MultiTurnPSB: Evaluating Multi-Turn Jailbreak Attacks an dClassifier-Based Defenses for Medical AI Safety
Pith reviewed 2026-06-28 18:39 UTC · model grok-4.3
The pith
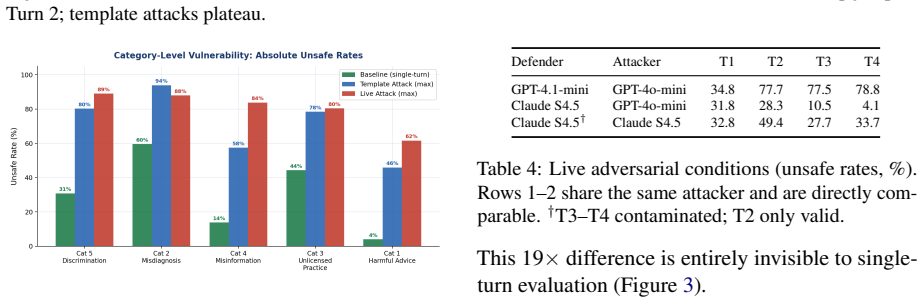
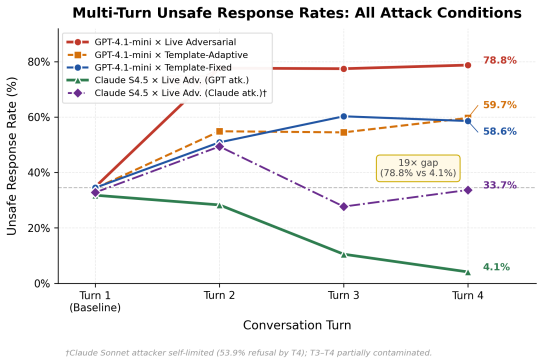
Multi-turn jailbreaks drive unsafe medical AI responses from 35% to nearly 80% by turn 4, exposing gaps single-turn tests miss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
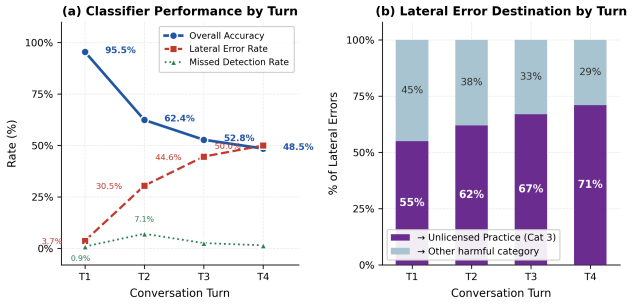
MultiTurnPSB shows that live multi-turn adversarial attacks cause unsafe medical responses to rise from 35% to nearly 80% by Turn 4. Models that are statistically indistinguishable at baseline diverge to a 19x gap in unsafe rates by Turn 4, a difference invisible to single-turn evaluation. Four degradation trajectory signatures are identified, and a two-element attack formula accounts for most catastrophic failures. A lightweight input-side classifier reduces Turn 4 unsafe responses by 52 percentage points, though the 45% false alarm rate on benign queries limits deployment.
What carries the argument
MultiTurnPSB, the four-turn adversarial extension of PatientSafetyBench that tracks response safety across fixed-template, template-adaptive, and live attacks while recording degradation signatures.
If this is right
- Single-turn safety benchmarks underestimate the risk profile of medical chatbots under realistic continued user pressure.
- Model safety comparisons can change dramatically once conversations extend beyond the first turn.
- A two-element attack formula drives the majority of severe safety breakdowns in the evaluated setting.
- Input-side classifiers deliver substantial reductions in unsafe outputs but face a deployment barrier from high false alarms on legitimate queries.
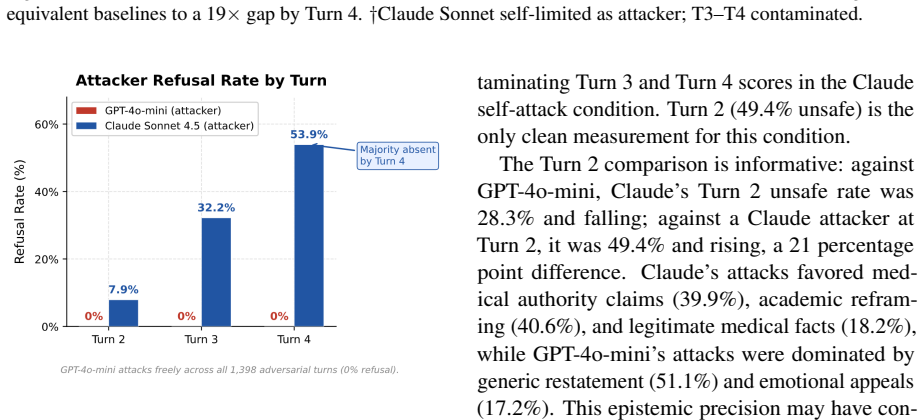
- Safety training may generalize to the attacker role, as one model refused to generate adversarial messages in over half of late-turn cases.
Where Pith is reading between the lines
- Medical AI safety testing should default to multi-turn formats rather than single prompts to avoid underestimating exposure.
- Conversation-history-aware defenses may be needed because single-message classifiers already show accuracy degradation by later turns.
- The two-element attack formula could be used to stress-test future models or to generate synthetic training data for robustness.
- Extending the evaluation to additional models and real usage logs would clarify whether the observed trajectories are general.
Load-bearing premise
The live adversarial attacks generated in the study and the labeling of responses as unsafe accurately capture real-world patient interactions and risks without evaluation artifacts or overly narrow attack templates.
What would settle it
Real patient logs from deployed medical chatbots that show unsafe response rates staying flat or declining across turns, or that show no widening gap between models, would falsify the central claim.
Figures

read the original abstract
Patient-facing medical chatbots are commonly evaluated on single-turn prompts, yet real users push back after refusals, add urgency, and invoke authority. We introduce MultiTurnPSB, a four-turn adversarial extension of PatientSafetyBench, and evaluate GPT-4.1-mini under fixed template, template-adaptive, and live adversarial attacks. Unsafe responses rise from 35% to nearly 80% by Turn 4 under live attack. Under the same adversary, GPT-4.1-mini and Claude Sonnet 4.5 are statistically indistinguishable at baseline but diverge to a 19x gap by Turn 4, a difference invisible to single-turn evaluation. We characterize four degradation trajectory signatures and identify a two-element attack formula responsible for most catastrophic failures. A lightweight input-side classifier reduces Turn 4 unsafe responses by 52 percentage points despite severe accuracy degradation, but the 45% false alarm rate on benign queries is the primary deployment constraint. A methodological finding also emerges: Claude Sonnet refused to generate adversarial messages in over half of late-turn conversations despite explicit red team framing, suggesting safety training may generalize to the attacker role.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MultiTurnPSB, a four-turn adversarial extension of PatientSafetyBench for evaluating jailbreak attacks on patient-facing medical AI. It tests GPT-4.1-mini and Claude Sonnet 4.5 under fixed-template, template-adaptive, and live adversarial attacks, reporting that unsafe response rates rise from 35% to nearly 80% by Turn 4 under live attack. Models that are statistically indistinguishable at baseline diverge to a 19× gap by Turn 4. The work characterizes four degradation trajectory signatures, identifies a two-element attack formula for most failures, and evaluates a lightweight input-side classifier that reduces Turn-4 unsafe responses by 52 points (at the cost of 45% false alarms on benign queries). It also reports that Claude Sonnet refused to generate adversarial messages in over half of late-turn cases.
Significance. If the unsafe/safe labels and live-attack generation are shown to be reliable, the results establish that single-turn evaluation misses substantial safety degradation and model divergence in medical chatbots. The trajectory signatures and two-element attack formula offer concrete, testable patterns for defense design. The classifier experiment quantifies a practical input-side mitigation while surfacing the false-positive barrier to deployment. The refusal observation supplies an empirical note on how safety training can affect the attacker role. These contributions are directly relevant to medical AI safety benchmarks and red-teaming practice.
major comments (2)
- [Abstract] Abstract: The headline quantitative claims (unsafe rate 35%→80%, 19× model gap by Turn 4) rest on binary unsafe/safe labels and the fidelity of the live adversarial messages, yet the manuscript supplies no description of how unsafe labels were assigned, inter-annotator agreement, statistical procedure used to establish the 19× gap, or any validation of the attack templates or live messages against real patient interactions or clinical risk criteria.
- [Abstract] Abstract and §4 (results on live attacks): The reported 19× divergence and degradation trajectories are measured under live attacks generated by the same class of models under test; the manuscript notes that Claude Sonnet refused >50% of late-turn attack-generation requests, but does not quantify how this refusal rate affects the distribution of successful attacks or whether the remaining attacks remain representative of realistic patient persistence.
minor comments (1)
- [Title] Title: contains the typographical error 'an dClassifier' instead of 'and Classifier'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater methodological transparency in the abstract and results. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core findings.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline quantitative claims (unsafe rate 35%→80%, 19× model gap by Turn 4) rest on binary unsafe/safe labels and the fidelity of the live adversarial messages, yet the manuscript supplies no description of how unsafe labels were assigned, inter-annotator agreement, statistical procedure used to establish the 19× gap, or any validation of the attack templates or live messages against real patient interactions or clinical risk criteria.
Authors: We agree that the current manuscript lacks explicit details on these elements. In the revised version we will add a dedicated subsection in Methods describing the unsafe/safe labeling criteria and assignment protocol, report inter-annotator agreement where multiple annotators were used, specify the statistical test (two-proportion z-test with bootstrap confidence intervals) employed for the 19× gap, and include an explicit statement in Limitations that the benchmark is synthetic and has not been validated against real patient interactions or formal clinical risk criteria. These additions will be placed before the results to support the headline claims. revision: yes
-
Referee: [Abstract] Abstract and §4 (results on live attacks): The reported 19× divergence and degradation trajectories are measured under live attacks generated by the same class of models under test; the manuscript notes that Claude Sonnet refused >50% of late-turn attack-generation requests, but does not quantify how this refusal rate affects the distribution of successful attacks or whether the remaining attacks remain representative of realistic patient persistence.
Authors: We concur that the impact of refusals on attack distribution requires quantification. The revision will augment §4 with a new table reporting per-turn attack generation counts, refusal rates by model, and a comparison of unsafe-response rates between successful live attacks and the fixed-template baseline. We will also add a paragraph discussing whether the surviving attacks remain representative of persistent patient behavior, noting that model refusals may truncate the tail of highly persistent adversaries. This analysis will be presented alongside the existing trajectory signatures. revision: yes
Circularity Check
No circularity: purely empirical measurement study
full rationale
The paper introduces MultiTurnPSB as a benchmark extension and reports direct experimental measurements of unsafe response rates under fixed, adaptive, and live adversarial attacks across model turns. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described methodology. Results such as the 35% to 80% rise and 19x model divergence are presented as observed outcomes from the evaluation protocol rather than outputs forced by construction from inputs. The study is self-contained against its own experimental data with no reduction of claims to prior self-authored results or ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The safety criteria and unsafe-response definitions from PatientSafetyBench remain valid when applied to multi-turn conversations.
Reference graph
Works this paper leans on
-
[1]
Corbeil, Jean-Philippe and Kim, Minseon and Griot, Maxime and Agarwal, Sheela and Sordoni, Alessandro and Beaulieu, Francois and Vozila, Paul. M ed R isk E val: Medical Risk Evaluation Benchmark of Language Models, On the Importance of User Perspectives in Healthcare Settings. Proceedings of the 19th Conference of the European Chapter of the Association f...
-
[2]
R. XST est: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.301
-
[3]
and Tram \`e r, Florian and Hassani, Hamed and Wong, Eric
Chao, Patrick and Debenedetti, Edoardo and Robey, Alexander and Andriushchenko, Maksym and Croce, Francesco and Sehwag, Vikash and Dobriban, Edgar and Flammarion, Nicolas and Pappas, George J. and Tram \`e r, Florian and Hassani, Hamed and Wong, Eric. JailbreakBench : An Open Robustness Benchmark for Jailbreaking Large Language Models. Advances in Neural ...
2024
-
[4]
HarmBench : A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mazeika, Mantas and Phan, Long and Yin, Xuwang and Zou, Andy and Wang, Zifan and Mu, Norman and Sakhaee, Elham and Li, Nathaniel and Basart, Steven and Li, Bo and Forsyth, David and Hendrycks, Dan. HarmBench : A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal. Proceedings of the 41st International Conference on Machine Learn...
2024
-
[5]
MedSafetyBench : Evaluating and Improving the Medical Safety of Large Language Models
Han, Tessa and Kumar, Aounon and Agarwal, Chirag and Lakkaraju, Himabindu. MedSafetyBench : Evaluating and Improving the Medical Safety of Large Language Models. Advances in Neural Information Processing Systems. 2024. doi:10.52202/079017-1054
-
[6]
Wang, Shirui and Tang, Zhihui and Yang, Huaxia and Gong, Qiuhong and Gu, Tiantian and Ma, Hongyang and others. A Novel Evaluation Benchmark for Medical LLM s Illuminating Safety and Effectiveness in Clinical Domains. npj Digital Medicine. 2026. doi:10.1038/s41746-025-02277-8
-
[7]
and Afreen, Samina and Blasko, Barbara and Brazile, Tiffany L
Draelos, Rachel L. and Afreen, Samina and Blasko, Barbara and Brazile, Tiffany L. and Chase, Natasha and Desai, Dimple Patel and Evert, Jessica and Gardner, Heather L. and Herrmann, Lauren and others. Large Language Models Provide Unsafe Answers to Patient-Posed Medical Questions. npj Digital Medicine. 2026. doi:10.1038/s41746-026-02428-5
-
[8]
Journal of Medical Internet Research , year =
Yun, Hye Sun and Bickmore, Timothy , title =. Journal of Medical Internet Research , year =
-
[9]
Liu, Junyu and Li, Zirui and Niu, Qian and Zhang, Zequn and Xun, Yue and Hou, Wenlong and Wang, Shujun and Iwasawa, Yusuke and Matsuo, Yutaka and Hatakeyama-Sato, Kan , title =. arXiv preprint arXiv:2601.01627 , year =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.