Matter to Mechanism: A Benchmark for AI Co-Scientists in Materials and Battery Research
Pith reviewed 2026-06-28 12:06 UTC · model grok-4.3
The pith
Matter to Mechanism benchmark evaluates AI systems on turning battery materials problems into mechanism-grounded solution hypotheses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The benchmark supplies structured problem statements, candidate hypotheses, reasoning traces, and domain annotations for material system, component, failure mode, intervention, mechanism, target property, and claimed outcome. It scores AI outputs on reasoning fidelity, problem alignment, mechanistic specificity, novelty, plausibility, and problem decomposition quality, then aggregates these into a composite score. This framework distinguishes AI systems in ways text-similarity metrics do not and maintains stability when systems face adversarial stress tests.
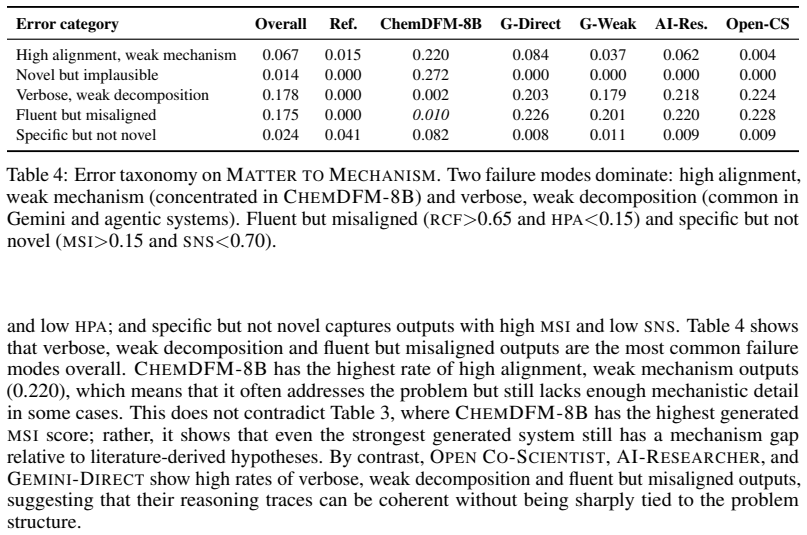
What carries the argument
The Matter to Mechanism benchmark, built from 2,645 publication-derived instances with structured annotations and a multi-metric suite aggregated into a composite score for problem-to-hypothesis reasoning.
If this is right
- AI evaluations in materials science can shift from text overlap to structured checks on whether a hypothesis correctly identifies failure modes and links them to mechanisms.
- Systems can be ranked by how well they decompose problems and propose interventions that are specific to the material component and target property.
- Composite scores give more reliable comparisons than any single metric when developers attempt to game individual dimensions.
- The same annotation structure can highlight which parts of the reasoning chain current AI systems still miss in battery research.
Where Pith is reading between the lines
- The same instance format could be applied to other domains that require mechanism-level explanations, such as catalysis or polymer design.
- If the annotations hold up, the benchmark could serve as a training signal to improve how language models generate and justify scientific proposals.
- Running the same test set on human experts would provide a direct performance ceiling against which AI systems can be measured.
Load-bearing premise
The 2,645 instances and their annotations for failure mode, intervention, mechanism, and outcome accurately represent the original scientific publications without systematic errors or selection biases.
What would settle it
Independent domain experts re-annotating a random sample of instances and finding frequent disagreement on assigned failure modes, mechanisms, or claimed outcomes would show the benchmark does not faithfully capture the source papers.
Figures

read the original abstract
AI co-scientists are increasingly used for scientific discovery, but current evaluations still do not test them on a key task: moving from a concrete scientific or technological problem to a plausible, mechanism-grounded solution hypothesis. This gap is especially important in materials science and, in particular, battery research, where a useful proposal must identify the relevant failure mode, propose a credible intervention, and explain why that intervention should improve the target property. We introduce Matter to Mechanism, a benchmark for evaluating AI co-scientists on problem-to-hypothesis reasoning in materials science, with a focus on battery materials research. The benchmark contains 2,645 instances derived from scientific publications. Each instance includes a structured problem statement, a candidate solution hypothesis, an explicit reasoning trace, and domain-grounded annotations such as material system, component, failure mode, intervention, mechanism, target property, and claimed outcome. We also introduce a metric suite that measures reasoning fidelity, problem alignment, mechanistic specificity, novelty, plausibility, and problem decomposition quality, and combine them into a composite score. Using this framework, we evaluate several AI co-scientist systems and show that Matter to Mechanism reveals interpretable system differences that are only partially recovered by standard text-similarity metrics. We further show through adversarial stress tests that the aggregate score is more stable than individual metric dimensions under superficial gaming attacks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Matter to Mechanism, a benchmark of 2,645 instances derived from battery materials publications. Each instance contains a structured problem statement, candidate hypothesis, reasoning trace, and annotations for material system, failure mode, intervention, mechanism, target property, and claimed outcome. A metric suite is defined for reasoning fidelity, problem alignment, mechanistic specificity, novelty, plausibility, and decomposition quality, aggregated into a composite score. Evaluations of several AI co-scientist systems are reported, claiming that the benchmark exposes interpretable system differences only partially recovered by text-similarity metrics and that the aggregate score is more stable than individual dimensions under adversarial stress tests.
Significance. If the instance annotations faithfully capture the source literature, the benchmark would fill a documented gap in evaluating mechanism-grounded hypothesis generation for AI co-scientists in materials science. The adversarial stability analysis is a concrete methodological contribution that could inform metric design in other scientific reasoning benchmarks.
major comments (1)
- [Abstract / benchmark construction] The central claims—that interpretable system differences are revealed and that the aggregate score is more stable under attacks—rest on the assumption that the 2,645 instances and their failure-mode/mechanism annotations accurately and without systematic bias represent the original publications. The manuscript reports neither the derivation protocol, inter-annotator agreement statistics, nor any expert validation of the annotations (Abstract; benchmark construction section). Without these checks, both the observed differences and the stability result risk being artifacts of curation rather than properties of the reasoning task.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in benchmark construction. We agree this is a substantive point and will revise accordingly to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / benchmark construction] The central claims—that interpretable system differences are revealed and that the aggregate score is more stable under attacks—rest on the assumption that the 2,645 instances and their failure-mode/mechanism annotations accurately and without systematic bias represent the original publications. The manuscript reports neither the derivation protocol, inter-annotator agreement statistics, nor any expert validation of the annotations (Abstract; benchmark construction section). Without these checks, both the observed differences and the stability result risk being artifacts of curation rather than properties of the reasoning task.
Authors: We agree that the absence of a detailed derivation protocol, inter-annotator agreement (IAA) statistics, and expert validation details is a limitation in the current manuscript and could undermine confidence in the claims. In the revised version we will expand the benchmark construction section with: (1) the full extraction and structuring protocol used to derive the 2,645 instances from source publications, including selection criteria and any automated vs. manual steps; (2) annotation guidelines for each field (material system, failure mode, intervention, mechanism, target property, claimed outcome) and the process by which annotations were assigned; (3) IAA metrics (e.g., Cohen’s kappa or raw agreement) computed on a subset of instances annotated by multiple domain experts; and (4) any post-annotation expert review or validation performed. If the original curation involved a single primary annotator with limited multi-annotator overlap, we will explicitly state this as a limitation rather than claiming full multi-annotator validation. These additions will directly address the risk that observed differences or stability results are curation artifacts. revision: yes
Circularity Check
No circularity: benchmark construction and evaluation are externally grounded
full rationale
The paper introduces an external benchmark (2,645 instances with structured annotations) and a composite metric suite for evaluating AI co-scientists. No derivation chain, equations, fitted parameters, or predictions are presented that reduce to the inputs by construction. Claims about interpretable system differences and aggregate-score stability under attacks rest on direct evaluation results rather than self-referential definitions or self-citation load-bearing premises. No self-citation, ansatz smuggling, or renaming patterns appear in the provided text. This is a standard benchmark paper whose central content is independent of its own curation process.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Annotations for material system, component, failure mode, intervention, mechanism, target property, and claimed outcome in each instance are accurate and representative of the source publications.
Reference graph
Works this paper leans on
-
[2]
IdeaBench: Benchmarking Large Language Models for Research Idea Generation. arXiv e-prints , keywords =. doi:10.48550/arXiv.2411.02429 , archivePrefix =. 2411.02429 , primaryClass =
-
[5]
MTBBench: A Multimodal Sequential Clinical Decision-Making Benchmark in Oncology. arXiv e-prints , keywords =. doi:10.48550/arXiv.2511.20490 , archivePrefix =. 2511.20490 , primaryClass =
-
[27]
Expert-Guided LLM Reasoning for Battery Discovery: From AI-Driven Hypothesis to Synthesis and Characterization. arXiv e-prints , keywords =. doi:10.48550/arXiv.2507.16110 , archivePrefix =. 2507.16110 , primaryClass =
-
[28]
A Penalty Goes a Long Way: Measuring Lexical Diversity in Synthetic Texts Under Prompt-Influenced Length Variations. arXiv e-prints , keywords =. doi:10.48550/arXiv.2507.15092 , archivePrefix =. 2507.15092 , primaryClass =
-
[33]
arXiv preprint arXiv:2406.13163 , year=
Llmatdesign: Autonomous materials discovery with large language models , author=. arXiv preprint arXiv:2406.13163 , year=
-
[37]
Domain-Grounded Evaluation of LLMs in International Student Knowledge. arXiv e-prints , keywords =. doi:10.48550/arXiv.2511.20653 , archivePrefix =. 2511.20653 , primaryClass =
-
[38]
arXiv e-prints , keywords =
Beyond Static Snapshots: A Grounded Evaluation Framework for Language Models at the Agentic Frontier. arXiv e-prints , keywords =
-
[39]
Improving Context Fidelity via Native Retrieval-Augmented Reasoning
Wang, Suyuchen and Wang, Jinlin and Wang, Xinyu and Li, Shiqi and Tang, Xiangru and Hong, Sirui and Chang, Xiao-Wen and Wu, Chenglin and Liu, Bang. Improving Context Fidelity via Native Retrieval-Augmented Reasoning. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1075
-
[40]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[41]
Nawaf Alampara , Mara Schilling-Wilhelmi , Marti \ n o R \' os-Garc \' a , Indrajeet Mandal , Pranav Khetarpal , Hargun Singh Grover , N. M. Anoop Krishnan , and Kevin Maik Jablonka . Probing the limitations of multimodal language models for chemistry and materials research . arXiv e-prints, art. arXiv:2411.16955, November 2024. doi:10.48550/arXiv.2411.16955
-
[42]
Neither Valid nor Reliable? Investigating the Use of LLMs as Judges
Khaoula Chehbouni , Mohammed Haddou , Jackie Chi Kit Cheung , and Golnoosh Farnadi . Neither Valid nor Reliable? Investigating the Use of LLMs as Judges . arXiv e-prints, art. arXiv:2508.18076, August 2025. doi:10.48550/arXiv.2508.18076
-
[43]
Ziru Chen , Shijie Chen , Yuting Ning , Qianheng Zhang , Boshi Wang , Botao Yu , Yifei Li , Zeyi Liao , Chen Wei , Zitong Lu , Vishal Dey , Mingyi Xue , Frazier N. Baker , Benjamin Burns , Daniel Adu-Ampratwum , Xuhui Huang , Xia Ning , Song Gao , Yu Su , and Huan Sun . ScienceAgentBench: Toward Rigorous Assessment of Language Agents for Data-Driven Scien...
-
[44]
Gritsenko, Zhe Zhao, Neil Houlsby, Fernando Diaz, Donald Metzler, and Oriol Vinyals
Mostafa Dehghani , Yi Tay , Alexey A. Gritsenko , Zhe Zhao , Neil Houlsby , Fernando Diaz , Donald Metzler , and Oriol Vinyals . The Benchmark Lottery . arXiv e-prints, art. arXiv:2107.07002, July 2021. doi:10.48550/arXiv.2107.07002
-
[45]
ROUGE 2.0: Updated and Improved Measures for Evaluation of Summarization Tasks
Kavita Ganesan . ROUGE 2.0: Updated and Improved Measures for Evaluation of Summarization Tasks . arXiv e-prints, art. arXiv:1803.01937, March 2018. doi:10.48550/arXiv.1803.01937
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1803.01937 2018
-
[46]
Juraj Gottweis , Wei-Hung Weng , Alexander Daryin , Tao Tu , Anil Palepu , Petar Sirkovic , Artiom Myaskovsky , Felix Weissenberger , Keran Rong , Ryutaro Tanno , Khaled Saab , Dan Popovici , Jacob Blum , Fan Zhang , Katherine Chou , Avinatan Hassidim , Burak Gokturk , Amin Vahdat , Pushmeet Kohli , Yossi Matias , Andrew Carroll , Kavita Kulkarni , Nenad ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.18864 2025
-
[47]
Jiawei Gu , Xuhui Jiang , Zhichao Shi , Hexiang Tan , Xuehao Zhai , Chengjin Xu , Wei Li , Yinghan Shen , Shengjie Ma , Honghao Liu , Saizhuo Wang , Kun Zhang , Yuanzhuo Wang , Wen Gao , Lionel Ni , and Jian Guo . A Survey on LLM-as-a-Judge . arXiv e-prints, art. arXiv:2411.15594, November 2024. doi:10.48550/arXiv.2411.15594
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.15594 2024
-
[48]
Rui Jiao , Yue Zhang , and Jinku Li . Trustworthy Reasoning: Evaluating and Enhancing Factual Accuracy in LLM Intermediate Thought Processes . arXiv e-prints, art. arXiv:2507.22940, July 2025. doi:10.48550/arXiv.2507.22940
-
[49]
Shrinidhi Kumbhar , Venkatesh Mishra , Kevin Coutinho , Divij Handa , Ashif Iquebal , and Chitta Baral . Hypothesis Generation for Materials Discovery and Design Using Goal-Driven and Constraint-Guided LLM Agents . arXiv e-prints, art. arXiv:2501.13299, January 2025. doi:10.48550/arXiv.2501.13299
-
[50]
Evaluating Scoring Bias in LLM-as-a-Judge
Qingquan Li , Shaoyu Dou , Kailai Shao , Chao Chen , and Haixiang Hu . Evaluating Scoring Bias in LLM-as-a-Judge . arXiv e-prints, art. arXiv:2506.22316, June 2025. doi:10.48550/arXiv.2506.22316
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.22316 2025
-
[51]
Siyu Liu , Bo Hu , Beilin Ye , Jiamin Xu , David J. Srolovitz , and Tongqi Wen . MatTools: Benchmarking Large Language Models for Materials Science Tools . arXiv e-prints, art. arXiv:2505.10852, May 2025 a . doi:10.48550/arXiv.2505.10852
-
[52]
ResearchBench: Benchmarking LLMs in Scientific Discovery via Inspiration-Based Task Decomposition
Yujie Liu , Zonglin Yang , Tong Xie , Jinjie Ni , Ben Gao , Yuqiang Li , Shixiang Tang , Wanli Ouyang , Erik Cambria , and Dongzhan Zhou . ResearchBench: Benchmarking LLMs in Scientific Discovery via Inspiration-Based Task Decomposition . arXiv e-prints, art. arXiv:2503.21248, March 2025 b . doi:10.48550/arXiv.2503.21248
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.21248 2025
-
[53]
Benchmark Data Repositories for Better Benchmarking
Rachel Longjohn , Markelle Kelly , Sameer Singh , and Padhraic Smyth . Benchmark Data Repositories for Better Benchmarking . arXiv e-prints, art. arXiv:2410.24100, October 2024. doi:10.48550/arXiv.2410.24100
-
[54]
Elbeheiry , Mar \' a Victoria Gil , Maximilian Greiner , Caroline T
Adrian Mirza , Nawaf Alampara , Sreekanth Kunchapu , Marti \ n o R \' os-Garc \' a , Benedict Emoekabu , Aswanth Krishnan , Tanya Gupta , Mara Schilling-Wilhelmi , Macjonathan Okereke , Anagha Aneesh , Amir Mohammad Elahi , Mehrdad Asgari , Juliane Eberhardt , Hani M. Elbeheiry , Mar \' a Victoria Gil , Maximilian Greiner , Caroline T. Holick , Christina ...
-
[55]
BixBench: a Comprehensive Benchmark for LLM-based Agents in Computational Biology
Ludovico Mitchener , Jon M Laurent , Alex Andonian , Benjamin Tenmann , Siddharth Narayanan , Geemi P Wellawatte , Andrew White , Lorenzo Sani , and Samuel G Rodriques . BixBench: a Comprehensive Benchmark for LLM-based Agents in Computational Biology . arXiv e-prints, art. arXiv:2503.00096, February 2025. doi:10.48550/arXiv.2503.00096
-
[56]
A Call for Clarity in Reporting BLEU Scores
Matt Post . A Call for Clarity in Reporting BLEU Scores . arXiv e-prints, art. arXiv:1804.08771, April 2018. doi:10.48550/arXiv.1804.08771
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1804.08771 2018
-
[57]
DiscoveryBench: Towards Data-Driven Discovery with Large Language Models
Bodhisattwa Prasad Majumder , Harshit Surana , Dhruv Agarwal , Bhavana Dalvi Mishra , Abhijeetsingh Meena , Aryan Prakhar , Tirth Vora , Tushar Khot , Ashish Sabharwal , and Peter Clark . DiscoveryBench: Towards Data-Driven Discovery with Large Language Models . arXiv e-prints, art. arXiv:2407.01725, July 2024. doi:10.48550/arXiv.2407.01725
-
[58]
Bender , Amandalynne Paullada , Emily Denton , and Alex Hanna
Inioluwa Deborah Raji , Emily M. Bender , Amandalynne Paullada , Emily Denton , and Alex Hanna . AI and the Everything in the Whole Wide World Benchmark . arXiv e-prints, art. arXiv:2111.15366, November 2021. doi:10.48550/arXiv.2111.15366
-
[59]
Judging the judges: A systematic study of position bias in LLM -as-a-judge
Lin Shi, Chiyu Ma, Wenhua Liang, Xingjian Diao, Weicheng Ma, and Soroush Vosoughi. Judging the judges: A systematic study of position bias in LLM -as-a-judge. In Kentaro Inui, Sakriani Sakti, Haofen Wang, Derek F. Wong, Pushpak Bhattacharyya, Biplab Banerjee, Asif Ekbal, Tanmoy Chakraborty, and Dhirendra Pratap Singh, editors, Proceedings of the 14th Inte...
-
[60]
Is Cosine-Similarity of Embeddings Really About Similarity? arXiv e-prints, art
Harald Steck , Chaitanya Ekanadham , and Nathan Kallus . Is Cosine-Similarity of Embeddings Really About Similarity? arXiv e-prints, art. arXiv:2403.05440, March 2024. doi:10.48550/arXiv.2403.05440
-
[61]
On the Kendall Correlation Coefficient
Alexei Stepanov . On the Kendall Correlation Coefficient . arXiv e-prints, art. arXiv:1507.01427, July 2015. doi:10.48550/arXiv.1507.01427
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1507.01427 2015
-
[62]
AI-Researcher: Autonomous Scientific Innovation
Jiabin Tang , Lianghao Xia , Zhonghang Li , and Chao Huang . AI-Researcher: Autonomous Scientific Innovation . arXiv e-prints, art. arXiv:2505.18705, May 2025. doi:10.48550/arXiv.2505.18705
-
[63]
SciCode: A Research Coding Benchmark Curated by Scientists
Minyang Tian , Luyu Gao , Shizhuo Dylan Zhang , Xinan Chen , Cunwei Fan , Xuefei Guo , Roland Haas , Pan Ji , Kittithat Krongchon , Yao Li , Shengyan Liu , Di Luo , Yutao Ma , Hao Tong , Kha Trinh , Chenyu Tian , Zihan Wang , Bohao Wu , Yanyu Xiong , Shengzhu Yin , Minhui Zhu , Kilian Lieret , Yanxin Lu , Genglin Liu , Yufeng Du , Tianhua Tao , Ofir Press...
-
[64]
Ngoc Tran , Hieu Tran , Son Nguyen , Hoan Nguyen , and Tien N. Nguyen . Does BLEU Score Work for Code Migration? arXiv e-prints, art. arXiv:1906.04903, June 2019. doi:10.48550/arXiv.1906.04903
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1906.04903 1906
-
[65]
Kiri Wagstaff . Machine Learning that Matters . arXiv e-prints, art. arXiv:1206.4656, June 2012. doi:10.48550/arXiv.1206.4656
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1206.4656 2012
-
[66]
Mirror: A Multiple-perspective Self-Reflection Method for Knowledge-rich Reasoning
Hanqi Yan , Qinglin Zhu , Xinyu Wang , Lin Gui , and Yulan He . Mirror: A Multiple-perspective Self-Reflection Method for Knowledge-rich Reasoning . arXiv e-prints, art. arXiv:2402.14963, February 2024. doi:10.48550/arXiv.2402.14963
-
[67]
Justice or Prejudice? Quantifying Biases in LLM-as-a-Judge
Jiayi Ye , Yanbo Wang , Yue Huang , Dongping Chen , Qihui Zhang , Nuno Moniz , Tian Gao , Werner Geyer , Chao Huang , Pin-Yu Chen , Nitesh V Chawla , and Xiangliang Zhang . Justice or Prejudice? Quantifying Biases in LLM-as-a-Judge . arXiv e-prints, art. arXiv:2410.02736, October 2024. doi:10.48550/arXiv.2410.02736
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.02736 2024
-
[68]
Fooling SHAP with Output Shuffling Attacks
Jun Yuan and Aritra Dasgupta . Fooling SHAP with Output Shuffling Attacks . arXiv e-prints, art. arXiv:2408.06509, August 2024. doi:10.48550/arXiv.2408.06509
-
[69]
BERTScore: Evaluating Text Generation with BERT
Tianyi Zhang , Varsha Kishore , Felix Wu , Kilian Q. Weinberger , and Yoav Artzi . BERTScore: Evaluating Text Generation with BERT . arXiv e-prints, art. arXiv:1904.09675, April 2019. doi:10.48550/arXiv.1904.09675
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1904.09675 1904
-
[70]
Developing ChemDFM as a large language foundation model for chemistry
Zihan Zhao , Da Ma , Lu Chen , Liangtai Sun , Zihao Li , Yi Xia , Bo Chen , Hongshen Xu , Zichen Zhu , Su Zhu , Shuai Fan , Guodong Shen , Kai Yu , and Xin Chen . Developing ChemDFM as a large language foundation model for chemistry . Cell Reports Physical Science, 6 0 (4): 0 102523, April 2025. doi:10.1016/j.xcrp.2025.102523
-
[71]
GeSS: Benchmarking Geometric Deep Learning under Scientific Applications with Distribution Shifts
Deyu Zou , Shikun Liu , Siqi Miao , Victor Fung , Shiyu Chang , and Pan Li . GeSS: Benchmarking Geometric Deep Learning under Scientific Applications with Distribution Shifts . arXiv e-prints, art. arXiv:2310.08677, October 2023. doi:10.48550/arXiv.2310.08677
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.