RoboSemanticBench: Diagnosing Semantic Grounding in Action Prediction for VLA Models
Pith reviewed 2026-06-28 14:37 UTC · model grok-4.3
The pith
VLA models grasp candidate blocks but select the semantically correct one at near-random rates after controlling for grasp success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
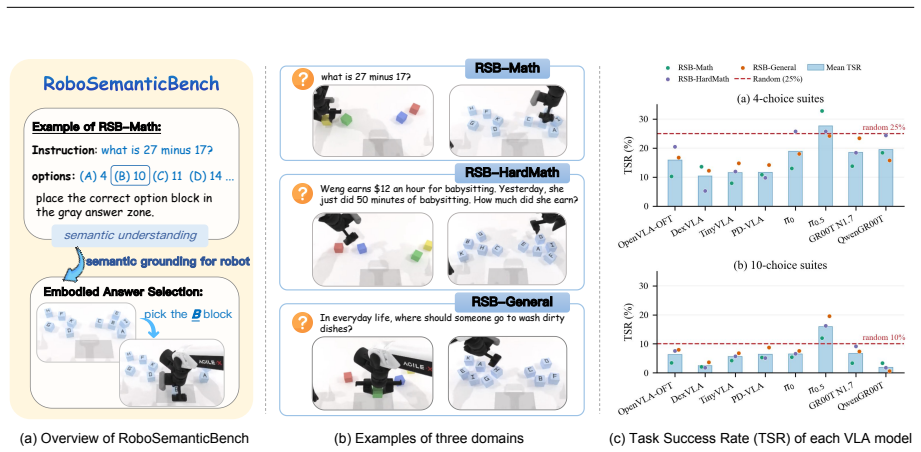
Vision-language-action (VLA) models are built on the premise that semantic understanding from pretrained language or vision-language backbones should guide robot action prediction. Yet robot fine-tuning is optimized as imitation over task-specific action distributions, and many evaluations can be solved through visual or instruction-action shortcuts. RoboSemanticBench reveals that across representative VLA models, many policies learn to grasp candidate blocks but select the semantically correct block at near-random or below-random rates after controlling for grasp success, revealing a persistent gap between backbone-level semantic competence and action prediction.
What carries the argument
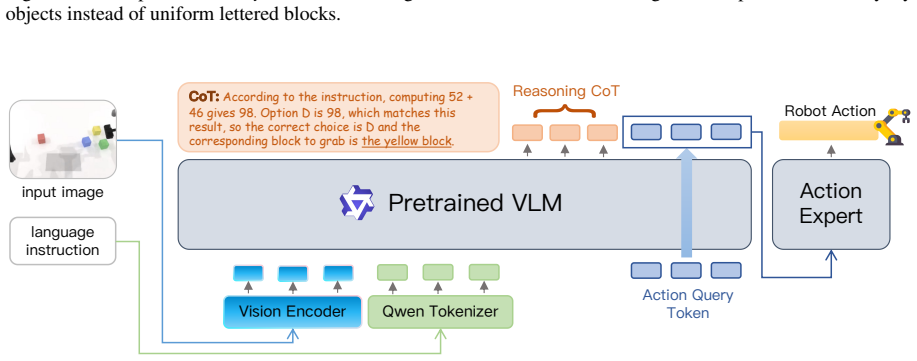
RoboSemanticBench, an embodied benchmark in which a robot must grasp the physical block whose label matches the correct answer to a presented multiple-choice arithmetic or factual question.
If this is right
- VLA models can succeed on standard tasks through shortcuts that do not require semantic comprehension of instructions.
- Imitation learning on task-specific action distributions does not transfer backbone semantic competence into action selection.
- Evaluations that do not control for grasp success separately from target selection overestimate semantic grounding.
- A persistent gap implies that current VLA training leaves models unable to use complex instruction semantics for physical target selection.
Where Pith is reading between the lines
- Explicit semantic supervision or auxiliary losses during fine-tuning might be needed to close the observed gap.
- The same shortcut problem could appear in other embodied models that combine language understanding with motor output.
- Diagnostic benchmarks like this one could be extended to continuous or open-ended instructions to test generalization beyond multiple choice.
Load-bearing premise
The multiple-choice block-grasping setup isolates semantic understanding and rules out all non-semantic shortcuts such as visual patterns or instruction-action correlations that do not require understanding the question content.
What would settle it
Finding that models select the correct block significantly above random rates once visual patterns, spatial biases, and instruction-action correlations are fully eliminated would show the gap does not exist.
Figures


read the original abstract
Vision-language-action (VLA) models are built on the premise that semantic understanding from pretrained language or vision-language backbones should guide robot action prediction. Yet robot fine-tuning is optimized as imitation over task-specific action distributions, and many evaluations can be solved through visual or instruction-action shortcuts. We introduce RoboSemanticBench (RSB), an embodied benchmark for diagnosing semantic grounding in action prediction: whether post-trained VLA models can use complex instruction semantics to select and manipulate the correct physical target. In each episode, a robot receives a multiple-choice math or general-knowledge question, observes candidate answer blocks, and must grasp the block corresponding to the correct answer. RSB covers controlled arithmetic, grade-school mathematical understanding, and commonsense or factual understanding under four-choice and ten-choice suites. Across representative VLA models, we find that many policies learn to grasp candidate blocks but select the semantically correct block at near-random or below-random rates after controlling for grasp success, revealing a persistent gap between backbone-level semantic competence and action prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RoboSemanticBench (RSB), an embodied benchmark in which a robot receives a multiple-choice math or general-knowledge question, observes candidate answer blocks, and must grasp the block matching the correct answer. The central empirical claim is that representative VLA models learn to grasp blocks at reasonable rates but select the semantically correct block at near-random or below-random rates once grasp success is conditioned upon, indicating a persistent gap between backbone-level semantic competence and action prediction under both four-choice and ten-choice protocols.
Significance. If the benchmark design demonstrably rules out non-semantic shortcuts, the result would be significant for VLA research: it would provide concrete evidence that imitation-based fine-tuning on task-specific action distributions fails to transfer pretrained semantic understanding into grounded action selection. The benchmark itself supplies a reusable diagnostic that could be adopted by the community to track progress on semantic grounding. The work is empirical rather than theoretical and does not claim parameter-free derivations or machine-checked proofs.
major comments (2)
- [Benchmark design and experimental controls] Benchmark construction and evaluation protocol: the headline result (near-random semantic selection after grasp-success filtering) assumes that the physical multiple-choice layout plus natural-language instruction forces reliance on question semantics. The manuscript does not report ablations that preserve visual appearance, block positions, and action space while destroying semantic content (e.g., random question labels or permuted answer mappings). Without such controls, the observed rates could arise from surface-level instruction-to-position correlations rather than a semantic-grounding deficit; this directly affects the interpretation of the central claim.
- [Results and analysis] Results presentation (§ on model comparisons): the paper reports selection rates conditioned on grasp success but does not provide per-model sample sizes, exact binomial or permutation-test p-values against the random baseline, or confidence intervals. If the number of evaluated episodes per model is modest, the claim of “below-random” performance cannot be distinguished from sampling variance; this is load-bearing for the quantitative diagnosis of the semantic gap.
minor comments (2)
- [Abstract and §1] The abstract and introduction should explicitly state the total number of episodes and the exact random baseline (1/4 or 1/10) used for each suite so readers can immediately assess the magnitude of the reported gap.
- [Figure 1 and environment description] Figure captions for the environment layout should clarify whether block positions are randomized across episodes or fixed, as fixed layouts could introduce additional visual shortcuts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on RoboSemanticBench. The two major comments highlight important aspects of experimental controls and statistical reporting. We address each point below and commit to revisions that directly strengthen the central claims without altering the manuscript's empirical findings.
read point-by-point responses
-
Referee: [Benchmark design and experimental controls] Benchmark construction and evaluation protocol: the headline result (near-random semantic selection after grasp-success filtering) assumes that the physical multiple-choice layout plus natural-language instruction forces reliance on question semantics. The manuscript does not report ablations that preserve visual appearance, block positions, and action space while destroying semantic content (e.g., random question labels or permuted answer mappings). Without such controls, the observed rates could arise from surface-level instruction-to-position correlations rather than a semantic-grounding deficit; this directly affects the interpretation of the central claim.
Authors: We agree that explicit semantic-ablated controls would provide stronger evidence against surface shortcuts. Our current protocol already randomizes block positions per episode and draws from diverse math/knowledge questions whose correct answers cannot be inferred from visual or positional cues alone. Nevertheless, to directly rule out instruction-to-position correlations, we will add two ablations in the revision: (1) replacing questions with random strings while keeping block visuals and positions fixed, and (2) permuting the answer-to-block mappings. These will be run on the same models and reported alongside the main results. revision: yes
-
Referee: [Results and analysis] Results presentation (§ on model comparisons): the paper reports selection rates conditioned on grasp success but does not provide per-model sample sizes, exact binomial or permutation-test p-values against the random baseline, or confidence intervals. If the number of evaluated episodes per model is modest, the claim of “below-random” performance cannot be distinguished from sampling variance; this is load-bearing for the quantitative diagnosis of the semantic gap.
Authors: We acknowledge that the current presentation lacks the requested statistical details. In the revised manuscript we will report, for each model and condition: (i) the exact number of evaluated episodes, (ii) 95% confidence intervals on the conditional selection rates, and (iii) exact binomial-test p-values against the appropriate random baseline (1/4 or 1/10). These additions will allow readers to assess whether observed rates are statistically distinguishable from chance. revision: yes
Circularity Check
Empirical benchmark evaluation with no derivation chain or self-referential reductions
full rationale
The paper introduces RoboSemanticBench as an empirical diagnostic benchmark for VLA models and reports experimental results on grasp success versus semantic selection rates. No equations, fitted parameters, or predictive derivations appear in the provided text. Central claims rest on direct observation of model behavior under controlled multiple-choice tasks rather than any reduction to prior author-defined quantities or self-citations. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, and 1 others. 2024.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alexander Herzog, Jasmine Hsu, Brian Ichter, and 35 others. 2023. Rt-2: Vision-language-action models ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, and 1 others. 2025. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Suhwan Choi, Yunsung Lee, Yubeen Park, Chris Dongjoo Kim, Ranjay Krishna, Dieter Fox, and Youngjae Yu
-
[5]
vla-eval: A unified evaluation harness for vision-language-action models.Preprint, arXiv:2603.13966
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plap- pert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems.Preprint, arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
StarVLA Community. 2026. Starvla: A lego-like codebase for vision-language-action model developing.arXiv preprint arXiv:2604.05014
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duck- worth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, and 3 others. 2023. Palm-e: An embodied multimodal language mod...
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [9]
-
[10]
Yu Fang, Yuchun Feng, Dong Jing, Jiaqi Liu, Yue Yang, Zhenyu Wei, Daniel Szafir, and Mingyu Ding
- [11]
-
[12]
Gemini Team. 2025. A new era of intelligence with gemini 3
2025
-
[13]
Xinyu Guo, Bin Xie, Wei Chai, Xianchi Deng, Tiancai Wang, Zhengxing Wu, and Xingyu Chen. 2026. Pri- orvla: Prior-preserving adaptation for vision-language-action models.Preprint, arXiv:2605.10925
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Hancock, Xindi Wu, Lihan Zha, Olga Russakovsky, and Anirudha Majumdar
Asher J. Hancock, Xindi Wu, Lihan Zha, Olga Russakovsky, and Anirudha Majumdar. 2025. Actions as language: Fine-tuning vlms into vlas without catastrophic forgetting.Preprint, arXiv:2509.22195
-
[15]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt
-
[16]
InInternational Conference on Learning Repre- sentations
Measuring massive multitask language understanding. InInternational Conference on Learning Repre- sentations
- [17]
-
[18]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, and 17 others. 2025.π0.5: a vision-language-action model with open-world...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. 2024. Openvla: An open-source vision-language-action model. InAnnual Conference on Robot Learn...
2024
-
[20]
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Oier Mees, Karl Pertsch, Homer Rich Walke, Chuyuan Fu, Ishikaa Lu- nawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. 2024. Evaluating real-world robot manipulation policies in simulation. InAnnual Conference on Robot Learning (CoRL)
2024
-
[21]
LangForce: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries
Shijie Lian, Bin Yu, Xiaopeng Lin, Laurence T. Yang, Zhaolong Shen, Changti Wu, Yuzhuo Miao, Cong Huang, and Kai Chen. 2026. Langforce: Bayesian decomposition of vision language action models via latent action queries.Preprint, arXiv:2601.15197
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. 2023. Libero: Benchmarking knowledge transfer for lifelong robot learning.arXiv preprint arXiv:2306.03310
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. 2022. Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automa- tion Letters (RA-L), 7(3):7327–7334
2022
-
[24]
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Man- dlekar, and Yuke Zhu. 2024. Robocasa: Large-scale simulation of everyday tasks for generalist robots. In Robotics: Science and Systems
2024
-
[25]
NVIDIA, :, Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi "Jim" Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, and 24 others. 2025. Gr00t n1: An open foundation model for generalist humanoid robots.Preprint, arXiv:2503.14734
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, and 1 others. 2024. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE
2024
-
[27]
Pierre Sermanet, Tianli Ding, Jeffrey Zhao, Fei Xia, Debidatta Dwibedi, Keerthana Gopalakrishnan, Christine Chan, Gabriel Dulac-Arnold, Sharath Maddineni, Nikhil J Joshi, Pete Florence, Wei Han, Robert Baruch, Yao Lu, Suvir Mirchandani, Peng Xu, Pannag Sanketi, Karol Hausman, Izhak Shafran, and 2 others. 2023. Robovqa: Multimodal long-horizon reasoning fo...
-
[28]
Modi Shi, Yuxiang Lu, Huijie Wang, and Shaoze Yang. 2025. Open-sourcing go-1: The bitter lessons of building vla systems at scale.https://opendrivelab.com/OpenGO1/. Blog post
2025
- [29]
-
[30]
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yunliang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. 2024. Octo: An open-source generalist robot policy.Preprint, arXiv:2405.12213
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Selma Wanna, Agnes Luhtaru, Jonathan Salfity, Ryan Barron, Juston Moore, Cynthia Matuszek, and Mitch Pryor. 2026. Limited linguistic diversity in embodied ai datasets.Preprint, arXiv:2601.03136
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Junjie Wen, Yichen Zhu, Jinming Li, Zhibin Tang, Chaomin Shen, and Feifei Feng. 2025. Dexvla: Vision- language model with plug-in diffusion expert for general robot control.arXiv preprint arXiv:2502.05855
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Kun Wu, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, Yaxin Peng, and 1 others. 2025. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation. InIEEE Robotics and Automation Letters (RA-L)
2025
-
[34]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chen- gen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. Qwen3 technical report.Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Bin Yu, Shijie Lian, Xiaopeng Lin, Yuliang Wei, Zhaolong Shen, Changti Wu, Yuzhuo Miao, Xinming Wang, Bailing Wang, Cong Huang, and Kai Chen. 2026. Twinbrainvla: Unleashing the potential of generalist vlms for embodied tasks via asymmetric mixture-of-transformers.Preprint, arXiv:2601.14133
-
[36]
Borong Zhang, Jiahao Li, Jiachen Shen, Yishuai Cai, Yuhao Zhang, Yuanpei Chen, Juntao Dai, Jiaming Ji, and Yaodong Yang. 2025. Vla-arena: An open-source framework for benchmarking vision-language-action models. Preprint, arXiv:2512.22539. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [37]
-
[38]
Jianke Zhang, Xiaoyu Chen, Qiuyue Wang, Mingsheng Li, Yanjiang Guo, Yucheng Hu, Jiajun Zhang, Shuai Bai, Junyang Lin, and Jianyu Chen. 2026. Vlm4vla: Revisiting vision-language-models in vision-language- action models.Preprint, arXiv:2601.03309
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Jianke Zhang, Yuanfei Luo, Yucheng Hu, Xiaoyu Chen, Yanjiang Guo, Ziyang Liu, Hongbin Xu, Tian Lan, and Jianyu Chen. 2026. Uam: A dual-stream perspective on forgetting in vla training.Preprint, arXiv:2605.15735
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [40]
-
[41]
Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu-Gang Jiang, and Xipeng Qiu. 2024. Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks.Preprint, arXiv:2412.18194
-
[42]
what is 27 minus 17? options: (A) 4 (B) 10 (C) 11 (D) 14. place the correct option block in the gray answer zone,
Zhongyi Zhou, Yichen Zhu, Minjie Zhu, Junjie Wen, Ning Liu, Zhiyuan Xu, Weibin Meng, Ran Cheng, Yaxin Peng, Chaomin Shen, and Feifei Feng. 2025. Chatvla: Unified multimodal understanding and robot control with vision-language-action model. InProceedings of the Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguist...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.