Geometry-Aware Implicit Memory for Video World Models
Pith reviewed 2026-06-28 15:25 UTC · model grok-4.3
The pith
GIM-World distills 3D geometry into implicit memory to keep long video simulations consistent
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
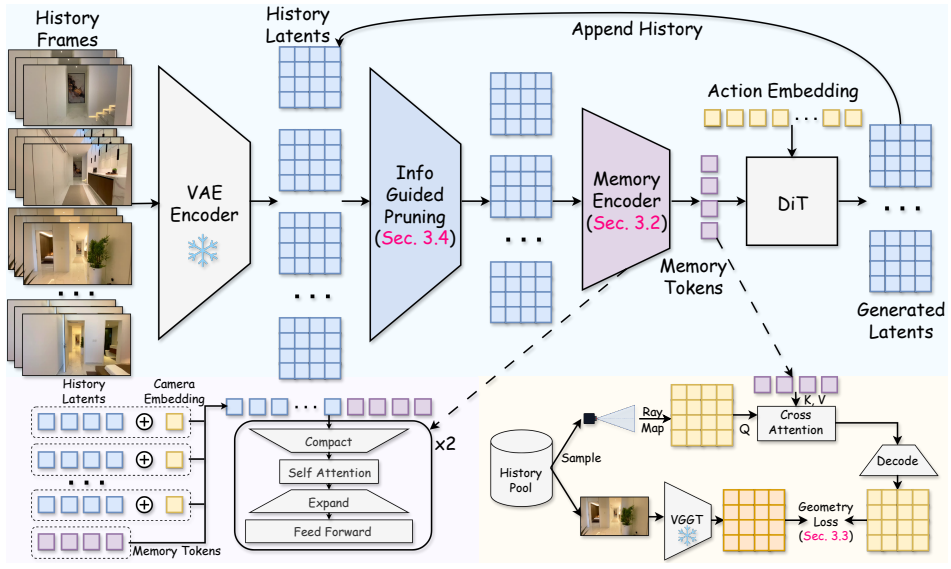
The paper claims that distilling cross-view 3D scene structure from a frozen foundation model into memory tokens during training produces an implicit state that remains geometrically consistent at inference once the geometry head is removed, enabling superior long-horizon rollouts in video world models compared with baselines that either store explicit frames or lack geometric constraints.
What carries the argument
The camera-queryable geometry head that distills 3D scene structure from a frozen foundation model into the memory tokens during training.
If this is right
- Long-horizon video simulations maintain scene geometry without storing raw frames or performing online 3D reconstructions at runtime.
- The memory module stays lightweight at inference because the geometry teacher is discarded after training.
- Encoding cost remains bounded as history grows thanks to the information-guided pruning rule.
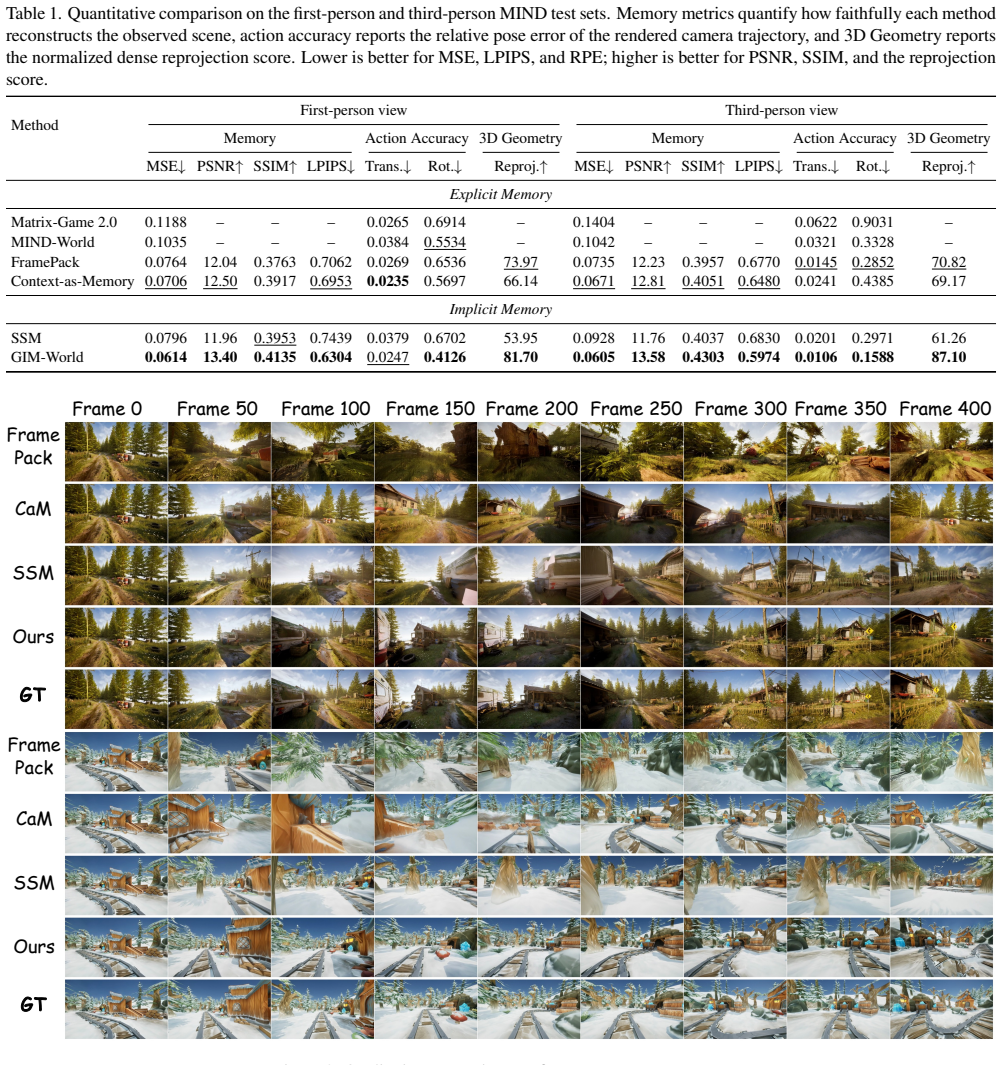
- GIM-World outperforms both explicit-memory approaches and prior implicit-memory designs on the MIND benchmark for geometric and visual consistency.
Where Pith is reading between the lines
- This distillation approach could lower runtime compute for world models deployed in real-time settings such as games or robotics simulators.
- The same training-time geometry injection might extend to other implicit state representations that must preserve spatial relations over time.
- Further measurements could check whether the memory tokens also encode motion or semantic properties beyond the distilled geometry.
Load-bearing premise
The 3D scene structure distilled into memory tokens during training will continue to enforce geometric consistency in the implicit state at inference without the geometry head.
What would settle it
A long-horizon rollout test on MIND where GIM-World produces geometric inconsistencies such as drifting object positions or view mismatches at rates equal to or higher than the explicit-memory and implicit-memory baselines.
Figures




read the original abstract
Video world models aim to simulate controllable visual environments, but long-horizon rollouts depend on what the model remembers after observations leave its native context window. Explicit memories retain frames or online 3D reconstructions, which can suffer from heuristic retrieval errors, redundant appearance storage, or reconstruction artifacts. Implicit memories compress history into a compact state, but existing designs are not explicitly constrained to encode cross-view scene geometry. We propose GIM-World, a geometry-aware implicit memory framework for video world models. A lightweight transformer encoder compresses variable-length history into fixed-size memory tokens, a camera-queryable geometry head distills 3D scene structure from a frozen foundation model into the memory during training, and an information-guided pruning rule keeps encoding cost bounded as history grows. The geometry teacher is discarded at inference, leaving a lightweight memory module. Experiments on MIND show that GIM-World better preserves long-horizon geometric and visual consistency than both explicit- and implicit-memory baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GIM-World, a geometry-aware implicit memory framework for video world models. A lightweight transformer encoder compresses variable-length history into fixed-size memory tokens; during training a camera-queryable geometry head distills 3D scene structure from a frozen foundation model into those tokens; an information-guided pruning rule bounds encoding cost as history grows; the geometry head is discarded at inference, leaving a lightweight memory module. Experiments on the MIND dataset are claimed to show that GIM-World better preserves long-horizon geometric and visual consistency than both explicit- and implicit-memory baselines.
Significance. If the central empirical claim holds with rigorous metrics, the approach could provide a practical route to geometrically consistent implicit states for long-horizon video simulation without the storage or retrieval overhead of explicit 3D reconstructions. The distillation-from-foundation-model design and the pruning rule are concrete technical contributions that, if supported by ablations and probing experiments, would be of interest to the video world-model community.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the abstract asserts superior performance on MIND yet supplies no quantitative metrics, error bars, baseline details, or statistical tests, so the central claim cannot be evaluated.
- [§3.2] §3.2 (Geometry Head and Inference): the claim that memory tokens retain cross-view geometric consistency after the camera-queryable head is removed requires direct evidence (geometry-probing metrics or ablations) that the implicit state alone preserves 3D relations; downstream rollout gains could arise from the pruning rule or compression rather than internalized geometry.
minor comments (2)
- [§3] Notation for the memory tokens and the pruning criterion should be introduced with explicit equations rather than prose only.
- [Figures] Figure captions should state the exact number of roll-out steps and the precise baselines compared.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the abstract asserts superior performance on MIND yet supplies no quantitative metrics, error bars, baseline details, or statistical tests, so the central claim cannot be evaluated.
Authors: We agree that the abstract would benefit from explicit quantitative support. The full results, including metrics, baselines, and any error bars or statistical details, appear in §4 and the tables. We will revise the abstract to include the key performance numbers from the MIND experiments so that the central claim can be evaluated directly from the abstract. revision: yes
-
Referee: [§3.2] §3.2 (Geometry Head and Inference): the claim that memory tokens retain cross-view geometric consistency after the camera-queryable head is removed requires direct evidence (geometry-probing metrics or ablations) that the implicit state alone preserves 3D relations; downstream rollout gains could arise from the pruning rule or compression rather than internalized geometry.
Authors: We acknowledge that the current experiments focus on downstream rollout consistency and do not include separate geometry-probing metrics on the memory tokens after the head is removed. While the design and training objective are intended to internalize geometry, we agree that additional ablations and probing experiments are needed to isolate this effect from the pruning rule and compression. We will add such metrics and ablations in the revised manuscript. revision: yes
Circularity Check
No circularity detected in derivation or claims
full rationale
The paper presents an empirical ML architecture proposal (transformer encoder + training-time geometry distillation head + pruning) whose central claims rest on experimental comparisons on the MIND benchmark rather than any mathematical derivation chain. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text. The inference-time removal of the geometry head is a stated design decision whose validity is asserted via downstream rollout metrics, not by construction from the training objective itself. The work is therefore self-contained against external benchmarks with no reduction of outputs to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A frozen foundation model supplies reliable 3D scene structure that can be distilled into memory tokens.
invented entities (1)
-
camera-queryable geometry head
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Diffusion for world modeling: Visual details matter in atari
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kan- ervisto, Amos Storkey, Tim Pearce, and François Fleuret. Diffusion for world modeling: Visual details matter in atari. Advances in Neural Information Processing Systems, 37: 58757–58791, 2024. 3
2024
-
[2]
Zhaochong An, Orest Kupyn, Théo Uscidda, Andrea Colaco, Karan Ahuja, Serge Belongie, Mar Gonzalez-Franco, and Marta Tintore Gazulla. Vggrpo: Towards world-consistent video generation with 4d latent reward.arXiv preprint arXiv:2603.26599, 2026. 2, 3
arXiv 2026
-
[3]
Ge- nie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Ge- nie: Generative interactive environments. InForty-first Inter- national Conference on Machine Learning, 2024. 1, 3
2024
-
[4]
Mixture of contexts for long video generation.arXiv preprint arXiv:2508.21058, 2025
Shengqu Cai, Ceyuan Yang, Lvmin Zhang, Yuwei Guo, Jun- fei Xiao, Ziyan Yang, Yinghao Xu, Zhenheng Yang, Alan Yuille, Leonidas Guibas, et al. Mixture of contexts for long video generation.arXiv preprint arXiv:2508.21058, 2025. 3
arXiv 2025
-
[5]
Uni3c: Unifying precisely 3d-enhanced camera and human motion controls for video generation
Chenjie Cao, Jingkai Zhou, Shikai Li, Jingyun Liang, Chao- hui Yu, Fan Wang, Xiangyang Xue, and Yanwei Fu. Uni3c: Unifying precisely 3d-enhanced camera and human motion controls for video generation. InProceedings of the SIG- GRAPH Asia 2025 Conference Papers, pages 1–12, 2025. 2, 3
2025
-
[6]
Gamegen-x: Interactive open-world game video generation.arXiv preprint arXiv:2411.00769, 2024
Haoxuan Che, Xuanhua He, Quande Liu, Cheng Jin, and Hao Chen. Gamegen-x: Interactive open-world game video generation.arXiv preprint arXiv:2411.00769, 2024. 3
arXiv 2024
-
[7]
Diffusion forcing: Next-token prediction meets full-sequence diffu- sion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Sim- chowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffu- sion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024. 3
2024
-
[8]
Kaijin Chen, Dingkang Liang, Xin Zhou, Yikang Ding, Xi- aoqiang Liu, Pengfei Wan, and Xiang Bai. Out of sight but not out of mind: Hybrid memory for dynamic video world models.arXiv preprint arXiv:2603.25716, 2026. 2, 3
arXiv 2026
-
[9]
Yabo Chen, Yuanzhi Liang, Jiepeng Wang, Tingxi Chen, Junfei Cheng, Zixiao Gu, Yuyang Huang, Zicheng Jiang, Wei Li, Tian Li, et al. Teleworld: Towards dynamic mul- timodal synthesis with a 4d world model.arXiv preprint arXiv:2601.00051, 2025. 3
arXiv 2025
-
[10]
Oasis: A universe in a trans- former.URL: https://oasis-model
Etched Decart, Quinn McIntyre, Spruce Campbell, Xinlei Chen, and Robert Wachen. Oasis: A universe in a trans- former.URL: https://oasis-model. github. io, 2(3):6, 2024. 1, 3
2024
-
[11]
Hongyang Du, Junjie Ye, Xiaoyan Cong, Runhao Li, Jingcheng Ni, Aman Agarwal, Zeqi Zhou, Zekun Li, Ran- dall Balestriero, and Yue Wang. Videogpa: Distilling geom- etry priors for 3d-consistent video generation.arXiv preprint arXiv:2601.23286, 2026. 2, 3
Pith/arXiv arXiv 2026
-
[12]
Zicheng Duan, Jiatong Xia, Zeyu Zhang, Wenbo Zhang, Gengze Zhou, Chenhui Gou, Yefei He, Feng Chen, Xinyu Zhang, and Lingqiao Liu. Liveworld: Simulating out-of- sight dynamics in generative video world models.arXiv preprint arXiv:2603.07145, 2026. 2, 3
arXiv 2026
-
[13]
Ruili Feng, Han Zhang, Zhantao Yang, Jie Xiao, Zhilei Shu, Zhiheng Liu, Andy Zheng, Yukun Huang, Yu Liu, and Hongyang Zhang. The matrix: Infinite-horizon world generation with real-time moving control.arXiv preprint arXiv:2412.03568, 2024. 3
arXiv 2024
-
[14]
Memcam: Memory- augmented camera control for consistent video generation
Xinhang Gao, Junlin Guan, Shuhan Luo, Wenzhuo Li, Guanghuan Tan, and Jiacheng Wang. Memcam: Memory- augmented camera control for consistent video generation. arXiv preprint arXiv:2603.26193, 2026. 3
arXiv 2026
-
[15]
Junliang Guo, Yang Ye, Tianyu He, Haoyu Wu, Yushu Jiang, Tim Pearce, and Jiang Bian. Mineworld: a real-time and open-source interactive world model on minecraft.arXiv preprint arXiv:2504.08388, 2025. 3
arXiv 2025
-
[16]
Yanjiang Guo, Lucy Xiaoyang Shi, Jianyu Chen, and Chelsea Finn. Ctrl-world: A controllable generative world model for robot manipulation.arXiv preprint arXiv:2510.10125, 2025. 3
Pith/arXiv arXiv 2025
-
[17]
Yanjun Guo, Zhengqiang Zhang, Pengfei Wang, Xinyue Liang, Zhiyuan Ma, and Lei Zhang. Memorize when needed: Decoupled memory control for spatially consistent long- horizon video generation.arXiv preprint arXiv:2604.18215,
-
[18]
World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018. 1, 2
Pith/arXiv arXiv 2018
-
[19]
Mastering diverse domains through world models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models. arXiv preprint arXiv:2301.04104, 2023. 2
Pith/arXiv arXiv 2023
-
[20]
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024. 3
Pith/arXiv arXiv 2024
-
[21]
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, et al. Matrix-game 2.0: An open-source real- time and streaming interactive world model.arXiv preprint arXiv:2508.13009, 2025. 1, 3, 6
Pith/arXiv arXiv 2025
-
[22]
Yicong Hong, Yiqun Mei, Chongjian Ge, Yiran Xu, Yang Zhou, Sai Bi, Yannick Hold-Geoffroy, Mike Roberts, Matthew Fisher, Eli Shechtman, et al. Relic: Interac- tive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040, 2025. 2, 3
arXiv 2025
-
[23]
Geometry-as-context: Modulating explicit 3d in scene-consistent video generation to geometry context
JiaKui Hu, Jialun Liu, Liying Yang, Xinliang Zhang, Kaiwen Li, Shuang Zeng, Yuanwei Li, Haibin Huang, Chi Zhang, and Yanye Lu. Geometry-as-context: Modulating explicit 3d in scene-consistent video generation to geometry context. arXiv preprint arXiv:2602.21929, 2026. 2, 3
arXiv 2026
-
[24]
Junchao Huang, Xinting Hu, Boyao Han, Shaoshuai Shi, Zhuotao Tian, Tianyu He, and Li Jiang. Memory forcing: Spatio-temporal memory for consistent scene generation on minecraft.arXiv preprint arXiv:2510.03198, 2025. 3
arXiv 2025
-
[25]
Vipe: Video pose engine for 3d geometric perception.arXiv preprint arXiv:2508.10934, 2025
Jiahui Huang, Qunjie Zhou, Hesam Rabeti, Aleksandr Ko- rovko, Huan Ling, Xuanchi Ren, Tianchang Shen, Jun Gao, Dmitry Slepichev, Chen-Hsuan Lin, et al. Vipe: Video pose engine for 3d geometric perception.arXiv preprint arXiv:2508.10934, 2025. 6
Pith/arXiv arXiv 2025
-
[26]
Kaiyi Huang, Yukun Huang, Yu Li, Jianhong Bai, Xintao Wang, Zinan Lin, Xuefei Ning, Jiwen Yu, Pengfei Wan, Yu 10 Wang, et al. Cinescene: Implicit 3d as effective scene rep- resentation for cinematic video generation.arXiv preprint arXiv:2602.06959, 2026. 2, 3
arXiv 2026
-
[27]
Siqiao Huang, Jialong Wu, Qixing Zhou, Shangchen Miao, and Mingsheng Long. Vid2world: Crafting video diffu- sion models to interactive world models.arXiv preprint arXiv:2505.14357, 2025. 3
arXiv 2025
-
[28]
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train- test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025. 3
Pith/arXiv arXiv 2025
-
[29]
Fifo-diffusion: Generating infinite videos from text without training.Advances in Neural Information Processing Sys- tems, 37:89834–89868, 2024
Jihwan Kim, Junoh Kang, Jinyoung Choi, and Bohyung Han. Fifo-diffusion: Generating infinite videos from text without training.Advances in Neural Information Processing Sys- tems, 37:89834–89868, 2024. 3
2024
-
[30]
Near- optimal sensor placements in gaussian processes: Theory, efficient algorithms and empirical studies.Journal of Ma- chine Learning Research, 9:235–284, 2008
Andreas Krause, Ajit Singh, and Carlos Guestrin. Near- optimal sensor placements in gaussian processes: Theory, efficient algorithms and empirical studies.Journal of Ma- chine Learning Research, 9:235–284, 2008. 2, 5
2008
-
[31]
Epipolar geometry improves video generation models.arXiv preprint arXiv:2510.21615, 2025
Orest Kupyn, Fabian Manhardt, Federico Tombari, and Christian Rupprecht. Epipolar geometry improves video generation models.arXiv preprint arXiv:2510.21615, 2025. 2, 3
Pith/arXiv arXiv 2025
-
[32]
Ground- ing image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Ground- ing image matching in 3d with mast3r. InEuropean confer- ence on computer vision, pages 71–91. Springer, 2024. 2
2024
-
[33]
Vmem: Consistent interactive video scene generation with surfel-indexed view memory
Runjia Li, Philip Torr, Andrea Vedaldi, and Tomas Jakab. Vmem: Consistent interactive video scene generation with surfel-indexed view memory. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 25690–25699, 2025. 2, 3
2025
-
[34]
Depth anything 3: Recovering the visual space from any views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647, 2025. 6
Pith/arXiv arXiv 2025
-
[35]
Yume: An interactive world gen- eration model.arXiv preprint arXiv:2507.17744, 2025
Xiaofeng Mao, Shaoheng Lin, Zhen Li, Chuanhao Li, Wen- shuo Peng, Tong He, Jiangmiao Pang, Mingmin Chi, Yu Qiao, and Kaipeng Zhang. Yume: An interactive world gen- eration model.arXiv preprint arXiv:2507.17744, 2025. 3
arXiv 2025
-
[36]
Worldpack: Compressed mem- ory improves spatial consistency in video world modeling
Yuta Oshima, Yusuke Iwasawa, Masahiro Suzuki, Yutaka Matsuo, and Hiroki Furuta. Worldpack: Compressed mem- ory improves spatial consistency in video world modeling. arXiv preprint arXiv:2512.02473, 2025. 2, 3
arXiv 2025
-
[37]
Haonan Qiu, Menghan Xia, Yong Zhang, Yingqing He, Xintao Wang, Ying Shan, et al. Freenoise: Tuning-free longer video diffusion via noise rescheduling.arXiv preprint arXiv:2310.15169, 2023. 3
arXiv 2023
-
[38]
Xuanchi Ren, Yifan Lu, Tianshi Cao, Ruiyuan Gao, Shengyu Huang, Amirmojtaba Sabour, Tianchang Shen, Tobias Pfaff, Jay Zhangjie Wu, Runjian Chen, et al. Cosmos-drive- dreams: Scalable synthetic driving data generation with world foundation models.arXiv preprint arXiv:2506.09042,
-
[39]
Gen3c: 3d-informed world-consistent video generation with precise camera con- trol
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexan- der Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world-consistent video generation with precise camera con- trol. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 6121–6132,
-
[40]
Lloyd Russell, Anthony Hu, Lorenzo Bertoni, George Fe- doseev, Jamie Shotton, Elahe Arani, and Gianluca Corrado. Gaia-2: A controllable multi-view generative world model for autonomous driving.arXiv preprint arXiv:2503.20523,
-
[41]
Nedko Savov, Naser Kazemi, Deheng Zhang, Danda Pani Paudel, Xi Wang, and Luc Van Gool. Statespacediffuser: Bringing long context to diffusion world models.arXiv preprint arXiv:2505.22246, 2025. 2, 3
arXiv 2025
-
[42]
Wenqiang Sun, Haiyu Zhang, Haoyuan Wang, Junta Wu, Zehan Wang, Zhenwei Wang, Yunhong Wang, Jun Zhang, Tengfei Wang, and Chunchao Guo. Worldplay: Towards long-term geometric consistency for real-time interactive world modeling.arXiv preprint arXiv:2512.14614, 2025. 1, 3
Pith/arXiv arXiv 2025
-
[43]
InSpatio Team, Donghui Shen, Guofeng Zhang, Haomin Liu, Haoyu Ji, Hujun Bao, Hongjia Zhai, Jialin Liu, Jing Guo, Nan Wang, et al. Inspatio-world: A real-time 4d world sim- ulator via spatiotemporal autoregressive modeling.arXiv preprint arXiv:2604.07209, 2026. 3
Pith/arXiv arXiv 2026
-
[44]
Advancing open-source world models.arXiv preprint arXiv:2601.20540, 2026
Robbyant Team, Zelin Gao, Qiuyu Wang, Yanhong Zeng, Jiapeng Zhu, Ka Leong Cheng, Yixuan Li, Hanlin Wang, Yinghao Xu, Shuailei Ma, et al. Advancing open-source world models.arXiv preprint arXiv:2601.20540, 2026. 2, 3
Pith/arXiv arXiv 2026
-
[45]
Diffusion models are real-time game engines
Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter. Diffusion models are real-time game engines. arXiv preprint arXiv:2408.14837, 2024. 3
Pith/arXiv arXiv 2024
-
[46]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianx- iao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 6
Pith/arXiv arXiv 2025
-
[47]
3d reconstruction with spatial memory
Hengyi Wang and Lourdes Agapito. 3d reconstruction with spatial memory. In2025 International Conference on 3D Vision (3DV), pages 78–89. IEEE, 2025. 2
2025
-
[48]
Vggt: Vi- sual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Vi- sual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 5, 8
2025
-
[49]
Continuous 3d per- ception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d per- ception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510–10522, 2025
2025
-
[50]
Dust3r: Geometric 3d vi- sion made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vi- sion made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697– 20709, 2024. 2
2024
-
[51]
Motionctrl: A unified and flexible motion controller for 11 video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for 11 video generation. InACM SIGGRAPH 2024 Conference Pa- pers, pages 1–11, 2024. 3
2024
-
[52]
Haoyu Wu, Diankun Wu, Tianyu He, Junliang Guo, Yang Ye, Yueqi Duan, and Jiang Bian. Geometry forcing: Marrying video diffusion and 3d representation for consistent world modeling.arXiv preprint arXiv:2507.07982, 2025. 2, 3, 5, 8
Pith/arXiv arXiv 2025
-
[53]
Multi- world: Scalable multi-agent multi-view video world models
Haoyu Wu, Jiwen Yu, Yingtian Zou, and Xihui Liu. Multi- world: Scalable multi-agent multi-view video world models. arXiv preprint arXiv:2604.18564, 2026. 3
Pith/arXiv arXiv 2026
-
[54]
Ruiqi Wu, Xuanhua He, Meng Cheng, Tianyu Yang, Yong Zhang, Zhuoliang Kang, Xunliang Cai, Xiaoming Wei, Chunle Guo, Chongyi Li, et al. Infinite-world: Scaling inter- active world models to 1000-frame horizons via pose-free hi- erarchical memory.arXiv preprint arXiv:2602.02393, 2026. 2, 3
arXiv 2026
-
[55]
Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284,
Tong Wu, Shuai Yang, Ryan Po, Yinghao Xu, Ziwei Liu, Dahua Lin, and Gordon Wetzstein. Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284,
-
[56]
Xiaofei Wu, Guozhen Zhang, Zhiyong Xu, Yuan Zhou, Qinglin Lu, and Xuming He. Pack and force your memory: Long-form and consistent video generation.arXiv preprint arXiv:2510.01784, 2025. 2, 3
arXiv 2025
-
[57]
Xunzhi Xiang and Qi Fan. Make it efficient: Dynamic sparse attention for autoregressive image generation.arXiv preprint arXiv:2506.18226, 2025. 3
arXiv 2025
-
[58]
Xunzhi Xiang, Yabo Chen, Guiyu Zhang, Zhongyu Wang, Zhe Gao, Quanming Xiang, Gonghu Shang, Junqi Liu, Haibin Huang, Yang Gao, et al. Macro-from-micro planning for high-quality and parallelized autoregressive long video generation.arXiv preprint arXiv:2508.03334, 2025
arXiv 2025
-
[59]
Xunzhi Xiang, Zixuan Duan, Guiyu Zhang, Haiyu Zhang, Zhe Gao, Junta Wu, Shaofeng Zhang, Tengfei Wang, Qi Fan, and Chunchao Guo. Pathwise test-time correction for autoregressive long video generation.arXiv preprint arXiv:2602.05871, 2026. 3
arXiv 2026
-
[60]
Worldmem: Long- term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025
Zeqi Xiao, Yushi Lan, Yifan Zhou, Wenqi Ouyang, Shuai Yang, Yanhong Zeng, and Xingang Pan. Worldmem: Long- term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025. 2, 3
arXiv 2025
-
[61]
Mingyang Xie, Numair Khan, Tianfu Wang, Naina Dhin- gra, Seonghyeon Nam, Haitao Yang, Zhuo Hui, Christo- pher Metzler, Andrea Vedaldi, Hamed Pirsiavash, et al. Lavr: Scene latent conditioned generative video trajectory re-rendering using large 4d reconstruction models.arXiv preprint arXiv:2601.14674, 2026. 2, 3
arXiv 2026
-
[62]
Ucm: Unifying camera control and memory with time-aware positional encoding warping for world models
Tianxing Xu, Zixuan Wang, Guangyuan Wang, Li Hu, Zhongyi Zhang, Peng Zhang, Bang Zhang, and Song-Hai Zhang. Ucm: Unifying camera control and memory with time-aware positional encoding warping for world models. arXiv preprint arXiv:2602.22960, 2026. 2, 3
arXiv 2026
-
[63]
Yixuan Ye, Xuanyu Lu, Yuxin Jiang, Yuchao Gu, Rui Zhao, Qiwei Liang, Jiachun Pan, Fengda Zhang, Weijia Wu, and Alex Jinpeng Wang. Mind: Benchmarking memory consis- tency and action control in world models.arXiv preprint arXiv:2602.08025, 2026. 6
arXiv 2026
-
[64]
Context as memory: Scene-consistent interactive long video generation with memory retrieval
Jiwen Yu, Jianhong Bai, Yiran Qin, Quande Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Context as memory: Scene-consistent interactive long video generation with memory retrieval. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–11, 2025. 2, 3, 4, 6
2025
-
[65]
Gamefactory: Creating new games with gen- erative interactive videos
Jiwen Yu, Yiran Qin, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Gamefactory: Creating new games with gen- erative interactive videos. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11590– 11599, 2025. 3
2025
-
[66]
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffu- sion transformers is easier than you think.arXiv preprint arXiv:2410.06940, 2024. 2
Pith/arXiv arXiv 2024
-
[67]
Wei Yu, Runjia Qian, Yumeng Li, Liquan Wang, Songheng Yin, Dennis Anthony, Yang Ye, Yidi Li, Weiwei Wan, Animesh Garg, et al. Mosaicmem: Hybrid spatial mem- ory for controllable video world models.arXiv preprint arXiv:2603.17117, 2026. 3
arXiv 2026
-
[68]
Yifei Yu, Xiaoshan Wu, Xinting Hu, Tao Hu, Yangtian Sun, Xiaoyang Lyu, Bo Wang, Lin Ma, Yuewen Ma, Zhongrui Wang, et al. Videossm: Autoregressive long video gen- eration with hybrid state-space memory.arXiv preprint arXiv:2512.04519, 2025. 3, 6
arXiv 2025
-
[69]
Packing input frame context in next-frame prediction models for video genera- tion.arXiv e-prints, pages arXiv–2504, 2025
Lvmin Zhang and Maneesh Agrawala. Packing input frame context in next-frame prediction models for video genera- tion.arXiv e-prints, pages arXiv–2504, 2025. 6
2025
-
[70]
World-consistent video diffusion with explicit 3d modeling
Qihang Zhang, Shuangfei Zhai, Miguel Angel Bautista Mar- tin, Kevin Miao, Alexander Toshev, Joshua Susskind, and Jiatao Gu. World-consistent video diffusion with explicit 3d modeling. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 21685–21695, 2025. 2, 3
2025
-
[71]
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burch- fiel, Paarth Shah, and Abhishek Gupta. Unified world mod- els: Coupling video and action diffusion for pretraining on large robotic datasets.arXiv preprint arXiv:2504.02792,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.