Tiny Collaborative Inference for Occlusion-Robust Object Detection
Pith reviewed 2026-06-28 14:54 UTC · model grok-4.3
The pith
Decision-level fusion with weighted boxes outperforms feature fusion for occlusion-robust detection on devices under 1 MB SRAM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
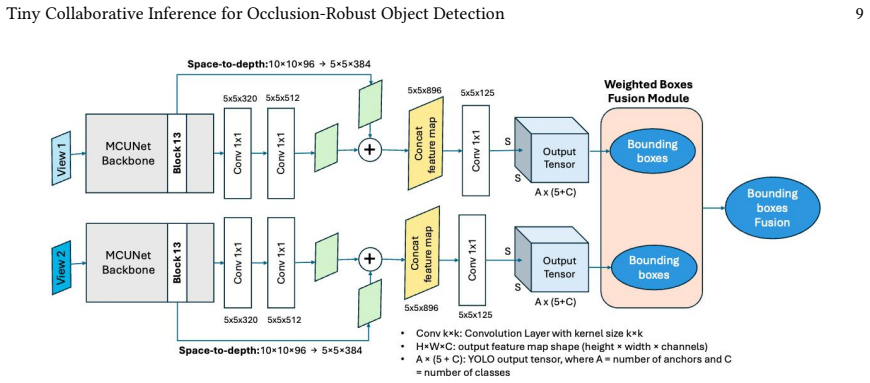
The central claim is that decision-level fusion via Weighted Boxes Fusion outperforms feature-level fusion under all tested occlusion conditions on MCUNet-YOLOv2 models quantized for less than 1 MB SRAM, with gains reaching 0.2736 mAP in two-view asymmetric cases and 0.3827 mAP when extended to three views, at roughly 1.3 KB communication per exchange, and that this fusion executes on-device on Coral Dev Board Micro units with negligible added energy, increasing autonomous coverage from 47 to 61 frames in a 301.9-second session.
What carries the argument
Weighted Boxes Fusion (WBF), which merges bounding-box outputs from separate detectors by weighting them according to their confidence scores.
If this is right
- Three-view fusion adds further accuracy at only modest extra communication cost.
- On-device WBF removes the need for a host computer and raises the fraction of frames that contain detections.
- The same fusion step works across both USB-relay and Wi-Fi peer-to-peer setups.
- Federated learning remains possible but shows limited gains when data across nodes are non-iid.
Where Pith is reading between the lines
- Similar late-fusion logic could apply to other bandwidth-limited multi-sensor tasks such as distributed tracking.
- Energy measurements on longer missions would show whether the coverage gain translates into extended battery runtime.
- Replacing the current backbone with newer tiny detectors might lower the baseline memory requirement even further.
Load-bearing premise
The specific occlusion patterns and datasets used produce accuracy and energy gains that represent real search-and-rescue conditions on these boards.
What would settle it
A field deployment in actual search-and-rescue terrain where the measured mAP improvement from two- or three-view WBF falls below 0.1 and coverage gain disappears.
Figures

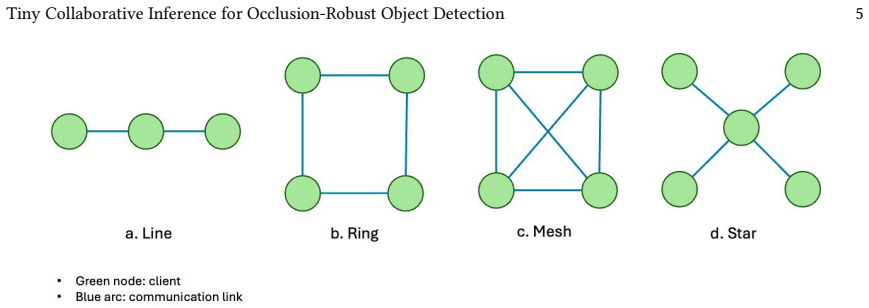
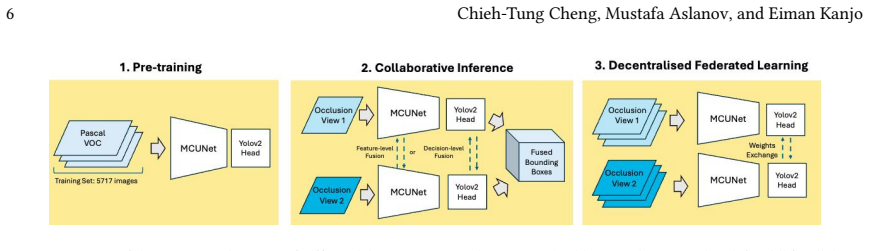
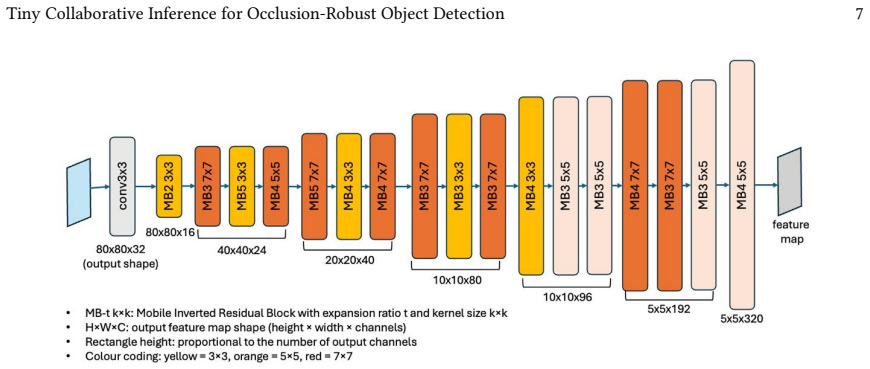

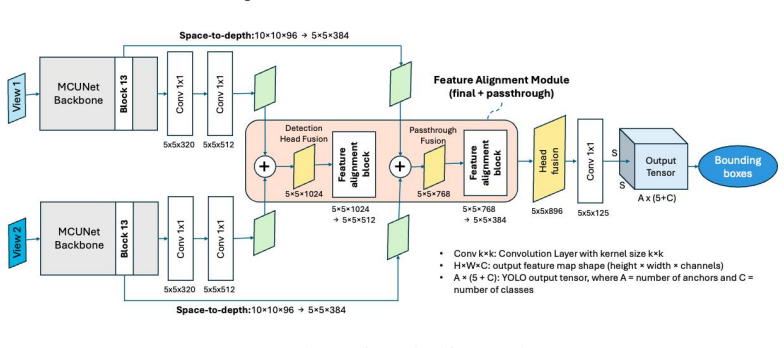










read the original abstract
Edge AI nodes for search and rescue are increasingly expected to run computer vision locally, yet ultra-low-end hardware imposes hard constraints on memory, compute, and inter-device communication. This work addresses occlusion-robust object detection on devices with less than 1 MB SRAM by combining an MCUNet backbone, a YOLOv2 detection head, and Lite quantisation. Two collaborative inference strategies are evaluated: feature-level fusion, concatenating intermediate feature maps, and decision-level fusion via Weighted Boxes Fusion (WBF). WBF outperforms feature-level fusion under all tested occlusion conditions, yielding gains of up to +0.2736 mAP in asymmetric scenarios. Extending fusion to three views improves accuracy further (up to +0.3827 mAP) at modest communication overhead (~1.3 KB per exchange). Hardware experiments progress from a host-assisted USB-relay baseline to a Wi-Fi peer-to-peer deployment on two Coral Dev Board Micro units, where WBF executes on-device with negligible communication energy relative to inference. In a 301.9 s autonomous session of 108 frames, fused output is produced on 61 frames versus 47 for a single board - a coverage gain of +29.8%. A decentralised federated learning feasibility note is included but not treated as a primary result, as performance remains limited under non-iid data. The results support decision-level fusion as a viable option for improving occlusion robustness in small-scale edge object detection, including host-free multi-board operation on ultra-low-end hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates two collaborative inference strategies—feature-level fusion and decision-level fusion via Weighted Boxes Fusion (WBF)—for occlusion-robust object detection on ultra-low-end edge devices (<1 MB SRAM) using an MCUNet backbone with YOLOv2 head and Lite quantization. It reports that WBF outperforms feature-level fusion under tested occlusion conditions (gains up to +0.2736 mAP in asymmetric cases), with further gains from three-view fusion (+0.3827 mAP) at ~1.3 KB overhead per exchange. Hardware experiments on Coral Dev Board Micro units progress from USB-relay to Wi-Fi P2P, claiming on-device WBF execution with negligible communication energy and a +29.8% coverage gain (61 vs. 47 frames) in a 301.9 s / 108-frame autonomous session. A brief federated learning note is included but not central.
Significance. If the hardware claims hold, the work supplies concrete empirical evidence that decision-level fusion can improve occlusion robustness and coverage in multi-view setups on severely memory-constrained devices, with modest communication cost. The reported mAP deltas and coverage numbers from real hardware runs are a strength; the approach could be relevant for search-and-rescue edge AI if energy and dataset details are clarified.
major comments (1)
- [Abstract / hardware experiments] Abstract and hardware experiments section: the central claim that WBF on-device execution incurs 'negligible communication energy relative to inference' in the Wi-Fi P2P Coral Dev Board Micro deployment is unsupported by any quantitative measurements (e.g., mJ per inference vs. per 1.3 KB exchange, or power traces). This directly weakens the hardware-practicality half of the contribution for <1 MB SRAM devices.
minor comments (1)
- [Abstract / results] The abstract and results mention specific datasets and occlusion generation methods but do not provide sufficient detail on exact occlusion synthesis procedure or statistical significance tests for the mAP deltas.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the hardware energy claim. We address it directly below.
read point-by-point responses
-
Referee: [Abstract / hardware experiments] Abstract and hardware experiments section: the central claim that WBF on-device execution incurs 'negligible communication energy relative to inference' in the Wi-Fi P2P Coral Dev Board Micro deployment is unsupported by any quantitative measurements (e.g., mJ per inference vs. per 1.3 KB exchange, or power traces). This directly weakens the hardware-practicality half of the contribution for <1 MB SRAM devices.
Authors: We agree that the manuscript provides no direct quantitative energy measurements (mJ, power traces, or per-inference vs. per-exchange comparisons) to substantiate the 'negligible communication energy' phrasing. The statement was based on the modest payload size (~1.3 KB) and the known high compute cost of MCUNet inference on the target platform, but this remains a qualitative inference rather than an empirically measured result. In the revised version we will (1) remove or qualify the unqualified 'negligible' wording in both the abstract and hardware-experiments section, (2) explicitly note the absence of direct energy profiling, and (3) add a short discussion of the data-size argument together with a reference to typical Wi-Fi energy costs on similar Cortex-M devices. These changes will make the hardware-practicality claims more precise while preserving the reported coverage and latency numbers. revision: yes
Circularity Check
No circularity: purely empirical comparison with no derivations or self-referential predictions
full rationale
The paper evaluates two fusion strategies (feature-level vs. WBF decision-level) via direct mAP measurements on occlusion datasets and hardware timing/energy on Coral Dev Board Micro units. No equations, fitted parameters, or derivation chains are present; results are reported as measured outputs (e.g., +0.2736 mAP, 1.3 KB overhead, 301.9 s session coverage). The reader's assessment of score 1.0 is consistent with the absence of any load-bearing steps that reduce to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Internet of Things: Catching Up to an Accelerating Opportunity
Chui M, Collins M, and Patel M. The Internet of Things: Catching Up to an Accelerating Opportunity. 2021. Accessed: 2025-08-24. Available from: https://www.mckinsey.com/capabilities/tech-and-ai/our-insights/iot-value-set-to-accelerate-through-2030-where-and-how-to-capture-it
2021
-
[2]
Deep learning with edge computing: A review
Chen J and Ran X. Deep learning with edge computing: A review. Proceedings of the IEEE 2019; 107:1655–74. doi: 10.1109/JPROC.2019.2921977
-
[3]
Deep learning for edge computing applications: A state-of-the-art survey
Wang F, Zhang M, Wang X, Ma X, and Liu J. Deep learning for edge computing applications: A state-of-the-art survey. IEEE Access 2020; 8:58322–36. doi: 10.1109/ACCESS.2020.2982411
-
[4]
A survey of methods for low-power deep learning and computer vision
Goel A, Tung C, Lu YH, and Thiruvathukal GK. A survey of methods for low-power deep learning and computer vision. In: 2020 IEEE 6th World Forum on Internet of Things (WF-IoT). IEEE; 2020:1–6
2020
-
[5]
Making accurate object detection at the edge: review and new approach
Huang Z, Yang S, Zhou M, Gong Z, Abusorrah A, Lin C, and Huang Z. Making accurate object detection at the edge: review and new approach. Artificial Intelligence Review 2022; 55:2245–74. doi: 10.1007/s10462-021-10059-3
-
[6]
Bany Abdelnabi AA and Rabadi G. Human detection from unmanned aerial vehicles’ images for search and rescue missions: A state-of-the-art review. IEEE Access 2024; 12:152009–35. doi: 10.1109/ACCESS.2024.3479988
-
[7]
UAV-based real-time survivor detection system in post-disaster search and rescue operations
Dong J, Ota K, and Dong M. UAV-based real-time survivor detection system in post-disaster search and rescue operations. IEEE Journal on Miniaturization for Air and Space Systems 2021; 2:209–19. doi: 10.1109/JMASS.2021.3083659
-
[8]
A review of occluded objects detection in real complex scenarios for autonomous driving
Ruan J, Cui H, Huang Y, Li T, Wu C, and Zhang K. A review of occluded objects detection in real complex scenarios for autonomous driving. Green Energy and Intelligent Transportation 2023; 2:100092. doi: 10.1016/j.geits.2023.100092
-
[9]
Lightweight deep learning for resource-constrained environments: A survey
Liu HI, Galindo M, Xie H, Wong LK, Shuai HH, Li YH, and Cheng WH. Lightweight deep learning for resource-constrained environments: A survey. ACM Computing Surveys 2024; 56(10):Article 267. doi: 10.1145/3657282
-
[10]
MCUNet: Tiny Deep Learning on IoT Devices
Lin J, Chen WM, Lin Y, Cohn J, Gan C, and Han S. MCUNet: Tiny Deep Learning on IoT Devices. arXiv 2020. arXiv:2007.10319 [cs.CV]. Available from: https://arxiv.org/abs/2007.10319
arXiv 2020
-
[11]
MCUNetV2: Memory-Efficient Patch-Based Inference for Tiny Deep Learning
Lin J, Chen WM, Cai H, Gan C, and Han S. MCUNetV2: Memory-Efficient Patch-Based Inference for Tiny Deep Learning. arXiv 2021. arXiv:2110.15352 [cs.CV]. Available from: https://arxiv.org/abs/2110.15352
arXiv 2021
-
[12]
Robustness of object recognition under extreme occlusion in humans and computational models
Zhu H, Tang P, Park J, Park S, and Yuille A. Robustness of object recognition under extreme occlusion in humans and computational models. arXiv
-
[13]
Available from: https://arxiv.org/abs/1905.04598
arXiv:1905.04598 [cs.CV]. Available from: https://arxiv.org/abs/1905.04598
Pith/arXiv arXiv 1905
-
[14]
Occlusion handling in generic object detection: A review
Saleh K, Szénási S, and Vámossy Z. Occlusion handling in generic object detection: A review. In: 2021 IEEE 19th World Symposium on Applied Machine Intelligence and Informatics (SAMI). IEEE; 2021:477–84
2021
-
[15]
Compositional convolutional neural networks: A deep architecture with innate robustness to partial occlusion
Kortylewski A, He J, Liu Q, and Yuille AL. Compositional convolutional neural networks: A deep architecture with innate robustness to partial occlusion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020:8940–49
2020
-
[16]
Robust object detection under occlusion with context-aware CompositionalNets
Wang A, Sun Y, Kortylewski A, and Yuille AL. Robust object detection under occlusion with context-aware CompositionalNets. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2020:12645–54. Available from: https://openaccess.thecvf.com/content_ CVPR_2020/html/Wang_Robust_Object_Detection_Under_Occlusion_With_Conte...
2020
-
[17]
DeepVoting: A robust and explainable deep network for semantic part detection under partial occlusion
Zhang Z, Xie C, Wang J, Xie L, and Yuille AL. DeepVoting: A robust and explainable deep network for semantic part detection under partial occlusion. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018:1372–80
2018
-
[18]
Multiview objects recognition using deep learning-based Wrap-CNN with voting scheme
Balamurugan D, Aravinth SS, Reddy PCS, Rupani A, and Manikandan A. Multiview objects recognition using deep learning-based Wrap-CNN with voting scheme. Neural Processing Letters 2022; 54(3):1495–521. doi: 10.1007/s11063-021-10679-4
-
[19]
Edge-device collaborative computing for multi-view classification
Palena M, Cerquitelli T, and Chiasserini CF. Edge-device collaborative computing for multi-view classification. Computer Networks 2024; 254:110823. doi: 10.1016/j.comnet.2024.110823
-
[20]
Multimodal machine learning: A survey and taxonomy
Baltrušaitis T, Ahuja C, and Morency LP. Multimodal machine learning: A survey and taxonomy. IEEE Transactions on Pattern Analysis and Machine Intelligence 2019; 41(2):423–43. doi: 10.1109/TPAMI.2018.2798607
-
[21]
Multimodal fusion for multimedia analysis: A survey
Atrey PK, Hossain MA, El Saddik A, and Kankanhalli MS. Multimodal fusion for multimedia analysis: A survey. Multimedia Systems 2010; 16:345–79
2010
-
[22]
Boulahia SY, Amamra A, Madi MR, and Daikh S. Early, intermediate and late fusion strategies for robust deep learning-based multimodal action recognition. Machine Vision and Applications 2021; 32(6):121. doi: 10.1007/s00138-021-01249-8
-
[23]
Multi-view object detection based on deep learning
Tang C, Ling Y, Yang X, Jin W, and Zheng C. Multi-view object detection based on deep learning. Applied Sciences 2018; 8(9):1423. doi: 10.3390/app8091423
-
[24]
Cross-Domain Federated Object Detection
Su S, Li B, Zhang C, Yang M, and Xue X. Cross-Domain Federated Object Detection. In: 2023 IEEE International Conference on Multimedia and Expo (ICME). IEEE; 2023:1469–74. doi: 10.1109/ICME55011.2023.00254. Available from: http://dx.doi.org/10.1109/ICME55011.2023.00254
-
[25]
Weighted boxes fusion: Ensembling boxes from different object detection models
Solovyev R, Wang W, and Gabruseva T. Weighted boxes fusion: Ensembling boxes from different object detection models. Image and Vision Computing 2021; 107:104117. doi: 10.1016/j.imavis.2021.104117. Available from: http://dx.doi.org/10.1016/j.imavis.2021.104117
-
[26]
Deep models for multi-view 3D object recognition: A review
Alzahrani M, Usman M, Jarraya SK, Anwar S, and Helmy T. Deep models for multi-view 3D object recognition: A review. Artificial Intelligence Review 2024; 57(12):Article 323. doi: 10.1007/s10462-024-10941-w
-
[27]
Fully decentralized federated learning
Lalitha A, Shekhar S, Javidi T, and Koushanfar F. Fully decentralized federated learning. In: Third Workshop on Bayesian Deep Learning (NeurIPS). Vol. 12. 2018
2018
-
[28]
Decentralized Federated Learning: A Survey and Perspective
Yuan L, Wang Z, Sun L, Yu PS, and Brinton CG. Decentralized Federated Learning: A Survey and Perspective. IEEE Internet of Things Journal 2024; 11:34617–38. doi: 10.1109/JIOT.2024.3407584
-
[29]
Randomized gossip algorithms
Boyd S, Ghosh A, Prabhakar B, and Shah D. Randomized gossip algorithms. IEEE Transactions on Information Theory 2006; 52:2508–30. Manuscript submitted to ACM Tiny Collaborative Inference for Occlusion-Robust Object Detection 39
2006
-
[30]
Federated learning for computer vision
Himeur Y, Varlamis I, Kheddar H, Amira A, Atalla S, Singh Y, Bensaali F, and Mansoor W. Federated learning for computer vision. arXiv 2023. arXiv:2308.13558 [cs.CV]. Available from: https://arxiv.org/abs/2308.13558
arXiv 2023
-
[31]
YOLO9000: Better, Faster, Stronger
Redmon J and Farhadi A. YOLO9000: Better, Faster, Stronger. arXiv 2016. arXiv:1612.08242 [cs.CV]. Available from: https://arxiv.org/abs/1612.08242
Pith/arXiv arXiv 2016
-
[32]
A multicore and Edge TPU-accelerated multimodal TinyML system for livestock behavior recognition
Zhang Q and Kanjo E. A multicore and Edge TPU-accelerated multimodal TinyML system for livestock behavior recognition. IEEE Internet of Things Journal 2026; 13(1):666–77. doi: 10.1109/JIOT.2025.3624811. Available from: https://arxiv.org/abs/2504.11467
-
[33]
Common Objects in 3D: Large-Scale Learning and Evaluation of Real-life 3D Category Reconstruction
Reizenstein J, Shapovalov R, Henzler P, Sbordone L, Labatut P, and Novotny D. Common Objects in 3D: Large-Scale Learning and Evaluation of Real-life 3D Category Reconstruction. arXiv 2021. arXiv:2109.00512 [cs.CV]. Available from: https://arxiv.org/abs/2109.00512
arXiv 2021
-
[34]
Improved Regularization of Convolutional Neural Networks with Cutout
DeVries T and Taylor GW. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017. arXiv:1708.04552 [cs.CV]. Available from: https://arxiv.org/abs/1708.04552
Pith/arXiv arXiv 2017
-
[35]
Communication-efficient learning of deep networks from decentralized data
McMahan B, Moore E, Ramage D, Hampson S, and Agüera y Arcas B. Communication-efficient learning of deep networks from decentralized data. In: Artificial Intelligence and Statistics. PMLR; 2017:1273–82
2017
-
[36]
Representative Batch Normalization with Feature Calibration
Gao SH, Han Q, Li D, Cheng MM, and Peng P. Representative Batch Normalization with Feature Calibration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2021:8669–79
2021
-
[37]
A Standard for the Transmission of IP Datagrams over Ethernet Networks. RFC 894. 1984 Apr. doi: 10.17487/RFC0894. Available from: https: //www.rfc-editor.org/info/rfc894
-
[38]
Dev Board Micro datasheet
Coral. Dev Board Micro datasheet. Version 1.0. Google LLC. Available from: https://coral.ai/static/files/Coral-Dev-Board-Micro-datasheet.pdf Manuscript submitted to ACM
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.