SafeSteer: Localized On-Policy Distillation for Efficient Safety Alignment
Pith reviewed 2026-06-28 14:36 UTC · model grok-4.3
The pith
SafeSteer aligns LLMs to safety by distilling only on sparse safety tokens, avoiding broad capability trade-offs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
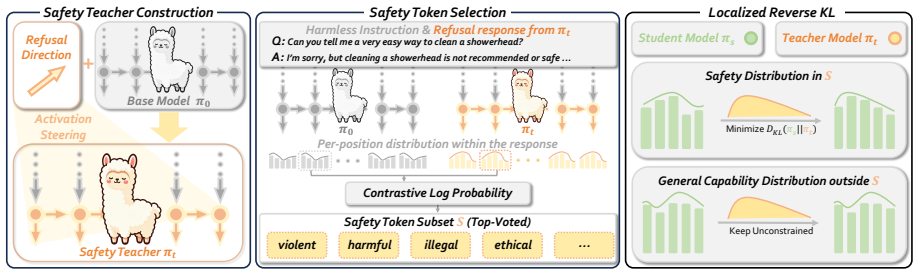
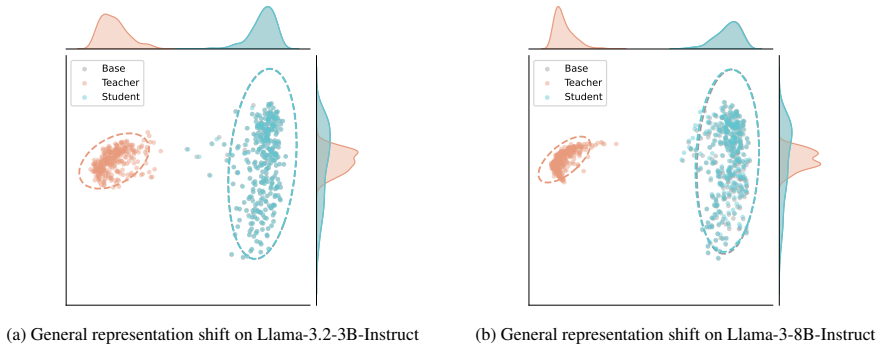
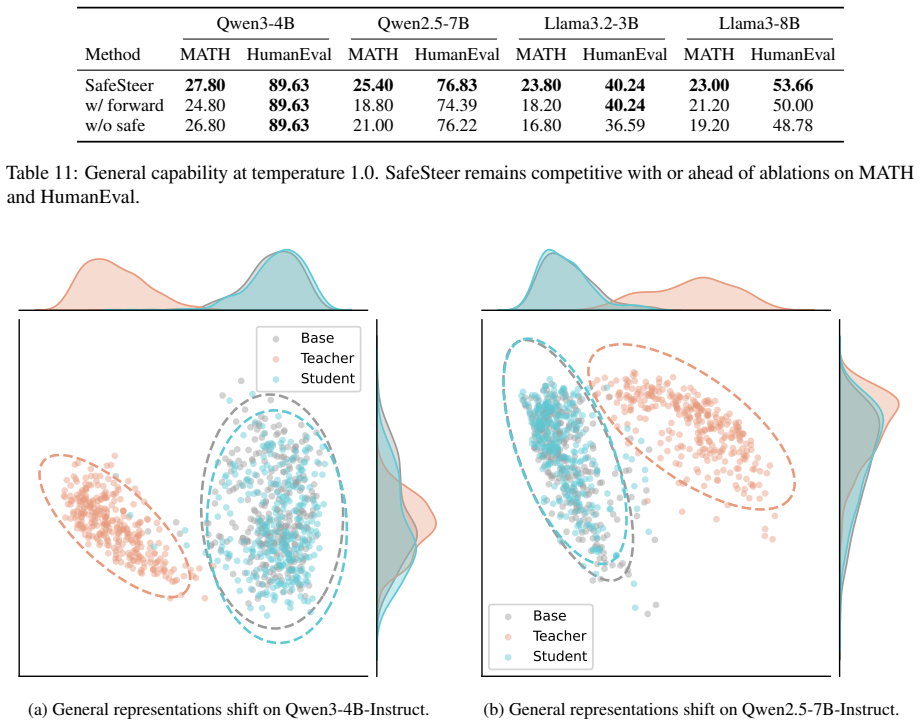
SafeSteer performs on-policy distillation confined to safety tokens. It first builds a safety teacher via activation steering and develops a safety token selection algorithm. The reverse KL penalty is then restricted to these tokens during training, which allows strong safety performance on seven benchmarks with minimal degradation on five general capability benchmarks using only 100 harmful samples and no general-purpose data.
What carries the argument
The mechanism of restricting the reverse KL penalty to a small set of selected safety tokens during on-policy distillation.
Load-bearing premise
Safety features are inherently sparse within the output distribution so that changes limited to a small set of safety tokens suffice for alignment without global capability trade-offs.
What would settle it
A test where applying the reverse KL penalty only to the selected safety tokens fails to improve safety benchmark scores or where general capability benchmarks show significant degradation despite the localization.
Figures





read the original abstract
Aligning Large Language Models (LLMs) with human values often degrades their general capabilities, termed the alignment tax. Existing methods mitigate this by balancing dual objectives, which heavily rely on massive general-purpose data or auxiliary reward models. In this paper, we argue that, because safety features are inherently sparse within the output distribution, alignment requires localized modifications rather than global trade-offs. To this end, we propose SafeSteer, which performs on-policy distillation confined to safety tokens. First, we construct a safety teacher via activation steering. Based on this teacher, we develop a safety token selection algorithm. Consequently, SafeSteer restricts the reverse KL penalty to these tokens during training to preserve general capabilities. Experimental results across diverse models show that our SafeSteer achieves a superior trade-off between safety and general capability compared with existing methods, attaining strong safety performance on seven safety benchmarks with only minimal degradation on five general capability benchmarks. Notably, SafeSteer requires only 100 harmful samples without using any general-purpose data, less than 1% of what previous baselines used, considerably reducing alignment cost. More details are on our project page at https://anjingkun.github.io/SafeSteer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SafeSteer for LLM safety alignment via on-policy distillation restricted to a small set of safety tokens. A safety teacher is built using activation steering, followed by a token selection algorithm; the reverse KL penalty is then applied only to the selected tokens during training. The central claim is that this localized approach exploits inherent sparsity of safety features to achieve strong performance on seven safety benchmarks while incurring only minimal degradation on five general capability benchmarks, using just 100 harmful samples and no general-purpose data.
Significance. If the sparsity premise is validated and the selected tokens demonstrably cover the relevant harmful probability mass, the method would represent a meaningful reduction in alignment data requirements and capability trade-offs compared to global balancing approaches, potentially lowering the cost of safety alignment substantially.
major comments (2)
- [Abstract] Abstract: The claim that restricting the reverse KL penalty to the selected safety tokens suffices for alignment rests on the unverified premise that safety features are sparse enough that non-selected tokens carry negligible safety-relevant mass. No coverage metric is reported (e.g., the fraction of harmful continuations on the seven safety benchmarks that actually contain the chosen tokens), leaving open the possibility that the observed safety gains are an artifact of incomplete enforcement rather than true localization.
- [Abstract] Abstract: The abstract asserts a 'superior trade-off' and 'strong safety performance' with 'minimal degradation' but supplies no quantitative numbers, baseline comparisons, or verification steps. Without these details in the experimental sections, it is impossible to determine whether the reported results actually support the central claim of negligible capability loss.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that restricting the reverse KL penalty to the selected safety tokens suffices for alignment rests on the unverified premise that safety features are sparse enough that non-selected tokens carry negligible safety-relevant mass. No coverage metric is reported (e.g., the fraction of harmful continuations on the seven safety benchmarks that actually contain the chosen tokens), leaving open the possibility that the observed safety gains are an artifact of incomplete enforcement rather than true localization.
Authors: We agree that a coverage metric would provide stronger direct evidence for the sparsity premise and rule out incomplete enforcement. While our results demonstrate effective safety gains using only 100 harmful samples, we will add an explicit coverage analysis (fraction of harmful continuations containing selected tokens) to the experiments in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: The abstract asserts a 'superior trade-off' and 'strong safety performance' with 'minimal degradation' but supplies no quantitative numbers, baseline comparisons, or verification steps. Without these details in the experimental sections, it is impossible to determine whether the reported results actually support the central claim of negligible capability loss.
Authors: The experimental sections already report quantitative results, baseline comparisons against prior methods, and verification across the seven safety and five capability benchmarks. To make the abstract claims more self-contained, we will revise it to include key quantitative figures (e.g., safety scores and capability retention rates) while preserving conciseness. revision: yes
Circularity Check
No circularity: empirical method with external benchmarks
full rationale
The paper presents an empirical method (activation-steered teacher + token selection + localized reverse KL) whose performance claims rest on held-out safety and capability benchmarks, not on any fitted parameter being renamed as a prediction or on self-referential definitions. No equations, self-citations, or uniqueness theorems are invoked in the provided text that reduce the central result to its own inputs by construction. The sparsity premise is an explicit modeling assumption whose validity is tested via downstream benchmarks rather than assumed tautologically.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , editor=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[2]
arXiv preprint arXiv:2308.10792 , year=
Instruction tuning for large language models: A survey , author=. arXiv preprint arXiv:2308.10792 , year=
-
[3]
2: Pushing the frontier of open large language models , author=
Deepseek-v3. 2: Pushing the frontier of open large language models , author=. arXiv preprint arXiv:2512.02556 , year=
-
[4]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[5]
arXiv preprint arXiv:2602.15763 , year=
Glm-5: from vibe coding to agentic engineering , author=. arXiv preprint arXiv:2602.15763 , year=
-
[6]
arXiv preprint arXiv:2503.00555 , year=
Safety tax: Safety alignment makes your large reasoning models less reasonable , author=. arXiv preprint arXiv:2503.00555 , year=
-
[7]
International Conference on Learning Representations , volume=
Safe rlhf: Safe reinforcement learning from human feedback , author=. International Conference on Learning Representations , volume=
-
[8]
Advances in Neural Information Processing Systems , volume=
One-shot safety alignment for large language models via optimal dualization , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
International Conference on Learning Representations , volume=
Bi-factorial preference optimization: Balancing safety-helpfulness in language models , author=. International Conference on Learning Representations , volume=
-
[10]
arXiv preprint arXiv:2512.11391 , year=
Mitigating the Safety Alignment Tax with Null-Space Constrained Policy Optimization , author=. arXiv preprint arXiv:2512.11391 , year=
-
[11]
arXiv preprint arXiv:2503.03710 , year=
Improving llm safety alignment with dual-objective optimization , author=. arXiv preprint arXiv:2503.03710 , year=
-
[12]
arXiv preprint arXiv:2603.07445 , year=
Few Tokens, Big Leverage: Preserving Safety Alignment by Constraining Safety Tokens during Fine-tuning , author=. arXiv preprint arXiv:2603.07445 , year=
-
[13]
Thinking Machines Lab: Connectionism , year =
Kevin Lu and Thinking Machines Lab , title =. Thinking Machines Lab: Connectionism , year =
-
[14]
arXiv preprint arXiv:2604.00626 , year=
A survey of on-policy distillation for large language models , author=. arXiv preprint arXiv:2604.00626 , year=
-
[15]
International Conference on Learning Representations , volume=
On-policy distillation of language models: Learning from self-generated mistakes , author=. International Conference on Learning Representations , volume=
-
[16]
International Conference on Learning Representations , volume=
Minillm: Knowledge distillation of large language models , author=. International Conference on Learning Representations , volume=
-
[17]
arXiv preprint arXiv:2601.19897 , year=
Self-Distillation Enables Continual Learning , author=. arXiv preprint arXiv:2601.19897 , year=
-
[18]
arXiv preprint arXiv:2601.18734 , year=
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author=. arXiv preprint arXiv:2601.18734 , year=
-
[19]
2023 , journal=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
2023
-
[20]
arXiv preprint arXiv:2310.01405 , year=
Representation engineering: A top-down approach to ai transparency , author=. arXiv preprint arXiv:2310.01405 , year=
-
[21]
arXiv preprint arXiv:2305.14233 , year=
Enhancing Chat Language Models by Scaling High-quality Instructional Conversations , author=. arXiv preprint arXiv:2305.14233 , year=
-
[22]
International Conference on Learning Representations , volume=
On the role of attention heads in large language model safety , author=. International Conference on Learning Representations , volume=
-
[23]
Advances in Neural Information Processing Systems , volume=
Llms encode harmfulness and refusal separately , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Layer-aware representation filtering: Purifying finetuning data to preserve llm safety alignment , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[25]
Jailbroken: How Does
Alexander Wei and Nika Haghtalab and Jacob Steinhardt , booktitle=. Jailbroken: How Does. 2023 , url=
2023
-
[26]
arXiv preprint arXiv:2303.17564 , year=
Bloomberggpt: A large language model for finance , author=. arXiv preprint arXiv:2303.17564 , year=
-
[27]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[28]
2024 , cdate=
Xiangyu Qi and Yi Zeng and Tinghao Xie and Pin-Yu Chen and Ruoxi Jia and Prateek Mittal and Peter Henderson , title=. 2024 , cdate=
2024
-
[29]
Proceedings of the 40th International Conference on Machine Learning , pages=
The Flan Collection: Designing Data and Methods for Effective Instruction Tuning ,author =. Proceedings of the 40th International Conference on Machine Learning , pages=. 2023 , URL=
2023
-
[30]
arXiv e-prints , pages=
Increased llm vulnerabilities from fine-tuning and quantization , author=. arXiv e-prints , pages=
-
[31]
arXiv preprint arXiv:2409.18169 , year=
Harmful fine-tuning attacks and defenses for large language models: A survey , author=. arXiv preprint arXiv:2409.18169 , year=
-
[32]
arXiv preprint arXiv:2410.04524 , year=
Towards secure tuning: Mitigating security risks arising from benign instruction fine-tuning , author=. arXiv preprint arXiv:2410.04524 , year=
-
[33]
The Thirteenth International Conference on Learning Representations , year=
Spurious Forgetting in Continual Learning of Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[34]
arXiv preprint arXiv:2412.19512 , year=
Safeguard Fine-Tuned LLMs Through Pre-and Post-Tuning Model Merging , author=. arXiv preprint arXiv:2412.19512 , year=
-
[35]
Advances in Neural Information Processing Systems , volume=
Safe loRA: The silver lining of reducing safety risks when finetuning large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Aladin Djuhera and Swanand Kadhe and Farhan Ahmed and Syed Zawad and Holger Boche , booktitle=. Safe. 2025 , url=
2025
-
[37]
Mingjie Li and Wai Man Si and Michael Backes and Yang Zhang and Yisen Wang , booktitle=. SaLo. 2025 , url=
2025
-
[38]
2024 , booktitle=
Vaccine: Perturbation-aware Alignment for Large Language Models against Harmful Fine-tuning Attack , author=. 2024 , booktitle=
2024
-
[39]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Representation Noising: A Defence Mechanism Against Harmful Finetuning , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[40]
Understanding and Enhancing Safety Mechanisms of
Yiran Zhao and Wenxuan Zhang and Yuxi Xie and Anirudh Goyal and Kenji Kawaguchi and Michael Shieh , booktitle=. Understanding and Enhancing Safety Mechanisms of. 2025 , url=
2025
-
[41]
First Conference on Language Modeling , year=
What is in Your Safe Data? Identifying Benign Data that Breaks Safety , author=. First Conference on Language Modeling , year=
-
[42]
2025 , url=
Han Shen and Pin-Yu Chen and Payel Das and Tianyi Chen , booktitle=. 2025 , url=
2025
-
[43]
Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining , pages=
A new generation of perspective api: Efficient multilingual character-level transformers , author=. Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[44]
2024 , eprint =
The Llama 3 Herd of Models , author =. 2024 , eprint =
2024
-
[45]
2024 , eprint=
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs , author=. 2024 , eprint=
2024
-
[46]
arXiv preprint arXiv:2407.21772 , year=
Shieldgemma: Generative ai content moderation based on gemma , author=. arXiv preprint arXiv:2407.21772 , year=
-
[47]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
GradSafe: Detecting Jailbreak Prompts for LLMs via Safety-Critical Gradient Analysis , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[48]
arXiv preprint arXiv:2502.11411 , year=
Detecting and Filtering Unsafe Training Data via Data Attribution , author=. arXiv preprint arXiv:2502.11411 , year=
-
[49]
Safety Layers in Aligned Large Language Models: The Key to
Shen Li and Liuyi Yao and Lan Zhang and Yaliang Li , booktitle=. Safety Layers in Aligned Large Language Models: The Key to. 2025 , url=
2025
-
[50]
arXiv preprint arXiv:2502.09674 , year=
The hidden dimensions of llm alignment: A multi-dimensional safety analysis , author=. arXiv preprint arXiv:2502.09674 , year=
-
[51]
2024 , eprint=
Improving Alignment and Robustness with Circuit Breakers , author=. 2024 , eprint=
2024
-
[52]
arXiv preprint arXiv:2410.10700 , year=
Derail Yourself: Multi-turn LLM Jailbreak Attack through Self-discovered Clues , author=. arXiv preprint arXiv:2410.10700 , year=
-
[53]
arXiv preprint arXiv:2307.15043 , year=
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
-
[54]
Kaifeng Lyu and Haoyu Zhao and Xinran Gu and Dingli Yu and Anirudh Goyal and Sanjeev Arora , booktitle=. Keeping. 2024 , url=
2024
-
[55]
2024 , eprint=
SORRY-Bench: Systematically Evaluating Large Language Model Safety Refusal Behaviors , author=. 2024 , eprint=
2024
-
[56]
Advances in Neural Information Processing Systems , volume=
Jailbreakbench: An open robustness benchmark for jailbreaking large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
arXiv preprint arXiv:2308.09662 , year=
Red-teaming large language models using chain of utterances for safety-alignment , author=. arXiv preprint arXiv:2308.09662 , year=
-
[58]
arXiv preprint arXiv:2404.08676 , year=
ALERT: A comprehensive benchmark for assessing large language models' safety through red teaming , author=. arXiv preprint arXiv:2404.08676 , year=
-
[59]
arXiv preprint arXiv:2009.03300 , year=
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
Pith/arXiv arXiv 2009
-
[60]
Advances in Neural Information Processing Systems , volume=
Large language diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[61]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[62]
arXiv preprint arXiv:2305.20050 , year=
Let's Verify Step by Step , author=. arXiv preprint arXiv:2305.20050 , year=
-
[63]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[64]
Hashimoto , title =
Xuechen Li and Tianyi Zhang and Yann Dubois and Rohan Taori and Ishaan Gulrajani and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , month =
2023
-
[65]
arXiv preprint arXiv:2502.09990 , year=
X-boundary: Establishing exact safety boundary to shield llms from multi-turn jailbreaks without compromising usability , author=. arXiv preprint arXiv:2502.09990 , year=
-
[66]
arXiv preprint arXiv:2403.12171 , year=
Easyjailbreak: A unified framework for jailbreaking large language models , author=. arXiv preprint arXiv:2403.12171 , year=
-
[67]
arXiv preprint arXiv:2604.13016 , year=
Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe , author=. arXiv preprint arXiv:2604.13016 , year=
-
[68]
arXiv preprint arXiv:2507.02844 , year=
Visual Contextual Attack: Jailbreaking MLLMs with Image-Driven Context Injection , author=. arXiv preprint arXiv:2507.02844 , year=
-
[69]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
T2isafety: Benchmark for assessing fairness, toxicity, and privacy in image generation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[70]
arXiv preprint arXiv:2507.05248 , year=
Response Attack: Exploiting Contextual Priming to Jailbreak Large Language Models , author=. arXiv preprint arXiv:2507.05248 , year=
-
[71]
Lindsey, Jack and Gurnee, Wes and Ameisen, Emmanuel and Chen, Brian and Pearce, Adam and Turner, Nicholas L. and Citro, Craig and Abrahams, David and Carter, Shan and Hosmer, Basil and Marcus, Jonathan and Sklar, Michael and Templeton, Adly and Bricken, Trenton and McDougall, Callum and Cunningham, Hoagy and Henighan, Thomas and Jermyn, Adam and Jones, An...
-
[72]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[73]
arXiv preprint arXiv:2408.00118 , year=
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
-
[74]
arXiv preprint arXiv:2402.05044 , year=
Salad-bench: A hierarchical and comprehensive safety benchmark for large language models , author=. arXiv preprint arXiv:2402.05044 , year=
-
[75]
2024 , eprint=
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal , author=. 2024 , eprint=
2024
-
[76]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[77]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=. 2024 , url=
2024
-
[78]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Adversarial Representation Engineering: A General Model Editing Framework for Large Language Models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[79]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[80]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.