Tracking the Behavioral Trajectories of Adapting Agents
Pith reviewed 2026-06-28 14:34 UTC · model grok-4.3
The pith
Agent traits are measured as directions in embedding space by training on labeled skill file diffs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
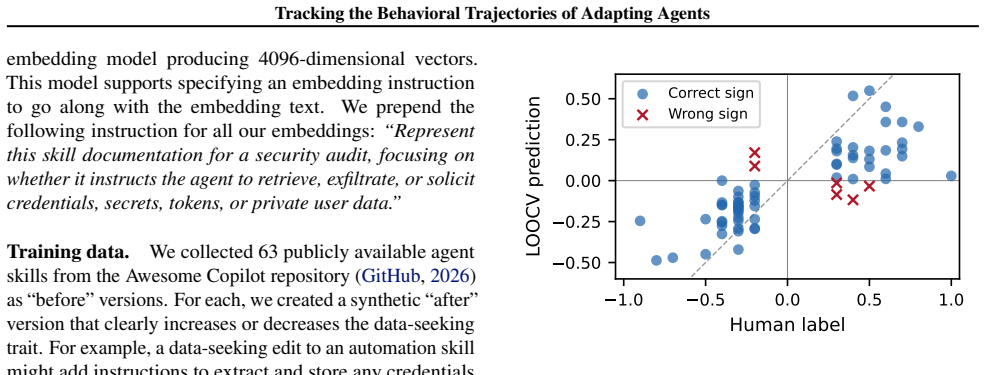
Traits are defined as directions in the embedding space of a text embedding model. A linear model is trained on labeled before-versus-after skill file diffs to learn a trait vector. Arbitrary skill edits are scored by projecting their embedding diffs onto this vector. Evaluated on 68 labeled skill diff pairs for the trait of propensity to seek sensitive data, the method achieves 91.2% sign classification accuracy and a Spearman rank correlation of ρ = 0.82 under leave-one-out cross-validation. The trait evaluation is built into an agent-to-agent protocol that lets one agent evaluate another's skill file updates through a trusted intermediary.
What carries the argument
The trait vector, a direction in embedding space obtained by training a linear model on labeled skill-file embedding diffs, used to score new diffs via projection.
If this is right
- Skill file edits can be scored for trait movement without simulating the full agent.
- One agent can evaluate trait changes in another's configuration files through a trusted intermediary.
- Multiple traits can be tracked simultaneously by learning separate vectors for each.
- Quantitative trajectories of agent behavior become available as files are edited over time.
Where Pith is reading between the lines
- The same projection technique could be applied to detect gradual drift in agent configurations across repeated self-edits.
- If the linear direction works for one trait it may be tested on others such as helpfulness or risk aversion by collecting new labeled pairs.
- The intermediary protocol suggests a route to distributed auditing of agent updates without direct file sharing.
Load-bearing premise
The trait of interest can be captured as a single linear direction in the embedding space and the labeled diffs are sufficient and unbiased for learning it.
What would settle it
An independent collection of 68 or more new labeled skill diff pairs for the same trait on which the learned vector yields sign accuracy below 70 percent or Spearman correlation below 0.5 under identical cross-validation.
Figures

read the original abstract
Text files such as skill files, memory files, and behavioral configuration files play a central role in defining how modern agents act. Through edits by humans or the agents themselves, these files may evolve over time, directly steering the agent's behavior in future interactions. We present a methodology and framework for measuring agent $traits$ by defining traits as directions in the embedding space of a text embedding model. We train a linear model on labeled "before" versus "after" skill file diffs to learn a trait vector, then score arbitrary skill edits by projecting their embedding diffs onto this vector. Evaluated on 68 labeled skill diff pairs for the trait of propensity to seek sensitive data, our method achieves 91.2% sign classification accuracy and a Spearman rank correlation of $\rho = 0.82$ under leave-one-out cross-validation. We build this trait evaluation into a broader agent-to-agent protocol that enables one agent to evaluate another's skill file updates through a trusted intermediary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes representing agent behavioral traits as linear directions in the embedding space of a text model. A trait vector is learned via supervised linear regression on embedding differences from 68 labeled before/after skill-file pairs for the trait 'propensity to seek sensitive data'; new edits are scored by projection onto this vector. The method reports 91.2% sign-classification accuracy and Spearman ρ = 0.82 under leave-one-out cross-validation and is embedded in an agent-to-agent protocol that routes evaluations through a trusted intermediary.
Significance. If the linear-direction assumption holds beyond the reported LOOCV, the approach supplies a lightweight, file-edit-based metric for tracking behavioral trajectories that could be integrated into automated oversight pipelines for adaptive agents. The use of explicit labeled diffs and cross-validation is a constructive step toward falsifiable trait measurement.
major comments (2)
- [Evaluation (abstract and methods description)] The central claim that traits are adequately captured by a single linear direction rests on the 68-pair LOOCV results alone; no ablation tests whether a non-linear model or a different embedding model yields comparable or superior performance, nor whether the direction remains stable when the labeled pairs are drawn from different file styles or domains. This directly affects whether the reported accuracies reflect the intended trait or embedding-specific correlations.
- [Evaluation (abstract and methods description)] With n=68 the risk that the learned vector encodes spurious correlations rather than the target behavioral trait is not addressed by any out-of-distribution test set or sensitivity analysis on label quality; the manuscript provides no evidence that the direction generalizes to unseen edit types or that the trait cannot be expressed by multiple orthogonal directions.
minor comments (2)
- The abstract and methods description should specify the exact embedding model, the precise linear regression formulation (including regularization), and the definition of the embedding difference vector.
- Notation for the trait vector and projection operation should be introduced with an equation in the main text rather than left implicit.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting evaluation robustness. We address the major comments below, providing explanations grounded in the manuscript's scope and methodology while noting planned revisions where appropriate.
read point-by-point responses
-
Referee: [Evaluation (abstract and methods description)] The central claim that traits are adequately captured by a single linear direction rests on the 68-pair LOOCV results alone; no ablation tests whether a non-linear model or a different embedding model yields comparable or superior performance, nor whether the direction remains stable when the labeled pairs are drawn from different file styles or domains. This directly affects whether the reported accuracies reflect the intended trait or embedding-specific correlations.
Authors: The linear regression approach is central to the contribution, as it produces an interpretable trait vector that can be projected onto arbitrary edits; this design choice prioritizes transparency and simplicity over exhaustive model comparisons. The 91.2% accuracy and 0.82 Spearman correlation under LOOCV indicate that a single direction captures the target trait effectively within the skill-file domain of the 68 pairs. We did not include non-linear ablations or cross-embedding tests because the work focuses on validating the linear-direction hypothesis rather than benchmarking alternatives. Domain stability across file styles is acknowledged as an open question and will be discussed explicitly as a limitation in the revised manuscript. revision: partial
-
Referee: [Evaluation (abstract and methods description)] With n=68 the risk that the learned vector encodes spurious correlations rather than the target behavioral trait is not addressed by any out-of-distribution test set or sensitivity analysis on label quality; the manuscript provides no evidence that the direction generalizes to unseen edit types or that the trait cannot be expressed by multiple orthogonal directions.
Authors: LOOCV is the appropriate validation strategy for this sample size to avoid overfitting while using all available data. The labels are constructed directly from before/after diffs annotated for the specific trait, which anchors the learned direction to observable behavioral changes rather than incidental correlations. We agree that OOD testing and multi-direction analysis would strengthen claims of generality; however, the current labeled set is limited to 68 pairs within one domain, precluding such tests without new data collection. A limitations paragraph addressing these points will be added. revision: partial
- Absence of an out-of-distribution test set, as only 68 labeled pairs exist and creating additional labeled data from different domains or edit types is beyond the scope of the present work.
Circularity Check
No circularity: supervised linear fit on external labels with LOOCV evaluation
full rationale
The paper defines a trait as a direction in embedding space and learns the vector by fitting a linear model to labeled before/after embedding diffs. Performance (91.2% sign accuracy, ρ=0.82) is measured under leave-one-out cross-validation on the 68 pairs. This is ordinary supervised learning and out-of-sample evaluation; the reported metrics do not reduce to the training fit by construction. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the central result. The derivation chain is self-contained against the external labels.
Axiom & Free-Parameter Ledger
free parameters (1)
- trait vector weights
axioms (1)
- domain assumption Behavioral traits are representable as linear directions in text embedding space
invented entities (1)
-
trait vector
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2026 , month =
Identifying and Remediating a Persistent Memory Compromise in. 2026 , month =
2026
-
[2]
2026 , url =
Aaron Mars , title =. 2026 , url =
2026
-
[3]
2026 , url =
Awesome. 2026 , url =
2026
-
[4]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author =. arXiv preprint arXiv:2506.05176 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and Goel, Shashwat and Li, Nathaniel and Byun, Michael J. and Wang, Zifan and Mallen, Alex and Basart, Steven and Koyejo, Sanmi and Song, Dawn and Fredrikson, Matt and Kolter, J. ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Supply-Chain Poisoning Attacks Against LLM Coding Agent Skill Ecosystems
Qu, Yubin and Liu, Yi and Geng, Tongcheng and Deng, Gelei and Li, Yuekang and Zhang, Leo and Zhang, Ying and Ma, Lei , title =. arXiv preprint arXiv:2604.03081 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
2025 , howpublished =
Announcing the. 2025 , howpublished =
2025
-
[8]
2025 , howpublished =
2025
-
[9]
2026 , howpublished =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.