liu, Y., Zhou, J., Liu, Z., Xia, Z., Li, C., Deng, H., Wang, J., Luo, K., Zhang, B., Lian, D., Wang, X., Wang, Z., Huang, T., Liu, Z.: Omnigen2: Exploration to advanced multimodal generation. arXiv preprint arXiv:2506.18871 (2025) 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
In: The Fourteenth In- ternational Conference on Learning Representations (2026),https://openreview
Wu, K., Jiang, S., Ku, M., Nie, P., Liu, M., Chen, W.: Editreward: A human- aligned reward model for instruction-guided image editing. In: The Fourteenth In- ternational Conference on Learning Representations (2026),https://openreview. net/forum?id=eZu358JOOR3, 7
2026
-
[51]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xiao, S., Wang, Y., Zhou, J., Yuan, H., Xing, X., Yan, R., Li, C., Wang, S., Huang, T., Liu, Z.: Omnigen: Unified image generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 13294–13304 (2025) 2, 4
2025
-
[52]
In: Proceedingsofthe37thInternationalConferenceonNeuralInformationProcessing Systems
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: learning and evaluating human preferences for text-to-image generation. In: Proceedingsofthe37thInternationalConferenceonNeuralInformationProcessing Systems. pp. 15903–15935 (2023) 4
2023
-
[53]
DanceGRPO: Unleashing GRPO on Visual Generation
Xue, Z., Wu, J., Gao, Y., Kong, F., Zhu, L., Chen, M., Liu, Z., Liu, W., Guo, Q., Huang, W., et al.: Dancegrpo: Unleashing grpo on visual generation. arXiv preprint arXiv:2505.07818 (2025) 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025) 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
arXiv preprint arXiv:2504.13143 , year=
Yang, S., Hui, M., Zhao, B., Zhou, Y., Ruiz, N., Xie, C.: Complex-edit: Cot-like instruction generation for complexity-controllable image editing benchmark. arXiv preprint arXiv:2504.13143 (2025) 2, 4
-
[56]
In: The Thirty-ninth Annual Confer- ence on Neural Information Processing Systems Datasets and Benchmarks Track (2025),https://openreview.net/forum?id=uUCSrMlfD32, 3, 4, 7, 11
Ye, Y., He, X., Li, Z., Lin, B., Yuan, S., Yan, Z., Hou, B., Yuan, L.: Imgedit: A unified image editing dataset and benchmark. In: The Thirty-ninth Annual Confer- ence on Neural Information Processing Systems Datasets and Benchmarks Track (2025),https://openreview.net/forum?id=uUCSrMlfD32, 3, 4, 7, 11
2025
-
[57]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yu, Q., Chow, W., Yue, Z., Pan, K., Wu, Y., Wan, X., Li, J., Tang, S., Zhang, H., Zhuang, Y.: Anyedit: Mastering unified high-quality image editing for any idea. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 26125–26135 (2025) 4, 7
2025
-
[58]
Advances in Neural Information Pro- cessing Systems36, 31428–31449 (2023) 4, 7
Zhang, K., Mo, L., Chen, W., Sun, H., Su, Y.: Magicbrush: A manually annotated dataset for instruction-guided image editing. Advances in Neural Information Pro- cessing Systems36, 31428–31449 (2023) 4, 7
2023
-
[59]
In: Leonardis, A., Ricci, E., Roth, S., Rus- sakovsky, O., Sattler, T., Varol, G
Zhang,Y.,Yu,P.,Wu,Y.N.:Object-conditionedenergy-basedattentionmapalign- ment in text-to-image diffusion models. In: Leonardis, A., Ricci, E., Roth, S., Rus- sakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision – ECCV 2024. pp. 55–71. Springer Nature Switzerland, Cham (2025) 4
2024
-
[60]
Zhang, Y., Yu, P., Zhu, Y., Chang, Y., Gao, F., Wu, Y.N., Leong, O.: Flow pri- ors for linear inverse problems via iterative corrupted trajectory matching. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum?id=1H2e7USI094 Reinforcement Learning for Multi-Turn Image Editing with Flow Matching 19
2024
-
[61]
In: The Thirteenth International Conference on Learning Rep- resentations (2025),https://openreview.net/forum?id=84pDoCD4lH4
Zhang, Z., Hu, F., Lee, J., Shi, F., Kordjamshidi, P., Chai, J., Ma, Z.: Do vision- language models represent space and how? evaluating spatial frame of reference under ambiguities. In: The Thirteenth International Conference on Learning Rep- resentations (2025),https://openreview.net/forum?id=84pDoCD4lH4
2025
-
[62]
Advances in Neural Information Processing Systems37, 3058–3093 (2024) 4, 7
Zhao, H., Ma, X.S., Chen, L., Si, S., Wu, R., An, K., Yu, P., Zhang, M., Li, Q., Chang, B.: Ultraedit: Instruction-based fine-grained image editing at scale. Advances in Neural Information Processing Systems37, 3058–3093 (2024) 4, 7
2024
-
[63]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Zhao,Y.,Gu,A.,Varma,R.,Luo,L.,Huang,C.C.,Xu,M.,Wright,L.,Shojanazeri, H., Ott, M., Shleifer, S., et al.: Pytorch fsdp: experiences on scaling fully sharded data parallel. arXiv preprint arXiv:2304.11277 (2023) 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
In: The Fourteenth International Conference on Learning Representations (2026),https://openreview.net/forum?id=VJZ477R89F2, 5, 6, 11 20 J
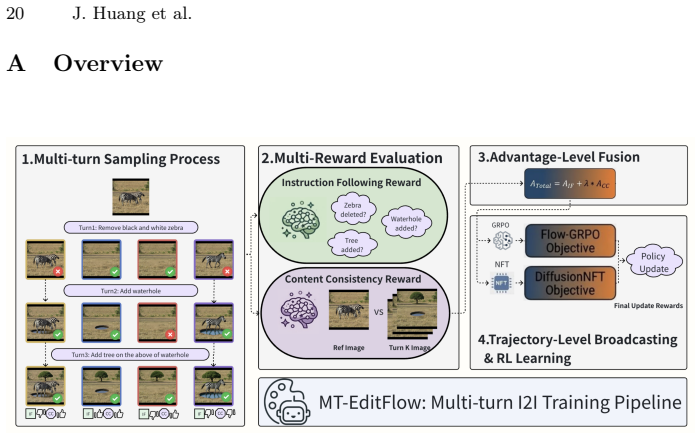
Zheng, K., Chen, H., Ye, H., Wang, H., Zhang, Q., Jiang, K., Su, H., Ermon, S., Zhu, J., Liu, M.Y.: DiffusionNFT: Online diffusion reinforcement with forward process. In: The Fourteenth International Conference on Learning Representations (2026),https://openreview.net/forum?id=VJZ477R89F2, 5, 6, 11 20 J. Huang et al. A Overview Fig.8: Overview of MT-EditF...
2026
-
[69]
Then give final score 1-5 in <Score> <Thought> [Analysis here] </Thought> <Score>X</Score> Multi-turn IF prompt
Fully Compliant: Instruction accurately and completely executed, all non-targeted original content perfectly preserved Provide analysis in <Thought> tag covering: instruction execution accuracy and completeness, preservation of non-targeted elements, unintended changes. Then give final score 1-5 in <Score> <Thought> [Analysis here] </Thought> <Score>X</Sc...
-
[70]
Failed: Instruction completely ignored/opposite changes made, or critical original content destroyed
-
[71]
Minimal: Only minor parts of instruction followed, major elements missing/wrong, or severe content loss/unintended changes
-
[72]
Partial: Key instruction elements followed but incomplete/ inaccurate, with noticeable original content loss/unintended modifications
-
[73]
Mostly Compliant: Instruction largely executed correctly with minor flaws, original content well-preserved with minimal unintended changes
-
[74]
Fully Compliant: Instruction accurately and completely executed, all non-targeted original content perfectly preserved Provide analysis in <Thought> tag covering each turn’s execution. Then give scores in format: <Thought> [Turn 1 analysis] [Turn 2 analysis] [Turn 3 analysis] </Thought> <Turn1Score>X</Turn1Score> <Turn2Score>X</Turn2Score> <Turn3Score>X</...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.