When Do Attention Circuits Form? Developmental Trajectories of Capability and Attention-Sink Emergence Across Three 1B-ClassArchitectures
Pith reviewed 2026-06-28 15:44 UTC · model grok-4.3
The pith
In 1B-class models trained on DCLM, induction-circuit formation precedes attention-sink formation by an order of magnitude in tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
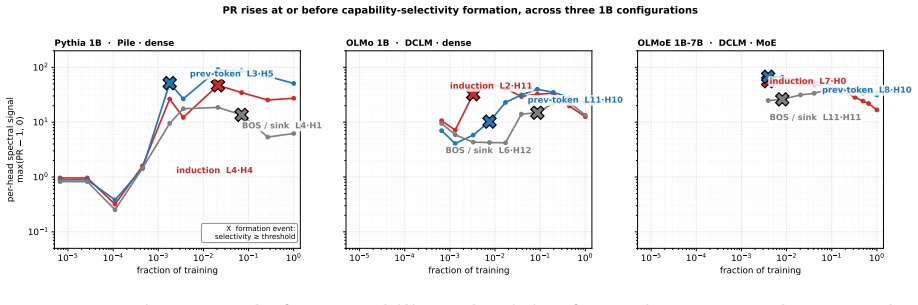
In the three 1B-class models, layers 0 and 1 produce zero BOS-classified heads at every revision. The whole-model BOS-attractor fraction follows model-specific shapes: gradual ramp, sharp phase transition, or gradual ramp. In DCLM-trained models the induction transition precedes the BOS-attractor transition by 10-20 times the number of tokens and the two transitions have different shapes. The capability-specific screen reaches the final induction circuit within 0.3-2 percent of total training tokens, and per-head participation ratio is already elevated when a head first crosses its capability-selectivity threshold.
What carries the argument
The participation-ratio spectral signal combined with the all-head capability-specific selectivity screen that classifies induction, previous-token, and BOS-attractor heads at each checkpoint.
If this is right
- Layers 0 and 1 never produce BOS-classified heads in any of the three models at any revision.
- BOS-attractor emergence takes one of three distinct shapes depending on the model and data combination.
- The capability-specific screen identifies the final induction circuit after only a small fraction of total training tokens.
- Elevated participation ratio appears at or before the point where an induction head crosses its selectivity threshold.
Where Pith is reading between the lines
- Circuit monitoring methods could be applied during training to observe capability emergence without completing a full run.
- Basic induction capability does not require the presence of attention-sink heads.
- The same staged timing pattern may appear in models larger than 1B or trained on different data mixtures.
Load-bearing premise
The participation-ratio spectral signal together with the capability-specific selectivity screen correctly labels head types at early revisions without false positives and without needing the final model state.
What would settle it
A DCLM training run on a 1B-class model in which the token count at which induction heads reach high selectivity is within a factor of two of the token count at which BOS-attractor heads emerge would falsify the claimed separation of transitions.
Figures


read the original abstract
We track the developmental trajectory of attention-head circuit formation across three 1B-class language models spanning two architecture families (dense transformer, mixture-of-experts) and two pretraining corpora (The Pile, DCLM): Pythia 1B, OLMo 1B-0724-hf, and OLMoE 1B-7B-0924. At each of 10 log-spaced revisions per model -- 30 mechanistic-interpretability runs in total -- we apply a participation-ratio (PR) spectral signal and an all-head capability-specific selectivity screen to track induction, previous-token, and BOS-attractor heads as they emerge. Five findings. (F1) Layers 0 and 1 produce zero BOS-classified heads at every revision in every model: the L0/L1 zero-BOS floor is an architectural property, not a learned outcome. (F2) The whole-model BOS-attractor fraction follows three distinct emergence shapes -- a gradual ramp in Pythia 1B, a sharp phase transition in OLMo 1B (7% to 70% between adjacent checkpoints), and a gradual ramp in OLMoE 1B-7B. (F3) In DCLM models, induction-circuit formation precedes BOS-attractor formation by 10-20x in tokens; capability-circuit formation and attention-sink formation are two transitions, not one. (F4) The capability-specific screen converges to the final induction circuit within 0.3-2% of total training tokens -- circuit identification does not require the final model. (F5) For every final-checkpoint induction head sampled across all three models, per-head PR is elevated at or before the first revision at which that head crosses its capability-selectivity threshold. The results refine the induction-phase-transition framing: in 1B-class models trained on DCLM, the induction transition and the attention-sink transition are separated by an order of magnitude in tokens and have qualitatively different shapes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript tracks attention-head circuit formation in three 1B-class models (Pythia 1B, OLMo 1B, OLMoE 1B) across 10 log-spaced revisions each using a participation-ratio (PR) spectral signal and an all-head capability-specific selectivity screen. It reports five findings: L0/L1 produce zero BOS heads in all models; BOS-attractor fractions show model-specific emergence shapes; in DCLM models induction precedes BOS by 10-20x tokens with distinct shapes; the selectivity screen converges to the final induction circuit within 0.3-2% of training tokens; and final induction heads show elevated PR at or before their selectivity threshold crossing. The central claim is that capability and attention-sink transitions are separate, not coincident.
Significance. If the PR/selectivity classification is robust at early checkpoints, the work supplies concrete empirical timelines separating induction-circuit and BOS-attractor emergence across architectures and corpora. The 30-run design and observation that circuit identification does not require the final model are strengths that could inform future mechanistic studies of pretraining dynamics.
major comments (3)
- [F3] F3: The headline separation claim (induction precedes BOS by 10-20x tokens with qualitatively different shapes) is measured by the first revision at which heads cross the capability-selectivity threshold and exhibit elevated PR. The manuscript provides no external validation of this joint screen against functional behavior at those early revisions, which is load-bearing for the temporal-offset result.
- [F5] F5 and abstract: The internal consistency check that per-head PR is elevated at or before the selectivity threshold crossing does not rule out false positives or delayed detections caused by training noise or a moving capability baseline at early checkpoints.
- [Abstract] Abstract and methods description: The capability-selectivity threshold is listed as a free parameter; no sensitivity analysis or justification for its value is reported, directly affecting which heads are classified as induction versus BOS at each revision.
minor comments (2)
- The abstract states that 30 runs were performed but reports no error bars, exclusion criteria, or how variability across runs is aggregated in the emergence curves.
- Clarify whether the PR spectral signal is computed on the full attention matrix or per-head and whether any preprocessing (e.g., centering) is applied before the participation-ratio calculation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on validation and parameter choices. We respond point-by-point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: The headline separation claim (induction precedes BOS by 10-20x tokens with qualitatively different shapes) is measured by the first revision at which heads cross the capability-selectivity threshold and exhibit elevated PR. The manuscript provides no external validation of this joint screen against functional behavior at those early revisions, which is load-bearing for the temporal-offset result.
Authors: We agree that functional validation (e.g., via patching or ablation) at early checkpoints would strengthen the temporal-offset claim. The current evidence rests on the uniform application of the selectivity screen and the independent PR spectral measure across 30 runs. The offset appears consistently in both DCLM models. In revision we will add an explicit limitations paragraph acknowledging the lack of early functional tests and their implications for interpreting the separation. revision: partial
-
Referee: F5 and abstract: The internal consistency check that per-head PR is elevated at or before the selectivity threshold crossing does not rule out false positives or delayed detections caused by training noise or a moving capability baseline at early checkpoints.
Authors: F5 is presented strictly as an internal consistency observation, not a full defense against noise or baseline drift. We accept that checkpoint variability could affect early detections. We will revise the wording in F5 and the abstract to clarify its correlational nature and briefly note potential confounds from training dynamics. revision: yes
-
Referee: Abstract and methods description: The capability-selectivity threshold is listed as a free parameter; no sensitivity analysis or justification for its value is reported, directly affecting which heads are classified as induction versus BOS at each revision.
Authors: The threshold was chosen to recover the induction heads known to exist in the final checkpoint of each model. We will add a methods paragraph justifying this choice and include a sensitivity analysis (varying the threshold by ±10%) as a new appendix figure in the revised manuscript. revision: yes
Circularity Check
No circularity: purely observational tracking of circuit emergence via fixed screens
full rationale
The paper applies a participation-ratio spectral signal and capability-specific selectivity screen to log-spaced model checkpoints across three architectures. All five findings (F1-F5) are direct measurements of when heads cross thresholds or exhibit PR elevation at specific revisions. No equations derive a target quantity from fitted parameters, no predictions reduce to inputs by construction, and no self-citations are invoked as load-bearing uniqueness theorems. The separation claim (induction precedes BOS by 10-20x tokens) is an empirical timing observation, not a self-referential derivation. The method is applied uniformly without the final model state being required for classification (F4), confirming the analysis is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- capability-selectivity threshold
axioms (1)
- domain assumption The participation-ratio spectral signal reliably detects attention-head types across training revisions.
Reference graph
Works this paper leans on
-
[1]
Transformer Circuits Thread , year =
In-context Learning and Induction Heads , author =. Transformer Circuits Thread , year =
-
[2]
Efficient Streaming Language Models with Attention Sinks
Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike , title =. International Conference on Learning Representations , year =. 2309.17453 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
International Conference on Machine Learning (ICML) , year =
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling , author =. International Conference on Machine Learning (ICML) , year =
-
[4]
OLMo: Accelerating the Science of Language Models
OLMo: Accelerating the Science of Language Models , author =. arXiv preprint arXiv:2402.00838 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
OLMoE: Open Mixture-of-Experts Language Models
OLMoE: Open Mixture-of-Experts Language Models , author =. arXiv preprint arXiv:2409.02060 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
DataComp-LM: In search of the next generation of training sets for language models
DataComp-LM: In Search of the Next Generation of Training Sets for Language Models , author =. arXiv preprint arXiv:2406.11794 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
The Pile: An 800GB Dataset of Diverse Text for Language Modeling , author =. arXiv preprint arXiv:2101.00027 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
International Conference on Learning Representations (ICLR) , year =
Interpretability in the Wild: A Circuit for Indirect Object Identification in GPT-2 Small , author =. International Conference on Learning Representations (ICLR) , year =
-
[9]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Towards Automated Circuit Discovery for Mechanistic Interpretability , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[10]
Transformer Circuits Thread , year =
A Mathematical Framework for Transformer Circuits , author =. Transformer Circuits Thread , year =
-
[11]
Does Circuit Analysis Interpretability Scale? Evidence from Multiple Choice Capabilities in Chinchilla , author =. arXiv preprint arXiv:2307.09458 , year =
-
[12]
The Linear Centroids Hypothesis: Features as Directions Learned by Local Experts
The Linear Centroids Hypothesis: Features as Directions Learned by Local Experts , author =. arXiv preprint arXiv:2604.11962 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Spectral Edge Dynamics of Training Trajectories: Signal--Noise Geometry Across Scales , author =. arXiv preprint arXiv:2603.15678 , year =
-
[14]
Gradient-Direction Sensitivity Reveals Linear-Centroid Coupling Hidden by Optimizer Trajectories
Gradient-Direction Sensitivity Reveals Linear-Centroid Coupling Hidden by Optimizer Trajectories , author =. arXiv preprint arXiv:2604.25143 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Spectral Probe-Circuits: A Three-Step Recipe for Identifying Attention-Head Circuits in Pretrained Transformers , author =. arXiv preprint , year =. 2605.24059 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Pattern Selectivity vs Task-Causal Structure: Composed-Task Circuits across Three 1
Xu, Yongzhong , year =. Pattern Selectivity vs Task-Causal Structure: Composed-Task Circuits across Three 1
-
[17]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[18]
International Conference on Learning Representations (ICLR) , year =
Progress Measures for Grokking via Mechanistic Interpretability , author =. International Conference on Learning Representations (ICLR) , year =
-
[19]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models , author =. arXiv preprint arXiv:2403.19647 , year =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.