Who Annotates in NLP? A Large-scale Assessment of Human Annotation Reporting between 2018 and 2025
Pith reviewed 2026-06-28 14:58 UTC · model grok-4.3
The pith
NLP papers often report how annotations were collected but omit details needed to judge their quality and validity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
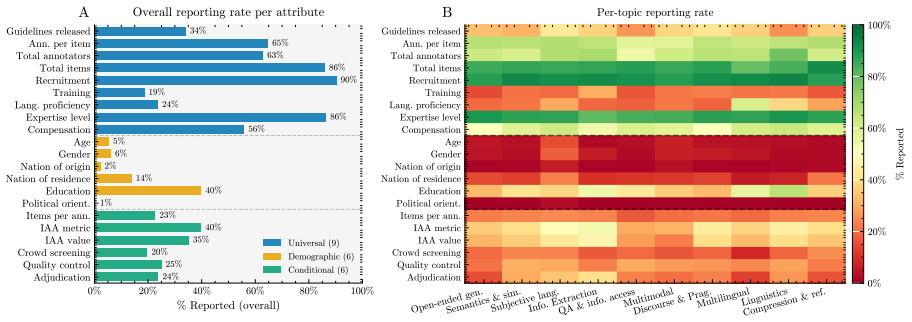
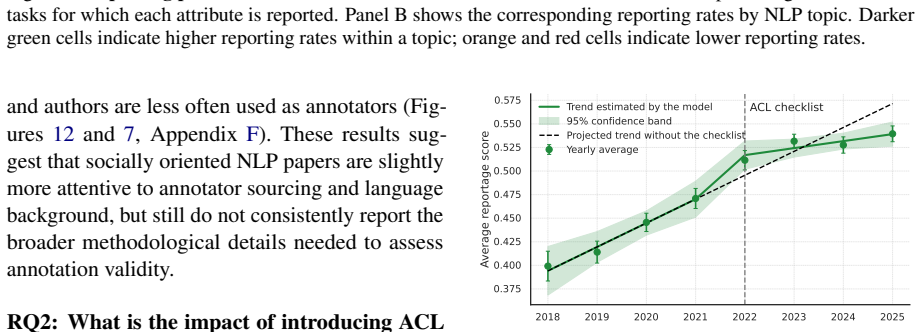
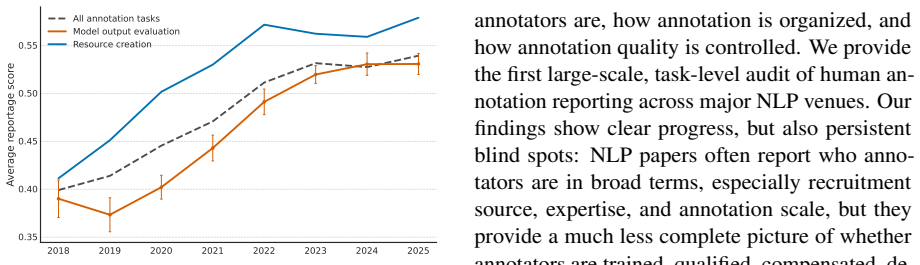
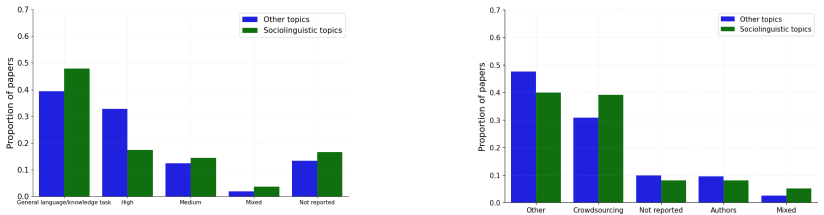
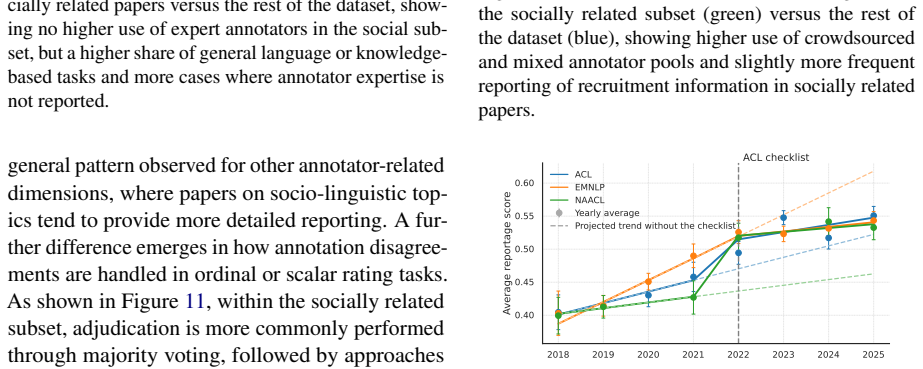
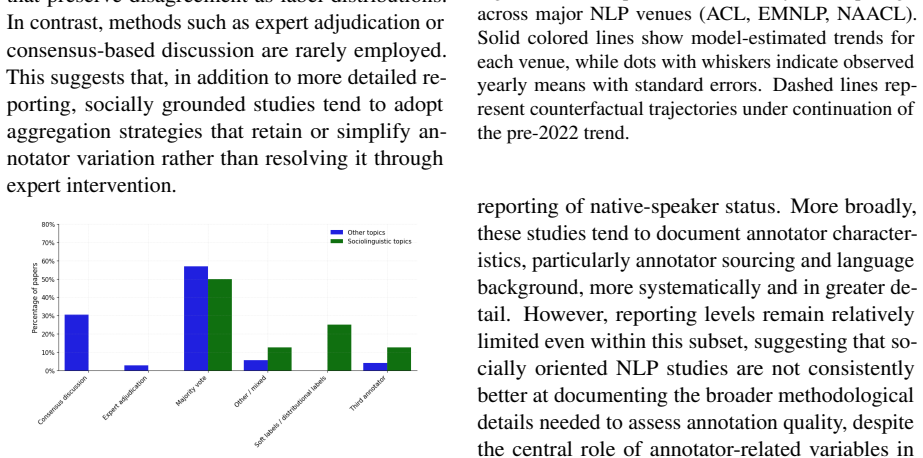
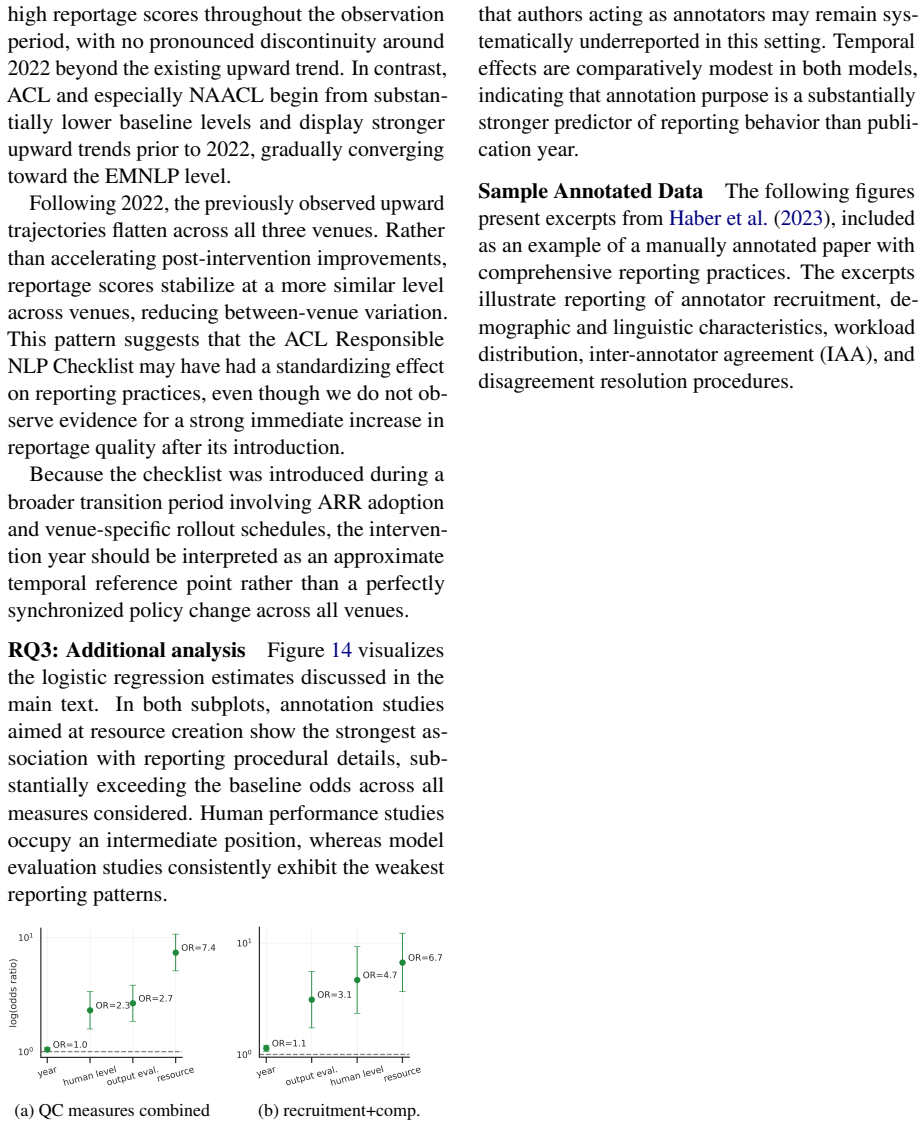
Across 1,603 papers containing 2,667 annotation tasks, papers frequently report operational details such as recruitment strategies, annotator expertise, and annotation volume, but often omit details needed to assess annotation validity, including training, language proficiency, compensation, socio-demographics, adjudication, and agreement values, especially in model-evaluation studies; reporting has improved over time but remains uneven.
What carries the argument
A unified taxonomy of annotation-reporting practices together with an LLM-assisted extraction pipeline that reaches Krippendorff's alpha of 0.606 on a human-adjudicated gold standard of 41 papers.
If this is right
- Model-evaluation studies require extra scrutiny on agreement and adjudication reporting.
- The taxonomy can serve as a checklist for authors and reviewers.
- The Annotated-llm dataset enables tracking of reporting changes over time.
- Bare-minimum reporting standards derived from the taxonomy would improve reproducibility of annotation-based results.
Where Pith is reading between the lines
- Widespread adoption of the taxonomy could reduce hidden variability in benchmark quality.
- The same extraction approach could be applied to non-NLP fields that rely on human labels.
- Journals could require the taxonomy items as a submission checklist to close the observed gaps.
- Continued monitoring with the pipeline would show whether community guidelines are actually changing practice.
Load-bearing premise
The LLM pipeline extracts and classifies reporting practices accurately enough across the full collection of papers to support the reported patterns of presence and absence.
What would settle it
A fresh manual review of several hundred randomly sampled papers that shows the pipeline systematically misclassifies the presence or absence of validity-related items such as training or agreement scores.
Figures








read the original abstract
Human annotation is the empirical foundation of much NLP research, from dataset construction to model evaluation, but papers often leave unclear who produced the annotations and how the annotation process was controlled. We provide the first large-scale, task-level audit of human annotation reporting across major NLP venues, asking which annotation details are documented, which are missing, and how reporting varies across time, topic, venue, and intended use of human judgment. We introduce a unified taxonomy of annotation-reporting practices and validate an LLM-assisted extraction pipeline against Annotated-gold, a human-adjudicated gold standard of 41 papers and 72 annotation tasks, where the best model reaches human-comparable agreement with adjudicated labels, with Krippendorff's alpha of 0.606 versus 0.585 for human-human agreement. Using this pipeline, we construct Annotated-llm, a dataset covering ACL-venue papers from 2018-2025, with 2,667 extracted annotation tasks from 1,603 papers, and find that papers frequently report operational details such as recruitment strategies, annotator expertise, and annotation volume, but often omit details needed to assess annotation validity, including training, language proficiency, compensation, socio-demographics, adjudication, and agreement values, especially in model-evaluation studies. Our results show that annotation reporting in NLP has improved over time but remains uneven, and they establish a scalable framework and bare-minimum reporting recommendations for making human annotation more reliable, reproducible, and interpretable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a unified taxonomy of annotation-reporting practices and uses an LLM-assisted extraction pipeline (validated on a 41-paper/72-task human-adjudicated gold standard reaching Krippendorff's α=0.606, comparable to human-human α=0.585) to audit reporting across 1,603 ACL-venue papers (2,667 tasks) from 2018–2025. It claims that operational details (recruitment, expertise, volume) are frequently reported while validity-related details (training, language proficiency, compensation, socio-demographics, adjudication, agreement) are often omitted—especially in model-evaluation studies—and that reporting has improved over time but remains uneven, offering a scalable framework and minimum reporting recommendations.
Significance. If the extraction pipeline proves reliable, the work supplies the first large-scale empirical map of annotation-reporting gaps in NLP, reusable datasets (Annotated-gold, Annotated-llm), and a taxonomy that could support reproducibility standards. The explicit comparison to human agreement and the task-level granularity are strengths.
major comments (2)
- [validation results on Annotated-gold] Validation experiment (41-paper gold standard): Krippendorff's α=0.606 is reported as human-comparable, yet no per-category agreement scores, confusion matrices, or error rates are provided for individual reporting dimensions (e.g., compensation, socio-demographics, adjudication). Systematic LLM bias on any single dimension would directly distort the headline omission frequencies and the “improved over time” trend across the 2,667 tasks.
- [methods and results on full corpus extraction] Pipeline application to full corpus (§ on Annotated-llm construction): The central observational claims rest on automated classification of 1,603 papers without reported held-out validation, inter-annotator agreement on a larger sample, or sensitivity analysis for extraction errors; the moderate α on the small gold set therefore leaves the quantitative results (e.g., differential omission in model-evaluation vs. dataset-construction tasks) on uncertain footing.
minor comments (2)
- [task extraction definition] Clarify how “annotation task” boundaries are defined when a single paper contains multiple distinct annotation efforts; this affects the 2,667-task count and cross-task comparisons.
- [taxonomy section] The taxonomy could be presented with an explicit mapping table to the extracted fields to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their careful review and constructive comments on our validation approach and the reliability of the extraction pipeline. We provide point-by-point responses below.
read point-by-point responses
-
Referee: [validation results on Annotated-gold] Validation experiment (41-paper gold standard): Krippendorff's α=0.606 is reported as human-comparable, yet no per-category agreement scores, confusion matrices, or error rates are provided for individual reporting dimensions (e.g., compensation, socio-demographics, adjudication). Systematic LLM bias on any single dimension would directly distort the headline omission frequencies and the “improved over time” trend across the 2,667 tasks.
Authors: We agree that aggregate agreement alone does not fully address potential dimension-specific biases. In the revised manuscript, we will add per-category Krippendorff's α scores for each of the reporting dimensions in the taxonomy, as well as selected confusion matrices and error analysis for key categories such as compensation and socio-demographics. This will allow better assessment of the pipeline's reliability on individual dimensions. revision: yes
-
Referee: [methods and results on full corpus extraction] Pipeline application to full corpus (§ on Annotated-llm construction): The central observational claims rest on automated classification of 1,603 papers without reported held-out validation, inter-annotator agreement on a larger sample, or sensitivity analysis for extraction errors; the moderate α on the small gold set therefore leaves the quantitative results (e.g., differential omission in model-evaluation vs. dataset-construction tasks) on uncertain footing.
Authors: The gold standard of 41 papers was constructed as a held-out validation set for the pipeline, and we selected it to be representative across venues, years, and task types. We acknowledge that the sample size is modest and that additional human validation on a larger subset of the corpus would be ideal. Due to the high cost of human annotation, we did not perform this. However, we will include a sensitivity analysis in the revision by simulating extraction errors and assessing the robustness of the reported trends, such as the improvement over time and differences by task type. We believe this, combined with the human-comparable aggregate agreement, provides reasonable support for the claims. revision: partial
Circularity Check
No circularity: empirical extraction from external papers with external human validation
full rationale
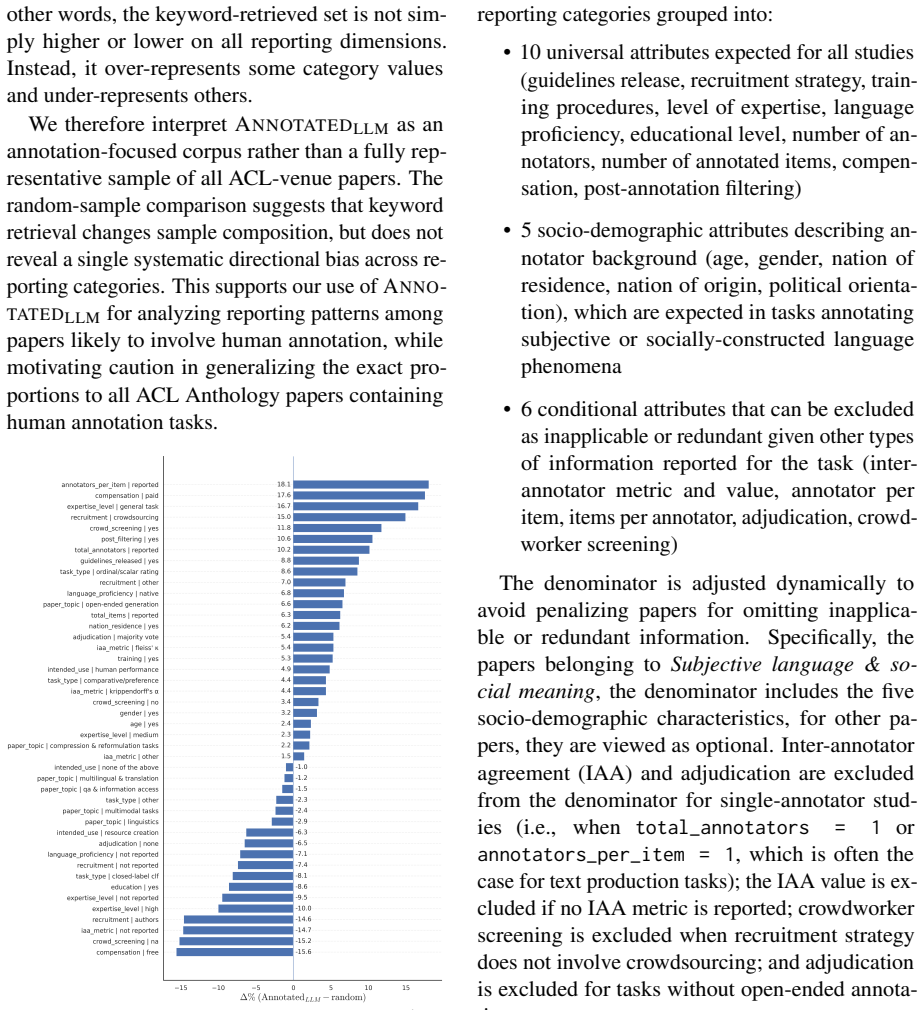
This is a descriptive content-analysis study that applies an LLM pipeline to extract reporting details from 1,603 external ACL papers (2018-2025) and validates the pipeline against a separately human-adjudicated gold standard of 41 papers. No mathematical derivations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the chain from data extraction to reported frequencies and trends. The central results are direct tallies of omitted vs. reported fields across the extracted tasks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The unified taxonomy of annotation-reporting practices is comprehensive and appropriate for auditing NLP papers.
invented entities (2)
-
unified taxonomy of annotation-reporting practices
no independent evidence
-
Annotated-llm dataset
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Language Models are Few-Shot Learners
WiC-TSV: An evaluation benchmark for target sense verification of words in context. InProceed- ings of the 16th Conference of the European Chap- ter of the Association for Computational Linguistics: Main V olume, pages 1635–1645, Online. Association for Computational Linguistics. Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Praf...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[2]
NeuroTrialNER: An annotated corpus for neu- rological diseases and therapies in clinical trial reg- istries. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 18868–18890, Miami, Florida, USA. Associa- tion for Computational Linguistics. 10 Steffen Eger, Yong Cao, Jennifer D’Souza, Andreas Geiger, Christian Gr...
-
[3]
Heseia: A community-based dataset for eval- uating social biases in large language models, co- designed in real school settings in latin america. Preprint, arXiv:2505.24712. Aiqi Jiang, Nikolas Vitsakis, Tanvi Dinkar, Gavin Aber- crombie, and Ioannis Konstas. 2024. Re-examining sexism and misogyny classification with annotator attitudes. InFindings of the...
-
[4]
Human-in-the-loop synthetic text data in- spection with provenance tracking.Preprint, arXiv:2404.18881. 11 Antonia Karamolegkou, Sandrine Schiller Hansen, Ariadni Christopoulou, Filippos Stamatiou, Anne Lauscher, and Anders Søgaard. 2025. Ethical con- cern identification in NLP: A corpus of ACL Anthol- ogy ethics statements. InProceedings of the 2025 Conf...
-
[5]
Visbias: Measuring explicit and implicit so- cial biases in vision language models.Preprint, arXiv:2503.07575. Keith Tyser, Ben Segev, Gaston Longhitano, Xin-Yu Zhang, Zachary Meeks, Jason Lee, Uday Garg, Nicholas Belsten, Avi Shporer, Madeleine Udell, Dov Te’eni, and Iddo Drori. 2024. Ai-driven review sys- tems: Evaluating llms in scalable and bias-aware...
-
[6]
Bridging ai and science: Implications from a large-scale literature analysis of ai4science.Preprint, arXiv:2412.09628. Limao Xiong, Jie Zhou, Qunxi Zhu, Xiao Wang, Yuan- bin Wu, Qi Zhang, Tao Gui, Xuanjing Huang, Jin Ma, and Ying Shan. 2023. A confidence-based partial la- bel learning model for crowd-annotated named entity recognition. InFindings of the A...
-
[7]
hate speech detection vs
**Different annotation objective** -- distinct label spaces or annotation goals (e.g. hate speech detection vs. stance detection)
-
[8]
experts for one subtask, crowd for another)
**Different annotator pools** -- different groups used for different tasks (e.g. experts for one subtask, crowd for another)
-
[9]
**Different recruitment / compensation** -- one task paid, another unpaid; or recruited via different channels
-
[10]
**Different annotation units** -- sentence-level vs document-level; word-level vs sentence-level
-
[11]
A paper that runs hate speech labeling and then target-type labeling on the same dataset has TWO experiments, not one
**Separate dedicated annotation rounds** -- the paper describes multiple distinct rounds, each with its own guidelines, annotators, or IAA Real-paper SPLIT examples: * binary attack classification / language classification / attack target classification -> 3 experiments (different label spaces) * summarization generation / summarization rating -> 2 experi...
-
[12]
Does the paper describe any OTHER annotation task (different labels, different annotators, different purpose in a different paper section)?
-
[13]
Experiment 2
Are there separate sections titled "Experiment 2", "Human Evaluation", "Quality Annotation", "Pilot Study"?
-
[14]
Did any OTHER group of humans label, rate, or judge data in this paper?
-
[15]
### CRITICAL: Avoid These Common Mistakes
Is there a text production task AND a separate evaluation/rating task performed by humans? If the answer to ANY of these is yes -> add another experiment. ### CRITICAL: Avoid These Common Mistakes
-
[16]
Not reported
**Do NOT use "Not reported" for demographic fields** -- use "No". These fields ONLY accept "Yes" or "No"
-
[17]
Majority vote
**disagreement_resolution_adjudication must be one of the specific methods** -- "Majority vote", "Expert adjudication", "Third annotator", "Consensus discussion", "Soft labels / Distributional labels", "Weighted voting", "Other / mixed", or "None"
-
[18]
**Do NOT infer language proficiency** from the dataset language or annotator country alone (exception: ethnicity matching task language -> "Native")
-
[19]
**Do NOT infer compensation amounts** -- but DO infer "Free" when authors annotate their own data, or mention voluntary effort
-
[20]
**Do NOT assume guidelines are released** just because the paper describes the task in prose -- there must be a dedicated document, appendix, URL, or cited source
-
[21]
**Do NOT calculate workload fields** from other numbers -- only extract explicitly stated values
-
[22]
Crowdsourcing
**For recruitment**, use the broad categories: "Crowdsourcing", "Authors", "Other", "Mixed", "Not reported" -- do NOT use platform-specific names
-
[23]
NA"** -- use
**For compensation, do NOT use "NA"** -- use "Not reported" if compensation is unmentioned
-
[24]
General Language/Knowledge task
**Do NOT confuse expertise_level "General Language/Knowledge task" and "Not reported"**: "General 26 Language/Knowledge task" = task needs no specialization at all; "Not reported" = task could need specialization but paper doesn't specify annotators'expertise
-
[25]
Do not output "NA" for a real metric until you have checked all tables
**For IAA values, check tables** -- numeric values are very often in tables, not the prose. Do not output "NA" for a real metric until you have checked all tables
-
[26]
**For total_annotated_items, use the annotated subset size**, not the total corpus/dataset size -- these can differ substantially
-
[27]
sentiment rating
**subtask_name must name the ANNOTATION task**, not the downstream NLP modelling task -- "sentiment rating" not "sentiment classifier"; "NER tagging" not "NER model"
-
[28]
Not reported
**For every numerical value, record evidence** in the `numerical_evidence`object -- do NOT leave it empty when you extracted a non-"Not reported" value. ### Field Interdependencies -- APPLY THESE BEFORE FINALISING OUTPUT These conditional rules take PRECEDENCE over all other guidance. Check each one after filling every field. **A. iaa_value is fully deter...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.