A Training-Efficient Transformer-Based Anti-Spoofing Network for Logical Access in ASVspoof 5
Pith reviewed 2026-06-30 11:24 UTC · model grok-4.3
The pith
TFPARN, a Transformer network using focal and pairwise losses, outperforms re-implemented baselines on ASVspoof 5 Track 1 with lower memory and faster training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
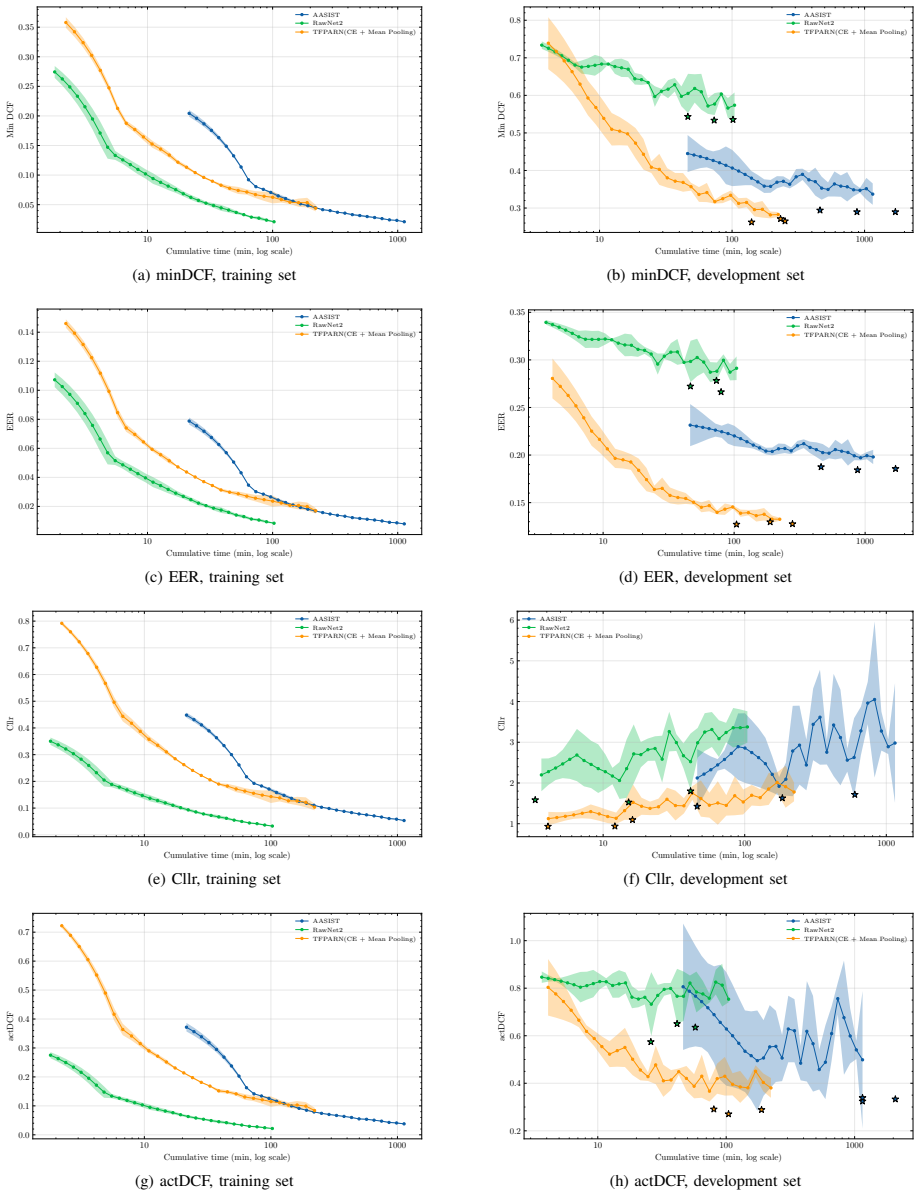
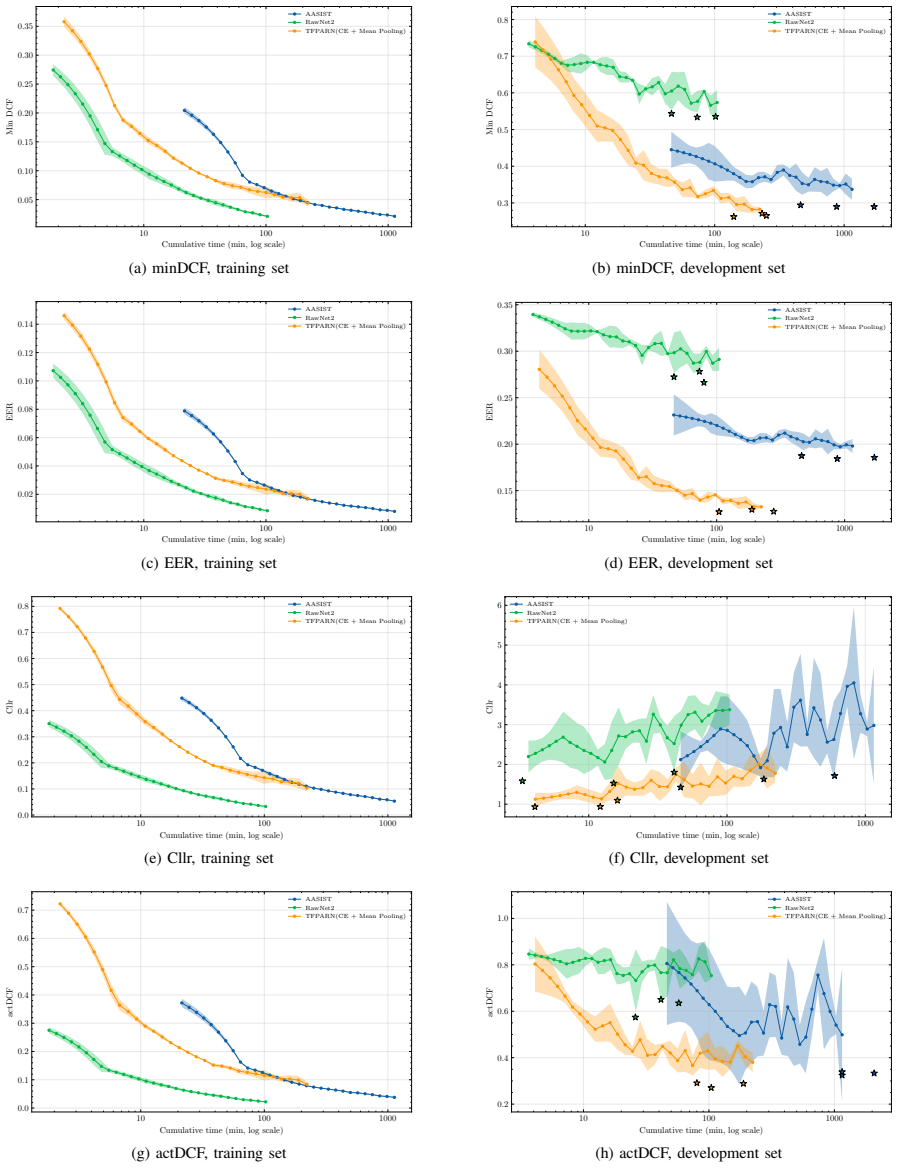
TFPARN extracts log-Mel features from speech, models frame-level information with a Transformer encoder, obtains utterance-level representations via attention pooling, and trains with focal classification loss combined with pairwise ranking loss under RawBoost augmentation and test-time augmentation. On the ASVspoof 5 Track 1 closed condition it reaches a minDCF of 0.2430 and EER of 12.52 percent, beating re-implemented AASIST and RawNet2 baselines while using 1.4 GB inference memory, running at 0.79 ms per utterance, and converging faster during training.
What carries the argument
TFPARN, a Transformer encoder with attention pooling trained by focal classification loss plus pairwise ranking loss.
If this is right
- Focal loss directs more attention to difficult spoofing trials during training.
- Pairwise ranking loss improves alignment between the training objective and the threshold-based evaluation metrics.
- Attention pooling produces stronger utterance-level representations than alternatives tested in the ablations.
- The full system delivers both higher accuracy and lower computational cost than the compared baselines.
Where Pith is reading between the lines
- The efficiency numbers suggest the architecture could scale to real-time voice verification pipelines with limited hardware.
- Similar focal-plus-pairwise training might benefit other audio tasks that require distinguishing subtle differences under ranking metrics.
- Applying the same losses and pooling to open-condition tracks or additional datasets would test whether the gains persist outside the closed setting.
Load-bearing premise
The performance gains come from the focal loss, pairwise loss, and attention pooling rather than from unstated differences in how the baseline systems were coded or tuned.
What would settle it
An independent reproduction of the experiments under identical data splits and hyperparameter protocols that shows no advantage for TFPARN over the baselines in minDCF or EER.
Figures

read the original abstract
Synthetic and manipulated speech can reduce the reliability of automatic speaker verification systems, so anti-spoofing methods need to be both accurate and efficient in training and inference. This paper focuses on the ASVspoof 5 Track 1 closed condition, where standard cross-entropy training may not give enough attention to hard trials and is not directly aligned with ranking- and threshold-based evaluation metrics. We propose TFPARN, a Transformer-based focal-pairwise attentive ranking network. The system extracts log-Mel features from speech, uses a Transformer encoder to model frame-level information, applies attention pooling to obtain utterance-level representations, and is trained with a combination of focal classification loss and pairwise ranking loss. RawBoost augmentation is used during training, and test-time augmentation is applied during evaluation to improve robustness. Compared with re-implemented AASIST and RawNet2 baselines under the same protocol, TFPARN achieves the best results, with a minDCF of 0.2430 and an EER of 12.52%. Ablation experiments further show that the pairwise loss, focal loss, and attention pooling all improve performance. TFPARN also uses the lowest inference memory among the compared systems, at 1.4 GB, runs at about 0.79 ms per utterance, and reaches its best checkpoint in less training time than AASIST. These results show that TFPARN provides a good balance between detection accuracy and computational cost for logical access anti-spoofing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TFPARN, a Transformer-based focal-pairwise attentive ranking network for logical access anti-spoofing on the ASVspoof 5 Track 1 closed condition. It extracts log-Mel features, employs a Transformer encoder with attention pooling for utterance-level embeddings, and trains using a combination of focal classification loss and pairwise ranking loss, augmented by RawBoost during training and test-time augmentation at inference. The central empirical claim is that TFPARN outperforms re-implemented AASIST and RawNet2 baselines under identical protocol, achieving minDCF of 0.2430 and EER of 12.52%, while also showing lower inference memory (1.4 GB), faster per-utterance inference (0.79 ms), and quicker convergence to best checkpoint; ablations are presented to attribute gains to the focal loss, pairwise loss, and attention pooling.
Significance. If the baseline re-implementations prove faithful, the work offers a practical, training-efficient alternative for ASV anti-spoofing that improves upon standard cross-entropy training by aligning better with ranking- and threshold-based metrics. The reported efficiency metrics and component ablations provide concrete evidence of a favorable accuracy-cost trade-off on a public benchmark, which could inform deployment in resource-constrained speaker verification systems.
major comments (2)
- [§4 (Experimental Setup and Results)] §4 (Experimental Setup and Results): The headline claim that TFPARN achieves the best minDCF (0.2430) and EER (12.52%) rests on the re-implemented AASIST and RawNet2 baselines being faithful reproductions under the same protocol, data splits, augmentation, and hyperparameter effort. The manuscript must tabulate the re-implemented baseline metrics alongside the numbers originally reported in the AASIST and RawNet2 papers; without this verification, performance deltas cannot be confidently attributed to the focal loss, pairwise ranking loss, or attention pooling rather than optimization or implementation disparities.
- [Ablation subsection of §4] Ablation subsection of §4: The paper states that ablations demonstrate improvements from the pairwise loss, focal loss, and attention pooling, but does not report the number of random seeds, variance across runs, or statistical significance tests for the incremental gains. This weakens the causal attribution of the final 0.2430 minDCF / 12.52% EER to those specific components.
minor comments (2)
- [Abstract and §3.2] Abstract and §3.2: The description of test-time augmentation is brief; specifying the exact operations (e.g., which augmentations are applied at test time and how scores are aggregated) would improve reproducibility.
- [§3.3] §3.3: The weighting hyperparameter between focal and pairwise losses is a free parameter; reporting its tuned value and any sensitivity analysis would strengthen the training-objective description.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each of the major comments below, proposing specific revisions to strengthen the paper.
read point-by-point responses
-
Referee: [§4 (Experimental Setup and Results)] The headline claim that TFPARN achieves the best minDCF (0.2430) and EER (12.52%) rests on the re-implemented AASIST and RawNet2 baselines being faithful reproductions under the same protocol, data splits, augmentation, and hyperparameter effort. The manuscript must tabulate the re-implemented baseline metrics alongside the numbers originally reported in the AASIST and RawNet2 papers; without this verification, performance deltas cannot be confidently attributed to the focal loss, pairwise ranking loss, or attention pooling rather than optimization or implementation disparities.
Authors: We agree with the referee that tabulating the original reported metrics would enhance the credibility of our claims. In the revised version, we will include a new table in Section 4 that lists the minDCF and EER values originally reported for AASIST and RawNet2 in their respective papers, next to the results from our re-implementations under the ASVspoof 5 closed condition protocol. This will allow direct comparison and help attribute improvements appropriately. revision: yes
-
Referee: [Ablation subsection of §4] The paper states that ablations demonstrate improvements from the pairwise loss, focal loss, and attention pooling, but does not report the number of random seeds, variance across runs, or statistical significance tests for the incremental gains. This weakens the causal attribution of the final 0.2430 minDCF / 12.52% EER to those specific components.
Authors: We acknowledge that the absence of statistical analysis limits the strength of the ablation conclusions. To address this, we will rerun the ablation experiments using multiple random seeds and report the mean and standard deviation of the metrics. Additionally, we will include statistical significance tests (e.g., paired t-tests) for the observed improvements in the revised ablation subsection. revision: yes
Circularity Check
No circularity: empirical benchmark results with independent validation
full rationale
The paper reports experimental results comparing TFPARN to re-implemented AASIST and RawNet2 on the public ASVspoof 5 Track 1 closed condition, using minDCF, EER, memory, and timing metrics. No equations, derivations, or parameter fits are presented that reduce the reported performance numbers to quantities defined inside the same paper by construction. Ablations attribute gains to focal loss, pairwise loss, and attention pooling, but these are standard empirical checks against external baselines rather than self-referential reductions. The work is self-contained against the public benchmark.
Axiom & Free-Parameter Ledger
free parameters (1)
- loss weighting between focal and pairwise terms
axioms (1)
- domain assumption Log-Mel spectrograms contain sufficient information to distinguish genuine from spoofed speech
Reference graph
Works this paper leans on
-
[1]
Natural TTS synthesis by conditioning WaveNet on Mel spectrogram predictions,
J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yang, Z. Chen, Y . Zhang, Y . Wang, R. J. Skerry-Ryan, R. A. Saurous, Y . Agiomyrgian- nakis, and Y . Wu, “Natural TTS synthesis by conditioning WaveNet on Mel spectrogram predictions,” inProc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), 2018, pp. 4779–4783
2018
-
[2]
ASVspoof 2015: The first automatic speaker verification spoofing and countermeasures challenge,
Z. Wu, T. Kinnunen, N. Evans, J. Yamagishi, C. Hanilc ¸i, M. Sahidullah, and A. Sizov, “ASVspoof 2015: The first automatic speaker verification spoofing and countermeasures challenge,” inProc. Interspeech, 2015, pp. 2037–2041
2015
-
[3]
The ASVspoof 2017 challenge: Assessing the limits of replay spoofing attack detection,
T. Kinnunen, M. Sahidullah, H. Delgado, M. Todisco, N. Evans, J. Ya- magishi, and K. A. Lee, “The ASVspoof 2017 challenge: Assessing the limits of replay spoofing attack detection,” inProc. Interspeech, 2017, pp. 2–6
2017
-
[4]
ASVspoof 2019: Future horizons in spoofed and fake audio detection,
M. Todisco, X. Wang, V . Vestman, M. Sahidullah, H. Delgado, A. Nautsch, J. Yamagishi, N. Evans, T. H. Kinnunen, and K. A. Lee, “ASVspoof 2019: Future horizons in spoofed and fake audio detection,” inProc. Interspeech, 2019, pp. 1008–1012
2019
-
[5]
ASVspoof 2021: Accelerating progress in spoofed and deepfake speech detection,
J. Yamagishi, X. Wang, M. Todisco, M. Sahidullah, J. Patino, A. Nautsch, X. Liu, K. A. Lee, T. Kinnunen, N. Evans, and H. Delgado, “ASVspoof 2021: Accelerating progress in spoofed and deepfake speech detection,” inProc. 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge (ASVspoof), 2021, pp. 47–54
2021
-
[6]
ASVspoof 5 evaluation plan,
H. Delgado, N. Evans, J. w. Jung, T. Kinnunen, I. Kukanov, K. A. Lee, X. Liu, H. j. Shim, M. Sahidullah, H. Tak, M. Todisco, X. Wang, and J. Yamagishi, “ASVspoof 5 evaluation plan,” ASVspoof Consortium, Tech. Rep., 2024. [Online]. Available: https://www.asvspoof.org
2024
-
[7]
AASIST: Audio anti-spoofing using integrated spectro-temporal graph attention networks,
J. w. Jung, H.-S. Heo, H. Tak, H. j. Shim, J. S. Chung, B.-J. Lee, H.- J. Yu, and N. Evans, “AASIST: Audio anti-spoofing using integrated spectro-temporal graph attention networks,” inProc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), 2022, pp. 2405–2409
2022
-
[8]
End-to-end anti-spoofing with RawNet2,
H. Tak, J. Patino, M. Todisco, A. Nautsch, N. Evans, and A. Larcher, “End-to-end anti-spoofing with RawNet2,” inProc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), 2021, pp. 6369–6373
2021
-
[9]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017, pp. 5998–6008
2017
-
[10]
Focal loss for dense object detection,
T.-Y . Lin, P. Goyal, R. Girshick, K. He, and P. Doll ´ar, “Focal loss for dense object detection,” inProc. IEEE Int. Conf. Comput. Vis. (ICCV), 2017, pp. 2980–2988
2017
-
[11]
Pairwise discriminative speaker verification in the I-vector space,
S. Cumani, N. Br ¨ummer, L. Burget, P. Laface, O. Plchot, and V . Vasi- lakakis, “Pairwise discriminative speaker verification in the I-vector space,”IEEE/ACM Trans. Audio, Speech, Language Process., vol. 21, no. 6, pp. 1217–1227, 2013
2013
-
[12]
RawBoost: A raw data boosting and augmentation method applied to automatic speaker verification anti-spoofing,
H. Tak, M. Kamble, J. Patino, M. Todisco, and N. Evans, “RawBoost: A raw data boosting and augmentation method applied to automatic speaker verification anti-spoofing,” inProc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), 2022, pp. 6382–6386
2022
-
[13]
MLS: A large-scale multilingual dataset for speech research,
V . Pratap, Q. Xu, A. Sriram, G. Synnaeve, and R. Collobert, “MLS: A large-scale multilingual dataset for speech research,” inProc. Inter- speech, 2020, pp. 2757–2761
2020
-
[14]
Application-independent evaluation of speaker detection,
N. Br ¨ummer and J. du Preez, “Application-independent evaluation of speaker detection,”Computer Speech & Language, vol. 20, no. 2–3, pp. 230–275, 2006
2006
-
[15]
Attentive statistics pooling for deep speaker embedding,
K. Okabe, T. Koshinaka, and K. Shinoda, “Attentive statistics pooling for deep speaker embedding,” inProc. Interspeech, 2018, pp. 2252–2256
2018
-
[16]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inProc. Int. Conf. Learn. Representations (ICLR), 2019. [Online]. Available: https://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[17]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
P. Goyal, P. Doll ´ar, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y . Jia, and K. He, “Accurate, large minibatch SGD: Training ImageNet in 1 hour,”arXiv preprint arXiv:1706.02677, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
SGDR: Stochastic gradient descent with warm restarts,
I. Loshchilov and F. Hutter, “SGDR: Stochastic gradient descent with warm restarts,” inProc. Int. Conf. Learn. Representations (ICLR),
-
[19]
Available: https://openreview.net/forum?id=Skq89Scxx
[Online]. Available: https://openreview.net/forum?id=Skq89Scxx
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.