Do Multimodal Agents Really Benefit from Tool Use? A Systematic Study of Capability Gains
Pith reviewed 2026-06-28 14:56 UTC · model grok-4.3
The pith
Tool access yields little consistent improvement for multimodal agents beyond learning call patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
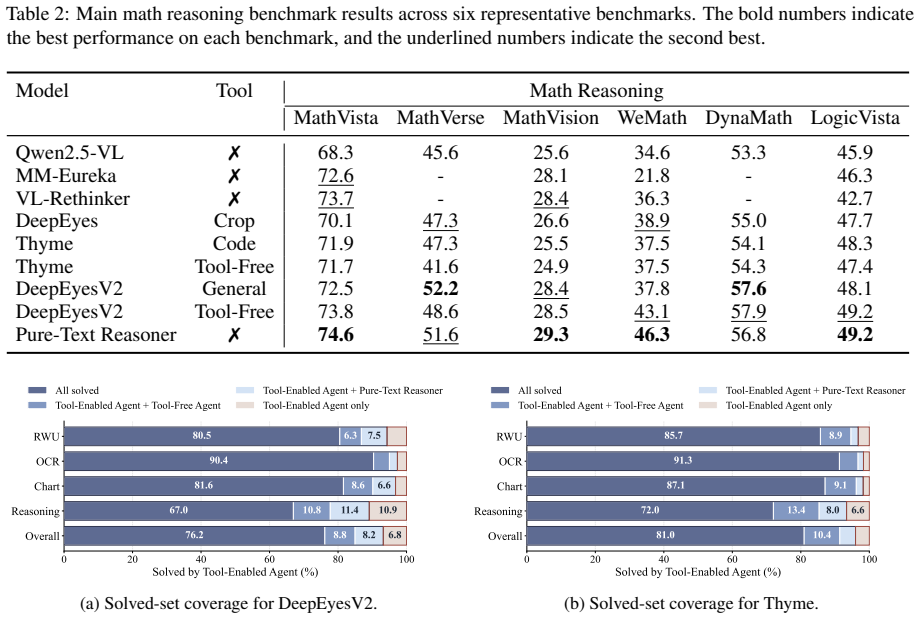
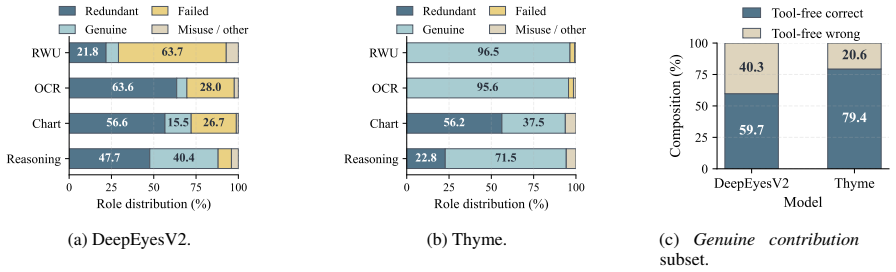
Across the studied agents and tasks, tool access produces little consistent aggregate improvement and does not reliably reduce generated-token cost. Only a small tool-only solved set remains: 93 percent of DeepEyesV2 tool-solved problems and 96 percent of Thyme tool-solved problems are also solved by at least one non-tool setting. Mechanism ablations show the full tool-use loop does not consistently outperform the tool-call format or the returned execution result alone.
What carries the argument
The tool-only solved set, which counts problems solved exclusively when tools are available but not in any non-tool control condition, serves as the direct measure of capability expansion from tool use.
If this is right
- Tool access does not reliably reduce generated-token cost in the evaluated settings.
- The complete tool-use loop does not consistently outperform the tool-call format or execution result alone.
- Agents learn tool-calling patterns more reliably than they acquire tool-contributed capabilities.
- Evaluation protocols should separate tool availability from whether tools expand the set of solvable problems.
Where Pith is reading between the lines
- The same pattern of limited tool-only gains may appear in other multimodal agents trained with similar reinforcement or supervised signals.
- Benchmarks could be strengthened by adding explicit controls that test whether tool results supply answer-critical information rather than just format cues.
- Training objectives that reward integration of tool outputs rather than call frequency might shift agents toward greater capability expansion.
- Parallel studies on text-only agents would clarify whether the observed pattern is specific to multimodal tool loops.
Load-bearing premise
The Tool-Free counterpart and Pure-Text Reasoner trained from the same source pool without tool-calling trajectories form fair controls that isolate the contribution of tool use itself.
What would settle it
A substantially larger set of problems solved exclusively by the full tool-use condition and unsolved by all non-tool and partial-tool ablations would demonstrate genuine capability gains from tool access.
Figures


read the original abstract
Tool-augmented multimodal agents show strong benchmark gains, often taken as evidence that agents have learned to use tools. We argue that this interpretation can be premature: a tool-call trace alone does not show whether the tool supplied answer-critical information. We study two representative ``thinking with images'' agents, Thyme and DeepEyesV2, across real-world understanding, OCR, chart understanding, and mathematical reasoning. Each agent is compared with its Tool-Free counterpart and with a Pure-Text Reasoner trained from the same source pool without tool-calling trajectories. Tool access yields little consistent aggregate improvement, does not reliably reduce generated-token cost, and leaves only a small tool-only solved set: 93% of DeepEyesV2's tool-solved problems and 96% of Thyme's are also solved by at least one non-tool setting. Mechanism ablations further show that the full tool-use loop does not consistently outperform either the tool-call format or the returned execution result alone. In the settings we study, the analyzed agents appear to learn tool-calling patterns more reliably than tool-contributed capabilities, suggesting that evaluation should distinguish tool availability from whether tools actually expand what agents can solve.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that tool access in multimodal agents Thyme and DeepEyesV2 yields little consistent aggregate improvement over Tool-Free counterparts and Pure-Text Reasoners trained from the same source pool without tool-calling trajectories. Across real-world understanding, OCR, chart understanding, and mathematical reasoning, tool use does not reliably reduce generated-token cost, and 93% of DeepEyesV2's tool-solved problems and 96% of Thyme's are also solved by at least one non-tool setting. Mechanism ablations indicate the full tool-use loop does not consistently outperform tool-call format or execution result alone, suggesting agents learn tool-calling patterns more reliably than tool-contributed capabilities.
Significance. If the result holds after verification of baseline parity, the finding would be significant for multimodal agent research by challenging the common interpretation of benchmark gains as evidence of learned tool use and by advocating evaluations that separate tool availability from actual expansion of solvable problems. The study supplies concrete overlap statistics and ablation outcomes that could inform more rigorous agent assessment protocols.
major comments (1)
- [Abstract] Abstract: The central claim that tool access adds little capability beyond patterns rests on Tool-Free counterparts and Pure-Text Reasoners serving as fair controls that isolate the contribution of tool use. The abstract supplies no quantitative comparison of training compute, data volume, filtering effects, or parity on non-tool tasks, so performance gaps cannot yet be attributed specifically to the presence or absence of tool-calling trajectories.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address the concern regarding the abstract below.
read point-by-point responses
-
Referee: The central claim that tool access adds little capability beyond patterns rests on Tool-Free counterparts and Pure-Text Reasoners serving as fair controls that isolate the contribution of tool use. The abstract supplies no quantitative comparison of training compute, data volume, filtering effects, or parity on non-tool tasks, so performance gaps cannot yet be attributed specifically to the presence or absence of tool-calling trajectories.
Authors: We agree that the abstract would be strengthened by briefly noting the quantitative controls. The full manuscript (Methods and Appendix) establishes that Tool-Free and Pure-Text models were trained from the identical source pool with the same data volume, compute budget, and hyperparameters, with no differential filtering applied. Direct parity on non-tool tasks is reported via side-by-side benchmark results. We will revise the abstract to include a concise statement referencing these equalities so that the isolation of tool-use effects is clearer from the outset. revision: yes
Circularity Check
No circularity: purely empirical comparison study
full rationale
The paper conducts a systematic empirical evaluation of two multimodal agents (Thyme and DeepEyesV2) against Tool-Free counterparts and Pure-Text Reasoners trained from the same source pool. All claims rest on direct benchmark performance measurements, ablation studies, and counts of tool-only solved problems across real-world understanding, OCR, chart, and math tasks. No equations, derivations, fitted parameters, or mathematical predictions are present. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The controls are described explicitly in the abstract and methods as removing tool-calling trajectories while sharing the source pool; any debate over their fairness concerns experimental validity rather than circular reduction of a claimed derivation to its inputs. The study is self-contained against external benchmarks and contains no steps that match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Visual-rft: Visual reinforcement fine-tuning. In2025 IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 2034–2044. Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chun- yuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai- Wei Chang, Michel Galley, and Jianfeng Gao. 2024. MathVista: Evaluating mathematical reasoning of foundation models in visual...
work page internal anchor Pith review Pith/arXiv arXiv 2034
-
[2]
LogicVista: Multimodal llm logical reason- ing benchmark in visual contexts.arXiv preprint arXiv:2407.04973. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Day- iheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. Qwen...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
InThe Fourteenth International Conference on Learning Representa- tions
Deepeyes: Incentivizing ”thinking with im- ages” via reinforcement learning. InThe Fourteenth International Conference on Learning Representa- tions. Chengke Zou, Xingang Guo, Rui Yang, Junyu Zhang, Bin Hu, and Huan Zhang. 2025. DynaMath: A dy- namic visual benchmark for evaluating mathematical reasoning robustness of vision language models. In The Thirte...
2025
-
[4]
,→ ,→ - Confirmatory: the tool mainly confirms or repeats an already available conclusion.,→ - Irrelevant: the tool output is not materially useful for solving the task.,→
Information Gain - Novel: the tool provides new task-relevant information not already available from the model's unaided reasoning. ,→ ,→ - Confirmatory: the tool mainly confirms or repeats an already available conclusion.,→ - Irrelevant: the tool output is not materially useful for solving the task.,→
-
[5]
Tool Output Quality - Useful/Correct: the tool output is correct and meaningfully usable.,→ - Partially useful: the tool output is partially correct, incomplete, or only weakly useful.,→ - Wrong/Failed: the tool output is wrong, failed, or unusable.,→
-
[6]
Integration Status - Used correctly: the final reasoning meaningfully uses the tool output in a correct way. ,→ ,→ - Ignored: useful or potentially useful tool output is not actually used.,→ - Misused/Misinterpreted: the model uses the tool output incorrectly or is misled by it.,→ Important decision rules:
-
[7]
Only assign Novel if the tool output clearly reveals or computes information ,→ ,→ that was not already available from the pre-tool reasoning.,→
Novel should be rare. Only assign Novel if the tool output clearly reveals or computes information ,→ ,→ that was not already available from the pre-tool reasoning.,→
-
[8]
If the tool only redisplays the original image without crop, zoom, OCR, enhancement, measurement, ,→ ,→ parsing, or other transformation, do NOT label it as Novel.,→
-
[9]
If the tool output is empty, trivial, or only repeats the original image view, it should usually be ,→ ,→ Confirmatory or Irrelevant, not Novel
-
[10]
A correct final answer can still correspond to ,→ ,→ Confirmatory, Partially useful, or even Irrelevant tool use.,→
Do not infer tool usefulness from final correctness. A correct final answer can still correspond to ,→ ,→ Confirmatory, Partially useful, or even Irrelevant tool use.,→
-
[11]
If it adds ,→ ,→ little or no new evidence, prefer Partially useful or Wrong/Failed as appropriate.,→
Useful/Correct requires that the tool output itself is materially informative and correct. If it adds ,→ ,→ little or no new evidence, prefer Partially useful or Wrong/Failed as appropriate.,→
-
[12]
If the post-tool answer mostly repeats the same conclusion already stated before the tool call, that is ,→ ,→ evidence against Novel information gain
-
[13]
It is NOT a valid value for tool_output_quality or ,→ ,→ integration_status
Irrelevant is ONLY valid for information_gain. It is NOT a valid value for tool_output_quality or ,→ ,→ integration_status
-
[14]
If the tool output is empty, blank, trivial, or unusable, then tool_output_quality should usually be ,→ ,→ Wrong/Failed
-
[15]
If the tool output is merely the same unprocessed image view, with no crop / zoom / OCR / enhancement / ,→ ,→ measurement / parsing, then tool_output_quality should usually be Partially useful at most, and often ,→ ,→ Wrong/Failed if the execution adds nothing
-
[16]
information_gain
If the tool output adds nothing and the final answer comes from the same pre-tool reasoning, prefer ,→ ,→ integration_status = Ignored, not Used correctly.,→ Field-specific allowed values: - information_gain must be exactly one of: Novel, Confirmatory, Irrelevant,→ - tool_output_quality must be exactly one of: Useful/Correct, Partially useful, Wrong/Faile...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.