TIDES: Time-Derivative Event Simulation via Deformable Reconstruction
Pith reviewed 2026-06-28 15:31 UTC · model grok-4.3
The pith
TIDES derives per-pixel intensity changes continuously from a dynamic Gaussian splatting scene to predict event timestamps without batching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
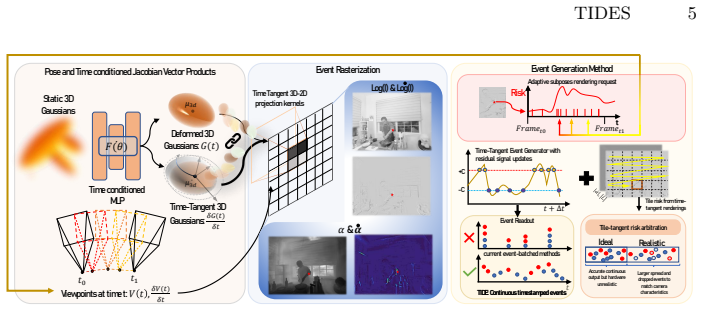
TIDES is a continuous-time event simulator built on dynamic Gaussian splatting. Because it operates on an explicit 3D scene representation with learnt geometry and motion, it derives per-pixel intensity dynamics directly from the scene rather than by differencing rendered frames, enabling accurate threshold-crossing prediction including multiple crossings per rendering step without temporal upsampling, guided adaptive stepping based on partial occlusions, and realistic sensor artifact modeling via a tile-level arbiter.
What carries the argument
Dynamic Gaussian splatting representation that supplies explicit 3D geometry, motion, and partial occlusion data to compute continuous per-pixel intensity dynamics and direct adaptive simulation steps.
If this is right
- Simulated event streams achieve higher fidelity to real paired RGB-event data than frame-differencing simulators.
- Events from TIDES transfer more effectively to real downstream tasks such as detection or tracking.
- Multiple brightness threshold crossings can be predicted within a single rendering interval.
- Computation concentrates only in regions where occlusion dynamics invalidate simple brightness change models.
- Finite sensor bandwidth effects are reproduced through tile-level arbitration of event throughput and drops.
Where Pith is reading between the lines
- The same 3D motion model could support simulation of other asynchronous sensors that respond to appearance change.
- If the Gaussian representation holds under varied lighting, it might allow training of event-based models with far less real sensor data.
- Adaptive stepping based on occlusion could be tested for efficiency gains on longer video sequences with static backgrounds.
Load-bearing premise
The dynamic Gaussian splatting representation accurately captures scene geometry, motion, and partial occlusions so derived intensity dynamics match real sensor behavior without post-hoc corrections.
What would settle it
A benchmark sequence with rapid object motion and layered occlusions where the number and timing distribution of TIDES-generated events deviates measurably from paired real event camera recordings.
Figures



read the original abstract
Event cameras emit asynchronous events in response to environmental appearance changes. The scarcity of real-world event datasets makes simulation essential. However, most simulators infer event timestamps from frame sequences, forcing many threshold crossings to share a small set of discrete times; a failure mode we term timestamp batching that worsens under fast motion and occlusion. We present TIDES, a continuous-time event simulator built on dynamic Gaussian splatting. Because TIDES operates on an explicit 3D scene representation with learnt geometry and motion, it can derive per-pixel intensity dynamics directly from the scene, rather than by differencing rendered frames. This enables accurate threshold-crossing prediction, including multiple crossings per rendering step, without temporal upsampling or frame interpolation. The same 3D scene model reveals where objects partially occlude one another; TIDES uses this to guide adaptive time stepping, concentrating computation only in regions where occlusion dynamics make simple models of brightness change unreliable. Finally, we model finite sensor bandwidth using a tile-level arbiter whose throughput, jitter, and event drops reproduce realistic sensor artifacts. Across paired RGB-event benchmarks, TIDES attains state-of-the-art event-stream fidelity. We also show that events simulated by TIDES transfer more effectively to real downstream tasks than competitors'.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TIDES, a continuous-time event simulator based on dynamic Gaussian splatting. It derives per-pixel intensity dynamics directly from an explicit 3D deformable scene model rather than frame differencing, enabling multi-crossing threshold prediction, adaptive stepping guided by occlusion, and modeling of sensor bandwidth artifacts. The central claims are state-of-the-art fidelity on paired RGB-event benchmarks and superior transfer of simulated events to real downstream tasks compared to prior simulators.
Significance. If the quantitative claims hold and the core assumption about accurate intensity trajectory recovery is validated, the work would advance event simulation by replacing discrete frame-based methods with direct differentiation from learned 3D geometry and motion. This could reduce timestamp batching artifacts in fast-motion and occluded scenes and improve utility for data-scarce event-vision applications.
major comments (2)
- [Abstract] Abstract: The assertion of 'state-of-the-art event-stream fidelity' and 'more effective transfer to real downstream tasks' is presented without any quantitative metrics, specific baselines, ablation results, or error analysis, making it impossible to assess whether the central claims are supported by the experiments.
- [Abstract] Abstract (and implied method sections): The claim that the dynamic Gaussian splatting representation accurately captures per-pixel continuous intensity trajectories (including under partial occlusion) without post-hoc corrections is load-bearing for the SOTA fidelity result, yet no independent diagnostic such as high-speed intensity ground truth, per-pixel error curves, or radiance/motion bias analysis is referenced to confirm the assumption holds on the evaluation scenes.
minor comments (1)
- [Abstract] Abstract: The newly introduced term 'timestamp batching' would benefit from a short inline definition or citation to prior work for readers unfamiliar with the failure mode.
Simulated Author's Rebuttal
We thank the referee for the comments. We address each point below and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion of 'state-of-the-art event-stream fidelity' and 'more effective transfer to real downstream tasks' is presented without any quantitative metrics, specific baselines, ablation results, or error analysis, making it impossible to assess whether the central claims are supported by the experiments.
Authors: The abstract is a concise summary; the full quantitative metrics, baselines (including ESIM and V2E), ablations, and error analysis appear in Sections 4 and 5 with supporting tables and figures. We will revise the abstract to incorporate key numerical results (e.g., fidelity metrics and downstream gains) so the claims can be assessed directly from the abstract. revision: yes
-
Referee: [Abstract] Abstract (and implied method sections): The claim that the dynamic Gaussian splatting representation accurately captures per-pixel continuous intensity trajectories (including under partial occlusion) without post-hoc corrections is load-bearing for the SOTA fidelity result, yet no independent diagnostic such as high-speed intensity ground truth, per-pixel error curves, or radiance/motion bias analysis is referenced to confirm the assumption holds on the evaluation scenes.
Authors: Section 3 details the direct derivation of per-pixel intensity trajectories from the explicit 3D deformable model without frame differencing or post-hoc corrections, with adaptive occlusion-guided stepping in Section 3.3. The paired RGB-event benchmarks (which include fast motion and occlusion) provide the primary validation through end-to-end fidelity. We will revise the abstract to explicitly reference these method sections and the benchmark validation approach. revision: yes
Circularity Check
No circularity: forward simulation from independent 3D reconstruction
full rationale
The abstract and description present TIDES as a forward derivation of per-pixel intensity trajectories from an explicit dynamic Gaussian splatting scene model (learned geometry and motion), followed by direct differentiation, occlusion-aware adaptive stepping, and a bandwidth model. No equation or step is shown to reduce by construction to event data fitting, self-citation of a uniqueness result, or renaming of an input pattern. The claimed SOTA fidelity is an external evaluation on paired benchmarks, not a tautological output of the simulator itself. The central assumption (accurate intensity recovery) is a modeling claim subject to empirical test rather than a definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dynamic Gaussian splatting can represent scene geometry and motion sufficiently well to derive continuous per-pixel intensity changes that match real event camera behavior.
Reference graph
Works this paper leans on
-
[1]
Bhattacharya, A., Madaan, R., Cladera, F., Vemprala, S., Bonatti, R., Daniilidis, K., Kapoor, A., Kumar, V., Matni, N., Gupta, J.K.: Evdnerf: Reconstructing event datawithdynamicneuralradiancefields.In:ProceedingsoftheIEEE/CVFWinter Conference on Applications of Computer Vision (WACV). pp. 5846–5855 (Jan 2024)
2024
-
[2]
https://doi.org/10.1109/JSSC.2014.2342715
Brandli, C., Berner, R., Yang, M., Liu, S.C., Delbruck, T.: A 240×180 130 db 3 µs latency global shutter spatiotemporal vision sensor49(10), 2333–2341 (2014). https://doi.org/10.1109/JSSC.2014.2342715
-
[3]
Chen, Y., Alliez, P., Aubry, M., Barrau, A., Cabon, Y., Revaud, J.: Easi3r: Es- timating disentangled motion from dust3r. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2025).https://doi. org/10.48550/arXiv.2503.24391,https://www.cvlibs.net/publications/ Chen2025ICCV.pdf
-
[4]
arXiv preprint arXiv:2501.02807 (2025)
Feng, C., Yu, W., Cheng, X., Tang, Z., Zhang, J., Yuan, L., Tian, Y.: Ae-nerf: Augmenting event-based neural radiance fields for non-ideal conditions and larger scene. arXiv preprint arXiv:2501.02807 (2025)
arXiv 2025
-
[5]
In: Proceedings of the 33rd ACM International Conference on Multimedia (ACM MM)
Feng, C., Yu, W., Cheng, X., Tang, Z., Zhang, J., Yuan, L., Tian, Y.: E-4dgs: High- fidelity dynamic reconstruction from the multi-view event cameras. In: Proceedings of the 33rd ACM International Conference on Multimedia (ACM MM). pp. 7356– 7365 (2025).https://doi.org/10.1145/3746027.3754777
-
[6]
Gallego, G., Delbrück, T., Orchard, G., Bartolozzi, C., Taba, B., Censi, A., Leutenegger, S., Davison, A.J., Conradt, J., Daniilidis, K., Scaramuzza, D.: Event- based vision: A survey44(1), 154–180 (2022).https://doi.org/10.1109/TPAMI. 2020.3008413
-
[7]
IEEE Robotics and Automation Letters (7 2021)
Gehrig, M., Aarents, W., Gehrig, D., Scaramuzza, D.: Dsec: A stereo event camera dataset for driving scenarios. IEEE Robotics and Automation Letters (7 2021). https://doi.org/10.1109/LRA.2021.3068942,https://magehrig.github.io/ publication/gehrig-2021-ral-dsec/
-
[8]
Ghosh, D.K., Jung, Y.J.: Two-stage cross-fusion network for stereo event-based depth estimation. Expert Systems with Applications241, 122743 (2024).https: //doi.org/https://doi.org/10.1016/j.eswa.2023.122743,https://www. sciencedirect.com/science/article/pii/S0957417423032451
-
[9]
Ghosh, D.K., Jung, Y.J.: Depth cue fusion for event-based stereo depth estimation. Information Fusion117, 102891 (2025).https://doi.org/https://doi.org/ 10.1016/j.inffus.2024.102891,https://www.sciencedirect.com/science/ article/pii/S1566253524006699
-
[10]
In: Advances in Neural Information Pro- cessing Systems
Han, H., Li, J., Wei, H., Ji, X.: Event-3dgs: Event-based 3d reconstruc- tion using 3d gaussian splatting. In: Advances in Neural Information Pro- cessing Systems. vol. 37 (2024).https : / / doi . org / 10 . 52202 / 079017 - 4069,https : / / proceedings . neurips . cc / paper _ files / paper / 2024 / hash / e73ad1f690542144ce354637bb913c35-Abstract-Confer...
2024
-
[11]
Han, H., Lyu, J., Li, J., Wei, H., Li, C., Wei, Y., Chen, S., Ji, X.: Physical-based event camera simulator. In: Computer Vision – ECCV 2024. pp. 19–35 (2024). https://doi.org/10.1007/978- 3- 031- 72995- 9_2,https://www.ecva.net/ papers/eccv_2024/papers_ECCV/papers/06110.pdf
-
[12]
Hidalgo-Carrió, J., Gallego, G., Scaramuzza, D.: Event-aided direct sparse odome- try. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022).https://doi.org/10.48550/arXiv.2204.07640, 16 F. Author et al. https://openaccess.thecvf.com/content/CVPR2022/html/Hidalgo- Carrio_ Event-Aided_Direct_Sparse_Odometry_CVP...
-
[13]
Hu, Y., Liu, S.C., Delbruck, T.: v2e: From video frames to realistic dvs events. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). pp. 1312–1319 (2021).https://doi.org/ 10.1109/CVPRW53098.2021.00152,https://openaccess.thecvf.com/content/ CVPR2021W/EventVision/html/Hu_v2e_From_Video_Frames_to_Realistic...
-
[14]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Hwang, I., Kim, J., Kim, Y.M.: Ev-nerf: Event based neural radiance field. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 837–847 (Jan 2023)
2023
-
[15]
https://doi.org/10.3389/fnins.2021.702765
Joubert, D., Marcireau, A., Ralph, N., Jolley, A., van Schaik, A., Cohen, G.: Event camera simulator improvements via characterized parameters15, 702765 (2021). https://doi.org/10.3389/fnins.2021.702765
-
[16]
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering (2023).https://doi.org/10.1145/3592433
-
[17]
Expert Systems with Applications223, 119917 (2023)
Kim, J., Ghosh, D.K., Jung, Y.J.: Event-based video deblurring based on image and event feature fusion. Expert Systems with Applications223, 119917 (2023). https://doi.org/https://doi.org/10.1016/j.eswa.2023.119917,https:// www.sciencedirect.com/science/article/pii/S0957417423004189
-
[18]
IEEE Robotics and Automation Letters8(3), 1587– 1594 (2023).https://doi.org/10.1109/LRA.2023.3240646
Klenk, S., Koestler, L., Scaramuzza, D., Cremers, D.: E-nerf: Neural radiance fields from a moving event camera. IEEE Robotics and Automation Letters8(3), 1587– 1594 (2023).https://doi.org/10.1109/LRA.2023.3240646
-
[19]
Lichtsteiner, P., Posch, C., Delbruck, T.: A 128×128 120 db 15µs latency asyn- chronous temporal contrast vision sensor43(2), 566–576 (2008).https://doi. org/10.1109/JSSC.2007.914337
-
[20]
In: Computer Vision – ECCV 2022
Lin, S., Ma, Y., Guo, Z., Wen, B.: Dvs-voltmeter: Stochastic process-based event simulator for dynamic vision sensors. In: Computer Vision – ECCV 2022. pp. 578– 593 (2022).https://doi.org/10.1007/978-3-031-20071-7_34
-
[21]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (Oct 2023)
Low, W.F., Lee, F.C., Lim, L.P., Khor, K.H., Ng, H.Z., Cheong, L.F.: Robust e- nerf: Nerf from sparse & noisy events under non-uniform motion. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (Oct 2023)
2023
-
[22]
Ma, Y., Guo, S., Chen, Y., Xue, T., Gu, J.: Timelens-xl: Real-time event-based videoframeinterpolationwithlargemotion.In:EuropeanConferenceonComputer Vision (ECCV) (2024)
2024
-
[23]
Mueggler, E., Gallego, G., Rebecq, H., Scaramuzza, D.: The event-camera dataset and simulator: Event-based data for pose estimation, visual odometry, and slam (2017)
2017
-
[24]
neuromorphicsystems: IEBCS: ICNS event based camera simulator (2023),https: //github.com/neuromorphicsystems/IEBCS
2023
-
[25]
In: Proceedings of the Conference on Robot Learning (CoRL)
Rebecq, H., Gehrig, D., Scaramuzza, D.: Esim: An open event camera simulator. In: Proceedings of the Conference on Robot Learning (CoRL). pp. 969–982 (2018), https://proceedings.mlr.press/v87/rebecq18a.html
2018
-
[26]
Rebecq, H., Ranftl, R., Koltun, V., Scaramuzza, D.: High speed and high dynamic range video with an event camera (2019)
2019
-
[27]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR)
Rudnev, V., Elgharib, M., Theobalt, C., Golyanik, V.: Eventnerf: Neural radiance fields from a single colour event camera. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR). pp. 4992–5002 (Jun 2023) TIDES 17
2023
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops
Rudnev, V., Fox, G., Elgharib, M., Theobalt, C., Golyanik, V.: Dynamic eventnerf: Reconstructing general dynamic scenes from multi-view rgb and event streams. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. pp. 4905–4915 (Jun 2025)
2025
-
[29]
European Conference on Computer Vision
Sun*, Z., Messikommer*, N., Gehrig, D., Scaramuzza, D.: Ess: Learning event- based semantic segmentation from still images. European Conference on Computer Vision. (ECCV) (2022)
2022
-
[30]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Thirgood, C., Mendez, O., Ling, E., Storey, J., Hadfield, S.: HyperGS: Hyper- spectral 3d gaussian splatting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5970–5979.https: / / doi . org / 10 . 1109 / CVPR52734 . 2025 . 00560,https : / / openaccess . thecvf . com/content/CVPR2025/html/Thirgood_HyperGS_Hy...
2025
-
[31]
Thirgood, C., Mendez Maldonado, O., Ling, E.C., Storey, J., Hadfield, S.: Fea- tureSLAM: Feature-enriched 3d gaussian splatting SLAM in real time,https: //arxiv.org/abs/2601.05738
-
[32]
Thirgood, C., Mendez Maldonado, O., Ling, E.C., Storey, J., Hadfield, S.: HYDRA: HYbrid knowledge distillation and spectral reconstruction algorithm for high- channel hyperspectral camera applications,https://arxiv.org/abs/2510.16664
-
[33]
In: 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Thirgood, C.T., Mendez Maldonado, O.A., Ling, C., Storey, J., Hadfield, S.J.: RaSpectLoc: RAman SPECTroscopy-dependent robot LOCalisation. In: 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 5296–5303. IEEE.https://doi.org/10.1109/IROS55552.2023.10342198
-
[34]
Tulyakov, S., Bochicchio, A., Gehrig, D., Georgoulis, S., Li, Y., Scaramuzza, D.: Time lens++: Event-based frame interpolation with parametric non-linear flow and multi-scale fusion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022),https : / / openaccess.thecvf.com/content/CVPR2022/html/Tulyakov_Time_Lens...
2022
-
[35]
Tulyakov, S., Gehrig, D., Georgoulis, S., Erbach, J., Gehrig, M., Li, Y., Scara- muzza, D.: Time lens: Event-based video frame interpolation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021),https://openaccess.thecvf.com/content/CVPR2021/html/Tulyakov_ Time_Lens_Event-Based_Video_Frame_Interpolation_CVPR_...
2021
-
[36]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024),https://github.com/naver/ dust3r
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: Dust3r: Geometric 3d vision made easy. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024),https://github.com/naver/ dust3r
2024
-
[37]
Wu, G., Yi, T., Fang, J., Xie, L., Zhang, X., Wei, W., Liu, W., Tian, Q., Wang, X.: 4d gaussian splatting for real-time dynamic scene rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 20310–20320 (2024).https://doi.org/10.1109/CVPR52733.2024.01920, https://openaccess.thecvf.com/content/CVPR2024/pa...
-
[38]
In: ConferenceonRobotLearning,6-9November2024,Munich,Germany.Proceedings of Machine Learning Research, vol
Xiong, T., Wu, J., He, B., Fermüller, C., Aloimonos, Y., Huang, H., Metzler, C.A.: Event3dgs: Event-based 3d gaussian splatting for high-speed robot egomotion. In: ConferenceonRobotLearning,6-9November2024,Munich,Germany.Proceedings of Machine Learning Research, vol. 270, pp. 4100–4118. PMLR (2024),https: //proceedings.mlr.press/v270/xiong25b.html 18 F. A...
2024
-
[39]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Yura, T., Mirzaei, A., Gilitschenski, I.: Eventsplat: 3d gaussian splatting from moving event cameras for real-time rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 26876– 26886 (Jun 2025)
2025
-
[40]
In: International Conference on 3D Vision (3DV)
Zahid,S.,Rudnev,V.,Ilg,E.,Golyanik,V.:E-3dgs:Event-basednovelviewrender- ing of large-scale scenes using 3d gaussian splatting. In: International Conference on 3D Vision (3DV). pp. 926–934 (2025).https://doi.org/10.1109/3DV66043. 2025.00090
-
[41]
Zhang, Z., Cui, S., Chai, K., Yu, H., Dasgupta, S., Mahbub, U., Rahman, T.: V2CE: Video to continuous events simulator. In: IEEE International Conference on Robotics and Automation (ICRA 2024), Yokohama, Japan, May 13–17, 2024. pp. 12455–12461. IEEE (2024).https://doi.org/10.1109/ICRA57147.2024. 10609864,https://doi.org/10.1109/ICRA57147.2024.10609864
-
[42]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Zhu, J., Pan, T., Cao, Z., Liu, Y., Kwok, J.T., Xiong, H.: Depth any event stream: Enhancing event-based monocular depth estimation via dense-to-sparse distilla- tion. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 5146–5155 (October 2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.