Active Exploring like a Pigeon: Reinforcing Spatial Reasoning via Agentic Vision-Language Models
Pith reviewed 2026-06-28 15:14 UTC · model grok-4.3
The pith
Vision-language models using a dynamic cognitive map and spatial assertion codes reach 80.5 percent accuracy on the MindCube benchmark by verifying intermediate reasoning steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
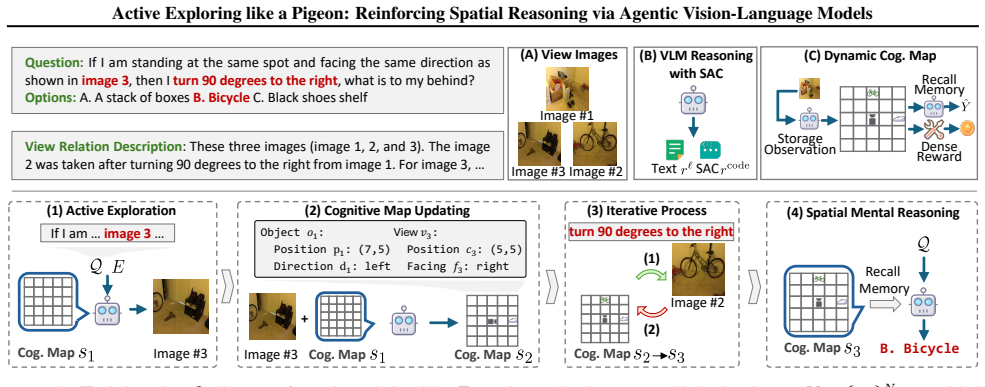
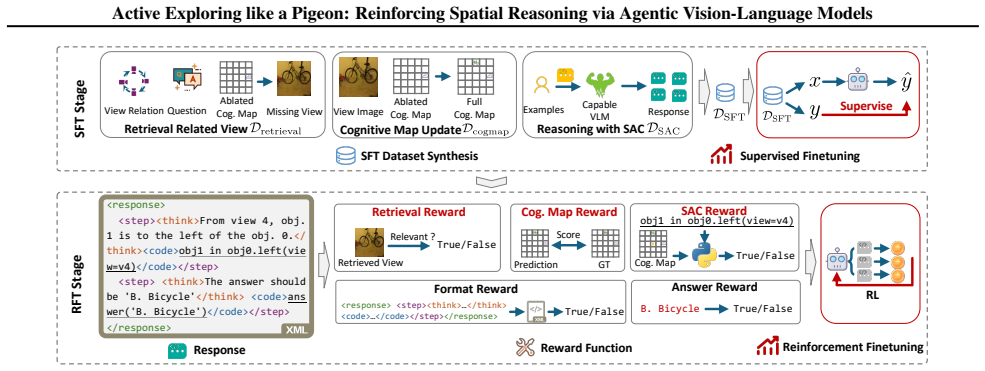
A dynamic cognitive map that parameterizes scene layout by object positions and orientations, together with Spatial Assertion Codes expressed as Python expressions, verifies intermediate spatial reasoning steps and supplies dense reward signals during supervised and reinforcement finetuning, enabling state-of-the-art performance on spatial reasoning tasks.
What carries the argument
The dynamic cognitive map paired with Spatial Assertion Codes (SAC), which together maintain persistent scene memory and generate verifiable assertions for dense rewards.
If this is right
- The model outperforms the previous best method by 29.5 accuracy points on the Rotation subset.
- Dense rewards from step verification improve results on complex multi-step spatial tasks where sparse rewards previously limited progress.
- Treating VLMs as active agents rather than passive observers enables better handling of real-world spatial queries that require exploration.
- The combination of persistent memory and programmatic assertions scales to new observations without resetting the scene representation.
Where Pith is reading between the lines
- The same verification mechanism could be tested on embodied navigation benchmarks that require physical movement rather than static image reasoning.
- If SAC expressions generalize beyond spatial relations, similar assertion-based rewards might apply to other VLM reasoning domains such as temporal or causal inference.
- Open-sourcing the code allows direct measurement of how much the cognitive map contributes when the model faces novel object configurations not seen in MindCube.
Load-bearing premise
The dynamic cognitive map and SAC together produce reliable verification of intermediate steps that actually supply effective dense reward signals during finetuning.
What would settle it
Removing either the dynamic cognitive map or the SAC component and observing no drop in accuracy on the Rotation subset of MindCube would falsify the claim that these elements drive the reported performance gains.
Figures


read the original abstract
Enabling Vision-Language Models (VLMs) to perform spatial reasoning remains challenging. Existing approaches treat VLMs as passive observers, which is difficult for real-world applications. Moreover, reinforcement learning methods rely on sparse rewards, limiting their effectiveness for complex reasoning tasks. Inspired by pigeons' building and exploiting cognitive maps for navigation, we propose a novel agentic pipeline for spatial reasoning. First, we introduce a new \emph{dynamic cognitive map} parameterizing scene layout as object positions and orientations, serving as persistent memory for new observations. Second, we propose a novel \emph{Spatial Assertion Codes (SAC)}, Python expressions programmatically describing spatial relationships. By collaborating with the dynamic cognitive map, SAC enables verification of intermediate reasoning steps, providing dense reward signals. We optimize the model via supervised and reinforcement finetuning. Experiments on the MindCube benchmark demonstrate state-of-the-art performance with \emph{80.5\%} overall accuracy, outperforming the best current method by \emph{29.5} accuracy points (a relative improvement of \emph{53.2\%}) on the challenging \textsc{Rotation} subset. Our code and data are open-sourced at https://github.com/dw-dengwei/active-spatial-reasoning.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an agentic pipeline for spatial reasoning in VLMs, inspired by pigeons' cognitive maps. It introduces a dynamic cognitive map to represent scene layouts (object positions and orientations) as persistent memory and Spatial Assertion Codes (SAC) as Python expressions for spatial relationships. These enable verification of intermediate reasoning steps to generate dense rewards during supervised and reinforcement finetuning (SAC + dynamic map collaboration). On the MindCube benchmark, the approach achieves SOTA performance of 80.5% overall accuracy, with a 29.5-point (53.2% relative) gain on the challenging Rotation subset over prior methods. Code and data are open-sourced.
Significance. If the reported gains are shown to stem from the SAC-derived dense rewards and dynamic cognitive map enabling verifiable intermediate steps, the work would be significant for advancing RL-based finetuning of VLMs on complex spatial tasks, addressing the limitations of sparse rewards and passive observation. The open-sourcing strengthens reproducibility.
major comments (2)
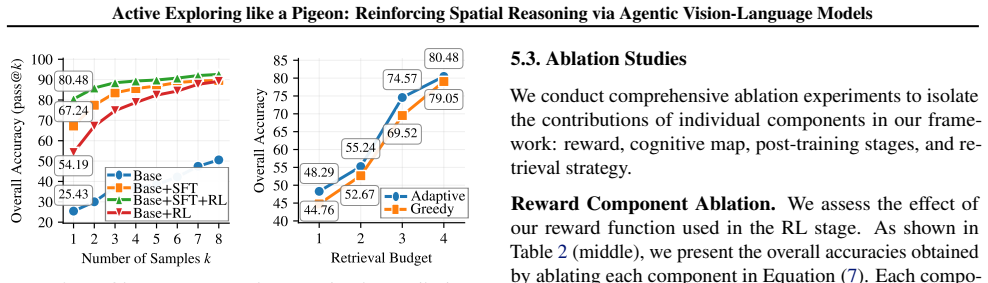
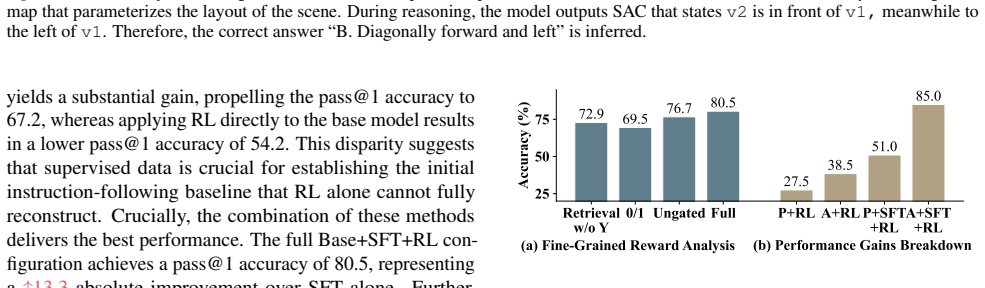
- [Experiments] Experiments section: The central claim requires that the dynamic cognitive map + SAC pipeline supplies verifiable intermediate steps yielding effective dense rewards, producing the 80.5% overall / 29.5-point Rotation gain. No component ablations, reward histograms, step-verification accuracy metrics, or error bars are reported to show that removing SAC collapses performance or that SAC expressions succeed at scale; the margin could arise from base-model differences, data curation, or prompt engineering instead.
- [Method] Method section: The description of how SAC Python expressions programmatically describe spatial relationships and collaborate with the dynamic cognitive map for verification is high-level only. Without concrete examples of SAC expressions, verification logic, or how they integrate into the RL reward function, it is impossible to assess whether they actually provide the claimed dense signals or are load-bearing for the finetuning pipeline.
minor comments (1)
- [Abstract] The abstract and method overview would benefit from a brief table or figure summarizing the MindCube dataset splits and baseline methods for context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where additional evidence and detail would strengthen the paper. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The central claim requires that the dynamic cognitive map + SAC pipeline supplies verifiable intermediate steps yielding effective dense rewards, producing the 80.5% overall / 29.5-point Rotation gain. No component ablations, reward histograms, step-verification accuracy metrics, or error bars are reported to show that removing SAC collapses performance or that SAC expressions succeed at scale; the margin could arise from base-model differences, data curation, or prompt engineering instead.
Authors: We agree that the manuscript would benefit from explicit ablations and supporting metrics to isolate the contributions of the dynamic cognitive map and SAC. In the revised version we will add component ablations (full pipeline vs. without SAC, without dynamic map, and without both), reward histograms comparing dense vs. sparse settings, step-verification accuracy on held-out examples, and error bars from multiple random seeds. These additions will directly test whether performance collapses without the proposed mechanisms. revision: yes
-
Referee: [Method] Method section: The description of how SAC Python expressions programmatically describe spatial relationships and collaborate with the dynamic cognitive map for verification is high-level only. Without concrete examples of SAC expressions, verification logic, or how they integrate into the RL reward function, it is impossible to assess whether they actually provide the claimed dense signals or are load-bearing for the finetuning pipeline.
Authors: We acknowledge the Method section remains at a high level. The revised manuscript will include (1) multiple concrete SAC Python expression examples for common spatial relations (e.g., relative position, orientation, containment), (2) pseudocode for the verification procedure that queries the dynamic cognitive map, and (3) the exact mapping from verification outcomes (true/false/unknown) to the per-step dense reward term used in both supervised and RL stages. revision: yes
Circularity Check
No circularity; novel components introduced without reducing claims to fitted inputs or self-citations
full rationale
The paper presents a dynamic cognitive map and Spatial Assertion Codes (SAC) as newly introduced mechanisms that collaborate to verify intermediate spatial reasoning steps and supply dense rewards during supervised and reinforcement finetuning of VLMs. No equations, fitted parameters, or self-citations appear in the provided text that would make the claimed 80.5% accuracy or 29.5-point Rotation gain equivalent to the inputs by construction. The derivation relies on standard RL/VLM finetuning pipelines augmented by these independent components, with benchmark results treated as empirical outcomes rather than tautological predictions. This is the most common honest finding for papers that add new architectural elements without load-bearing self-referential reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard VLM finetuning and RL assumptions hold without modification.
invented entities (2)
-
dynamic cognitive map
no independent evidence
-
Spatial Assertion Codes (SAC)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Claude 3.5 sonnet
Anthropic. Claude 3.5 sonnet. Blog, 10 2024. Accessed: November 22, 2024
2024
-
[2]
Bai, S., Chen, K., Liu, X., et al. Qwen2.5-vl technical report. arXiv preprint: 2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Bingman, V., Jechura, T., and Kahn, M. C. Behavioral and neural mechanisms of homing and migration in birds. Animal Spatial Cognition: Comparative, Neural, and Computational Approaches,[On-line]. Available: pigeon.psy.tufts.edu/asc/Bingman/Default.htm, 2006
2006
-
[4]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Chen, B., Xu, Z., Kirmani, S., et al. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In IEEE Conf. Comput. Vis. Pattern Recog., pp.\ 14455--14465, June 2024 a
2024
-
[5]
Evaluating Large Language Models Trained on Code
Chen, M., Tworek, J., Jun, H., et al. Evaluating large language models trained on code. arXiv preprint: 2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Chen, Z., Wu, J., Wang, W., et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In IEEE Conf. Comput. Vis. Pattern Recog., June 2024 b
2024
-
[7]
Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? In Adv
Chen, Z., Lu, R., Zhao, A., et al. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? In Adv. Neural Inform. Process. Syst., volume 38, pp.\ 57654--57689, 2025
2025
-
[8]
Think with 3d: Geometric imagination grounded spatial reasoning from limited views
Chen, Z., Zhang, M., Yu, X., et al. Think with 3d: Geometric imagination grounded spatial reasoning from limited views. In IEEE Conf. Comput. Vis. Pattern Recog., June 2026
2026
-
[9]
Global-local tree search in vlms for 3d indoor scene generation
Deng, W., Qi, M., and Ma, H. Global-local tree search in vlms for 3d indoor scene generation. In IEEE Conf. Comput. Vis. Pattern Recog., pp.\ 8975--8984, June 2025
2025
-
[10]
Scene-llm: Extending language model for 3d visual reasoning
Fu, R., Liu, J., Chen, X., et al. Scene-llm: Extending language model for 3d visual reasoning. In IEEE Win. Conf. on App. of Comput. Vis., 2025
2025
-
[11]
A survey on llm-as-a-judge
Gu, J., Jiang, X., Shi, Z., et al. A survey on llm-as-a-judge. The Innovation, pp.\ 101253, 2026. ISSN 2666-6758
2026
-
[12]
L., Wolfer, D
Lipp, H.-P., Vyssotski, A. L., Wolfer, D. P., et al. Pigeon homing along highways and exits. Current Biology, 14 0 (14): 0 1239--1249, 2004. ISSN 0960-9822
2004
-
[13]
Sgformer: Semantic graph transformer for point cloud-based 3d scene graph generation
Lv, C., Qi, M., Li, X., et al. Sgformer: Semantic graph transformer for point cloud-based 3d scene graph generation. AAAI, 38 0 (5): 0 4035--4043, 2024
2024
-
[14]
T2sg: Traffic topology scene graph for topology reasoning in autonomous driving
Lv, C., Qi, M., Liu, L., et al. T2sg: Traffic topology scene graph for topology reasoning in autonomous driving. In IEEE Conf. Comput. Vis. Pattern Recog., pp.\ 17197--17206, June 2025
2025
-
[16]
OpenAI. Gpt-4o system card. arXiv preprint: 2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
SpaceR: Reinforcing MLLMs in Video Spatial Reasoning
Ouyang, K., Liu, Y., Wu, H., et al. Spacer: Reinforcing mllms in video spatial reasoning. arXiv preprint: 2504.01805, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Training language models to follow instructions with human feedback
Ouyang, L., Wu, J., Jiang, X., et al. Training language models to follow instructions with human feedback. In Adv. Neural Inform. Process. Syst., volume 35, 2022
2022
-
[19]
Open x-embodiment: Robotic learning datasets and rt-x models : Open x-embodiment collaboration0
O’Neill, A., Rehman, A., Maddukuri, A., et al. Open x-embodiment: Robotic learning datasets and rt-x models : Open x-embodiment collaboration0. In IEEE Int. Conf. on Robot. and Auto., pp.\ 6892--6903, 2024
2024
-
[20]
Skywork r1v: Pioneering multimodal reasoning with chain-of-thought
Peng, Y., Wang, P., Wang, X., et al. Skywork r1v: Pioneering multimodal reasoning with chain-of-thought. arXiv preprint: 2504.05599, 2025
-
[21]
Action quality assessment via hierarchical pose-guided multi-stage contrastive regression
Qi, M., Ye, H., Peng, J., et al. Action quality assessment via hierarchical pose-guided multi-stage contrastive regression. IEEE Trans. Image Process., 34: 0 6461--6474, 2025
2025
-
[22]
Robust disentangled counterfactual learning for physical audiovisual commonsense reasoning
Qi, M., Lv, C., and Ma, H. Robust disentangled counterfactual learning for physical audiovisual commonsense reasoning. IEEE Trans. Pattern Anal. and Mach. Intell., 48 0 (3): 0 2514--2527, 2026 a
2026
-
[23]
Dc-sam: In-context segment anything in images and videos via dual consistency
Qi, M., Zhu, P., Li, X., et al. Dc-sam: In-context segment anything in images and videos via dual consistency. IEEE Trans. Pattern Anal. and Mach. Intell., 48 0 (4): 0 4642--4656, 2026 b
2026
-
[24]
Direct preference optimization: Your language model is secretly a reward model
Rafailov, R., Sharma, A., Mitchell, E., et al. Direct preference optimization: Your language model is secretly a reward model. In Adv. Neural Inform. Process. Syst., 2023
2023
-
[25]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., et al. Proximal policy optimization algorithms. arXiv preprint: 1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint: 2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Hybridflow: A flexible and efficient rlhf framework
Sheng, G., Zhang, C., Ye, Z., et al. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, EuroSys '25, pp.\ 1279–1297, New York, NY, USA, 2025. Association for Computing Machinery. ISBN 9798400711961
2025
-
[28]
V., Lee, J., Xu, K., et al
Snell, C. V., Lee, J., Xu, K., et al. Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning. In Int. Conf. Learn. Represent., 2025
2025
-
[29]
Reason-rft: Reinforcement fine-tuning for visual reasoning of vision language models
Tan, H., Ji, Y., Hao, X., et al. Reason-rft: Reinforcement fine-tuning for visual reasoning of vision language models. In Belgrave, D., Zhang, C., Lin, H., et al. (eds.), Adv. Neural Inform. Process. Syst., volume 38, pp.\ 5772--5822. Curran Associates, Inc., 2025
2025
-
[30]
Vggt: Visual geometry grounded transformer
Wang, J., Chen, M., Karaev, N., et al. Vggt: Visual geometry grounded transformer. In IEEE Conf. Comput. Vis. Pattern Recog., June 2025
2025
-
[31]
Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai
Wang, T., Mao, X., Zhu, C., et al. Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai. In IEEE Conf. Comput. Vis. Pattern Recog., pp.\ 19757--19767, June 2024
2024
-
[32]
Chain-of-thought prompting elicits reasoning in large language models
Wei, J., Wang, X., Schuurmans, D., et al. Chain-of-thought prompting elicits reasoning in large language models. In Adv. Neural Inform. Process. Syst., volume 35, pp.\ 24824--24837, 2022
2022
-
[33]
Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence
Wu, D., Liu, F., Hung, Y.-H., et al. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence. In Belgrave, D., Zhang, C., Lin, H., et al. (eds.), Adv. Neural Inform. Process. Syst., volume 38, pp.\ 13569--13597. Curran Associates, Inc., 2025 a
2025
-
[34]
Reinforcing spatial reasoning in vision-language models with interwoven thinking and visual drawing
Wu, J., Guan, J., Feng, K., et al. Reinforcing spatial reasoning in vision-language models with interwoven thinking and visual drawing. In Adv. Neural Inform. Process. Syst., volume 38, pp.\ 143297--143330, 2025 b
2025
-
[35]
R., He, Z., et al
Xia, F., Zamir, A. R., He, Z., et al. Gibson env: Real-world perception for embodied agents. In IEEE Conf. Comput. Vis. Pattern Recog., June 2018
2018
-
[36]
W., et al
Yang, J., Yang, S., Gupta, A. W., et al. Thinking in space: How multimodal large language models see, remember, and recall spaces. In IEEE Conf. Comput. Vis. Pattern Recog., pp.\ 10632--10643, 2025 a
2025
-
[37]
Embodiedbench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents
Yang, R., Chen, H., Zhang, J., et al. Embodiedbench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents. In Int. Conf. Mach. Learn., volume 267, pp.\ 70576--70631, 13--19 Jul 2025 b
2025
-
[38]
R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization
Yang, Y., He, X., Pan, H., et al. R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization. In Int. Conf. Comput. Vis., pp.\ 2376--2385, October 2025 c
2025
-
[39]
Tree of thoughts: Deliberate problem solving with large language models
Yao, S., Yu, D., Zhao, J., et al. Tree of thoughts: Deliberate problem solving with large language models. In Adv. Neural Inform. Process. Syst., volume 36, pp.\ 11809--11822, 2023
2023
-
[40]
Spatial Mental Modeling from Limited Views
Yin, B., Wang, Q., Zhang, P., et al. Spatial Mental Modeling from Limited Views . In Structural Priors for Vision Workshop at ICCV '25 , 2025
2025
-
[41]
Thinking in 360°: Humanoid visual search in the wild
Yu, H., Han, Y., Zhang, X., et al. Thinking in 360°: Humanoid visual search in the wild. In IEEE Conf. Comput. Vis. Pattern Recog., June 2026
2026
-
[42]
Multimodal chain-of-thought reasoning in language models
Zhang, Z., Zhang, A., Li, M., et al. Multimodal chain-of-thought reasoning in language models. Transactions on Machine Learning Research, 2024. ISSN 2835-8856
2024
-
[44]
L lama F actory: Unified efficient fine-tuning of 100+ language models
Zheng, Y., Zhang, R., Zhang, J., et al. L lama F actory: Unified efficient fine-tuning of 100+ language models. In Annual Meeting of the Ass. for Comput. Ling., pp.\ 400--410, 2024
2024
-
[45]
Llava-3d: A simple yet effective pathway to empowering lmms with 3d capabilities
Zhu, C., Wang, T., Zhang, W., et al. Llava-3d: A simple yet effective pathway to empowering lmms with 3d capabilities. In Int. Conf. Comput. Vis., pp.\ 4295--4305, October 2025
2025
-
[46]
Yin, Baiqiao and Wang, Qineng and Zhang, Pingyue and Zhang, Jianshu and Wang, Kangrui and Wang, Zihan and Zhang, Jieyu and Chandrasegaran, Keshigeyan and Liu, Han and Krishna, Ranjay and Xie, Saining and Li, Manling and Wu, Jiajun and Fei-Fei, Li , booktitle =. Spatial. 2025 , organization =
2025
-
[47]
2025 , pages =
Zhu, Chenming and Wang, Tai and Zhang, Wenwei and Pang, Jiangmiao and Liu, Xihui , title =. 2025 , pages =
2025
-
[48]
2025 , volume=
Fu, Rao and Liu, Jingyu and Chen, Xilun and Nie, Yixin and Xiong, Wenhan , booktitle=WACV, title=. 2025 , volume=
2025
-
[49]
Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence , volume =
Wu, Diankun and Liu, Fangfu and Hung, Yi-Hsin and Duan, Yueqi , booktitle = NIPS, editor =. Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence , volume =
-
[50]
Wang, Jianyuan and Chen, Minghao and Karaev, Nikita and Vedaldi, Andrea and Rupprecht, Christian and Novotny, David , title =
-
[51]
2025 , journal=
SpaceR: Reinforcing MLLMs in Video Spatial Reasoning , author=. 2025 , journal=
2025
-
[52]
Reason-RFT: Reinforcement Fine-Tuning for Visual Reasoning of Vision Language Models , volume =
Tan, Huajie and Ji, Yuheng and Hao, Xiaoshuai and Chen, Xiansheng and Wang, Pengwei and Wang, Zhongyuan and Zhang, Shanghang , booktitle = NIPS, editor =. Reason-RFT: Reinforcement Fine-Tuning for Visual Reasoning of Vision Language Models , volume =
-
[53]
2024 , journal=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , journal=
2024
-
[54]
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul F and Leike, Jan and Lowe,...
-
[55]
2017 , journal=
Proximal Policy Optimization Algorithms , author=. 2017 , journal=
2017
-
[56]
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Manning, Christopher D and Ermon, Stefano and Finn, Chelsea , booktitle = NIPS, title =
-
[57]
2025 , journal=
Qwen2.5-VL Technical Report , author=. 2025 , journal=
2025
-
[58]
Bo Li and Yuanhan Zhang and Dong Guo and Renrui Zhang and Feng Li and Hao Zhang and Kaichen Zhang and Peiyuan Zhang and Yanwei Li and Ziwei Liu and Chunyuan Li , journal=TMLR, issn=
-
[59]
Yuanhan Zhang and Jinming Wu and Wei Li and Bo Li and Zejun MA and Ziwei Liu and Chunyuan Li , journal=TMLR, issn=
-
[60]
Long Context Transfer from Language to Vision , author=
-
[61]
Jiabo Ye and Haiyang Xu and Haowei Liu and Anwen Hu and Ming Yan and Qi Qian and Ji Zhang and Fei Huang and Jingren Zhou , booktitle=ICLR, year=. m
-
[62]
Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and Li, Bin and Luo, Ping and Lu, Tong and Qiao, Yu and Dai, Jifeng , title =
-
[63]
Workshop on Responsibly Building the Next Generation of Multimodal Foundational Models , year=
Building and better understanding vision-language models: insights and future directions , author=. Workshop on Responsibly Building the Next Generation of Multimodal Foundational Models , year=
-
[64]
2024 , journal=
DeepSeek-VL: Towards Real-World Vision-Language Understanding , author=. 2024 , journal=
2024
-
[65]
2025 , journal=
Gemma 3 Technical Report , author=. 2025 , journal=
2025
-
[66]
Mantis: Interleaved Multi-Image Instruction Tuning , author=
-
[67]
2024 , journal=
GPT-4o System Card , author=. 2024 , journal=
2024
-
[68]
2024 , month =
Anthropic , title =. 2024 , month =
2024
-
[69]
Ji, Yuheng and Tan, Huajie and Shi, Jiayu and Hao, Xiaoshuai and Zhang, Yuan and Zhang, Hengyuan and Wang, Pengwei and Zhao, Mengdi and Mu, Yao and An, Pengju and Xue, Xinda and Su, Qinghang and Lyu, Huaihai and Zheng, Xiaolong and Liu, Jiaming and Wang, Zhongyuan and Zhang, Shanghang , title =
-
[70]
2024 , pages =
Chen, Boyuan and Xu, Zhuo and Kirmani, Sean and Ichter, Brain and Sadigh, Dorsa and Guibas, Leonidas and Xia, Fei , title =. 2024 , pages =
2024
-
[71]
2026 , month =
Think with 3D: Geometric Imagination Grounded Spatial Reasoning from Limited Views , author=. 2026 , month =
2026
-
[72]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model , volume =
Hu, Jingcheng and Zhang, Yinmin and Han, Qi and Jiang, Daxin and Zhang, Xiangyu and Shum, Heung-Yeung , booktitle = NIPS, editor =. Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model , volume =
-
[73]
Charlie Victor Snell and Jaehoon Lee and Kelvin Xu and Aviral Kumar , booktitle=ICLR, year=. Scaling
-
[74]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? , volume =
Chen, Zhiqi and Lu, Rui and Zhao, Andrew and Wang, Zhaokai and Yue, Yang and Song, Shiji and Huang, Gao , booktitle = NIPS, pages =. Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? , volume =
-
[75]
Reinforcing Spatial Reasoning in Vision-Language Models with Interwoven Thinking and Visual Drawing , volume =
Wu, Junfei and Guan, Jian and Feng, Kaituo and Liu, Qiang and Wu, Shu and Wang, Liang and Wu, Wei and Tan, Tieniu , booktitle = NIPS, pages =. Reinforcing Spatial Reasoning in Vision-Language Models with Interwoven Thinking and Visual Drawing , volume =
-
[76]
2004 , doi =
Dora Biro and Jessica Meade and Tim Guilford , title =. 2004 , doi =
2004
-
[77]
and Wolfer, David P
Lipp, Hans-Peter and Vyssotski, Alexei L. and Wolfer, David P. and Renaudineau, Sophie and Savini, Maria and Tr. Pigeon Homing along Highways and Exits , journal=. 2004 , volume=
2004
-
[78]
2013 , month=
The internal compass of the pigeon , journal=. 2013 , month=
2013
-
[79]
2024 , pages =
Wang, Tai and Mao, Xiaohan and Zhu, Chenming and Xu, Runsen and Lyu, Ruiyuan and Li, Peisen and Chen, Xiao and Zhang, Wenwei and Chen, Kai and Xue, Tianfan and Liu, Xihui and Lu, Cewu and Lin, Dahua and Pang, Jiangmiao , title =. 2024 , pages =
2024
-
[80]
and He, Zhiyang and Sax, Alexander and Malik, Jitendra and Savarese, Silvio , title =
Xia, Fei and Zamir, Amir R. and He, Zhiyang and Sax, Alexander and Malik, Jitendra and Savarese, Silvio , title =
-
[81]
2025 , pages =
Yan, Tianyi and Wu, Dongming and Han, Wencheng and Jiang, Junpeng and Zhou, Xia and Zhan, Kun and Xu, Cheng-zhong and Shen, Jianbing , title =. 2025 , pages =
2025
-
[82]
arXiv preprint:2601.05172 , year=
CoV: Chain-of-View Prompting for Spatial Reasoning , author=. arXiv preprint:2601.05172 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.