Building Better Activation Oracles
Pith reviewed 2026-06-30 14:16 UTC · model grok-4.3
The pith
Four changes to Activation Oracle training cut vagueness and hallucinations when interpreting model activations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
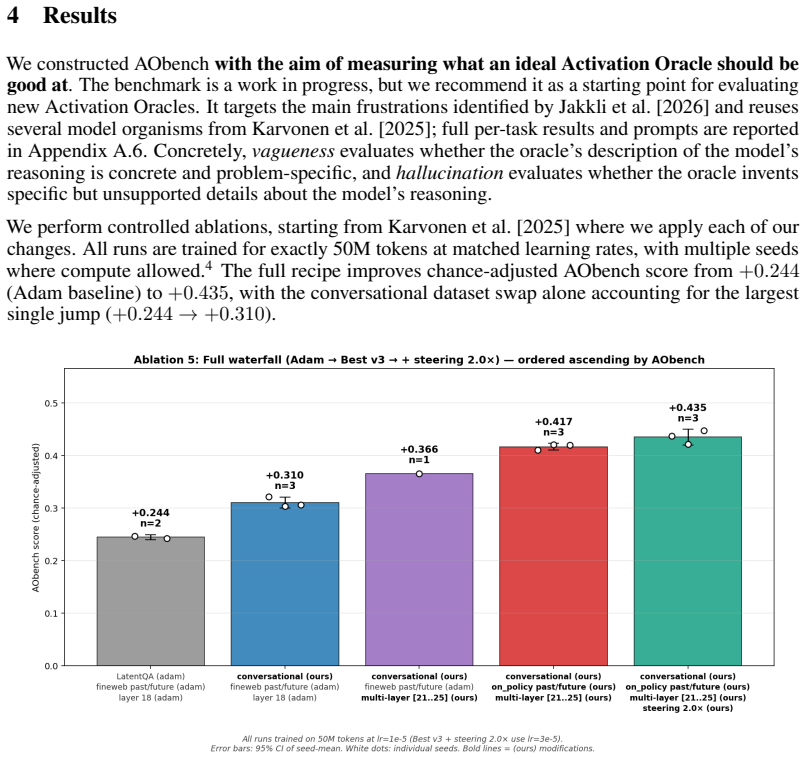
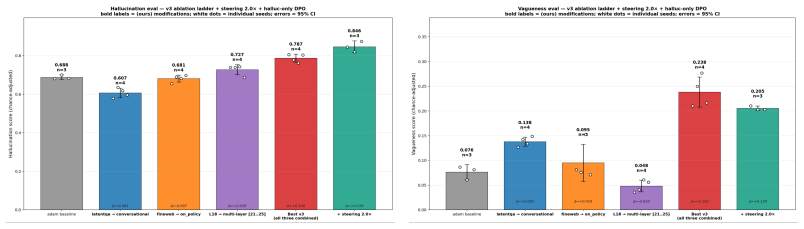
Training Activation Oracles on on-policy rollouts, an improved conversational dataset, activations from more layers, and with a refined injection formula yields substantial quality-of-life gains by reducing hallucinations and vagueness, even though capability improvements stay marginal. The work also contributes AObench as the first comprehensive open-source suite for measuring AO quality in the presence of text-inversion confounds.
What carries the argument
The Activation Oracle training regime, which conditions a separate model on residual stream activations to produce human-readable interpretations, with four specific updates to data collection, dataset content, layer coverage, and information injection.
If this is right
- AOs become more practical tools for inspecting what specific activations encode inside a model.
- AObench supplies a shared yardstick that future AO methods can be measured against.
- The training changes support the broader goal of scalable, end-to-end interpretability by making activation-based tools more reliable.
- Quality-of-life gains may encourage wider adoption of AOs for model debugging even before larger capability jumps appear.
Where Pith is reading between the lines
- Similar on-policy and multi-layer adjustments could be tested on other activation-conditioned models beyond the oracle setting.
- If AObench sees adoption, progress in this area may shift from ad-hoc demos to tracked benchmark improvements.
- The modest capability gains hint that architectural changes to the oracle itself, rather than just training data, may be required for bigger leaps.
Load-bearing premise
That the four training changes actually lower hallucination and vagueness rates rather than merely swapping one set of artifacts for another, and that AObench scores reflect true oracle quality without being dominated by text-inversion confounds.
What would settle it
Evaluating the updated oracles on AObench and finding no measurable drop in hallucination frequency or vagueness ratings relative to earlier versions, or finding that human raters judge the new outputs as equally unclear on the same prompts.
Figures





read the original abstract
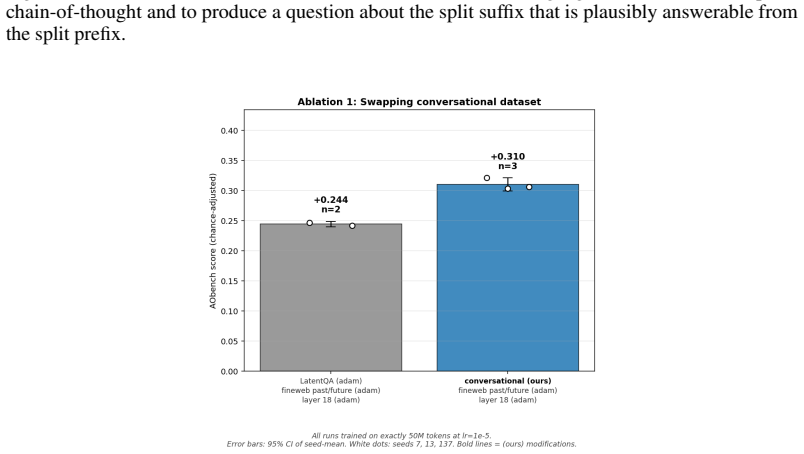
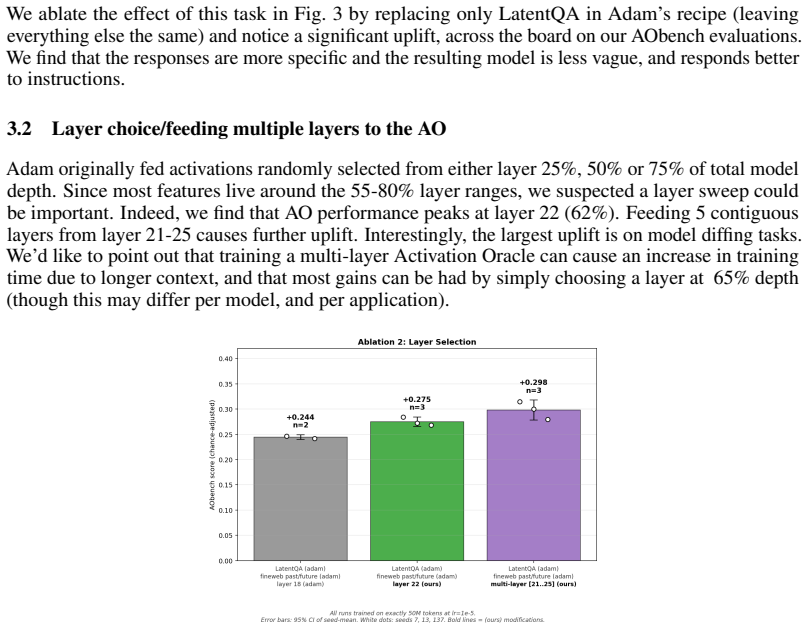
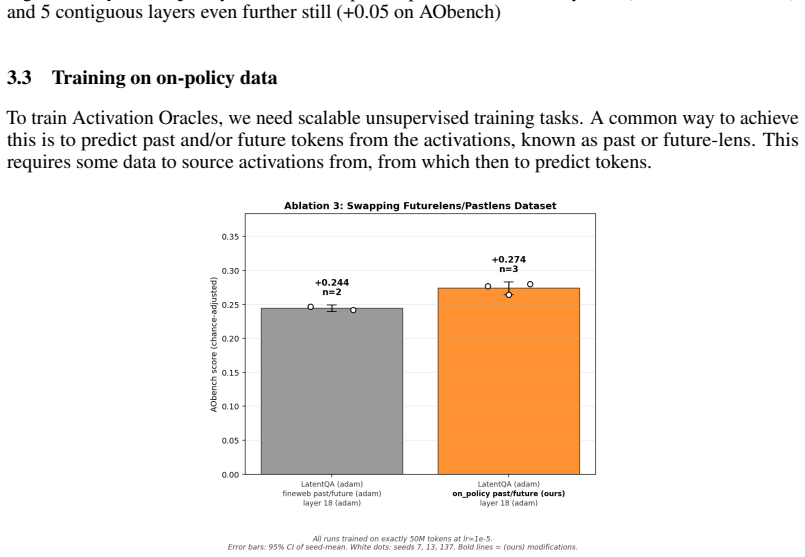
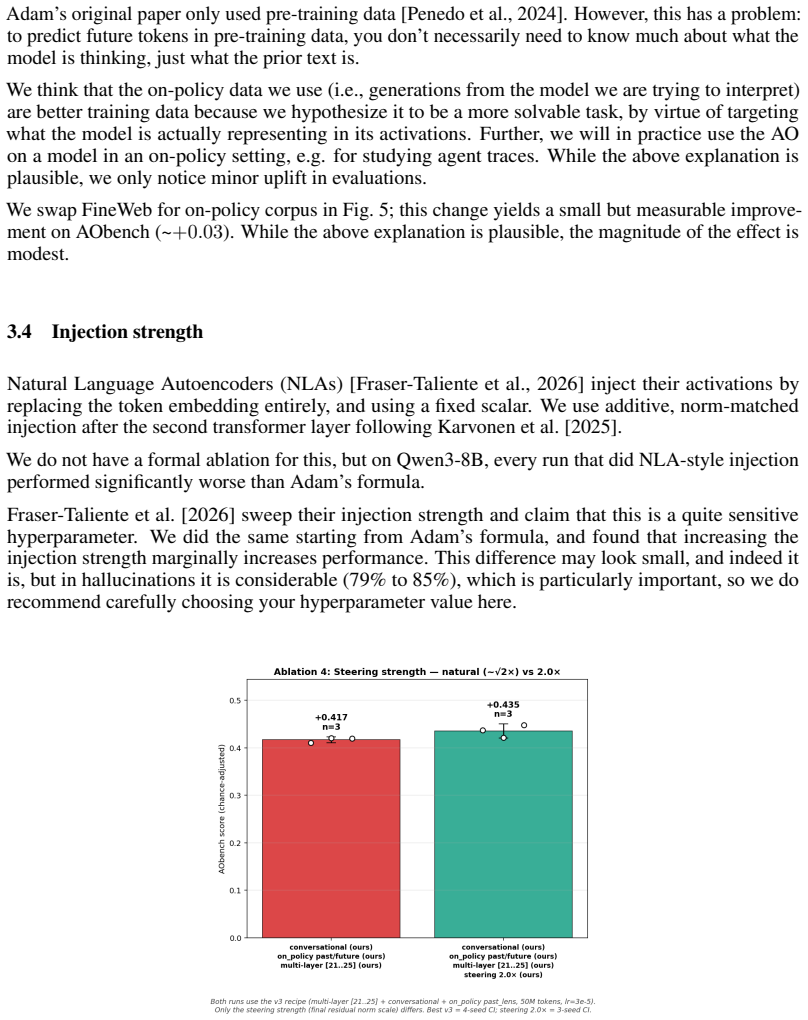
Activation Oracles (AOs) are promising methods for interpreting residual stream activations. However, current AOs face important issues, such as hallucinations and vagueness. Additionally, text-inversion confounds make them hard to evaluate. To this end, we improve the Activation Oracle (AO) training regime in four ways: training on on-policy rollouts, improving the conversational dataset, feeding more layers and an improvement to the injection formula. The capability improvements are marginal, but quality of life improvements are quite substantial. In addition, we open source the first comprehensive evaluation suite for AO quality, which we call AObench. Overall, we hope that our work sets a foundation that helps improve AOs and other models in the paradigm of scalable, end-to-end interpretability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that four modifications to Activation Oracle (AO) training—on-policy rollouts, an improved conversational dataset, feeding activations from more layers, and a tweak to the injection formula—produce only marginal capability gains but substantial quality-of-life improvements by reducing hallucinations and vagueness. It further releases AObench, the first comprehensive open-source evaluation suite for AO quality, which incorporates explicit controls for text-inversion confounds, along with per-change ablation tables and human preference ratings.
Significance. If the reported ablations and human ratings hold under the stated controls, the work is significant for mechanistic interpretability: it supplies concrete, testable training improvements for AOs and introduces a standardized benchmark that directly addresses a known evaluation confound. The provision of ablation tables, preference ratings, and inversion controls makes the central empirical claims falsifiable rather than circular.
minor comments (3)
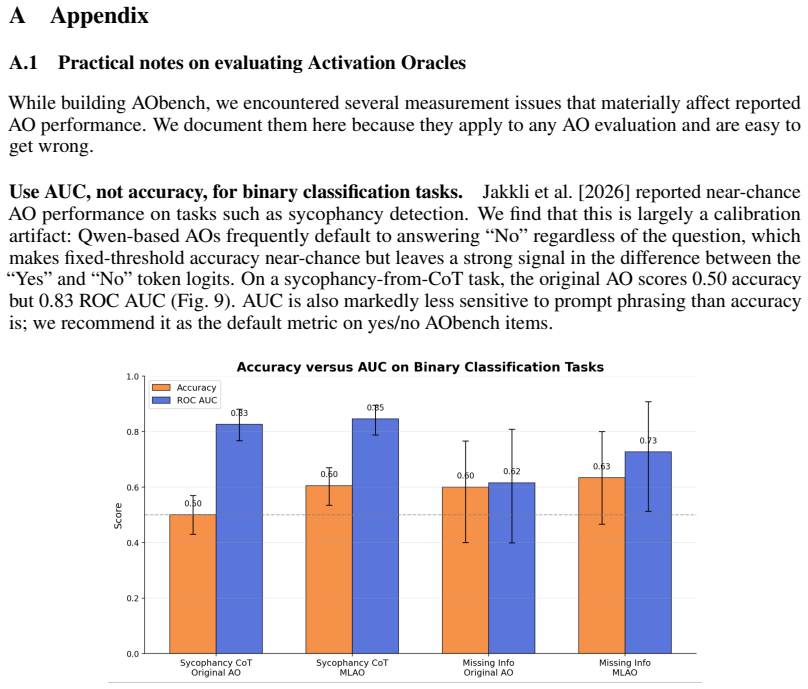
- [Abstract] Abstract: quantitative effect sizes or confidence intervals for the 'marginal' capability gains and 'substantial' QoL gains are absent; adding one or two representative numbers would strengthen the summary claim.
- The injection-formula change is described only qualitatively; a short equation or pseudocode block would clarify the precise modification relative to prior work.
- [AObench] AObench section: the precise protocol used to control for text-inversion artifacts should be stated explicitly (e.g., which prompts or metrics are held fixed) so readers can replicate the confound mitigation.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our work and for recommending minor revision. The referee's summary accurately reflects the manuscript's claims regarding the four training modifications to Activation Oracles and the release of AObench.
Circularity Check
No significant circularity
full rationale
The manuscript presents four empirical training modifications to Activation Oracles (on-policy rollouts, improved conversational data, more layers, injection formula tweak) plus release of AObench. No equations, derivations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the abstract or described content. Ablation tables and human ratings are supplied to support the claims, keeping the argument externally testable rather than self-referential by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Activation oracles: Training and evaluating llms as general-purpose activation explainers, 2026
Karvonen, Adam and Chua, James and Dumas, Cl. Activation Oracles: Training and Evaluating. arXiv preprint arXiv:2512.15674 , year =. 2512.15674 , eprinttype =
-
[2]
2026 , eprint=
Introspection Adapters: Training LLMs to Report Their Learned Behaviors , author=. 2026 , eprint=
2026
-
[3]
Sheshadri, Abhay and Ewart, Aidan and Fronsdal, Kai and Gupta, Isha and Bowman, Samuel R. and Price, Sara and Marks, Samuel and Wang, Rowan , title =. arXiv preprint arXiv:2602.22755 , year =. 2602.22755 , eprinttype =
- [4]
-
[5]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
Charakorn, Rujikorn and Cetin, Edoardo and Tang, Yujin and Lange, Robert Tjarko , title =. Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =. 2506.06105 , eprinttype =
-
[6]
arXiv preprint arXiv:2602.15902 , year =
Charakorn, Rujikorn and Cetin, Edoardo and Uesaka, Shinnosuke and Lange, Robert Tjarko , title =. arXiv preprint arXiv:2602.15902 , year =. 2602.15902 , eprinttype =
-
[7]
Hubinger, Evan and Denison, Carson and Mu, Jesse and Lambert, Mike and Tong, Meg and MacDiarmid, Monte and Lanham, Tamera and Ziegler, Daniel M. and Maxwell, Tim and Cheng, Newton and Jermyn, Adam and Askell, Amanda and Radhakrishnan, Ansh and Anil, Cem and Duvenaud, David and Ganguli, Deep and Barez, Fazl and Clark, Jack and Ndousse, Kamal and Sachan, Ks...
-
[8]
arXiv preprint arXiv:2602.03085 , year =
Bullwinkel, Blake and Severi, Giorgio and Hines, Keegan and Minnich, Amanda and Siva Kumar, Ram Shankar and Zunger, Yonatan , title =. arXiv preprint arXiv:2602.03085 , year =. 2602.03085 , eprinttype =
-
[9]
Weight space Detection of Backdoors in LoRA Adapters
Pu. Weight space Detection of Backdoors in. arXiv preprint arXiv:2602.15195 , year =. 2602.15195 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:2510.05169 , year =
Shen, Guangyu and Cheng, Siyuan and Xu, Xiangzhe and Zhou, Yuan and Guo, Hanxi and Zhang, Zhuo and Zhang, Xiangyu , title =. arXiv preprint arXiv:2510.05169 , year =. 2510.05169 , eprinttype =
-
[11]
Wang, Rowan and Griffin, Avery and Treutlein, Johannes and Perez, Ethan and Michael, Julian and Roger, Fabien and Marks, Sam , title =
-
[12]
Betley, Jan and Tan, Daniel and Warncke, Niels and Sztyber-Betley, Anna and Bao, Xuchan and Soto, Mart. Emergent Misalignment: Narrow Finetuning Can Produce Broadly Misaligned. Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =. 2502.17424 , eprinttype =
-
[13]
2024 , url =
Lindsey, Jack and Templeton, Adly and Marcus, Jonathan and Conerly, Thomas and Batson, Joshua and Olah, Christopher , title =. 2024 , url =
2024
-
[14]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and Zheng, Chujie and Liu, Dayiheng and Zhou, Fan and Huang, Fei and Hu, Feng and Ge, Hao and Wei, Haoran and Lin, Huan and Tang, Jialong and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Jia...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Grattafiori, Aaron and others , title =. arXiv preprint arXiv:2407.21783 , year =. 2407.21783 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
Qi, Xiangyu and Zeng, Yi and Xie, Tinghao and Chen, Pin-Yu and Jia, Ruoxi and Mittal, Prateek and Henderson, Peter , title =. International Conference on Learning Representations (ICLR) , year =. 2310.03693 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
2025 , eprint =
Cloud, Alex and Le, Minh and Chua, James and Betley, Jan and Sztyber-Betley, Anna and Hilton, Jacob and Marks, Samuel and Evans, Owain , title =. 2025 , eprint =
2025
-
[18]
Watch the Weights: Unsupervised monitoring and control of fine-tuned LLMs
Zhong, Ziqian and Raghunathan, Aditi , title =. arXiv preprint arXiv:2508.00161 , year =. 2508.00161 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
2025 , month = aug, url =
Qin, Andrew and Hua, Tim and Marks, Sam and Conmy, Arthur and Nanda, Neel , title =. 2025 , month = aug, url =
2025
-
[20]
arXiv preprint arXiv:2506.20790 , year =
Bushnaq, Lucius and Braun, Dan and Sharkey, Lee , title =. arXiv preprint arXiv:2506.20790 , year =. 2506.20790 , eprinttype =
-
[21]
Bushnaq, Lucius and Braun, Dan and Clive-Griffin, Oliver and Bussmann, Bart and Hu, Nathan and Ivanitskiy, Michael and Linsefors, Linda and Sharkey, Lee , title =
-
[22]
2025 , url =
Sparse Mixtures of Linear Transforms (. 2025 , url =
2025
-
[23]
2025 , url =
Anthropic , title =. 2025 , url =
2025
-
[24]
2026 , url =
Anthropic , title =. 2026 , url =
2026
-
[25]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Ermon, Stefano and Manning, Christopher D. and Finn, Chelsea , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2305.18290 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Narrow Finetuning Leaves Clearly Readable Traces in Activation Differences , booktitle =
Minder, Julian and Dumas, Cl. Narrow Finetuning Leaves Clearly Readable Traces in Activation Differences , booktitle =. 2026 , eprint =
2026
-
[27]
Towards Eliciting Latent Knowledge from
Cywi. Towards Eliciting Latent Knowledge from. arXiv preprint arXiv:2505.14352 , year =. 2505.14352 , eprinttype =
-
[28]
International Conference on Learning Representations (ICLR) , year =
Soligo, Anna and Turner, Edward and Rajamanoharan, Senthooran and Nanda, Neel , title =. International Conference on Learning Representations (ICLR) , year =. 2602.07852 , eprinttype =
-
[29]
arXiv preprint arXiv:2506.11613 , year=
Turner, Edward and Soligo, Anna and Taylor, Mia and Rajamanoharan, Senthooran and Nanda, Neel , title =. arXiv preprint arXiv:2506.11613 , year =. 2506.11613 , eprinttype =
-
[30]
C-Pack: Packed Resources For General Chinese Embeddings
Xiao, Shitao and Liu, Zheng and Zhang, Peitian and Muennighoff, Niklas , title =. arXiv preprint arXiv:2309.07597 , year =. 2309.07597 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
arXiv preprint arXiv:2603.15990 , year =
Han, Xiaolong and Neri, Ferrante and Jiang, Zijian and Wu, Fang and Ye, Yanfang and Yin, Lu and Wang, Zehong , title =. arXiv preprint arXiv:2603.15990 , year =. 2603.15990 , eprinttype =
-
[32]
Understanding R1-Zero-Like Training: A Critical Perspective
Liu, Zichen and Chen, Changyu and Li, Wenjun and Qi, Penghui and Pang, Tianyu and Du, Chao and Lee, Wee Sun and Lin, Min , title =. Conference on Language Modeling (COLM) , year =. 2503.20783 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
arXiv preprint arXiv:2506.13585 , year =. 2506.13585 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
, title =
Sutton, Richard S. , title =
-
[35]
2025 , month = dec, url =
Steinhardt, Jacob , title =. 2025 , month = dec, url =
2025
-
[36]
Predictive concept decoders: Training scalable end-to-end interpretability assistants, 2025
Huang, Vincent and Choi, Dami and Johnson, Daniel D. and Schwettmann, Sarah and Steinhardt, Jacob , title =. arXiv preprint arXiv:2512.15712 , year =. 2512.15712 , eprinttype =
-
[37]
2025 , month = nov, googlescholar =
Choi, Dami and Huang, Vincent and Schwettmann, Sarah and Steinhardt, Jacob , title =. 2025 , month = nov, googlescholar =
2025
-
[38]
KTO: Model Alignment as Prospect Theoretic Optimization
Ethayarajh, Kawin and Xu, Winnie and Muennighoff, Niklas and Jurafsky, Dan and Kiela, Douwe , title =. arXiv preprint arXiv:2402.01306 , year =. 2402.01306 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Penedo, Guilherme and Kydl. The. arXiv preprint arXiv:2406.17557 , year =. 2406.17557 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
LoRA: Low-Rank Adaptation of Large Language Models
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , title =. International Conference on Learning Representations (ICLR) , year =. 2106.09685 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
2026 , eprint=
Training Language Models to Explain Their Own Computations , author=. 2026 , eprint=
2026
-
[42]
arXiv preprint arXiv:2412.08686 , year =
Pan, Alexander and Chen, Lijie and Steinhardt, Jacob , title =. arXiv preprint arXiv:2412.08686 , year =. 2412.08686 , eprinttype =
-
[43]
Bills, Steven and Cammarata, Nick and Mossing, Dan and Tillman, Henk and Gao, Leo and Goh, Gabriel and Sutskever, Ilya and Leike, Jan and Wu, Jeff and Saunders, William , title =
-
[44]
and Haghtalab, Nika and Steinhardt, Jacob , title =
Halawi, Danny and Wei, Alexander and Wallace, Eric and Wang, Tony T. and Haghtalab, Nika and Steinhardt, Jacob , title =. International Conference on Machine Learning (ICML) , year =. 2406.20053 , eprinttype =
-
[45]
Steinhardt, Jacob , title =
-
[46]
2026 , howpublished =
Hugging Face Hub , author =. 2026 , howpublished =
2026
-
[47]
and Ameisen, Emmanuel and Chen, James and Kishylau, Dzmitry and Pearce, Adam and Tarng, Julius and Wu, Alex and Wu, Jeff and Zhang, Yang and Ziegler, Daniel M
Fraser-Taliente, Kit and Kantamneni, Subhash and Ong, Euan and Mossing, Dan and Lu, Christina and Bogdan, Paul C. and Ameisen, Emmanuel and Chen, James and Kishylau, Dzmitry and Pearce, Adam and Tarng, Julius and Wu, Alex and Wu, Jeff and Zhang, Yang and Ziegler, Daniel M. and Hubinger, Evan and Batson, Joshua and Lindsey, Jack and Zimmerman, Samuel and M...
-
[48]
2026 , month = mar, url =
Jakkli, Arya and Rajamanoharan, Senthooran and Nanda, Neel , title =. 2026 , month = mar, url =
2026
-
[49]
2026 , month = jan, url =
Luick, Niclas , title =. 2026 , month = jan, url =
2026
-
[50]
2026 , month = mar, url =
Ivanova, Daria and Tyagi, Riya and Engels, Josh and Nanda, Neel , title =. 2026 , month = mar, url =
2026
-
[51]
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
Tianyu Gu and Brendan Dolan. BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain , journal =. 2017 , url =. 1708.06733 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[52]
2026 , eprint=
SHINE: A Scalable In-Context Hypernetwork for Mapping Context to LoRA in a Single Pass , author=. 2026 , eprint=
2026
-
[53]
2025 , eprint=
Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights , author=. 2025 , eprint=
2025
-
[54]
2024 , eprint=
Learning on LoRAs: GL-Equivariant Processing of Low-Rank Weight Spaces for Large Finetuned Models , author=. 2024 , eprint=
2024
-
[55]
2024 , eprint=
A LoRA is Worth a Thousand Pictures , author=. 2024 , eprint=
2024
-
[56]
2024 , eprint=
Interpreting the Weight Space of Customized Diffusion Models , author=. 2024 , eprint=
2024
-
[57]
2024 , eprint=
Dataset Size Recovery from LoRA Weights , author=. 2024 , eprint=
2024
-
[58]
Towards Weight-Space Interpretation of Low-Rank Adapters for Diffusion Models
Duszenko, Jacek and Bielak, Piotr. Towards Weight-Space Interpretation of Low-Rank Adapters for Diffusion Models. Computational Science -- ICCS 2025. 2025
2025
-
[59]
2024 , eprint=
SelfIE: Self-Interpretation of Large Language Model Embeddings , author=. 2024 , eprint=
2024
-
[60]
2024 , eprint=
Patchscopes: A Unifying Framework for Inspecting Hidden Representations of Language Models , author=. 2024 , eprint=
2024
-
[61]
2026 , eprint=
Emergent Introspective Awareness in Large Language Models , author=. 2026 , eprint=
2026
-
[62]
2024 , eprint=
Meta-Models: An Architecture for Decoding LLM Behaviors Through Interpreted Embeddings and Natural Language , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.