ConTraIRL: Factorized Contrastive Abstractions for Transferable IRL
Pith reviewed 2026-06-28 11:27 UTC · model grok-4.3
The pith
ConTraIRL decouples dynamics and goals into separate latents to enable reward transfer in IRL to unseen combinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
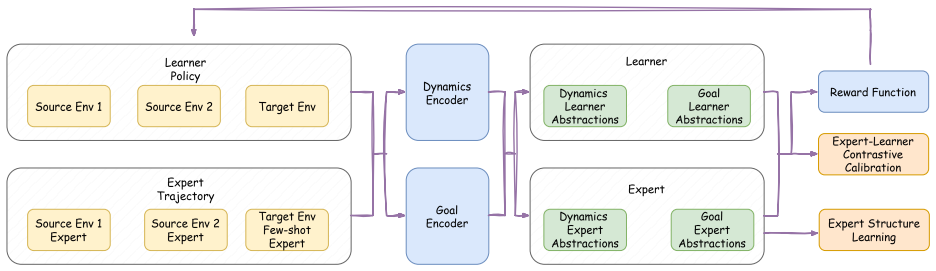
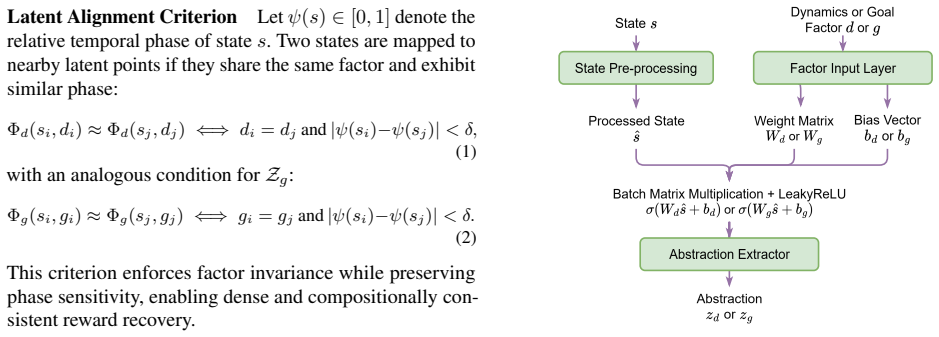
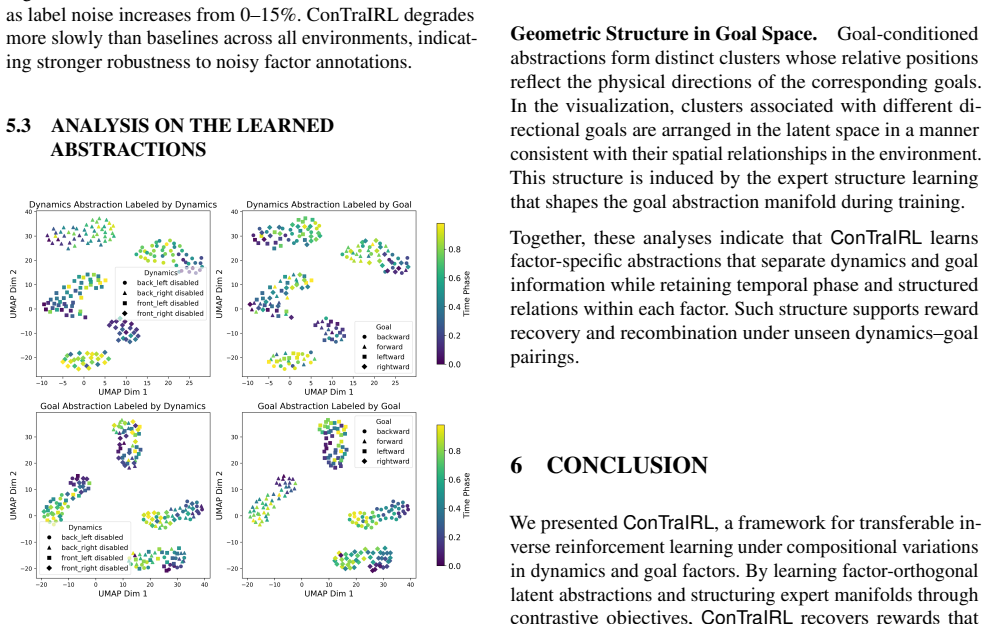
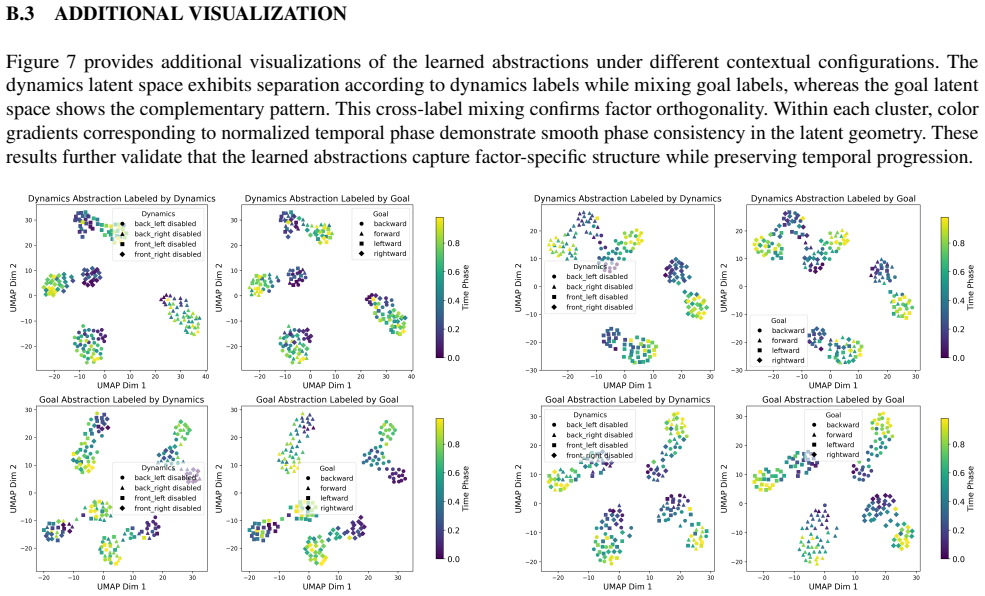
ConTraIRL uses a dual-encoder architecture that maps observations into separate dynamics and goal latent spaces, trained with a dual contrastive objective. Temporal alignment encourages the dynamics encoder to learn goal-invariant structure, while the goal encoder captures dynamics-invariant features. This factorization supports reward inference under recombined dynamics-goal settings.
What carries the argument
Dual-encoder architecture trained with dual contrastive objective that enforces temporal alignment for dynamics invariance and dynamics invariance for goals.
If this is right
- Few-shot transfer becomes possible to previously unseen dynamics-goal pairings.
- Sample efficiency increases during reward recovery in the new settings.
- Reward accuracy exceeds that of existing transfer IRL baselines on continuous control tasks.
Where Pith is reading between the lines
- The same separation might help other RL transfer problems where multiple independent factors must be recombined.
- If the latents remain disentangled at scale, the method could reduce retraining costs when only one factor changes in deployed systems.
- Extending the encoders to handle partial observability or discrete actions would test whether the contrastive alignment generalizes beyond the continuous benchmarks used.
Load-bearing premise
The dual contrastive objective reliably produces decoupled latent representations of dynamics and goals that support accurate reward inference when the factors are recombined.
What would settle it
If reward recovery or sample efficiency on continuous control benchmarks does not improve for unseen dynamics-goal pairings relative to transfer IRL baselines, the factorization claim would fail.
Figures

read the original abstract
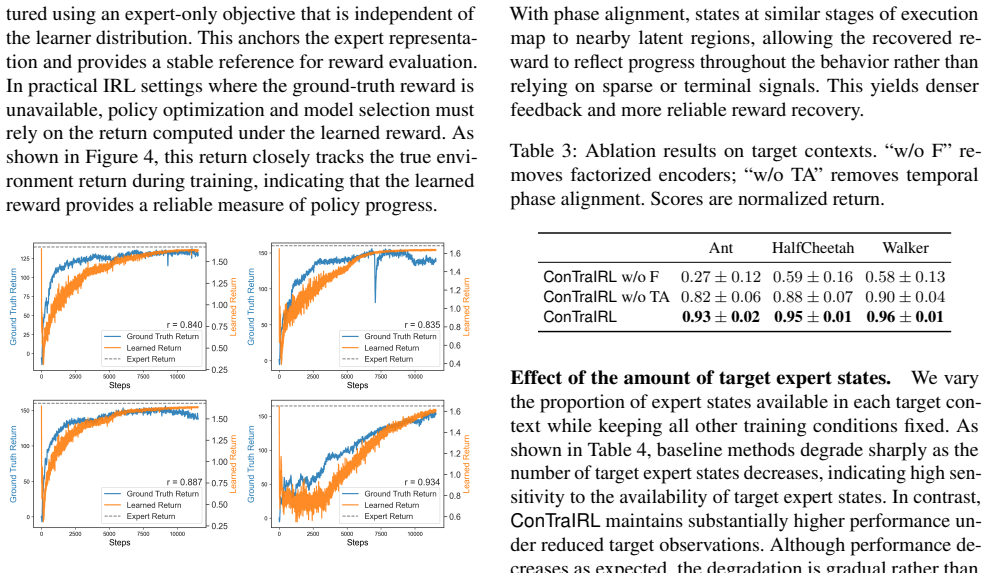
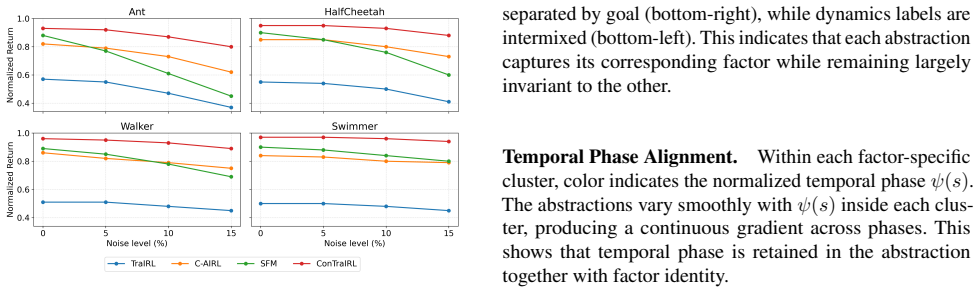
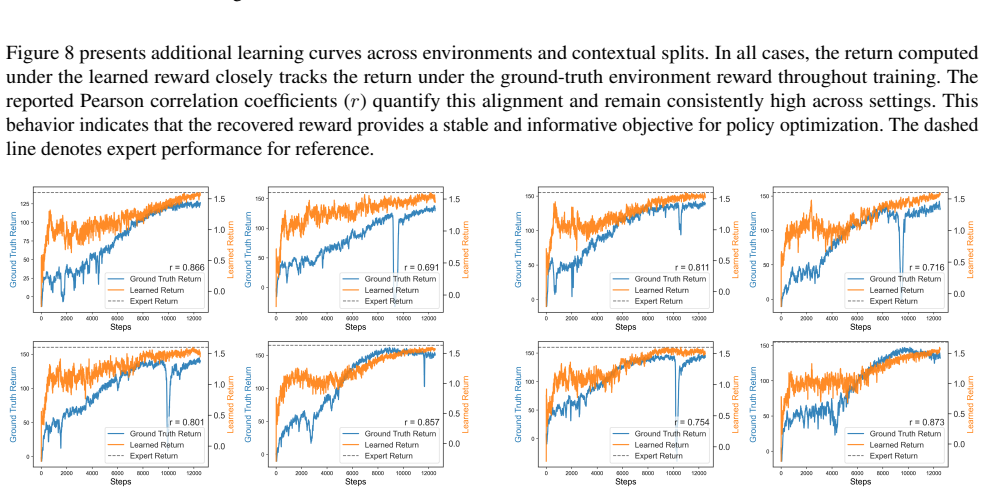
Reward transfer in Inverse Reinforcement Learning (IRL) is unreliable when policies must generalize to unseen combinations of environment dynamics and task goals. We propose Factorized Contrastive Abstractions for Transferable IRL (ConTraIRL), a framework that enables compositional reward transfer by learning decoupled latent representations of these two factors. ConTraIRL uses a dual-encoder architecture that maps observations into separate dynamics and goal latent spaces, trained with a dual contrastive objective. Temporal alignment encourages the dynamics encoder to learn goal-invariant structure, while the goal encoder captures dynamics-invariant features. This factorization supports reward inference under recombined dynamics-goal settings. Experiments on continuous control benchmarks demonstrate effective few-shot transfer to unseen dynamics-goal pairings, improving sample efficiency and reward recovery over transfer IRL baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ConTraIRL, a framework for transferable inverse reinforcement learning that learns decoupled latent representations of environment dynamics and task goals. It employs a dual-encoder architecture trained via a dual contrastive objective, with temporal alignment used to promote goal-invariant dynamics features and dynamics-invariant goal features. This factorization is intended to support reward inference and policy transfer under recombined, unseen dynamics-goal pairings. Experiments on continuous control benchmarks are reported to demonstrate improved few-shot transfer, sample efficiency, and reward recovery relative to transfer IRL baselines.
Significance. If the factorization claim holds with reliable decoupling, the work would address a key limitation in IRL transfer by enabling compositional generalization without retraining on every dynamics-goal combination. The approach is notable for attempting to achieve this via contrastive objectives rather than explicit regularizers, though the strength of the result depends on empirical validation of the latent independence.
major comments (2)
- [Abstract] Abstract: the central claim that the dual contrastive objective with temporal alignment produces dynamics latents that are goal-invariant and goal latents that are dynamics-invariant is load-bearing for the recombination results, yet the abstract provides no explicit independence regularizer, cycle-consistency term, or mutual-information penalty that would guarantee statistical decoupling when dynamics and goals are correlated in the training distribution.
- [Abstract] Abstract: without reported measures (e.g., mutual information estimates or ablation on latent recombination accuracy) it is unclear whether residual correlations remain, which would directly undermine the few-shot transfer improvements claimed for unseen pairings.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for clearer justification of the factorization mechanism in the abstract. We address each comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the dual contrastive objective with temporal alignment produces dynamics latents that are goal-invariant and goal latents that are dynamics-invariant is load-bearing for the recombination results, yet the abstract provides no explicit independence regularizer, cycle-consistency term, or mutual-information penalty that would guarantee statistical decoupling when dynamics and goals are correlated in the training distribution.
Authors: The dual contrastive objective, combined with temporal alignment for positive/negative pair construction, is the mechanism intended to encourage goal-invariant dynamics features and dynamics-invariant goal features. No additional explicit regularizer is used because the contrastive losses directly optimize for the desired separation via the sampling strategy. We will revise the abstract to more explicitly describe how the dual contrastive losses achieve this without relying on supplementary penalties. revision: yes
-
Referee: [Abstract] Abstract: without reported measures (e.g., mutual information estimates or ablation on latent recombination accuracy) it is unclear whether residual correlations remain, which would directly undermine the few-shot transfer improvements claimed for unseen pairings.
Authors: The current experiments focus on downstream transfer performance, but we agree that direct quantification of latent independence would strengthen the claims. We will add mutual information estimates between the two latent spaces and an ablation measuring recombination accuracy under controlled correlation levels in the revised version. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper proposes a new dual-encoder architecture and dual contrastive objective (with temporal alignment) to learn factorized dynamics and goal latents for IRL transfer. No derivation chain is presented that reduces a claimed prediction or first-principles result to its own inputs by construction, nor are there load-bearing self-citations, fitted inputs renamed as predictions, or ansatzes smuggled via prior work. The method is defined explicitly by its components, and claims rest on empirical evaluation rather than self-referential fitting or renaming of known results, rendering the approach self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Environment design for inverse reinforcement learning
Thomas Kleine Buening, Victor Villin, and Christos Dimitrakakis. Environment design for inverse reinforcement learning. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 , volume 235 of Proceedings of Machine Learning Research, pages 24808--24828. PMLR / OpenReview.net, 2024. URL https://proceedings....
2024
-
[2]
Multi-task hierarchical adversarial inverse reinforcement learning
Jiayu Chen, Dipesh Tamboli, Tian Lan, and Vaneet Aggarwal. Multi-task hierarchical adversarial inverse reinforcement learning. In International Conference on Machine Learning, pages 4895--4920. PMLR, 2023
2023
-
[3]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597--1607. PmLR, 2020
2020
-
[4]
Learning robust rewards with adversarial inverse reinforcement learning
Justin Fu, Katie Luo, and Sergey Levine. Learning robust rewards with adversarial inverse reinforcement learning. arXiv preprint arXiv:1710.11248, 2017
Pith/arXiv arXiv 2017
-
[5]
State-only imitation with transition dynamics mismatch
Tanmay Gangwani and Jian Peng. State-only imitation with transition dynamics mismatch. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020 . OpenReview.net, 2020. URL https://openreview.net/forum?id=HJgLLyrYwB
2020
-
[6]
Iq-learn: Inverse soft-q learning for imitation
Divyansh Garg, Shuvam Chakraborty, Chris Cundy, Jiaming Song, and Stefano Ermon. Iq-learn: Inverse soft-q learning for imitation. Advances in Neural Information Processing Systems, 34: 0 4028--4039, 2021
2021
-
[7]
Inversely Learning Transferable Rewards via Abstracted States
Yikang Gui and Prashant Doshi. Inversely learning transferable rewards via abstracted states. CoRR, abs/2501.01669, 2025. doi:10.48550/ARXIV.2501.01669. URL https://doi.org/10.48550/arXiv.2501.01669
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.01669 2025
-
[8]
Dai, and Quoc V
David Ha, Andrew M. Dai, and Quoc V. Le. Hypernetworks. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings . OpenReview.net, 2017. URL https://openreview.net/forum?id=rkpACe1lx
2017
-
[9]
Generative adversarial imitation learning
Jonathan Ho and Stefano Ermon. Generative adversarial imitation learning. Advances in neural information processing systems, 29, 2016
2016
-
[10]
Non-adversarial inverse reinforcement learning via successor feature matching
Arnav Kumar Jain, Harley Wiltzer, Jesse Farebrother, Irina Rish, Glen Berseth, and Sanjiban Choudhury. Non-adversarial inverse reinforcement learning via successor feature matching. arXiv preprint arXiv:2411.07007, 2024
arXiv 2024
-
[11]
Supervised contrastive learning
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning. Advances in neural information processing systems, 33: 0 18661--18673, 2020
2020
-
[12]
Adversarial self-supervised contrastive learning
Minseon Kim, Jihoon Tack, and Sung Ju Hwang. Adversarial self-supervised contrastive learning. Advances in neural information processing systems, 33: 0 2983--2994, 2020
2020
-
[13]
Tw-crl: Time-weighted contrastive reward learning for efficient inverse reinforcement learning
Yuxuan Li, Yicheng Gao, Ning Yang, and Stephen Xia. Tw-crl: Time-weighted contrastive reward learning for efficient inverse reinforcement learning. arXiv preprint arXiv:2504.05585, 2025
arXiv 2025
-
[14]
Umap: Uniform manifold approximation and projection for dimension reduction
Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426, 2018
Pith/arXiv arXiv 2018
-
[15]
Comi-irl: Contrastive multi-intention inverse reinforcement learning
Antonio Mone, Frans A Oliehoek, and Luciano Cavalcante Siebert. Comi-irl: Contrastive multi-intention inverse reinforcement learning. arXiv preprint arXiv:2602.07496, 2026
arXiv 2026
-
[16]
Multi-modal inverse constrained reinforcement learning from a mixture of demonstrations
Guanren Qiao, Guiliang Liu, Pascal Poupart, and Zhiqiang Xu. Multi-modal inverse constrained reinforcement learning from a mixture of demonstrations. Advances in Neural Information Processing Systems, 36: 0 60384--60396, 2023
2023
-
[17]
Dec-airl: Decentralized adversarial irl for human-robot teaming
Prasanth Sengadu Suresh, Yikang Gui, and Prashant Doshi. Dec-airl: Decentralized adversarial irl for human-robot teaming. In Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems, pages 1116--1124, 2023
2023
-
[18]
What makes for good views for contrastive learning? Advances in neural information processing systems, 33: 0 6827--6839, 2020
Yonglong Tian, Chen Sun, Ben Poole, Dilip Krishnan, Cordelia Schmid, and Phillip Isola. What makes for good views for contrastive learning? Advances in neural information processing systems, 33: 0 6827--6839, 2020
2020
-
[19]
Meta-inverse reinforcement learning with probabilistic context variables
Lantao Yu, Tianhe Yu, Chelsea Finn, and Stefano Ermon. Meta-inverse reinforcement learning with probabilistic context variables. Advances in neural information processing systems, 32, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.