GC-MoE: Genomics-Guided Cell-Type-Specific Mixture of Experts for Histology-Based Single-Cell Spatial Transcriptomics
Pith reviewed 2026-06-28 15:28 UTC · model grok-4.3
The pith
GC-MoE routes cell-type probabilities from images to combine specialized experts for single-cell gene expression prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
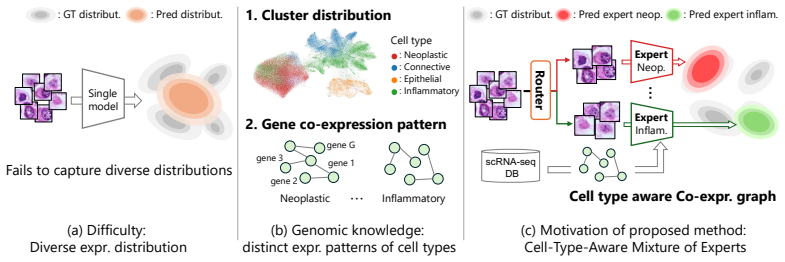
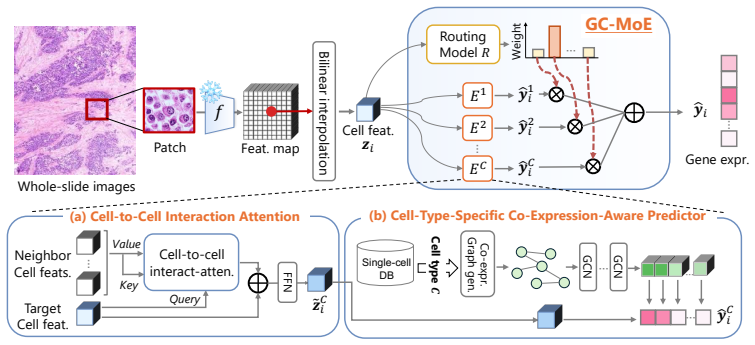
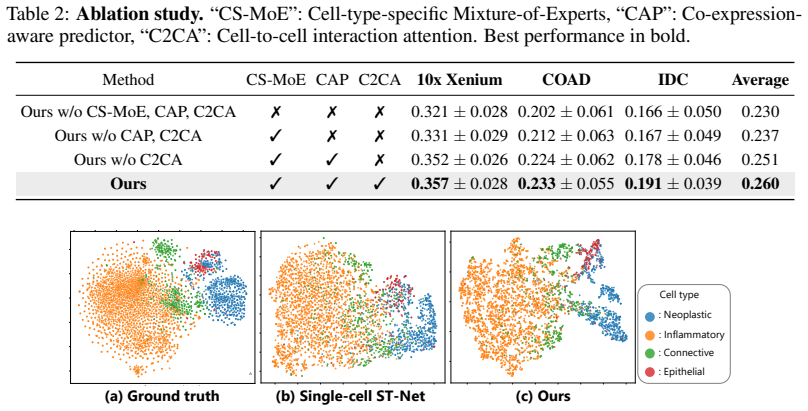
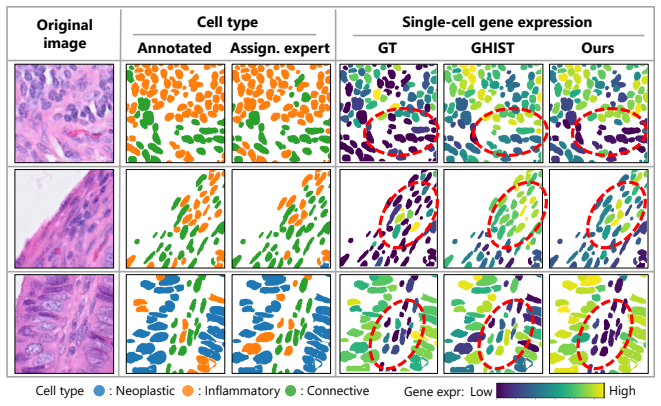
GC-MoE estimates cell-type probabilities with a routing network and softly combines cell-type-specific experts for gene expression prediction, together with CAP and C2CA modules, yielding consistent improvements over existing single-cell and adapted spot-level baselines on public datasets.
What carries the argument
Genomics-Guided Cell-Type-Specific Mixture-of-Experts (GC-MoE) architecture whose routing network produces cell-type probabilities from image features and whose expert heads are trained separately per cell type before soft combination.
If this is right
- Single-cell resolution predictions become feasible from standard H&E slides rather than requiring spot-level averaging.
- Cell-type-specific gene programs are captured explicitly instead of being averaged across mixed populations.
- Neighboring-cell spatial context is incorporated via lightweight attention without full graph neural networks.
- Ablation results indicate that removing either the routing network or the cell-type experts degrades accuracy on the tested datasets.
Where Pith is reading between the lines
- If the cell-type routing generalizes, the same trained model could annotate cell types and infer expression on archival slides from cohorts never sequenced at single-cell resolution.
- The approach may extend to other imaging modalities such as multiplexed immunofluorescence if the routing network is retrained on the new stain set.
- Downstream tasks such as inferring cell-cell communication graphs could use the predicted per-cell profiles directly.
Load-bearing premise
Cell-to-cell expression variability is strongly structured by cell type, allowing an image-based routing network to recover those types accurately enough for the mixture to help.
What would settle it
Performance on a dataset in which measured gene expression varies independently of annotated cell type would show no gain from the routing-plus-experts design.
Figures

read the original abstract
Histology-based single-cell spatial transcriptomics (ST) estimation aims to predict gene expression for individual cells from histopathological images and cell locations, reducing the need for costly single-cell ST measurements. Unlike existing histology-to-ST methods that mainly predict spot-level profiles for local regions containing multiple cells, this task requires modeling cell-to-cell expression variability, which is strongly structured by cell type. We propose Genomics-Guided Cell-Type-Specific Mixture-of-Experts (GC-MoE), which estimates cell-type probabilities with a routing network and softly combines cell-type-specific experts for gene expression prediction. To further encode cell-type-dependent gene programs, we introduce the Cell-Type-Specific Co-Expression-Aware Predictor (CAP), together with a lightweight Cell-to-Cell Interaction Attention (C2CA) module for neighboring-cell context. Experiments and ablations on public single-cell ST datasets show consistent improvements over existing single-cell and adapted spot-level baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GC-MoE, a genomics-guided cell-type-specific mixture-of-experts architecture for predicting single-cell gene expression from histopathological images and cell locations. A routing network estimates cell-type probabilities from images; these probabilities softly weight cell-type-specific expert networks for expression prediction. Additional CAP and C2CA modules encode cell-type-dependent co-expression programs and neighboring-cell context. Experiments and ablations on public single-cell ST datasets are reported to yield consistent improvements over existing single-cell and adapted spot-level baselines.
Significance. If the quantitative results and ablations hold, the work would demonstrate that explicitly decomposing expression variability by cell type via an image-based router and expert mixture can improve single-cell ST prediction accuracy beyond standard regression or spot-level adaptations. The modular design (routing + CAP + C2CA) offers a concrete, testable way to incorporate prior biological structure into histology-to-ST models.
major comments (2)
- [Abstract and Results] Abstract and Results sections: the central claim of consistent improvements is asserted without any reported quantitative metrics (e.g., Pearson/Spearman correlations, RMSE, or p-values), dataset sizes, number of genes/cells, or statistical tests. This prevents assessment of effect size or whether gains exceed noise.
- [Results and Ablation] Results and Ablation sections: no independent metric (accuracy, F1, or correlation) is supplied for the routing network's cell-type probability estimates against ground-truth cell-type labels available in the single-cell ST data. Without this, it remains possible that observed gains derive solely from the CAP or C2CA modules rather than the genomics-guided MoE decomposition, undermining the load-bearing assumption that cell-type structure is sufficiently recoverable from images to justify the expert mixture.
minor comments (2)
- [Methods] Notation for the soft combination of experts (routing weights imes expert outputs) should be written explicitly, preferably with an equation, to clarify whether the combination is performed per-gene or per-cell.
- [Figures and Tables] Figure captions and table headers should state the exact number of cells, spots, and genes used in each experiment so that baseline comparisons are reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that quantitative details and routing validation are important for assessing the claims and will revise the manuscript to incorporate them.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results sections: the central claim of consistent improvements is asserted without any reported quantitative metrics (e.g., Pearson/Spearman correlations, RMSE, or p-values), dataset sizes, number of genes/cells, or statistical tests. This prevents assessment of effect size or whether gains exceed noise.
Authors: We agree that the absence of specific metrics limits evaluation. In the revised manuscript we will report Pearson and Spearman correlations, RMSE, dataset sizes (genes/cells), and statistical tests in both the Abstract and Results sections. revision: yes
-
Referee: [Results and Ablation] Results and Ablation sections: no independent metric (accuracy, F1, or correlation) is supplied for the routing network's cell-type probability estimates against ground-truth cell-type labels available in the single-cell ST data. Without this, it remains possible that observed gains derive solely from the CAP or C2CA modules rather than the genomics-guided MoE decomposition, undermining the load-bearing assumption that cell-type structure is sufficiently recoverable from images to justify the expert mixture.
Authors: We acknowledge that an explicit validation of the routing network is needed to isolate the contribution of the MoE. In the revised version we will add accuracy or correlation metrics for the routing network against ground-truth cell-type labels in the Results and Ablation sections. revision: yes
Circularity Check
No significant circularity; model is a standard empirical proposal validated externally
full rationale
The paper introduces GC-MoE as a new architecture (routing network + cell-type experts + CAP + C2CA) for image-to-single-cell ST prediction and reports empirical gains over baselines on public datasets. No equations, predictions, or uniqueness claims reduce to fitted inputs by construction, self-citation chains, or ansatz smuggling. The central claim is an empirical modeling choice whose validity rests on held-out performance rather than definitional equivalence. This is the normal non-circular case for an ML architecture paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
PyTorch: An Imperative Style, High- Performance Deep Learning Library
Paszke Adam, Gross Sam, Massa Francisco, Lerer Adam, Bradbury James, Chanan Gregory, Killeen Trevor, Lin Zeming, Gimelshein Natalia, Antiga Luca, Desmaison Alban, Köpf Andreas, Yang Edward, DeVito Zach, Raison Martin, Tejani Alykhan, Chilamkurthy Sasank, Steiner Benoit, Fang Lu, Bai Junjie, and Chintala Soumith. PyTorch: An Imperative Style, High- Perform...
2019
-
[2]
Barrett, S
T. Barrett, S. E. Wilhite, P. Ledoux, C. Evangelista, I. F. Kim, M. Tomashevsky, K. A. Marshall, K. H. Phillippy, P. M. Sherman, M. Holko, A. Yefanov, H. Lee, N. Zhang, C. L. Robertson, N. Serova, S. Davis, and A. Soboleva. NCBI GEO: Archive for Functional Genomics Data Sets—Update.Nucleic acids research, 41(D1):D991–D995, 2012
2012
-
[3]
Barrett, S
T. Barrett, S. E. Wilhite, P. Ledoux, C. Evangelista, I. F. Kim, M. Tomashevsky, K. A. Marshall, K. H. Phillippy, P. M. Sherman, M. Holko, A. Yefanov, H. Lee, N. Zhang, C. L. Robertson, N. Serova, S. Davis, and A. Soboleva. High Resolution Mapping of the Tumor Microenvi- ronment Using Integrated Single-Cell, Spatial and in Situ Analysis.Nature communicati...
2023
-
[4]
Mod-squad: Designing Mixtures of Experts as Modular Multi-Task Learners
Zitian Chen, Yikang Shen, Mingyu Ding, Zhenfang Chen, Hengshuang Zhao, Erik G Learned- Miller, and Chuang Gan. Mod-squad: Designing Mixtures of Experts as Modular Multi-Task Learners. InConference on Computer Vision and Pattern Recognition, pages 11828–11837, 2023
2023
-
[5]
Accurate Spatial Gene Expression Prediction by Integrating Multi-resolution Features
Youngmin Chung, Ji Hun Ha, Kyeong Chan Im, and Joo Sang Lee. Accurate Spatial Gene Expression Prediction by Integrating Multi-resolution Features. InComputer Vision and Pattern Recognition, pages 11591–11600, 2024
2024
-
[6]
Williams, Andrew D
Michelli Faria de Oliveira, Meii Chung Juan Pablo Romero, Stephen R. Williams, Andrew D. Gottscho, Anushka Gupta, Susan E. Pilipauskas, Seayar Mohabbat, Nandhini Raman, David J. Sukovich, David M. Patterson, Visium HD Development Team, and Sarah E. B. Taylor. High- definition Spatial Transcriptomic Profiling of Immune Cell Populations in Colorectal Cancer...
2025
-
[7]
Spatial Gene Expression at Single-cell Resolution From Histology Using Deep Learning with GHIST.Nature Methods, 22(9):1900–1910, 2025
Xiaohang Fu, Yue Cao, Beilei Bian, Chuhan Wang, Dinny Graham, Nirmala Pathmanathan, Ellis Patrick, Jinman Kim, and Jean Yee Hwa Yang. Spatial Gene Expression at Single-cell Resolution From Histology Using Deep Learning with GHIST.Nature Methods, 22(9):1900–1910, 2025
1900
-
[8]
Merge: multi-faceted hierarchical graph-based gnn for gene expression prediction from whole slide histopathology images
Aniruddha Ganguly, Debolina Chatterjee, Wentao Huang, Jie Zhang, Alisa Yurovsky, Travis Steele Johnson, and Chao Chen. Merge: multi-faceted hierarchical graph-based gnn for gene expression prediction from whole slide histopathology images. InComputer Vision and Pattern Recognition Conference, pages 15611–15620, 2025
2025
-
[9]
Integrating Spatial Gene Expression and Breast Tumour Morphology via Deep Learning.Nature Biomedical Engineering, 4(8):827–834, 2020
Bryan He, Ludvig Bergenstråhle, Linnea Stenbeck, Abubakar Abid, Alma Andersson, Åke Borg, Jonas Maaskola, Joakim Lundeberg, and James Zou. Integrating Spatial Gene Expression and Breast Tumour Morphology via Deep Learning.Nature Biomedical Engineering, 4(8):827–834, 2020
2020
-
[10]
Deciphering Tumor Ecosystems at Super Resolution from Spatial Transcriptomics with TESLA.Cell Systems, 14(5):404–417, 2023
Jian Hu, Kyle Coleman, Daiwei Zhang, Edward B Lee, Humam Kadara, Linghua Wang, and Mingyao Li. Deciphering Tumor Ecosystems at Super Resolution from Spatial Transcriptomics with TESLA.Cell Systems, 14(5):404–417, 2023
2023
-
[11]
Cl-moe: Enhancing Multimodal Large Language Model with Dual Momentum Mixture-of-Experts for Continual Visual Question Answering
Tianyu Huai, Jie Zhou, Xingjiao Wu, Qin Chen, Qingchun Bai, Ze Zhou, and Liang He. Cl-moe: Enhancing Multimodal Large Language Model with Dual Momentum Mixture-of-Experts for Continual Visual Question Answering. InComputer Vision and Pattern Recognition Conference, pages 19608–19617, 2025. 10
2025
-
[12]
Hest-1k: A dataset for Spatial Transcriptomics and Histology Image Analysis.Neural Information Processing Systems, 37:53798–53833, 2024
Guillaume Jaume, Paul Doucet, Andrew Song, Ming Yang Lu, Cristina Almagro Pérez, Sophia Wagner, Anurag Vaidya, Richard Chen, Drew Williamson, Ahrong Kim, et al. Hest-1k: A dataset for Spatial Transcriptomics and Histology Image Analysis.Neural Information Processing Systems, 37:53798–53833, 2024
2024
-
[13]
A. M. Khaliq, C. Erdogan, Z. Kurt, S. S. Turgut, M. W. Grunvald, T. Rand, S. Khare, J. A. Borgia, D. M. Hayden, S. G. Pappas, H. R. Govekar, A. E. Kam, J. Reiser, K. Turaga, M. Radovich, Y . Zang, Y . Qiu, Y . Liu, M. L. Fishel, A. Turk, V . Gupta, R. Al-Sabti, J. Subramanian, T. M. Kuzel, A. Sadanandam, L. Waldron, A. Hussain, M. Saleem, B. El-Rayes, A. ...
2022
-
[14]
Mixture of Submodules for Domain Adaptive Person Search
Minsu Kim, Seungryong Kim, and Kwanghoon Sohn. Mixture of Submodules for Domain Adaptive Person Search. InConference on Computer Vision and Pattern Recognition, pages 13990–14001, 2025
2025
-
[15]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A Method for Stochastic Optimization.ArXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[16]
MoE-SAM: Enhancing SAM for Medical Image Segmentation with Mixture-of-Experts
Ruocheng Li, Lei Wu, Jingjun Gu, Qi Xu, Wanyi Chen, Xiaoxu Cai, and Jiajun Bu. MoE-SAM: Enhancing SAM for Medical Image Segmentation with Mixture-of-Experts. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 367–377, 2025
2025
-
[17]
High-Density Gen- eration of Spatial Transcriptomics with STAGE.Nucleic Acids Research, 52(9):4843–4856, 2024
Shang Li, Kuo Gai, Kangning Dong, Yiyang Zhang, and Shihua Zhang. High-Density Gen- eration of Spatial Transcriptomics with STAGE.Nucleic Acids Research, 52(9):4843–4856, 2024
2024
-
[18]
A Visual-Language Foundation Model for Computational Pathology.Nature medicine, pages 863–874, 2024
Ming Y Lu, Bowen Chen, Drew FK Williamson, Richard J Chen, Ivy Liang, Tong Ding, Guillaume Jaume, Igor Odintsov, Long Phi Le, Georg Gerber, et al. A Visual-Language Foundation Model for Computational Pathology.Nature medicine, pages 863–874, 2024
2024
-
[19]
SegMoTE: Token-Level Mixture of Experts for Medical Image Segmentation
Yujie Lu, Jingwen Li, Sibo Ju, Yanzhou Su, Yisong Liu, Min Zhu, Junlong Cheng, et al. SegMoTE: Token-Level Mixture of Experts for Medical Image Segmentation.ArXiv preprint arXiv:2602.19213, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Method of the Year: Spatially Resolved Transcriptomics.Nature methods, 18(1):9–14, 2021
Vivien Marx. Method of the Year: Spatially Resolved Transcriptomics.Nature methods, 18(1):9–14, 2021
2021
-
[21]
Leveraging Spatial Transcriptomics as Alternative to Manual Annotations for Deep Learning-Based Nuclei Analysis
Kazuya Nishimura, Ryoma Bise, Haruka Hirose, and Yasuhiro Kojima. Leveraging Spatial Transcriptomics as Alternative to Manual Annotations for Deep Learning-Based Nuclei Analysis. ArXiv preprint, 2026
2026
-
[22]
Leveraging Information in Spatial Transcriptomics to Predict Super-resolution Gene Expression from Histology Images in Tumors.BioRxiv, pages 2021–11, 2021
Minxing Pang, Kenong Su, and Mingyao Li. Leveraging Information in Spatial Transcriptomics to Predict Super-resolution Gene Expression from Histology Images in Tumors.BioRxiv, pages 2021–11, 2021
2021
-
[23]
Learning Transferable Visual Models from Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning Transferable Visual Models from Natural Language Supervision. InInternational Conference on Machine Learning, 2021
2021
-
[24]
U-Net: Convolutional Networks for Biomedical Image Segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional Networks for Biomedical Image Segmentation. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 234–241, 2015
2015
-
[25]
Single-Cell Transcriptomics of 20 Mouse Organs Creates a Tabula Muris: The Tabula Muris Consortium
Nicholas Schaum, Jim Karkanias, Norma F Neff, Andrew P May, Stephen R Quake, Tony Wyss- Coray, Spyros Darmanis, Joshua Batson, Olga Botvinnik, Michelle B Chen, et al. Single-Cell Transcriptomics of 20 Mouse Organs Creates a Tabula Muris: The Tabula Muris Consortium. Nature, 562(7727):367, 2018. 11
2018
-
[26]
Visualization and Analysis of Gene Expression in Tissue Sections by Spatial Transcriptomics
Patrik L Ståhl, Fredrik Salmén, Sanja Vickovic, Anna Lundmark, José Fernández Navarro, Jens Magnusson, Stefania Giacomello, Michaela Asp, Jakub O Westholm, Mikael Huss, et al. Visualization and Analysis of Gene Expression in Tissue Sections by Spatial Transcriptomics. Science, 353(6294):78–82, 2016
2016
-
[27]
Cell- Type-Specific Co-Expression Inference from Single Cell RNA-Sequencing Data.Nature Communications, 14(1):4846, 2023
Chang Su, Zichun Xu, Xinning Shan, Biao Cai, Hongyu Zhao, and Jingfei Zhang. Cell- Type-Specific Co-Expression Inference from Single Cell RNA-Sequencing Data.Nature Communications, 14(1):4846, 2023
2023
-
[28]
Mixture-of-Shape-Experts (Mose): End-to-End Shape Dictionary Framework to Prompt Sam for Generalizable Medical Segmentation
Jia Wei, Xiaoqi Zhao, Jonghye Woo, Jinsong Ouyang, Georges El Fakhri, Qingyu Chen, and Xiaofeng Liu. Mixture-of-Shape-Experts (Mose): End-to-End Shape Dictionary Framework to Prompt Sam for Generalizable Medical Segmentation. InComputer Vision and Pattern Recognition Conference, pages 6448–6458, 2025
2025
-
[29]
S. Z. Wu, G. Al-Eryani, D. L. Roden, S. Junankar, K. Harvey, A. Andersson, A. Thennavan, C. Wang, J. R. Torpy, N. Bartonicek, T. Wang, L. Larsson, D. Kaczorowski, N. I. Weisenfeld, C. R. Uytingco, J. G. Chew, Z. W. Bent, C. L. Chan, V . Gnanasambandapillai, C. A. Dutertre, L. Gluch, M. N. Hui, J. Beith, A. Parker, E. Robbins, D. Segara, C. Cooper, C. Mak,...
2021
-
[30]
Spatially Resolved Gene Expression Prediction from Histology Images via Bi-modal Contrastive Learning.Neural Information Processing Systems, 36:70626–70637, 2023
Ronald Xie, Kuan Pang, Sai Chung, Catia Perciani, Sonya MacParland, Bo Wang, and Gary Bader. Spatially Resolved Gene Expression Prediction from Histology Images via Bi-modal Contrastive Learning.Neural Information Processing Systems, 36:70626–70637, 2023
2023
-
[31]
Inferring Super-Resolved Gene Expression by Integrating Histology Images and Spatial Transcriptomics with HISTEX
Shuailin Xue, Changmiao Wang, Xiaomao Fan, and Wenwen Min. Inferring Super-Resolved Gene Expression by Integrating Histology Images and Spatial Transcriptomics with HISTEX. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 296–306, 2025
2025
-
[32]
Spatial Transcriptomics Analysis of Gene Expression Prediction Using Exemplar Guided Graph Neural Network.Pattern Recognition, 145:109966, 2024
Yan Yang, Md Zakir Hossain, Eric Stone, and Shafin Rahman. Spatial Transcriptomics Analysis of Gene Expression Prediction Using Exemplar Guided Graph Neural Network.Pattern Recognition, 145:109966, 2024
2024
-
[33]
Exemplar Guided Deep Neural Network for Spatial Transcriptomics Analysis of Gene Expression Prediction
Yan Yang, Md Zakir Hossain, Eric A Stone, and Shafin Rahman. Exemplar Guided Deep Neural Network for Spatial Transcriptomics Analysis of Gene Expression Prediction. InWinter Conference on Applications of Computer Vision, pages 5039–5048, 2023. 12
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.