Representational Capacity: Geometric Limits on Feature Representation in Transformer Language Models
Pith reviewed 2026-06-28 15:57 UTC · model grok-4.3
The pith
Transformer models can represent only a limited number of near-orthogonal feature directions, bounded by deviation from orthogonality in their embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
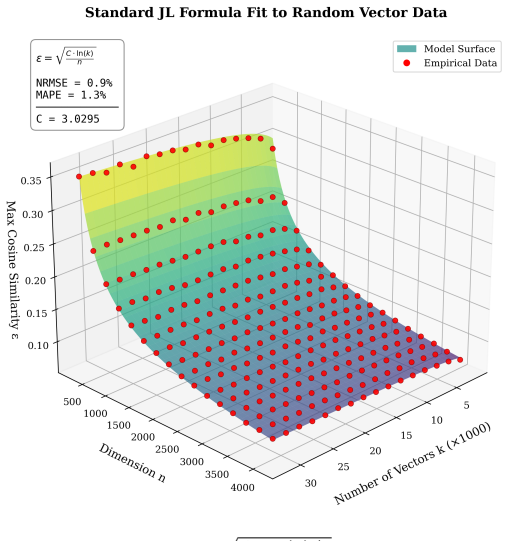
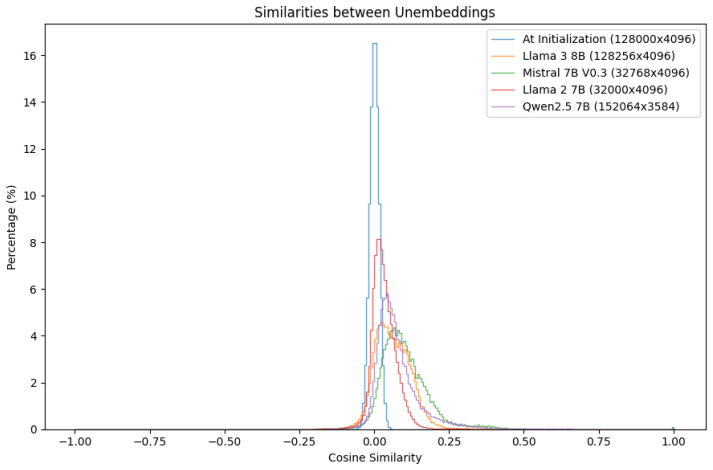
We define representational capacity as an upper bound on the number of distinguishable directions available for features and embeddings in a model's latent space. Capacity is exponentially sensitive to ε, and larger models favor tighter orthogonality constraints over maximizing raw capacity. The estimate comes from first measuring ε via the embedding matrix and then replacing the standard Johnson-Lindenstrauss bound with a version that depends on the observed k/d ratio.
What carries the argument
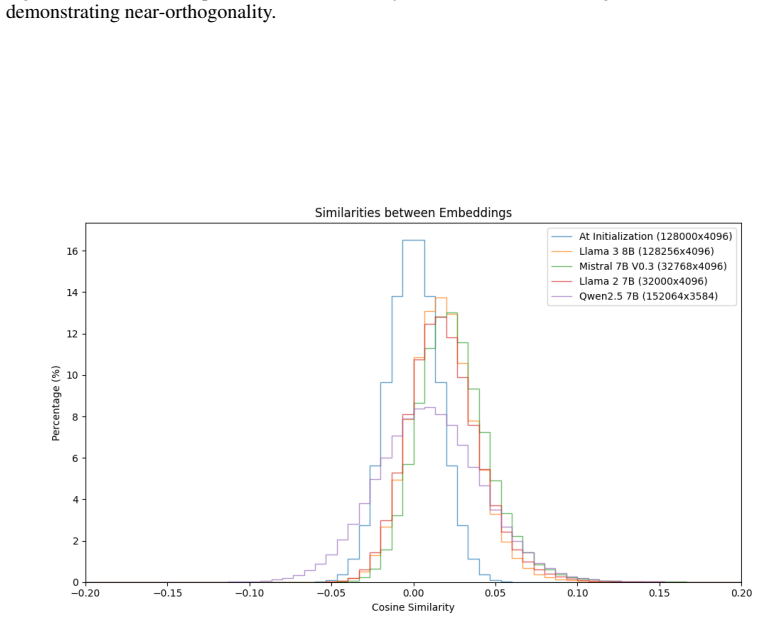
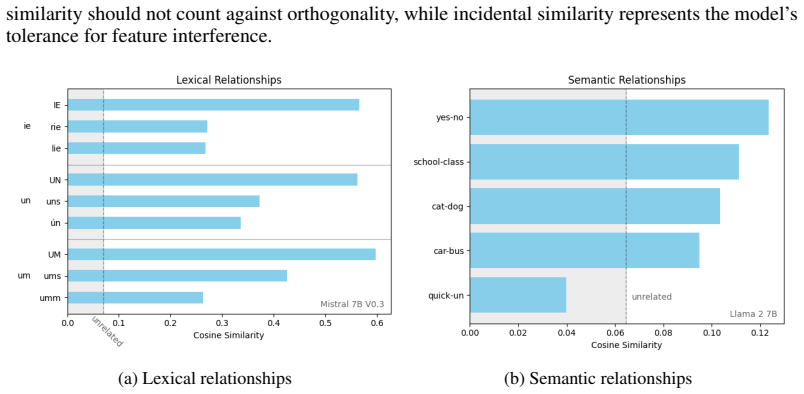
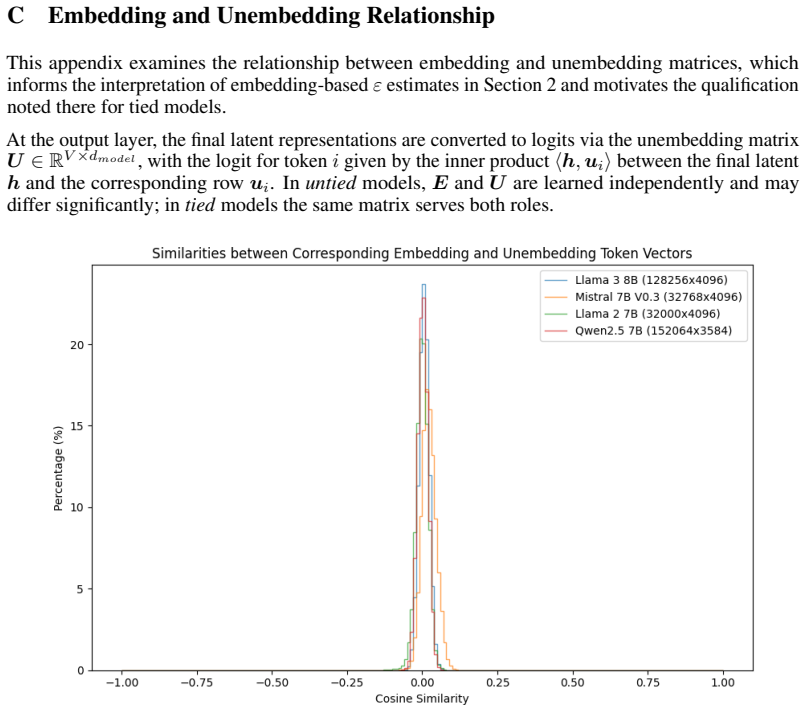
The embedding matrix as proxy for near-orthogonality constraints, supplying ε from the boundary in the pairwise cosine similarity distribution between meaningful token relationships and incidental similarity.
If this is right
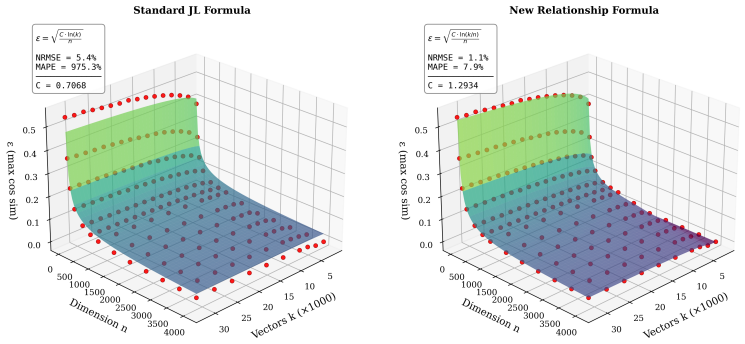
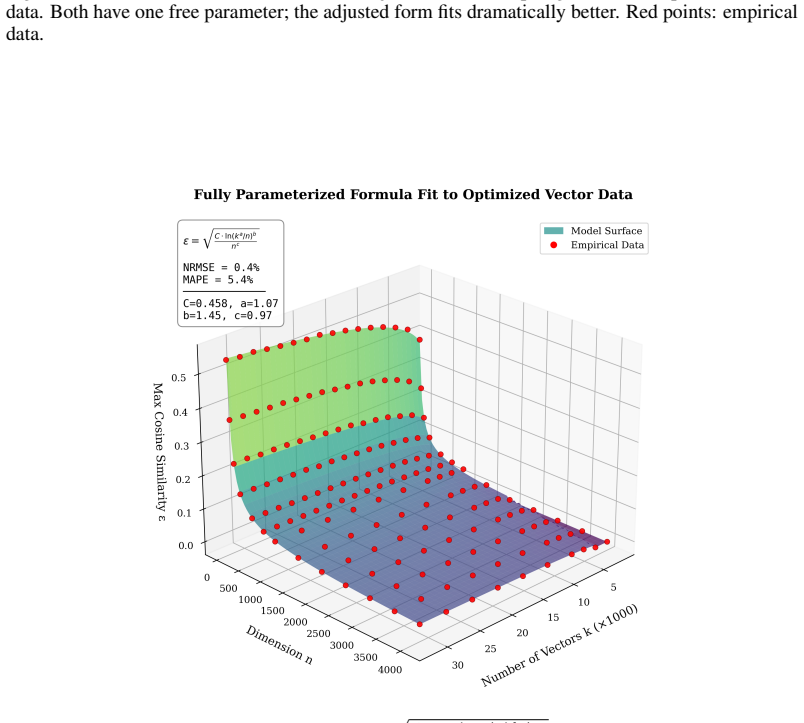
- The adjusted capacity formula that incorporates the k/d ratio cuts prediction error by two orders of magnitude compared with the standard Johnson-Lindenstrauss lemma.
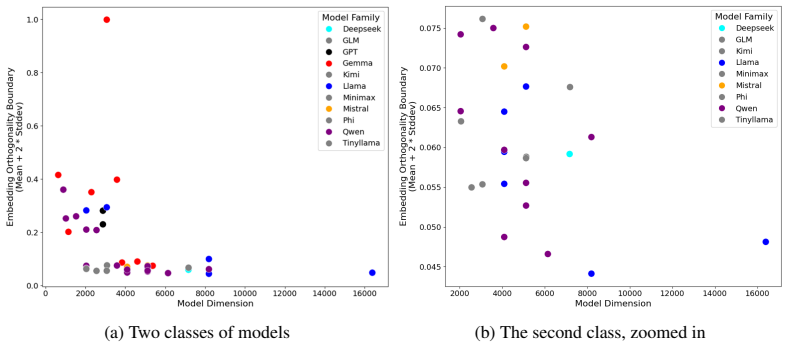
- Models fall into two classes: those with high ε whose embeddings lack near-orthogonal structure and those with low ε that maintain it.
- Larger models enforce tighter orthogonality constraints instead of increasing the raw number of directions.
- Capacity depends exponentially on the model's accepted deviation ε from perfect orthogonality.
Where Pith is reading between the lines
- The observed preference for tighter constraints in larger models may arise from a stability-capacity trade-off during training.
- The same ε measurement could be applied to other weight matrices to test whether the orthogonality bound is uniform across the network.
- If the capacity bound is tight, it would predict a ceiling on the number of independent concepts usable in any single forward pass independent of further scaling.
Load-bearing premise
The pairwise cosine similarity distribution in the embedding matrix accurately reflects the deviation from orthogonality that applies across the model's full latent space.
What would settle it
Count the number of linearly recoverable, distinguishable features via probing on model activations for a given model and check whether that count matches the representational capacity predicted from its measured ε and d_model.
Figures

read the original abstract
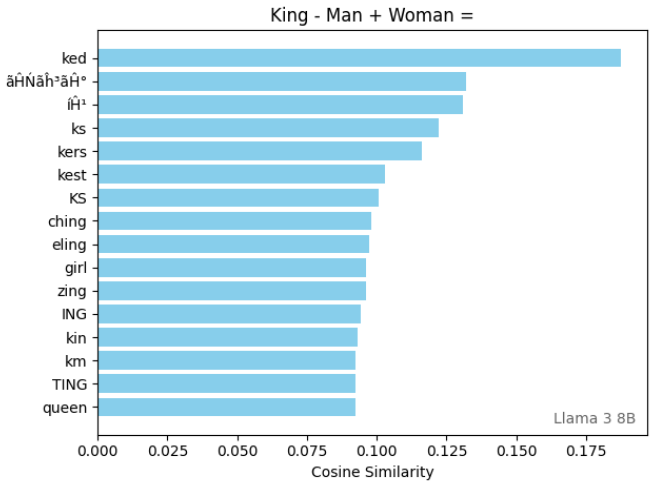
Model dimension ($d_{model}$) is a fundamental hyperparameter in transformer language models, yet its role in setting the geometric limits of feature representation remains under-explored. Grounded in the Linear Representation and Superposition Hypotheses - which propose that models encode features as near-orthogonal directions in latent space - we develop a framework for estimating how many such directions a model can support. We first establish the embedding matrix as a measurable proxy for near-orthogonality constraints across the latent space: the boundary between meaningful token relationships and incidental similarity in the pairwise cosine similarity distribution gives a concrete estimate of the model's accepted deviation $\varepsilon$ from perfect orthogonality. Applying this metric across dozens of open-source models reveals two classes: models with high $\varepsilon$ whose embeddings lack near-orthogonal structure, and models with low $\varepsilon$ that maintain it. We then show that the standard Johnson-Lindenstrauss lemma greatly underestimates the packing efficiency of trained representations, and derive an adjusted capacity formula in which the number of near-orthogonal directions depends on the ratio of vectors to dimensions ($k/d$) rather than the raw count - a single modification that cuts prediction error by two orders of magnitude with no extra parameters. Combining these results, we define representational capacity as an upper bound on the number of distinguishable directions available for features and embeddings in a model's latent space. Capacity is exponentially sensitive to $\varepsilon$, and larger models favor tighter orthogonality constraints over maximizing raw capacity - a pattern compatible with several explanations (a stability-capacity trade-off, a ceiling on usable concepts, or confounds with model scale) that we leave to future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the embedding matrix of transformer language models serves as a measurable proxy for near-orthogonality constraints in latent space, with the boundary in pairwise cosine similarity distributions providing an estimate of deviation ε from perfect orthogonality. It classifies models into high- and low-ε regimes, shows that the Johnson-Lindenstrauss lemma underestimates packing efficiency, derives an adjusted capacity formula depending on the observed k/d ratio that reduces prediction error by two orders of magnitude, and defines representational capacity as an exponentially ε-sensitive upper bound on distinguishable directions, with larger models favoring tighter orthogonality.
Significance. If the central claims hold, the work supplies a quantitative geometric account of feature representation limits grounded in the linear representation and superposition hypotheses, potentially explaining scaling patterns and providing a new analysis tool for model capacity. The reported error reduction without added parameters would be a substantial empirical advance if independently verifiable.
major comments (3)
- [Embedding matrix as measurable proxy] The section establishing the embedding matrix as proxy: the boundary in the embedding matrix pairwise cosine similarity distribution is taken as ε for the full latent space, yet no derivation or measurement demonstrates that this ε governs minimum angles between directions in post-attention or post-MLP hidden states; linear and nonlinear maps can alter angular structure, so the proxy does not automatically extend to feature directions.
- [Adjusted capacity formula] Derivation of the adjusted capacity formula: the formula is stated to depend on the observed k/d ratio and ε is extracted directly from the same embedding matrix under study; both the deviation parameter and the packing adjustment are therefore defined in terms of quantities measured from the data the capacity bound is intended to explain, creating a circularity risk for the central claim.
- [Empirical evaluation] Empirical results across dozens of models: the abstract asserts a two-order-of-magnitude error reduction and classification into two model classes, but the provided text supplies no equations, data tables, exclusion criteria, or error analysis, preventing verification that the adjusted formula is robust rather than overfit to the measured quantities.
minor comments (1)
- [Abstract] The abstract would benefit from including the key equations for the adjusted capacity formula and the definition of ε to make the central claims more self-contained.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment below with clarifications and indicate revisions to strengthen the work where appropriate.
read point-by-point responses
-
Referee: [Embedding matrix as measurable proxy] The section establishing the embedding matrix as proxy: the boundary in the embedding matrix pairwise cosine similarity distribution is taken as ε for the full latent space, yet no derivation or measurement demonstrates that this ε governs minimum angles between directions in post-attention or post-MLP hidden states; linear and nonlinear maps can alter angular structure, so the proxy does not automatically extend to feature directions.
Authors: The embedding matrix provides the initial directions in latent space under the linear representation hypothesis, with the observed similarity boundary serving as a measurable proxy for ε. We agree that explicit checks are needed to confirm this extends through the network. In revision we will add direct measurements of pairwise cosine similarities from post-attention and post-MLP activations on a representative subset of models to quantify how well the embedding-derived ε predicts angular structure deeper in the network. revision: yes
-
Referee: [Adjusted capacity formula] Derivation of the adjusted capacity formula: the formula is stated to depend on the observed k/d ratio and ε is extracted directly from the same embedding matrix under study; both the deviation parameter and the packing adjustment are therefore defined in terms of quantities measured from the data the capacity bound is intended to explain, creating a circularity risk for the central claim.
Authors: The k/d ratio is an architectural and training observable independent of the capacity bound itself, while ε is extracted from the empirical similarity distribution as the model's tolerated deviation. The adjusted formula applies a theoretically motivated modification to the Johnson-Lindenstrauss packing term using this ratio; we evaluate its predictive accuracy on held-out models and alternative metrics to demonstrate it is not merely fitting the same data. This empirical calibration improves the bound without introducing free parameters beyond the observed quantities. revision: no
-
Referee: [Empirical evaluation] Empirical results across dozens of models: the abstract asserts a two-order-of-magnitude error reduction and classification into two model classes, but the provided text supplies no equations, data tables, exclusion criteria, or error analysis, preventing verification that the adjusted formula is robust rather than overfit to the measured quantities.
Authors: The complete manuscript contains the explicit equations for the adjusted capacity formula, full data tables for all evaluated models, model selection and exclusion criteria, and quantitative error comparisons between the standard and adjusted formulas. These support the reported error reduction and the high-ε versus low-ε classification. We will ensure these sections are clearly presented and cross-referenced in the revised version to facilitate independent verification. revision: partial
Circularity Check
Representational capacity defined via ε and k/d measured directly from the embedding matrices under study
specific steps
-
fitted input called prediction
[Abstract]
"We first establish the embedding matrix as a measurable proxy for near-orthogonality constraints across the latent space: the boundary between meaningful token relationships and incidental similarity in the pairwise cosine similarity distribution gives a concrete estimate of the model's accepted deviation ε from perfect orthogonality."
ε is obtained by inspecting the pairwise cosine distribution of the embedding matrix of the very models whose latent-space capacity is being computed; the measured ε is then inserted into the capacity formula, so the bound is constructed from a statistic of the input data.
-
fitted input called prediction
[Abstract]
"derive an adjusted capacity formula in which the number of near-orthogonal directions depends on the ratio of vectors to dimensions (k/d) rather than the raw count - a single modification that cuts prediction error by two orders of magnitude with no extra parameters."
The adjustment that makes capacity depend on observed k/d is selected because it reduces error on the same collection of models; the 'derived' formula is therefore a fit to the measured k/d statistics rather than an independent geometric result.
full rationale
The paper measures ε from the cosine-similarity boundary in each model's own embedding matrix and adjusts the packing formula to depend on the observed k/d ratio in those same matrices; the resulting capacity is then presented as an upper bound on directions in the latent space. Both the deviation parameter and the functional adjustment are therefore extracted from the identical data the capacity is claimed to bound, reducing the central definition to a re-expression of the input measurements.
Axiom & Free-Parameter Ledger
free parameters (1)
- ε
axioms (1)
- domain assumption Linear Representation Hypothesis and Superposition Hypothesis
Reference graph
Works this paper leans on
-
[1]
2022 , journal =
Toy Models of Superposition , author =. 2022 , journal =
2022
-
[2]
Proceedings of the 2013 Conference of the North
Linguistic Regularities in Continuous Space Word Representations , author =. Proceedings of the 2013 Conference of the North. 2013 , address =
2013
-
[3]
2025 , month =
Beyond Orthogonality: How Language Models Pack Billions of Concepts into 12,000 Dimensions , author =. 2025 , month =
2025
-
[4]
Johnson and Joram Lindenstrauss
Johnson, William B. and Lindenstrauss, Joram , editor =. Extensions of. Conference in modern analysis and probability (New Haven, Conn., 1982) , series =. 1984 , publisher =. doi:10.1090/conm/026/737400 , mrclass =
-
[5]
2020 , eprint =
Scaling Laws for Neural Language Models , author =. 2020 , eprint =
2020
-
[6]
2025 , eprint =
Over-Tokenized Transformer: Vocabulary is Generally Worth Scaling , author =. 2025 , eprint =
2025
-
[7]
2023 , eprint =
Representational Strengths and Limitations of Transformers , author =. 2023 , eprint =
2023
-
[8]
2025 , eprint =
nGPT: Normalized Transformer with Representation Learning on the Hypersphere , author =. 2025 , eprint =
2025
-
[9]
2020 , month =
nostalgebraist , title =. 2020 , month =
2020
-
[10]
2025 , eprint =
Emergence of a High-Dimensional Abstraction Phase in Language Transformers , author =. 2025 , eprint =
2025
-
[11]
2023 , eprint =
The geometry of hidden representations of large transformer models , author =. 2023 , eprint =
2023
-
[12]
2023 , eprint =
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author =. 2023 , eprint =
2023
-
[13]
2024 , journal =
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author =. 2024 , journal =
2024
-
[14]
2024 , eprint =
The Linear Representation Hypothesis and the Geometry of Large Language Models , author =. 2024 , eprint =
2024
-
[15]
2017 , eprint =
Adam: A Method for Stochastic Optimization , author =. 2017 , eprint =
2017
-
[16]
2025 , eprint =
On the Theoretical Limitations of Embedding-Based Retrieval , author =. 2025 , eprint =
2025
-
[17]
2014 , eprint =
Representation Learning: A Review and New Perspectives , author =. 2014 , eprint =
2014
-
[18]
Distill , year =
Olah, Chris and Cammarata, Nick and Schubert, Ludwig and Goh, Gabriel and Petrov, Michael and Carter, Shan , title =. Distill , year =
-
[19]
2024 , eprint =
DeepSeek-V3 Technical Report , author =. 2024 , eprint =
2024
-
[20]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving Open Language Models at a Practical Size , author =. arXiv preprint arXiv:2408.00118 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
GLM-4: All Tools Integrated , author =. arXiv preprint arXiv:2406.12793 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
2025 , howpublished =
GPT OSS: Open Source Generative Pre-trained Transformers , author =. 2025 , howpublished =
2025
-
[23]
2024 , howpublished =
Moonshot AI: Kimi Intelligent Assistant , author =. 2024 , howpublished =
2024
-
[24]
The Llama 3 Herd of Models , author =. arXiv preprint arXiv:2407.21783 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
2025 , howpublished =
MiniMax M2 , author =. 2025 , howpublished =
2025
-
[26]
Mistral 7B , author =. arXiv preprint arXiv:2310.06825 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone , author =. arXiv preprint arXiv:2404.14219 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Qwen2 Technical Report , author =. arXiv preprint arXiv:2407.10671 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
TinyLlama: An Open-Source Small Language Model
TinyLlama: An Open-Source Small Language Model , author =. arXiv preprint arXiv:2401.02385 , year =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.