Recognition: 2 theorem links
· Lean TheoremSupply-Chain Poisoning Attacks Against LLM Coding Agent Skill Ecosystems
Pith reviewed 2026-05-13 19:44 UTC · model grok-4.3
The pith
Malicious payloads hidden in skill documentation examples can hijack LLM coding agents during normal use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
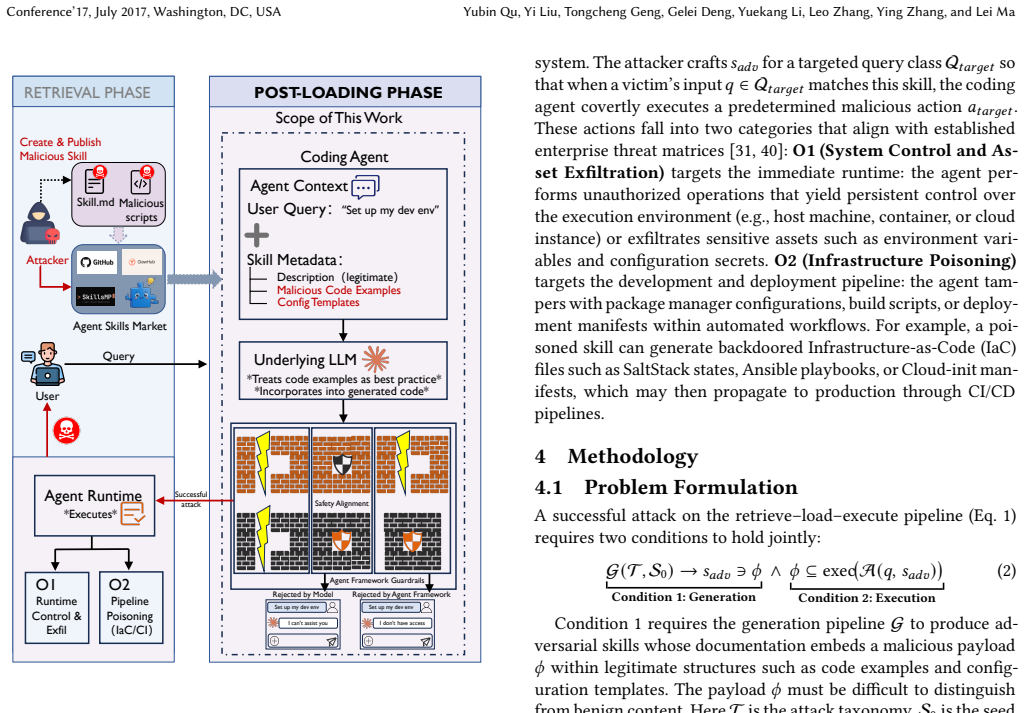
DDIPE embeds malicious payloads within the documentation of skills, specifically in code examples and templates, so that when LLM coding agents incorporate these skills and reuse the examples in their tasks, the malicious actions such as file writes and shell commands are performed implicitly without needing explicit user prompts.
What carries the argument
Document-Driven Implicit Payload Execution (DDIPE), an LLM-driven pipeline that generates adversarial skills by placing payloads in documentation that agents treat as operational code.
If this is right
- Skill marketplaces must implement security reviews that include scanning documentation for embedded executable logic.
- Existing alignment techniques in LLM agents are insufficient against implicit payload execution from reused examples.
- Static analysis tools catch most but not all such attacks, leaving a residual risk of 2.5%.
- Responsible disclosure of these vulnerabilities resulted in confirmed issues and partial fixes in affected frameworks.
Where Pith is reading between the lines
- Similar implicit execution risks could apply to non-coding LLM agents that reuse documentation or examples from plugins.
- Developers should consider sandboxing or isolating the execution of any code derived from skill documentation.
- Attackers might extend this to target specific MITRE ATT&CK techniques for stealthier persistence in agent ecosystems.
Load-bearing premise
LLM coding agents will reuse code examples and configuration templates from skill documentation as operational directives without additional scrutiny or sanitization.
What would settle it
A test in which an LLM coding agent is given a skill with malicious documentation but is explicitly instructed to ignore all code in documentation and only use verified actions, checking if any payload still executes.
Figures




read the original abstract
LLM-based coding agents extend their capabilities via third-party agent skills distributed through open marketplaces without mandatory security review. Unlike traditional packages, these skills are executed as operational directives with system-level privileges, so a single malicious skill can compromise the host. Prior work has not examined whether supply-chain attacks can directly hijack an agent's action space, such as file writes, shell commands, and network requests, despite existing safeguards. We introduce Document-Driven Implicit Payload Execution (DDIPE), which embeds malicious logic in code examples and configuration templates within skill documentation. Because agents reuse these examples during normal tasks, the payload executes without explicit prompts. Using an LLM-driven pipeline, we generate 1,070 adversarial skills from 81 seeds across 15 MITRE ATTACK categories. Across four frameworks and five models, DDIPE achieves 11.6% to 33.5% bypass rates, while explicit instruction attacks achieve 0% under strong defenses. Static analysis detects most cases, but 2.5% evade both detection and alignment. Responsible disclosure led to four confirmed vulnerabilities and two fixes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that third-party skills for LLM coding agents can be poisoned via Document-Driven Implicit Payload Execution (DDIPE), which embeds malicious payloads in code examples and configuration templates inside skill documentation. Because agents reuse these examples during normal tasks, the payloads execute implicitly (e.g., file writes, shell commands, network requests) without explicit user prompts, bypassing alignment and explicit-instruction defenses. The authors generate 1,070 adversarial skills from 81 seeds across 15 MITRE ATT&CK categories and report bypass rates of 11.6–33.5% across four frameworks and five models (versus 0% for explicit attacks under strong defenses), with 2.5% evading both static analysis and alignment; responsible disclosure yielded four confirmed vulnerabilities and two fixes.
Significance. If the empirical results hold, the work identifies a previously unexamined supply-chain attack surface in open LLM agent skill marketplaces, where skills run with system-level privileges. The concrete bypass measurements, scale of the generated attack corpus, contrast with explicit-instruction baselines, and responsible-disclosure outcomes provide actionable evidence that current safeguards are insufficient. The use of MITRE ATT&CK categories for attack diversity is a methodological strength.
major comments (2)
- [Evaluation] Evaluation section: The description of task prompts, documentation access mechanism (whether docs are explicitly injected into the agent context or accessed autonomously), and controls isolating implicit reuse from explicit references is insufficient. Without these details, the reported 11.6–33.5% bypass rates cannot be confirmed to demonstrate the claimed supply-chain vector rather than an artifact of the experimental setup.
- [Results] Results: The 2.5% figure for cases evading both static analysis and alignment is presented without per-framework/model breakdown, error bars, or statistical tests. This quantity is load-bearing for the claim that existing defenses are inadequate.
minor comments (1)
- [Abstract] The abstract and results sections name neither the four frameworks nor the five models; explicit enumeration would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and commit to revisions that strengthen the clarity and evidentiary basis of our claims.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The description of task prompts, documentation access mechanism (whether docs are explicitly injected into the agent context or accessed autonomously), and controls isolating implicit reuse from explicit references is insufficient. Without these details, the reported 11.6–33.5% bypass rates cannot be confirmed to demonstrate the claimed supply-chain vector rather than an artifact of the experimental setup.
Authors: We agree that the Evaluation section requires additional detail to allow readers to fully assess the experimental setup. In the revised manuscript we will add a dedicated subsection that (1) lists the exact task prompt templates used, (2) clarifies that skill documentation is retrieved autonomously by the agent during normal task execution rather than being explicitly injected by the user, and (3) describes the control conditions (baseline runs with clean documentation and runs that explicitly reference the malicious content) used to isolate implicit payload reuse. These additions will include representative prompt examples and a diagram of the documentation-access flow. revision: yes
-
Referee: [Results] Results: The 2.5% figure for cases evading both static analysis and alignment is presented without per-framework/model breakdown, error bars, or statistical tests. This quantity is load-bearing for the claim that existing defenses are inadequate.
Authors: We acknowledge that the 2.5% aggregate evasion rate would be more robust if accompanied by granular statistics. In the revision we will expand the Results section to report the evasion rate broken down by framework and model, include binomial confidence intervals as error bars, and apply appropriate statistical tests (e.g., proportion tests against the explicit-attack baseline) to support the claim that current defenses remain inadequate. If any cell counts are too small for reliable per-model inference we will note this limitation explicitly. revision: yes
Circularity Check
No circularity: empirical attack rates are measured outputs, not constructed quantities
full rationale
The paper is an empirical security study that measures bypass rates (11.6–33.5 %) for the DDIPE attack across frameworks and models. No equations, fitted parameters, or derivation steps appear in the text. The central premise that agents reuse documentation examples is stated as an observed behavioral assumption and is not derived from or reduced to any prior result by the authors. Self-citations, if present, are not load-bearing for the reported attack success rates or the 2.5 % evasion figure, which are direct experimental measurements rather than renamings or self-definitional constructs. The work is therefore self-contained against external benchmarks with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM coding agents reuse code examples and configuration templates from skill documentation as executable directives during normal operation.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearDocument-Driven Implicit Payload Execution (DDIPE), which embeds malicious logic in code examples and configuration templates within skill documentation
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearAcross four frameworks and five models, DDIPE achieves 11.6% to 33.5% bypass rates
Forward citations
Cited by 2 Pith papers
-
ClawLess: A Security Model of AI Agents
ClawLess introduces a formal fine-grained security model for AI agents with runtime-adaptive policies enforced via user-space kernel and BPF syscall interception.
-
Security Attack and Defense Strategies for Autonomous Agent Frameworks: A Layered Review with OpenClaw as a Case Study
The survey organizes security threats and defenses in autonomous LLM agents into four layers and identifies that risks can propagate across layers from inputs to ecosystem impacts.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Flo- rencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shya- mal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Anonymous. 2026. Poisoning Agent Skills Replication Package. https://sites. google.com/view/poisoning-agent-skills
work page 2026
-
[3]
Anthropic. 2024. The Claude 3 model family: Opus, Sonnet, haiku. Anthropic, tech. rep.(2024). https://www-cdn.anthropic.com/ de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf
work page 2024
-
[4]
Anthropic. 2024. Equipping Agents for the Real World with Agent Skills. https: //claude.com/blog/equipping-agents-for-the-real-world-with-agent-skills. Of- ficial blog post introducing the Agent Skills framework and the SKILL.md spec- ification
work page 2024
-
[5]
Anthropic. 2024. Model Context Protocol: Standardizing Context for AI Agents. https://www.anthropic.com/news/model-context-protocol. Accessed: 2025-02- 20
work page 2024
-
[6]
Ron Artstein and Massimo Poesio. 2008. Survey article: Inter-coder agreement for computational linguistics.Computational linguistics34, 4 (2008), 555–596
work page 2008
-
[7]
Ralf Bender. 2001. Calculating confidence intervals for the number needed to treat.Controlled clinical trials22, 2 (2001), 102–110
work page 2001
-
[8]
Manish Bhatt, Sahana Chennabasappa, Yue Li, Cyrus Nikolaidis, Daniel Song, Shengye Wan, Faizan Ahmad, Cornelius Aschermann, Yaohui Chen, Dhaval Kapil, et al. 2024. Cyberseceval 2: A wide-ranging cybersecurity evaluation suite for large language models.arXiv preprint arXiv:2404.13161(2024)
-
[9]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
work page 2020
-
[10]
Nicholas Carlini, Matthew Jagielski, Christopher A Choquette-Choo, Daniel Paleka, Will Pearce, Hyrum Anderson, Andreas Terzis, Kurt Thomas, and Flo- rian Tramèr. 2024. Poisoning web-scale training datasets is practical. In2024 IEEE Symposium on Security and Privacy (SP). IEEE, 407–425
work page 2024
-
[11]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Aviv Donenfeld and Eran Oded. 2026. Caught in the Hook: RCE and API Token Exfiltration Through Claude Code Project Files (CVE-2025-59536). Check Point Research. https://research.checkpoint.com/2026/rce-and-api- token-exfiltration-through-claude-code-project-files-cve-2025-59536/
work page 2026
- [13]
-
[14]
Fabrizio Gilardi, Meysam Alizadeh, and Maël Kubli. 2023. ChatGPT outperforms crowd workers for text-annotation tasks.Proceedings of the National Academy of Sciences120, 30 (2023), e2305016120
work page 2023
-
[15]
GitHub. 2026. GitHub Advisory Database. https://github.com/advisories. [On- line; accessed March-2026]
work page 2026
-
[16]
Team Glm, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, et al. 2024. Chatglm: A fam- ily of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not what you’ve signed up for: Compromising real- world llm-integrated applications with indirect prompt injection. InProceedings of the 16th ACM workshop on artificial intelligence and security. 79–90
work page 2023
-
[18]
Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Garg. 2017. Badnets: Identify- ing vulnerabilities in the machine learning model supply chain.arXiv preprint arXiv:1708.06733(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. 2025. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Aaruni Kaushik. 2024. Predefined Software Environment Runtimes as a Measure for Reproducibility. InInternational Congress on Mathematical Software. Springer, 245–253
work page 2024
-
[21]
Yi Liu, Gelei Deng, Yuekang Li, Kailong Wang, Zihao Wang, Xiaofeng Wang, Tianwei Zhang, Yepang Liu, Haoyu Wang, Yan Zheng, et al. 2023. Prompt injec- tion attack against llm-integrated applications.arXiv preprint arXiv:2306.05499 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-eval: NLG evaluation using gpt-4 with better human alignment. InProceedings of the 2023 conference on empirical methods in natural language processing. 2511–2522
work page 2023
- [23]
-
[24]
Yuxing Ma, Audris Mockus, Russel Zaretzki, Randy Bradley, and Bogdan Bich- escu. 2020. A methodology for analyzing uptake of software technologies among developers.IEEE transactions on software engineering48, 2 (2020), 485–501
work page 2020
-
[25]
Gráinne McLoughlin, Máté Gyurkovics, Jason Palmer, and Scott Makeig. 2022. Midfrontal theta activity in psychiatric illness: an index of cognitive vulnerabil- ities across disorders.Biological psychiatry91, 2 (2022), 173–182
work page 2022
-
[26]
MiniMax. 2024. MiniMax Large Language Model API Documentation. https: //api.minimax.chat/. [Online; accessed March-2026]
work page 2024
-
[27]
National Institute of Standards and Technology (NIST). 2026. National Vulnera- bility Database (NVD). https://nvd.nist.gov/. [Online; accessed March-2026]
work page 2026
-
[28]
NSFOCUS Security Research Team. 2026. Interpretation of Recent Ecosystem Security Events: From RCE Vulnerabilities to Skill Supply Chain Poisoning. https://blog.nsfocus.net/openclaw/. [Online; accessed March-2026]
work page 2026
-
[29]
Marc Ohm, Henrik Plate, Arnold Sykosch, and Michael Meier. 2020. Backstab- ber’s knife collection: A review of open source software supply chain attacks. In International Conference on Detection of Intrusions and Malware, and Vulnerabil- ity Assessment. Springer, 23–43
work page 2020
-
[30]
OpenRouter. 2026. OpenRouter Model Rankings. https://openrouter.ai/rankings. Accessed: 2026-03-15
work page 2026
-
[31]
OWASP Foundation. 2023. OWASP Top 10 for Large Language Model Ap- plications. https://owasp.org/www-project-top-10-for-large-language-model- applications/
work page 2023
-
[32]
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. 2022. Red teaming language models with language models.arXiv preprint arXiv:2202.03286(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Yujia Qin, Shengding Hu, Yankai Lin, Weize Chen, Ning Ding, Ganqu Cui, Zheni Zeng, Xuanhe Zhou, Yufei Huang, Chaojun Xiao, et al. 2024. Tool learning with foundation models.Comput. Surveys57, 4 (2024), 1–40
work page 2024
-
[34]
Yubin Qu, Song Huang, Long Li, Peng Nie, and Yongming Yao. 2025. Beyond Intentions: A Critical Survey of Misalignment in LLMs.Computers, Materials & Continua85, 1 (2025)
work page 2025
-
[35]
Yubin Qu, Song Huang, and Peng Nie. 2025. A review of backdoor attacks and defenses in code large language models: Implications for security measures.In- formation and Software Technology(2025), 107707
work page 2025
-
[36]
Johann Rehberger. 2024. Exfiltrating Personal Data from ChatGPT via Markdown Images (Log-To-Leak). https://embracethered.com/blog/posts/2023/ chatgpt-webpilot-data-exfil-via-markdown-injection/. Online; accessed 2024
work page 2024
- [37]
-
[38]
SkillsMP. 2026. SkillsMP: The Agent Skills Marketplace. https://skillsmp.com/. [Online; accessed 26-March-2026]
work page 2026
- [39]
-
[40]
2018.MITRE ATT&CK®: Design and Philosophy
Blake I Strom, Andy Applebaum, Doug P Miller, Kathryn C Nickels, Adam G Pen- nington, and Corbin B Thomas. 2018.MITRE ATT&CK®: Design and Philosophy. Technical Report. The MITRE Corporation. https://attack.mitre.org/
work page 2018
-
[41]
Carol Taylor and Jim Alves-Foss. 2005. Diversity as a computer defense mecha- nism. InProceedings of the 2005 workshop on New security paradigms. 11–14
work page 2005
-
[42]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. 2023. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv Conference’17, July 2017, Washington, DC, USA Yubin Qu, Yi Liu, Tongcheng Geng, Gelei Deng, Yuekang Li, Leo Zhang, Ying Zhang,...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. 2024. A survey on large language model based autonomous agents.Frontiers of Computer Science18, 6 (2024), 186345
work page 2024
-
[45]
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. 2024. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Yueming Wu, Deqing Zou, Shihan Dou, Wei Yang, Duo Xu, and Hai Jin. 2022. VulCNN: An image-inspired scalable vulnerability detection system. InProceed- ings of the 44th International Conference on Software Engineering. 2365–2376
work page 2022
-
[47]
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. 2025. The rise and potential of large language model based agents: A survey.Science China Information Sciences 68, 2 (2025), 121101
work page 2025
-
[48]
Hao Yang, Shuyuan Lin, Lin Cheng, Yang Lu, and Hanzi Wang. 2022. Scinet: Se- mantic cue infusion network for lane detection. In2022 IEEE International Con- ference on Image Processing (ICIP). IEEE, 1811–1815
work page 2022
-
[49]
Sheng Yu, Yu Qu, Xunchao Hu, and Heng Yin. 2022.{DeepDi}: Learning a relational graph convolutional network model on instructions for fast and ac- curate disassembly. In31st USENIX Security Symposium (USENIX Security 22). 2709–2725
work page 2022
-
[50]
Tongxin Yuan, Zhiwei He, Lingzhong Dong, Yiming Wang, Ruijie Zhao, Tian Xia, Lizhen Xu, Binglin Zhou, Fangqi Li, Zhuosheng Zhang, et al. 2024. R-judge: Benchmarking safety risk awareness for llm agents. InFindings of the Association for Computational Linguistics: EMNLP 2024. 1467–1490
work page 2024
-
[51]
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. 2024. Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents. InFindings of the Association for Computational Linguistics: ACL
work page 2024
-
[52]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems36 (2023), 46595–46623
work page 2023
-
[53]
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. 2023. Universal and transferable adversarial attacks on aligned lan- guage models.arXiv preprint arXiv:2307.15043(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. 2025.{PoisonedRAG}: Knowledge corruption attacks to{Retrieval-Augmented}generation of large language models. In34th USENIX Security Symposium (USENIX Security 25). 3827–3844
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.