Geometric Latent Reasoning Induces Shorter Generations in LLMs
Pith reviewed 2026-06-28 15:03 UTC · model grok-4.3
The pith
Replacing early explicit reasoning with continuous updates in embedding space lets models reach answers in fewer total generation steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
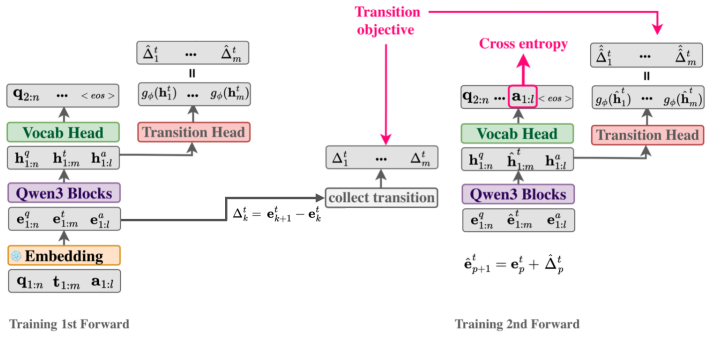
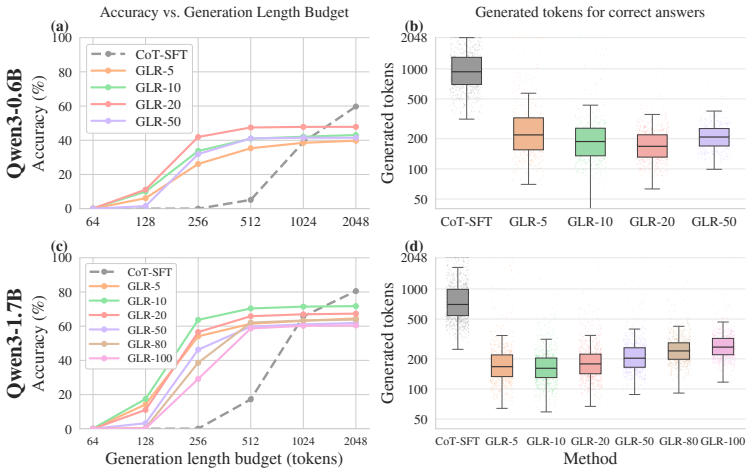
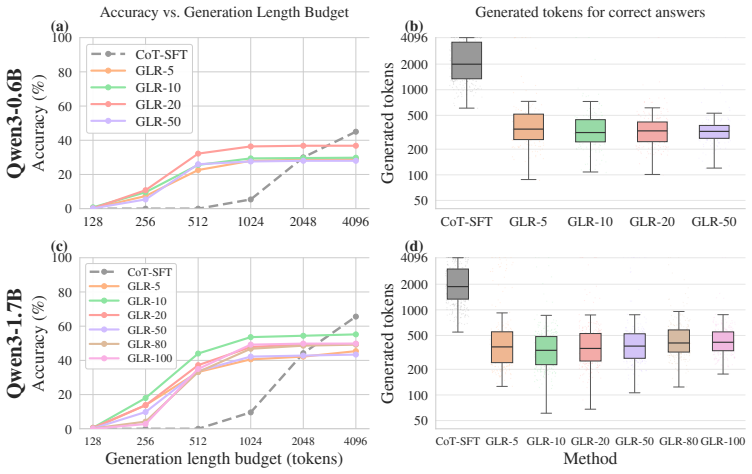
By treating latent reasoning as a geometric path-approximation task inside pretrained embedding space, a lightweight transition head is trained to predict iterative direction updates anchored to textual chain-of-thought traces. The head permits continuous deviations from exact token embeddings, so early reasoning steps can be executed latently; the model then completes the task with substantially shorter total generations on mathematical benchmarks.
What carries the argument
The lightweight transition head that predicts iterative direction updates inside the model's token-embedding space, trained on textual chain-of-thought traces as anchors.
If this is right
- Early explicit reasoning tokens can be replaced by continuous latent steps without any separate length objective.
- Models reach correct answers after substantially fewer total generation steps.
- Continuous trajectories function as compact intermediate reasoning states.
- A tradeoff appears between the number of latent steps, final output length, and answer accuracy.
Where Pith is reading between the lines
- The method could be tested on non-mathematical tasks that normally produce long explicit chains to see whether length reduction generalizes.
- Varying the number of latent steps before switching to explicit generation might reveal an optimal budget that balances accuracy against total tokens.
- Combining the geometric updates with existing inference-time efficiency methods could produce further reductions in compute per solved problem.
Load-bearing premise
The direction updates produced by the transition head, trained only on textual chain-of-thought examples, preserve enough semantic information to substitute for explicit token generation without degrading final answer correctness.
What would settle it
An experiment that disables the trained transition head or replaces its direction updates with random vectors in embedding space and checks whether generation lengths stay short and answers remain correct on the same mathematical benchmarks.
Figures
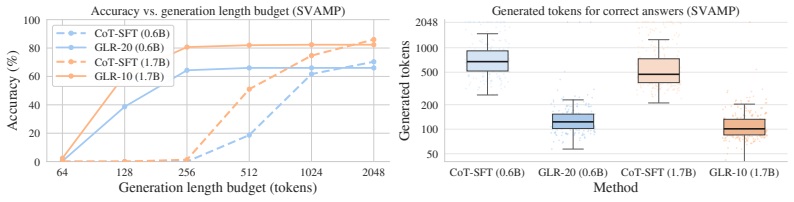

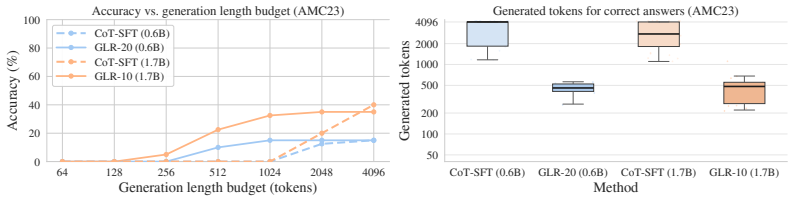
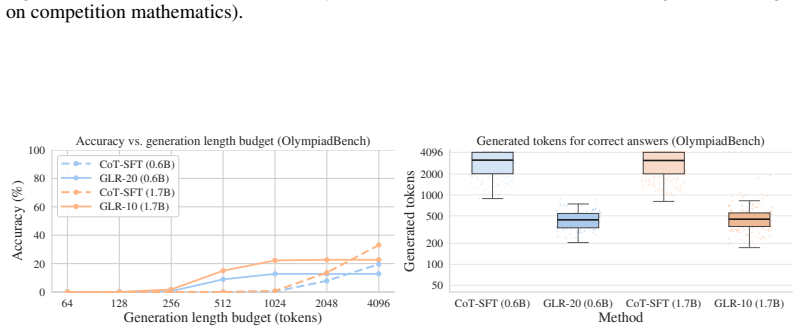
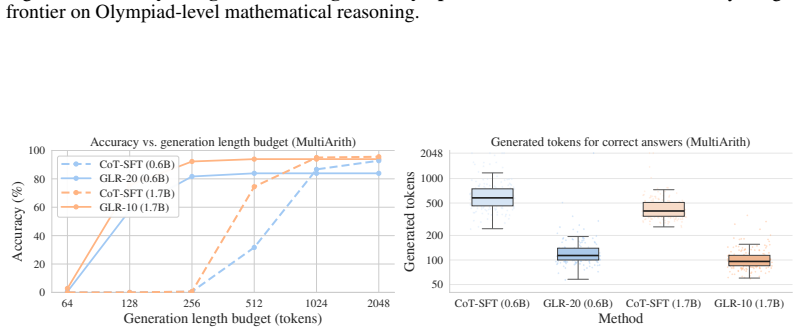








read the original abstract
Large language models solve complex problems by generating lengthy chains of explicit reasoning tokens. While effective, this makes reasoning expensive, length-sensitive, and constrained to (discrete) natural language. While latent reasoning offers a continuous alternative, determining useful structures for intermediate latent states is an open challenge. In this paper, we formulate latent reasoning as a geometric path-approximation problem within the model's pretrained token-embedding space. We introduce Geometric Latent Reasoning (GLR), which uses a lightweight transition head to predict iterative direction updates in embedding space. Using textual chain-of-thought traces as anchors, GLR learns to approximate discrete reasoning trajectories while permitting continuous deviations from exact token embeddings. Evaluations on mathematical reasoning benchmarks using Qwen3 models reveal an emergent phenomenon: geometric latent reasoning induces substantially shorter generations without an explicit length objective. By replacing early explicit reasoning with continuous latent steps, models often reach correct answers using substantially fewer total generation steps. These findings suggest that continuous trajectories act as compact intermediate reasoning states, exposing a new tradeoff between latent computation budget, output length, and accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Geometric Latent Reasoning (GLR) as a formulation of latent reasoning as a geometric path-approximation problem in the pretrained token-embedding space of LLMs. A lightweight transition head predicts iterative direction updates, trained on textual chain-of-thought traces as anchors to allow continuous deviations from exact token embeddings. The central claim is that this induces substantially shorter generations on mathematical reasoning benchmarks with Qwen3 models as an emergent phenomenon, without an explicit length objective, by replacing early explicit reasoning steps with continuous latent steps while still reaching correct answers.
Significance. If the central claim holds under rigorous evaluation, the work would be significant for identifying an emergent tradeoff between latent computation budget, output length, and accuracy. The geometric framing and use of continuous trajectories as compact intermediate states could provide a new mechanism for efficient reasoning beyond discrete token generation.
major comments (3)
- [Abstract] Abstract and method description: no equations, training procedure, or loss function are provided for the transition head, nor any description of how it is trained or evaluated on CoT anchors. This prevents checking whether continuous deviations preserve semantic content or simply allow early termination before the answer head.
- [Abstract] Abstract: the claim that models 'often reach correct answers using substantially fewer total generation steps' is unsupported by any quantitative results, accuracy metrics, error bars, or comparison to baselines. Without these, it is impossible to determine whether length reduction preserves correctness or arises from non-semantic shortcuts.
- [Method] The setup trains the transition head only to predict next-token direction vectors from textual CoT traces, yet allows free continuous deviation at inference. No mechanism (regularization, manifold constraint, or consistency loss) is described to ensure deviations remain on a semantically valid reasoning path, so shorter generations may reflect reduced token emission rather than genuine latent computation.
minor comments (1)
- [Abstract] The abstract would be clearer with a brief statement of the model sizes, benchmark names, and observed length reduction factors.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, providing clarifications from the full manuscript and indicating where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: no equations, training procedure, or loss function are provided for the transition head, nor any description of how it is trained or evaluated on CoT anchors. This prevents checking whether continuous deviations preserve semantic content or simply allow early termination before the answer head.
Authors: The abstract is intentionally concise. The full Method section (Section 3) defines the transition head as a lightweight network predicting direction vectors d_t = W * h_t + b, with the training objective being the squared L2 loss between predicted directions and the embedding differences extracted from CoT token sequences. The head is trained by supervising on these anchor trajectories to approximate discrete steps while permitting continuous interpolation at inference. We will revise the abstract to include a one-sentence description of the loss and CoT supervision. revision: partial
-
Referee: [Abstract] Abstract: the claim that models 'often reach correct answers using substantially fewer total generation steps' is unsupported by any quantitative results, accuracy metrics, error bars, or comparison to baselines. Without these, it is impossible to determine whether length reduction preserves correctness or arises from non-semantic shortcuts.
Authors: The abstract summarizes the central empirical finding. Section 4 reports the full quantitative results on mathematical reasoning benchmarks with Qwen3 models, including per-task accuracy, mean generation lengths with standard deviations across multiple runs, and direct comparisons against standard CoT prompting and other baselines. These experiments show accuracy is maintained while total steps decrease. We will incorporate a brief summary of the key metrics into the abstract. revision: partial
-
Referee: [Method] The setup trains the transition head only to predict next-token direction vectors from textual CoT traces, yet allows free continuous deviation at inference. No mechanism (regularization, manifold constraint, or consistency loss) is described to ensure deviations remain on a semantically valid reasoning path, so shorter generations may reflect reduced token emission rather than genuine latent computation.
Authors: The CoT anchor supervision directly grounds the learned directions in the semantic structure of the pretrained embedding space, so that iterative updates follow trajectories that were originally derived from valid reasoning sequences. At inference the model applies the same direction predictions without token emission until the answer head is triggered. While no additional explicit regularization term is introduced, the emergent preservation of accuracy alongside reduced length provides evidence that the latent steps perform useful computation rather than mere early stopping. We will expand the Method section with a dedicated paragraph clarifying this inference procedure and the role of anchor-based training. revision: yes
Circularity Check
No significant circularity detected; derivation is self-contained.
full rationale
The paper formulates GLR as a geometric path-approximation problem and trains a transition head on textual CoT traces to learn direction updates, with shorter generations reported as an emergent observation rather than a fitted or self-defined quantity. No equations, self-citations, or ansatzes are quoted that reduce the central claims (latent steps substituting for explicit tokens, length reduction without explicit objective) to inputs by construction. The method's training anchors and evaluation on benchmarks remain independent of the reported length effect, satisfying the criteria for a non-circular finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[2]
MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning
Xiang Yue, Xingwei Qu, Ge Zhang, Yao Fu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mammoth: Building math generalist models through hybrid instruction tuning.arXiv preprint arXiv:2309.05653, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Yige Xu, Xu Guo, Zhiwei Zeng, and Chunyan Miao. Softcot: Soft chain-of-thought for efficient reasoning with llms.arXiv preprint arXiv:2502.12134, 2025
-
[6]
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. Codi: Compressing chain-of-thought into continuous space via self-distillation.arXiv preprint arXiv:2502.21074, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
arXiv preprint arXiv:2502.03275 , year=
DiJia Su, Hanlin Zhu, Yingchen Xu, Jiantao Jiao, Yuandong Tian, and Qinqing Zheng. Token assorted: Mixing latent and text tokens for improved language model reasoning.arXiv preprint arXiv:2502.03275, 2025
-
[8]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling.arXiv preprint arXiv:2501.19393, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute opti- mally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023. 10
2023
-
[14]
Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems, 36:74952–74965, 2023
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems, 36:74952–74965, 2023
2023
-
[15]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Implicit chain of thought reasoning via knowledge distillation.arXiv preprint arXiv:2311.01460, 2023
Yuntian Deng, Kiran Prasad, Roland Fernandez, Paul Smolensky, Vishrav Chaudhary, and Stuart Shieber. Implicit chain of thought reasoning via knowledge distillation.arXiv preprint arXiv:2311.01460, 2023
-
[17]
Yige Xu, Xu Guo, Zhiwei Zeng, and Chunyan Miao. Softcot++: Test-time scaling with soft chain-of-thought reasoning.arXiv preprint arXiv:2505.11484, 2025
-
[18]
Zhen Zhang, Xuehai He, Weixiang Yan, Ao Shen, Chenyang Zhao, Shuohang Wang, Yelong Shen, and Xin Eric Wang. Soft thinking: Unlocking the reasoning potential of llms in continuous concept space.arXiv preprint arXiv:2505.15778, 2025
-
[19]
Hybrid latent reasoning via reinforcement learning.arXiv preprint arXiv:2505.18454, 2025
Zhenrui Yue, Bowen Jin, Huimin Zeng, Honglei Zhuang, Zhen Qin, Jinsung Yoon, Lanyu Shang, Jiawei Han, and Dong Wang. Hybrid latent reasoning via reinforcement learning.arXiv preprint arXiv:2505.18454, 2025
-
[20]
Open r1: A fully open reproduction of deepseek-r1, January 2025
Hugging Face. Open r1: A fully open reproduction of deepseek-r1, January 2025
2025
-
[21]
Openr1-math-220k
Anton Lozhkov, Hynek Kydlíˇcek, Loubna Ben Allal, Guilherme Penedo, Edward Beeching, Quentin Gallouédec, Nathan Habib, Lewis Tunstall, and Leandro von Werra. Openr1-math-220k. https://huggingface.co/datasets/open-r1/OpenR1-Math-220k, 2025
2025
-
[22]
Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
2015
-
[23]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020
2020
-
[24]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[25]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[26]
Solving general arithmetic word problems
Subhro Roy and Dan Roth. Solving general arithmetic word problems. InProceedings of the 2015 conference on empirical methods in natural language processing, pages 1743–1752, 2015
2015
-
[27]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Pape...
2024
-
[29]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are nlp models really able to solve simple math word problems? InProceedings of the 2021 conference of the North American chapter of the association for computational linguistics: human language technologies, pages 2080–2094, 2021. 11
2021
-
[30]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
2024
-
[31]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. Huggingface’s transform- ers: State-of-the-art natural language processing.arXiv preprint arXiv:1910.03771, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[32]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. 12 A Hyperparameters Both the COT-SFT baseline and our propo...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.