Scaling Laws for Neural-Network Quantum States
Pith reviewed 2026-06-28 11:28 UTC · model grok-4.3
The pith
Transformer wave functions for quantum spin models improve in accuracy as a power law with training compute.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
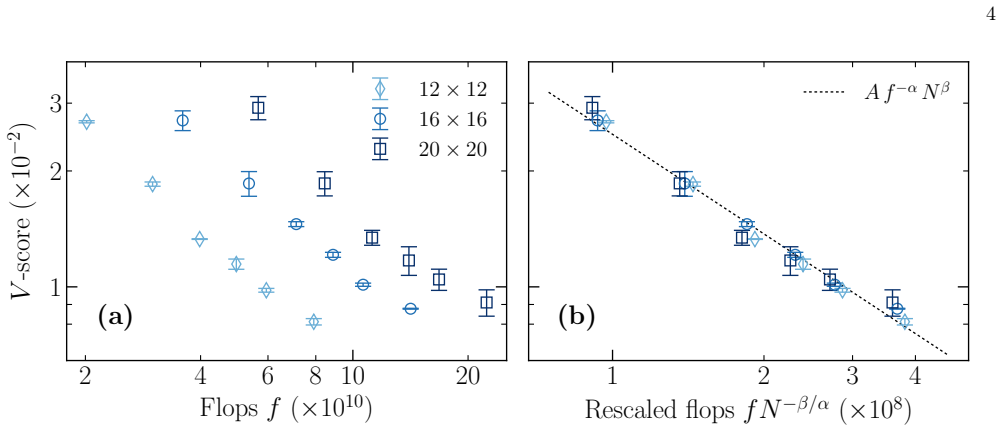
Transformer wave functions approximate ground states of the J1-J2 Heisenberg model on lattices with up to 20 by 20 sites. The V-score decays as a power law in training compute, with results for different system sizes collapsing onto one curve after rescaling compute. The power law is approximately independent of the number of sites, and its exponent decreases with frustration, quantifying the representational difficulty of the ground state.
What carries the argument
The V-score, a measure of accuracy of a variational state, which decays as a power law in training compute with data collapse under rescaling.
If this is right
- The transformer Ansatz is size-consistent for the systems considered.
- The exponent of the power law serves as a quantitative measure of representational difficulty.
- Scaling laws provide a framework for benchmarking different variational ansatze against one another.
- Additional training compute improves accuracy at a rate set by the exponent, largely independent of lattice size.
Where Pith is reading between the lines
- The same scaling analysis could be applied to other variational architectures to compare their efficiency on the same physical models.
- The dependence of the exponent on frustration may connect to physical features such as entanglement structure or the sign problem.
- Extending the study to three-dimensional lattices or to models with longer-range interactions would test whether the size-independence persists.
Load-bearing premise
The observed power-law scaling, data collapse, and frustration dependence are not artifacts of the particular transformer architecture, optimization schedule, or definition of the V-score.
What would settle it
A clear deviation from power-law decay or failure of data collapse when repeating the calculations with a different neural-network architecture or optimization method would falsify the generality of the scaling.
Figures




read the original abstract
Scaling laws, the power-law relations between loss, architecture size, and compute observed in modern neural networks, offer a quantitative way to characterize the complexity of a learning problem, with the exponent governing the decay of the loss reflecting how rapidly additional resources translate into improved accuracy, and thus how hard the target is to learn. Whether an analogous framework can characterize the complexity of physical problems remains open. We address this question for Neural-Network Quantum States, a leading variational approach for strongly correlated quantum many-body systems. Using transformer wave functions to approximate ground states of the $J_1$-$J_2$ Heisenberg model on triangular and square lattices with up to $20\times 20$ sites, we find that the $V$-score, a measure of accuracy of a variational state, decays as a power law in training compute. Under an appropriate rescaling of compute, results for different system sizes collapse onto a single curve, analogous to scaling collapse in critical phenomena. The resulting power law is, to a good approximation, independent of the number of sites, showing that the transformer Ansatz is size-consistent for the systems considered. The exponent decreases systematically with frustration, identifying it as a quantitative measure of representational difficulty of the ground state and establishing scaling laws as a general framework for benchmarking variational ans\"{a}tze.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports empirical observations using transformer-based neural-network quantum states to approximate ground states of the J1-J2 Heisenberg model on square and triangular lattices (up to 20x20 sites). It finds that the V-score decays as a power law in training compute, that results for different system sizes collapse onto a single curve under appropriate compute rescaling, that the power law is approximately independent of system size, and that the fitted exponent decreases systematically with increasing frustration. These are presented as establishing scaling laws as a general framework for benchmarking variational ansätze and quantifying representational difficulty of ground states.
Significance. If the reported power-law scaling, size collapse, and frustration dependence prove robust, they would offer a quantitative, resource-based diagnostic for the difficulty of variational ground-state approximation in quantum many-body systems, analogous to scaling laws in machine learning. The size-consistency observation and the link between exponent and frustration could help compare ansätze and identify regimes where additional compute yields diminishing returns.
major comments (2)
- [Abstract] Abstract: The claim that the exponent 'identifies it as a quantitative measure of representational difficulty of the ground state' and that the results establish 'scaling laws as a general framework for benchmarking variational ansätze' rests on the assumption that the observed scaling and frustration dependence are properties of the learning problem rather than the specific transformer architecture; all reported results use only transformer wave functions, with no ablations or comparisons to other NNQS forms (e.g., RBM, CNN, or MLP) described, which is load-bearing for the generality interpretation.
- [Methods] Methods (implied by abstract description of fits and collapse): No information is provided on error bars for V-score values, number of independent runs per data point, criteria for excluding optimization trajectories, or robustness checks against hyperparameter variation and optimizer stochasticity; without these, the reliability of the claimed power-law exponents and data collapse cannot be assessed.
minor comments (1)
- [Abstract] Abstract: The range of system sizes entering the collapse analysis is not stated explicitly (only the maximum 20x20 is given), which would help readers evaluate the collapse claim.
Simulated Author's Rebuttal
We thank the referee for these constructive comments, which highlight important aspects of our claims and presentation. We address each point below and will make corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the exponent 'identifies it as a quantitative measure of representational difficulty of the ground state' and that the results establish 'scaling laws as a general framework for benchmarking variational ansätze' rests on the assumption that the observed scaling and frustration dependence are properties of the learning problem rather than the specific transformer architecture; all reported results use only transformer wave functions, with no ablations or comparisons to other NNQS forms (e.g., RBM, CNN, or MLP) described, which is load-bearing for the generality interpretation.
Authors: We agree that the reported results are obtained exclusively with transformer wave functions and that no direct comparisons to other NNQS architectures are provided. The abstract language framing the findings as establishing 'scaling laws as a general framework' therefore exceeds what the data strictly support. In the revised manuscript we will rephrase the abstract to state that the observed power-law scaling, size collapse, and frustration dependence are demonstrated for transformer-based NNQS on the J1-J2 model, and that these results suggest scaling laws may offer a useful benchmarking approach; we will explicitly note that extension to other ansätze remains an open question for future work. This revision removes the overclaim while preserving the core empirical observations. revision: yes
-
Referee: [Methods] Methods (implied by abstract description of fits and collapse): No information is provided on error bars for V-score values, number of independent runs per data point, criteria for excluding optimization trajectories, or robustness checks against hyperparameter variation and optimizer stochasticity; without these, the reliability of the claimed power-law exponents and data collapse cannot be assessed.
Authors: We accept that the current manuscript lacks these statistical details. In the revised version we will add a dedicated subsection in Methods reporting: (i) the number of independent training runs performed for each system size and frustration value (typically five or more), (ii) error bars on V-score values computed from the standard deviation across runs, (iii) the convergence criteria used to retain or discard trajectories (e.g., energy stabilization within a tolerance over a fixed number of steps), and (iv) a brief statement on robustness to moderate hyperparameter changes. These additions will allow readers to evaluate the reliability of the reported exponents and collapse. revision: yes
Circularity Check
No circularity: empirical power-law fits to observed V-score data
full rationale
The paper reports numerical experiments training transformer wave functions on J1-J2 Heisenberg models and fitting observed V-score decay versus compute. No derivation chain, uniqueness theorem, or self-citation is invoked to obtain the power laws, data collapse, or frustration dependence; these are direct empirical measurements. The V-score itself is an independent accuracy metric, and the reported exponents are statistical fits to training curves rather than quantities defined in terms of those same fits. No step reduces by construction to its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- scaling exponent alpha
Reference graph
Works this paper leans on
-
[1]
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, Scaling laws for neural language models (2020), arXiv:2001.08361 [cs.LG]
Pith/arXiv arXiv 2020
-
[2]
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L. A. Hendricks, J. Welbl, A. Clark, T. Hennigan, E. Noland, K. Milli- can, G. van den Driessche, B. Damoc, A. Guy, S. Osin- dero, K. Simonyan, E. Elsen, J. W. Rae, O. Vinyals, and L.Sifre,Trainingcompute-optimallargelanguagemodels (2022), arXiv:2203.15556 [cs.CL]
Pith/arXiv arXiv 2022
-
[3]
X. Zhai, A. Kolesnikov, N. Houlsby, and L. Beyer, Scaling vision transformers (2022), arXiv:2106.04560 [cs.CV]
arXiv 2022
-
[4]
M. Dehghani, J. Djolonga, B. Mustafa, P. Padlewski, J. Heek, J. Gilmer, A. Steiner, M. Caron, R. Geirhos, I. Alabdulmohsin, R. Jenatton, L. Beyer, M. Tschan- nen, A. Arnab, X. Wang, C. Riquelme, M. Minderer, J. Puigcerver, U. Evci, M. Kumar, S. van Steenkiste, G. F. Elsayed, A. Mahendran, F. Yu, A. Oliver, F. Huot, J. Bastings, M. P. Collier, A. Gritsenko...
arXiv 2023
-
[5]
I. Alabdulmohsin, X. Zhai, A. Kolesnikov, and L. Beyer, Getting vit in shape: Scaling laws for compute-optimal model design (2024), arXiv:2305.13035 [cs.CV]
arXiv 2024
-
[6]
T. Henighan, J. Kaplan, M. Katz, M. Chen, C. Hesse, J. Jackson, H. Jun, T. B. Brown, P. Dhariwal, S. Gray, C. Hallacy, B. Mann, A. Radford, A. Ramesh, N. Ryder, D. M. Ziegler, J. Schulman, D. Amodei, and S. McCan- dlish, Scaling laws for autoregressive generative modeling (2020), arXiv:2010.14701 [cs.LG]
Pith/arXiv arXiv 2020
- [7]
-
[8]
Neumann and C
O. Neumann and C. Gros, Scaling laws for a multi-agent reinforcement learning model (2022)
2022
-
[9]
F. Cagnetta, A. Raventós, S. Ganguli, and M. Wyart, Deriving neural scaling laws from the statistics of natural language (2026), arXiv:2602.07488 [cs.LG]
arXiv 2026
-
[10]
Bahri, E
Y. Bahri, E. Dyer, J. Kaplan, J. Lee, and U. Sharma, Ex- plaining neural scaling laws, Proceedings of the National Academy of Sciences121, e2311878121 (2024)
2024
-
[11]
L. L. Viteritti, R. Rende, and F. Becca, Transformer vari- ational wave functions for frustrated quantum spin sys- tems, Phys. Rev. Lett.130, 236401 (2023)
2023
-
[12]
J. A. Sobral, M. Perle, and M. S. Scheurer, Physics- informed transformers for electronic quantum states, Nature Communications16, 10.1038/s41467-025-66844-z (2025)
-
[13]
R. P. Nutakki and F. Vicentini, Ground-state phases of s= 1/2heisenberg models on the body-centered cubic lattice (2026), arXiv:2602.10008 [cond-mat.str-el]
arXiv 2026
- [14]
-
[15]
K. Yamazaki, I. Sakata, T. Konishi, and Y. Kawa- hara, Physics-inspired transformer quantum states via la- tent imaginary-time evolution (2026), arXiv:2602.03031 [cond-mat.dis-nn]
arXiv 2026
-
[17]
L. L. Viteritti, R. Rende, G. Bracci-Testasecca, J. Niedda, R. Moessner, G. Carleo, and A. Scardicchio, Quantum spin glass in the two-dimensional disordered heisenberg model via foundation neural-network quan- tum states (2026), arXiv:2507.05073 [cond-mat.dis-nn]
arXiv 2026
-
[18]
I. von Glehn, J. S. Spencer, and D. Pfau, A self- attention ansatz for ab-initio quantum chemistry (2023), arXiv:2211.13672 [physics.chem-ph]
arXiv 2023
-
[19]
Shang, C
H. Shang, C. Guo, Y. Wu, Z. Li, and J. Yang, Solving the many-electron Schrödinger equation with a transformer- based framework, Nature Communications16, 8464 (2025)
2025
-
[20]
M.E.MswahiliandY.-S.Jeong,Transformer-basedmod- els for chemical smiles representation: A comprehensive literature review, Heliyon10, e39038 (2024)
2024
-
[21]
E. O. Pyzer-Knapp, M. Manica, P. Staar, L. Morin, P. Ruch, T. Laino, J. R. Smith, and A. Curioni, Founda- tion models for materials discovery – current state and future directions, npj Computational Materials11, 61 (2025)
2025
-
[22]
Jumper, R
J. Jumper, R. Evans, A. Pritzel, T. Green, M. Fig- urnov, O. Ronneberger, K. Tunyasuvunakool, R. Bates, A. Žídek, A. Potapenko, A. Bridgland, C. Meyer, S. A. A. Kohl, A. J. Ballard, A. Cowie, B. Romera-Paredes, S. Nikolov, R. Jain, J. Adler, T. Back, S. Petersen, D. Reiman, E. Clancy, M. Zielinski, M. Steinegger, M. Pacholska, T. Berghammer, S. Bodenstein...
2021
-
[23]
Moussad, R
B. Moussad, R. Roche, and D. Bhattacharya, The trans- formative power of transformers in protein structure pre- diction, Proceedings of the National Academy of Sciences 120, e2303499120 (2023)
2023
-
[24]
G. Carleo and M. Troyer, Solving the quan- tum many-body problem with artificial neu- ral networks, Science355, 602 (2017), https://www.science.org/doi/pdf/10.1126/science.aag2302
-
[25]
Becca and S
F. Becca and S. Sorella,Quantum Monte Carlo Ap- proaches for Correlated Systems(Cambridge University Press, 2017)
2017
-
[26]
H.Lange, A.VandeWalle, A.Abedinnia,andA.Bohrdt, From architectures to applications: a review of neural quantum states, Quantum Science and Technology9, 040501 (2024)
2024
-
[27]
K. Choo, T. Neupert, and G. Carleo, Two-dimensional frustratedJ 1−J2 model studied with neural network quantum states, Phys. Rev. B100, 125124 (2019)
2019
-
[28]
Chen and M
A. Chen and M. Heyl, Empowering deep neural quantum states through efficient optimization, Nature Physics20, 1476 (2024)
2024
-
[29]
A. Chen, V. D. Naik, and M. Heyl, Convolutional trans- former wave functions (2025), arXiv:2503.10462 [cond- mat.dis-nn]
arXiv 2025
- [30]
-
[31]
Hibat-Allah, M
M. Hibat-Allah, M. Ganahl, L. E. Hayward, R. G. Melko, and J. Carrasquilla, Recurrent neural network wave func- tions, Phys. Rev. Res.2, 023358 (2020)
2020
-
[32]
M. S. Moss, R. Wiersema, M. Hibat-Allah, J. Car- rasquilla, and R. G. Melko, Leveraging recurrence in neural network wavefunctions for large-scale simulations of heisenberg antiferromagnets on the triangular lattice, Phys. Rev. B112, 134449 (2025)
2025
-
[33]
O.Sharir, Y.Levine, N.Wies, G.Carleo,andA.Shashua, Deep autoregressive models for the efficient variational simulation of many-body quantum systems, Phys. Rev. Lett.124, 020503 (2020)
2020
-
[34]
Sprague and S
K. Sprague and S. Czischek, Variational monte carlo with large patched transformers, Communications Physics7, 90 (2024)
2024
-
[35]
N.-C., Pei, T., Liu, Z., Wang, X., Ning, G., Chan, T
R. Rende, L. L. Viteritti, F. Becca, A. Scardicchio, A. Laio, and G. Carleo, Foundation neural-networks quantum states as a unified ansatz for multiple hamilto- nians, Nature Communications16, 10.1038/s41467-025- 62098-x (2025)
-
[36]
L. L. Viteritti, R. Rende, A. Parola, S. Goldt, and F. Becca, Transformer wave function for two dimensional frustrated magnets: Emergence of a spin-liquid phase in the shastry-sutherland model, Phys. Rev. B111, 134411 (2025)
2025
-
[37]
C. Fan, B. Zhan, Y. Gu, T. Liu, Y. Wu, M. Qin, D. Lv, and T. Xiang, Disentangling tensor network states with deep neural network (2026), arXiv:2603.14425 [cond- mat.str-el]
arXiv 2026
-
[38]
L. L. Viteritti, R. Rende, S. Sachdev, and G. Carleo, Ap- proaching the thermodynamic limit with neural-network quantumstates,arXivpreprintarXiv:2602.02665 (2026)
arXiv 2026
-
[39]
Y. Gu, W. Li, H. Lin, B. Zhan, R. Li, Y. Huang, D. He, Y. Wu, T. Xiang, M. Qin, L. Wang, and D. Lv, Solving the hubbard model with neural quantum states (2025), arXiv:2507.02644 [cond-mat.str-el]
arXiv 2025
-
[40]
L. L. Viteritti, R. Rende, C. Roth, A. Sengupta, G. Car- leo, and A. Georges, Beyond variational bias: Resolv- ing intertwined orders in the hubbard model (2026), arXiv:2604.21978 [cond-mat.str-el]
Pith/arXiv arXiv 2026
- [41]
-
[42]
X. Cao, Z. Zhong, and Y. Lu, Vision transformer neural quantum states for impurity models (2024), arXiv:2408.13050 [cond-mat.str-el]
arXiv 2024
-
[43]
Shang, C
H. Shang, C. Guo, Y. Wu, Z. Li, and J. Yang, Solving the many-electron schrödinger equation with a transformer- based framework, Nature Communications16, 8464 (2025)
2025
-
[44]
T. Zhao, J. Stokes, and S. Veerapaneni, Scalable neu- ral quantum states architecture for quantum chemistry, Machine Learning: Science and Technology4, 025034 (2023)
2023
-
[45]
O. Knitter, D. Zhao, S. Leichenauer, and S. Veerapaneni, Large language model scaling laws for neural quantum states in quantum chemistry (2025), arXiv:2509.12679 [cs.LG]
arXiv 2025
-
[46]
Y. Lu, S. Bharadwaj, D. Rathore, and D. Luo, Information-theoretic scaling laws of neural quantum states (2026), arXiv:2603.23468 [quant-ph]
arXiv 2026
-
[47]
D. Wu, R. Rossi, F. Vicentini, N. Astrakhantsev, F. Becca, X. Cao, J. Carrasquilla, F. Ferrari, A. Georges, M. Hibat-Allah,et al., Variational benchmarks for quan- tum many-body problems, Science386, 296 (2024)
2024
-
[48]
T. Pearce and J. Song, Reconciling kaplan and chinchilla scaling laws (2024), arXiv:2406.12907 [cs.LG]
arXiv 2024
-
[49]
H. Li, W. Zheng, Q. Wang, Z. Ding, H. Wang, Z. Wang, S. Xuyang, N. Ding, S. Zhou, X. Zhang, and D. Jiang, Predictablescale: Partii, farseer: Arefinedscalinglawin large language models (2025), arXiv:2506.10972 [cs.LG]
arXiv 2025
-
[50]
A. W. Sandvik, Finite-size scaling of the ground-state pa- rameters of the two-dimensional heisenberg model, Phys. Rev. B56, 11678 (1997)
1997
-
[51]
A. W. Sandvik, High-precision ground state parameters of the two-dimensional spin-1/2 heisenberg model on the square lattice, Journal of Statistical Mechanics: Theory and Experiment2026, 043101 (2026)
2026
-
[52]
Calandra Buonaura and S
M. Calandra Buonaura and S. Sorella, Numerical study of the two-dimensional heisenberg model using a green function monte carlo technique with a fixed number of walkers, Phys. Rev. B57, 11446 (1998)
1998
-
[53]
W.-J. Hu, F. Becca, A. Parola, and S. Sorella, Direct evidence for a gaplessZ2 spin liquid by frustrating néel antiferromagnetism, Phys. Rev. B88, 060402(R) (2013)
2013
-
[54]
Nomura and M
Y. Nomura and M. Imada, Dirac-type nodal spin liq- uid revealed by refined quantum many-body solver using neural-network wave function, correlation ratio, and level spectroscopy, Phys. Rev. X11, 031034 (2021)
2021
-
[55]
Capriotti, A
L. Capriotti, A. E. Trumper, and S. Sorella, Long-range néel order in the triangular heisenberg model, Phys. Rev. Lett.82, 3899 (1999)
1999
-
[56]
S. R. White and A. L. Chernyshev, Neél order in square and triangular lattice heisenberg models, Phys. Rev. Lett.99, 127004 (2007)
2007
-
[57]
Kaneko, S
R. Kaneko, S. Morita, and M. Imada, Gapless spin- liquid phase in an extended spin 1/2 triangular heisen- berg model, Journal of the Physical Society of Japan83, 093707 (2014)
2014
-
[58]
Iqbal, W.-J
Y. Iqbal, W.-J. Hu, R. Thomale, D. Poilblanc, and F. Becca, Spin liquid nature in the heisenbergJ1 −J 2 triangular antiferromagnet, Phys. Rev. B93, 144411 (2016)
2016
-
[59]
K. G. Wilson and J. B. Kogut, The Renormalization group and the epsilon expansion, Phys. Rept.12, 75 (1974)
1974
-
[60]
K. G. Wilson, The renormalization group: Critical phe- nomena and the kondo problem, Rev. Mod. Phys.47, 773 (1975)
1975
-
[61]
Goldenfeld, Lectures on phase transitions and the renormalization group (1972)
N. Goldenfeld, Lectures on phase transitions and the renormalization group (1972)
1972
-
[62]
Cardy,Scaling and renormalization in statistical physics, Vol
J. Cardy,Scaling and renormalization in statistical physics, Vol. 5 (Cambridge university press, 1996)
1996
-
[63]
Nomura, Helping restricted boltzmann machines with quantum-state representation by restoring symmetry, JournalofPhysics: CondensedMatter33,174003(2021)
Y. Nomura, Helping restricted boltzmann machines with quantum-state representation by restoring symmetry, JournalofPhysics: CondensedMatter33,174003(2021)
2021
-
[64]
M. Reh, M. Schmitt, and M. Gärttner, Optimizing design choices for neural quantum states, Phys. Rev. B107, 195115 (2023)
2023
-
[65]
M. B. Hastings, I. González, A. B. Kallin, and R. G. Melko, Measuring renyi entanglement entropy in quan- tum monte carlo simulations, Phys. Rev. Lett.104, 157201 (2010)
2010
-
[66]
Passetti, D
G. Passetti, D. Hofmann, P. Neitemeier, L. Grunwald, 10 M. A. Sentef, and D. M. Kennes, Can neural quantum states learn volume-law ground states?, Phys. Rev. Lett. 131, 036502 (2023)
2023
-
[67]
can neural quantum states learn volume-law ground states?
Z. Denis, A. Sinibaldi, and G. Carleo, Comment on “can neural quantum states learn volume-law ground states?”, Phys. Rev. Lett.134, 079701 (2025)
2025
-
[68]
Orús, A practical introduction to tensor networks: Matrix product states and projected entangled pair states, Annals of Physics349, 117–158 (2014)
R. Orús, A practical introduction to tensor networks: Matrix product states and projected entangled pair states, Annals of Physics349, 117–158 (2014)
2014
-
[69]
Turkeshi, E
X. Turkeshi, E. Tirrito, and P. Sierant, Magic spread- ing inrandom quantum circuits, NatureCommunications 16, 2575 (2025)
2025
-
[70]
P. S. Tarabunga, E. Tirrito, T. Chanda, and M. Dal- monte, Many-body magic via pauli-markov chains—from criticality to gauge theories, PRX Quantum4, 040317 (2023)
2023
-
[71]
Leone, S
L. Leone, S. F. E. Oliviero, and A. Hamma, Stabilizer rényi entropy, Phys. Rev. Lett.128, 050402 (2022)
2022
-
[72]
Sinibaldi, A
A. Sinibaldi, A. F. Mello, M. Collura, and G. Carleo, Nonstabilizerness of neural quantum states, Phys. Rev. Res.7, 043289 (2025)
2025
-
[73]
Mendes-Santos, M
T. Mendes-Santos, M. Schmitt, A. Angelone, A. Ro- driguez, P. Scholl, H. J. Williams, D. Barredo, T. La- haye, A. Browaeys, M. Heyl, and M. Dalmonte, Wave- function network description and kolmogorov complex- ity of quantum many-body systems, Phys. Rev. X14, 021029 (2024)
2024
-
[74]
H.Xu, C.-M.Chung, M.Qin, U.Schollwöck, S.R.White, and S. Zhang, Coexistence of superconductivity with par- tially filled stripes in the hubbard model, Science384, 10.1126/science.adh7691 (2024)
-
[75]
C. Roth, A. Chen, A. Sengupta, and A. Georges, Superconductivity in the two-dimensional hubbard model revealed by neural quantum states (2025), arXiv:2511.07566 [cond-mat.supr-con]
arXiv 2025
-
[76]
D. Pfau, J. S. Spencer, A. G. D. G. Matthews, and W. M. C. Foulkes, Ab initio solution of the many-electron schrödinger equation with deep neural networks, Phys. Rev. Res.2, 033429 (2020)
2020
-
[77]
J. Nys, G. Pescia, A. Sinibaldi, and G. Carleo, Ab-initio variational wave functions for the time-dependent many- electron schrödinger equation, Nature communications 15, 9404 (2024)
2024
-
[78]
Rende, S
R. Rende, S. Goldt, F. Becca, and L. L. Viteritti, Fine- tuning neural network quantum states, Phys. Rev. Res. 6, 043280 (2024)
2024
-
[79]
Sorella, Green function monte carlo with stochastic reconfiguration, Phys
S. Sorella, Green function monte carlo with stochastic reconfiguration, Phys. Rev. Lett.80, 4558 (1998)
1998
-
[80]
R. Rende, L. L. Viteritti, L. Bardone, F. Becca, and S. Goldt, A simple linear algebra identity to optimize large-scale neural network quantum states, Communica- tions Physics7, 10.1038/s42005-024-01732-4 (2024)
-
[81]
A.Sinibaldi, C.Giuliani, G.Carleo,andF.Vicentini,Un- biasing time-dependent variational monte carlo by pro- jected quantum evolution, Quantum7, 1131 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.