Multimodal Action Diffusion for Robust End-to-End Autonomous Driving
Pith reviewed 2026-06-28 15:17 UTC · model grok-4.3
The pith
The Action Diffusion Transformer models multiple plausible driving actions to surpass prior end-to-end systems on closed-loop benchmarks at ten times lower latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Action Diffusion Transformer is an anchor-free diffusion transformer that natively models the multimodal distribution of driving actions by generating K candidates from a diffusion process trained with an MSE objective; at inference, Nearest Neighbour Matching selects the most suitable candidate, producing measurable gains in representational quality, behavioral consistency, closed-loop driving performance on Bench2Drive, and a tenfold latency reduction compared with deterministic architectures.
What carries the argument
Action Diffusion Transformer (ADT): an anchor-free diffusion transformer trained with MSE that generates multiple action candidates whose distribution is selected from by nearest-neighbor matching at inference.
If this is right
- Explicit multimodal action modeling improves the quality of learned representations beyond what deterministic models achieve.
- Behavioral consistency across driving scenarios increases when the model maintains multiple plausible actions rather than committing early.
- Direct prediction of throttle, steer, and brake becomes competitive with waypoint-based pipelines once multimodality is addressed.
- The same diffusion-plus-nearest-neighbor pipeline yields both higher benchmark scores and substantially lower inference latency.
Where Pith is reading between the lines
- Similar diffusion-based candidate generation could be tested in other continuous control domains such as robotic manipulation to check whether multimodality confers comparable robustness.
- If the approach generalizes, it would reduce dependence on separate hand-crafted controllers by making direct control-signal prediction more reliable.
- Measuring how often the generated candidate set contains the expert action on held-out data would provide a direct diagnostic of whether the multimodal distribution is being captured.
Load-bearing premise
The diffusion process trained with MSE on action data actually learns a useful multimodal distribution of plausible driving actions, and nearest-neighbor selection at inference consistently picks the appropriate candidate rather than the performance gains arising from other model choices.
What would settle it
A controlled ablation in which a deterministic counterpart of the same architecture and training regime reaches comparable Bench2Drive scores would indicate that multimodality is not required for the reported gains.
Figures

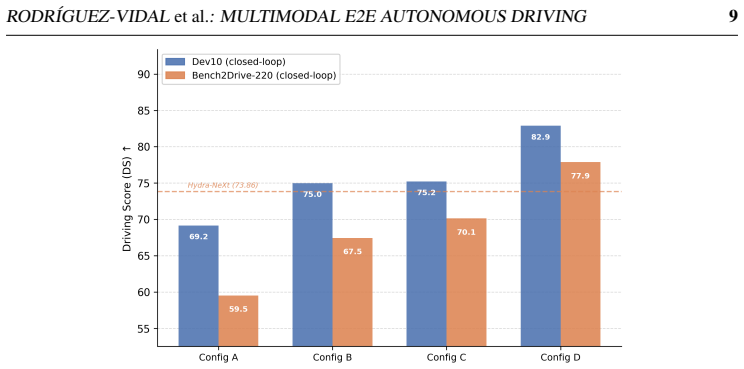

read the original abstract
End-to-End Autonomous Driving (E2E-AD) systems have largely converged on predicting intermediate trajectory waypoints, delegating final control to hand-crafted controllers with GPS access. Direct control-signal prediction (outputting throttle, steer and brake in an end-to-end fashion) remains underexplored, and critically, the role of action multimodality in such systems is not well understood. We argue that moving beyond deterministic, single-action outputs is not merely a modelling choice, but a key driver of driving performance, representational quality, and training stability. To validate this, we introduce the Action Diffusion Transformer (ADT), an anchor-free diffusion transformer trained with a MSE objective that natively models the multimodal distribution of plausible driving actions. Rather than committing to a single deterministic command, ADT generates K action candidates and selects the most suitable one at inference via Nearest Neighbour Matching (NNM). Beyond strong benchmark numbers, we show that action multimodality yields measurable benefits in learned representations and behavioral consistency, effects that deterministic architectures cannot replicate. ADT surpasses previous state-of-the-art on the challenging closed-loop Bench2Drive benchmark while achieving ten times lower latency, demonstrating that expressive, multimodal action modelling is both practically efficient and conceptually essential for robust end-to-end driving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Action Diffusion Transformer (ADT), an anchor-free diffusion transformer trained with an MSE objective to natively model the multimodal distribution of plausible driving actions (throttle, steer, brake). Rather than deterministic single-action outputs, ADT generates K action candidates and selects the most suitable one at inference via Nearest Neighbour Matching (NNM). The authors claim that this multimodal approach yields benefits in performance, learned representations, and behavioral consistency unattainable by deterministic models, with ADT surpassing prior SOTA on the closed-loop Bench2Drive benchmark at 10x lower latency.
Significance. If the results and attribution to multimodality hold after proper validation, the work would be significant for E2E-AD by demonstrating that direct control-signal prediction with expressive multimodal modeling can outperform trajectory-based methods while improving efficiency. The approach of applying diffusion to continuous control actions in this domain is a promising direction.
major comments (3)
- [Method] Method section: The diffusion process (forward and reverse steps) for continuous control signals is not formulated or specified, despite the central claim that an MSE-trained model 'natively models the multimodal distribution'; without this, it is impossible to verify how multimodality arises or differs from standard regression.
- [Experiments] Experiments section: No ablations isolate the diffusion/multimodality component from the transformer backbone, the generation of K candidates, or the NNM selection mechanism (e.g., no deterministic transformer baseline or random-selection control); this is load-bearing for the claim that 'action multimodality yields measurable benefits... that deterministic architectures cannot replicate.'
- [Abstract] Abstract and Experiments: The assertions of benchmark superiority on Bench2Drive, 10x lower latency, and unique representational/behavioral benefits from multimodality are presented without quantitative metrics, tables, error analysis, or ablation details, preventing verification of the central empirical claims.
minor comments (1)
- [Method] The description of NNM could benefit from an equation or pseudocode to clarify how candidates are matched to ground-truth actions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below and commit to revisions that clarify the method and strengthen the empirical support without misrepresenting the current manuscript.
read point-by-point responses
-
Referee: [Method] Method section: The diffusion process (forward and reverse steps) for continuous control signals is not formulated or specified, despite the central claim that an MSE-trained model 'natively models the multimodal distribution'; without this, it is impossible to verify how multimodality arises or differs from standard regression.
Authors: We agree that an explicit formulation of the diffusion process is required for verification. In the revised manuscript we will add the forward process q(a_t | a_{t-1}) = N(a_t; sqrt(1 - beta_t) a_{t-1}, beta_t I) and the learned reverse process p_theta(a_{t-1} | a_t) parameterized by the transformer, together with the MSE training objective on continuous actions. This will show how the generative denoising path produces a multimodal distribution over plausible controls, distinct from deterministic regression. revision: yes
-
Referee: [Experiments] Experiments section: No ablations isolate the diffusion/multimodality component from the transformer backbone, the generation of K candidates, or the NNM selection mechanism (e.g., no deterministic transformer baseline or random-selection control); this is load-bearing for the claim that 'action multimodality yields measurable benefits... that deterministic architectures cannot replicate.'
Authors: We recognize that isolating these components is essential to support the central claim. We will add the requested ablations in the revised Experiments section, including (i) a deterministic transformer baseline trained with the same backbone but without diffusion, (ii) a variant that generates K candidates but selects randomly instead of via NNM, and (iii) sweeps over K. These results will quantify the contribution of multimodality and the selection mechanism. revision: yes
-
Referee: [Abstract] Abstract and Experiments: The assertions of benchmark superiority on Bench2Drive, 10x lower latency, and unique representational/behavioral benefits from multimodality are presented without quantitative metrics, tables, error analysis, or ablation details, preventing verification of the central empirical claims.
Authors: The full manuscript contains tables and quantitative results for Bench2Drive closed-loop performance and latency; however, the abstract and certain experimental descriptions are indeed high-level. We will revise the abstract to report the concrete metrics (Bench2Drive score, latency reduction factor, and statistical significance) and expand the Experiments section with additional error bars, per-scenario breakdowns, and the new ablations noted above. revision: yes
Circularity Check
No circularity; empirical benchmark results are independent of model internals
full rationale
The paper is an empirical ML contribution whose central claims rest on closed-loop benchmark comparisons (Bench2Drive) and latency measurements rather than any mathematical derivation chain. No equations are presented that reduce a prediction to a fitted input by construction, no self-citations are invoked as uniqueness theorems, and the diffusion training (MSE objective, K-candidate generation, NNM selection) is described as a modeling choice whose value is tested externally rather than assumed. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A mul- timodal dataset for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[2]
End-to-end autonomous driving: Challenges and frontiers.IEEE Trans- actions on Pattern Analysis and Machine Intelligence, 2024
Li Chen, Penghao Wu, Kashyap Chitta, Bernhard Jaeger, Andreas Geiger, and Hongyang Li. End-to-end autonomous driving: Challenges and frontiers.IEEE Trans- actions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[3]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. InProceedings of the Robotics: Science and Systems (RSS) Conference, 2023
2023
-
[4]
Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022
Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022
2022
-
[5]
Lopez, Vladlen Koltun, and Alexey Dosovitskiy
Felipe Codevilla, Antonio M. Lopez, Vladlen Koltun, and Alexey Dosovitskiy. On offline evaluation of vision-based driving models. InProceedings of the European Conference on Computer Vision (ECCV), 2018
2018
-
[6]
End-to-end driving via conditional imitation learning
Felipe Codevilla, Matthias Müller, Antonio López, Vladlen Koltun, and Alexey Doso- vitskiy. End-to-end driving via conditional imitation learning. In2018 IEEE Interna- tional Conference on Robotics and Automation (ICRA), 2018
2018
-
[7]
López, and Adrien Gaidon
Felipe Codevilla, Eduardo Santana, Antonio M. López, and Adrien Gaidon. Exploring the limitations of behavior cloning for autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019
2019
-
[8]
Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking
Daniel Dauner, Marcel Hallgarten, Tianyu Li, Xinshuo Weng, Zhiyu Huang, Ze- tong Yang, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, Andreas Geiger, and Kashyap Chitta. Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 16RODRÍGUEZ-VIDALet a...
2024
-
[9]
Carla: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. InProceedings of the 1st Annual Conference on Robot Learning (CoRL), 2017
2017
-
[10]
Mapping like a skeptic: Prob- abilistic bev projection for online hd mapping
Fatih Erdo ˘gan, Merve Rabia Barın, and Fatma Güney. Mapping like a skeptic: Prob- abilistic bev projection for online hd mapping. InProceedings of the British Machine Vision Conference (BMVC), 2025
2025
-
[11]
PyTorch Lightning, March 2019
William Falcon and The PyTorch Lightning team. PyTorch Lightning, March 2019. URLhttps://github.com/Lightning-AI/lightning
2019
-
[12]
Muad: Multiple uncertainties for autonomous driving, a benchmark for multiple uncertainty types and tasks
Gianni Franchi, Xuanlong Yu, Andrei Bursuc, Ángel Tena, Rémi Kazmierczak, Séver- ine Dubuisson, Emanuel Aldea, and David Filliat. Muad: Multiple uncertainties for autonomous driving, a benchmark for multiple uncertainty types and tasks. InPro- ceedings of the British Machine Vision Conference (BMVC), 2022
2022
-
[13]
Dropout as a bayesian approximation: Repre- senting model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Repre- senting model uncertainty in deep learning. InProceedings of the 33rd International Conference on Machine Learning (ICML), 2016
2016
-
[14]
D 3nav: Data-driven driving agents for autonomous vehicles in unstructured traffic
Aditya Nalgunda Ganesh and Gowri Srinivasa. D 3nav: Data-driven driving agents for autonomous vehicles in unstructured traffic. InProceedings of the British Machine Vision Conference (BMVC), 2024
2024
-
[15]
Eta: Efficiency through thinking ahead, a dual approach to self-driving with large models
Shadi Hamdan, Chonghao Sima, Zetong Yang, Hongyang Li, and Fatma Güney. Eta: Efficiency through thinking ahead, a dual approach to self-driving with large models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[16]
Urban driving with conditional imitation learning
Jeffrey Hawke, Richard Shen, Corina Gurau, Siddharth Sharma, Daniele Reda, Nikolay Nikolov, Przemyslaw Mazur, Sean Micklethwaite, Nicholas Griffiths, Amar Shah, and Alex Kendall. Urban driving with conditional imitation learning. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2020
2020
-
[17]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016. doi: 10.1109/CVPR.2016.90
-
[18]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[19]
Model-based imitation learning for urban driving
Anthony Hu, Gianluca Corrado, Nicolas Griffiths, Zak Murez, Corina Gurau, Hud- son Yeo, Alex Kendall, Roberto Cipolla, and Jamie Shotton. Model-based imitation learning for urban driving. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[20]
Tracking meets large multimodal models for driving scenario understanding
Ayesha Ishaq, Jean Lahoud, Fahad Shahbaz Khan, Salman Khan, Hisham Cholakkal, and Rao Muhammad Anwer. Tracking meets large multimodal models for driving scenario understanding. InProceedings of the British Machine Vision Conference (BMVC), 2025. RODRÍGUEZ-VIDALet al.: MULTIMODAL E2E AUTONOMOUS DRIVING17
2025
-
[21]
Driveadapter: Breaking the coupling barrier of perception and planning in end-to- end autonomous driving
Xiaosong Jia, Yulu Gao, Li Chen, Junchi Yan, Patrick Langechuan Liu, and Hongyang Li. Driveadapter: Breaking the coupling barrier of perception and planning in end-to- end autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[22]
Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving
Xiaosong Jia, Zhenjie Yang, Qifeng Li, Zhiyuan Zhang, and Junchi Yan. Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[23]
Drivetransformer: Unified transformer for scalable end-to-end autonomous driving
Xiaosong Jia, Junqi You, Zhiyuan Zhang, and Junchi Yan. Drivetransformer: Unified transformer for scalable end-to-end autonomous driving. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[24]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[25]
Dualdistill: A unified cross- modal knowledge distillation framework for camera-based bev representation
Gaeun Kim, Daeil Han, Yeong Jun Koh, and Hanul Kim. Dualdistill: A unified cross- modal knowledge distillation framework for camera-based bev representation. InPro- ceedings of the British Machine Vision Conference (BMVC), 2025
2025
-
[26]
Logen: Toward lidar object generation by point diffusion
Ellington Kirby, Mickael Chen, Renaud Marlet, and Nermin Samet. Logen: Toward lidar object generation by point diffusion. InProceedings of the British Machine Vision Conference (BMVC), 2025
2025
-
[27]
Think2drive: Efficient rein- forcement learning by thinking in latent world model for quasi-realistic autonomous driving (in carla-v2)
Qifeng Li, Xiaosong Jia, Shaobo Wang, and Junchi Yan. Think2drive: Efficient rein- forcement learning by thinking in latent world model for quasi-realistic autonomous driving (in carla-v2). InProceedings of the European Conference on Computer Vision (ECCV), 2024
2024
-
[28]
Zhenxin Li, Kailin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Yishen Ji, Zhiqi Li, Ziyue Zhu, Jan Kautz, Zuxuan Wu, Yu-Gang Jiang, and Jose M. Alvarez. Hydra-mdp: End-to-end multimodal planning with multi-target hydra-distillation.arXiv preprint arXiv:2406.06978, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Zhenxin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Zuxuan Wu, and Jose M. Alvarez. Hydra-next: Robust closed-loop driving with open-loop training. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[30]
Zhiqi Li, Zhiding Yu, Shiyi Lan, Jiahan Li, Jan Kautz, Tong Lu, and José M. Álvarez. Is ego status all you need for open-loop end-to-end autonomous driving?2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14864–14873, 2023
2024
-
[31]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving
Bencheng Liao, Shaoyu Chen, Haoran Yin, Bo Jiang, Cheng Wang, Sixu Yan, Xinbang Zhang, Xiangyu Li, Ying Zhang, Qian Zhang, and Xinggang Wang. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[32]
Bridgedrive: Diffusion bridge policy for closed-loop trajectory planning in autonomous driving
Shu Liu, Wenlin Chen, Weihao Li, Zheng Wang, Lijin Yang, Jianing Huang, Yipin Zhang, Zhongzhan Huang, Ze Cheng, and Hao Yang. Bridgedrive: Diffusion bridge policy for closed-loop trajectory planning in autonomous driving. InProceedings of the International Conference on Learning Representations (ICLR), 2026. 18RODRÍGUEZ-VIDALet al.: MULTIMODAL E2E AUTONOM...
2026
-
[33]
Curran Associates Inc., Red Hook, NY , USA, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Des- maison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala.Py- Torch: an imperative style, high-perfo...
2019
-
[34]
Fast: Efficient action tokenization for vision-language-action models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models. InProceedings of Robotics: Science and Systems (RSS), 2025
2025
-
[35]
Safety-enhanced autonomous driving using interpretable sensor fusion transformer
Hao Shao, Letian Wang, RuoBing Chen, Hongsheng Li, and Yu Liu. Safety-enhanced autonomous driving using interpretable sensor fusion transformer. InProceedings of the Conference on Robot Learning (CoRL), 2022
2022
-
[36]
Denoising diffusion implicit mod- els
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit mod- els. InProceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[37]
Dropout: A simple way to prevent neural networks from overfitting
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 2014
2014
-
[38]
Lid-lab-nerf: Generating temporally consis- tent, labelled lidar point clouds using neural radiance fields
Shrestha Srivastava and Vaibhav Kumar. Lid-lab-nerf: Generating temporally consis- tent, labelled lidar point clouds using neural radiance fields. InProceedings of the British Machine Vision Conference (BMVC), 2025
2025
-
[39]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[40]
Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline
Penghao Wu, Xiaosong Jia, Li Chen, Junchi Yan, Hongyang Li, and Yu Qiao. Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[41]
Yi Xiao, Felipe Codevilla, Diego Porres, and Antonio M. López. Scaling vision-based end-to-end autonomous driving with multi-view attention learning. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023
2023
-
[42]
Diffrefiner: Coarse to fine trajectory planning via diffusion refinement with semantic interaction for end to end autonomous driving
Liuhan Yin, Runkun Ju, Guodong Guo, and Erkang Cheng. Diffrefiner: Coarse to fine trajectory planning via diffusion refinement with semantic interaction for end to end autonomous driving. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2026
2026
-
[43]
Rethinking the Open-Loop Evaluation of End-to-End Autonomous Driving in nuScenes
Jiang-Tian Zhai, Ze Feng, Jihao Du, Yongqiang Mao, Jiang-Jiang Liu, Zichang Tan, Yifu Zhang, Xiaoqing Ye, and Jingdong Wang. Rethinking the open-loop evaluation of end-to-end autonomous driving in nuscenes.arXiv preprint arXiv:2305.10430, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
End-to- end urban driving by imitating a reinforcement learning coach
Zhejun Zhang, Alexander Liniger, Dengxin Dai, Fisher Yu, and Luc Van Gool. End-to- end urban driving by imitating a reinforcement learning coach. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.