Hallucinations as Orthogonal Noise: Inference-Time Manifold Alignment via Dynamic Contextual Orthogonalization
Pith reviewed 2026-06-28 10:49 UTC · model grok-4.3
The pith
Large language models generate hallucinations when attention heads inject orthogonal noise into the residual stream, and this can be corrected at inference time by dynamic contextual orthogonalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
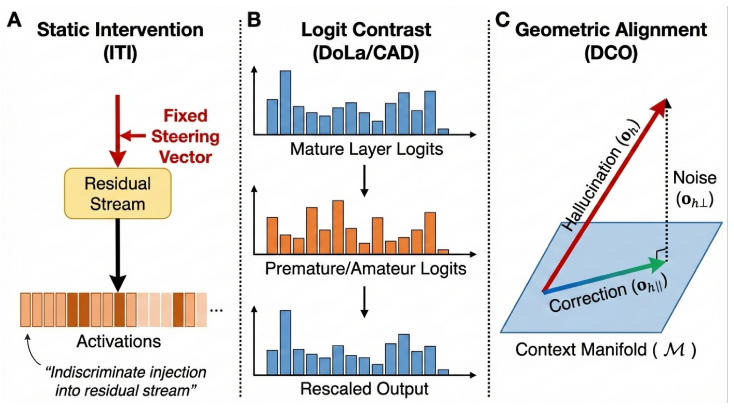
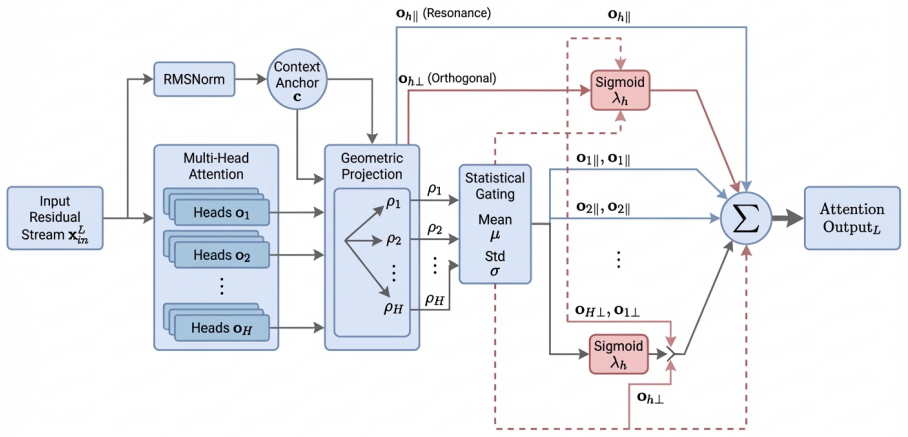
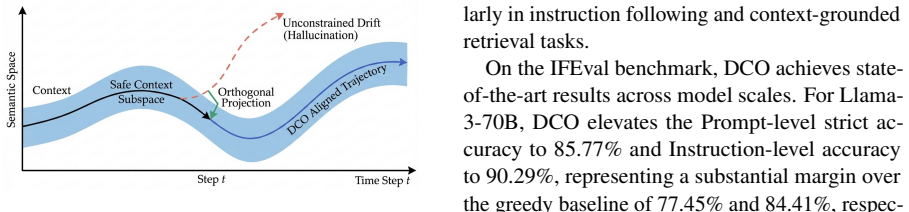
Hallucinations manifest as orthogonal noise relative to the semantic manifold of the residual stream. While attention heads ideally propagate information congruent with the context subspace, hallucinations arise when specific heads introduce components orthogonal to this subspace, disrupting the coherence of the latent representation. DCO utilizes the input residual stream as a dynamic context anchor to perform orthogonal decomposition on attention head outputs and employs a layer-wise Z-score suppression mechanism that selectively attenuates outlier orthogonal components based on statistical distributions.
What carries the argument
Dynamic Contextual Orthogonalization (DCO), which decomposes attention head outputs relative to the input residual stream and suppresses statistically outlier orthogonal components via per-layer Z-score thresholds.
If this is right
- DCO produces higher contextual faithfulness than prior intervention baselines on XSum, NQ-Swap, and IFEval.
- Performance on knowledge-intensive tasks such as TriviaQA and TruthfulQA remains high.
- The usual trade-off between hallucination suppression and parametric knowledge retention is reduced.
- The geometric interpretation of hallucinations as orthogonal noise receives empirical support.
- Manifold alignment can be enforced with a computationally efficient inference-time procedure.
Where Pith is reading between the lines
- If the orthogonal-noise account is accurate, similar decomposition steps might be applied to other generation inconsistencies such as logical contradictions or style drift.
- The method could be layered with existing fine-tuning techniques to create more robust deployed systems.
- Testing the same orthogonalization procedure on models trained for specialized domains would show whether domain-specific errors follow the same geometric pattern.
- Wider use might lower reliance on post-hoc filtering or human review in contexts that demand strict prompt adherence.
Load-bearing premise
Hallucinations arise specifically when attention heads introduce components orthogonal to the context subspace in the residual stream, and these components can be reliably identified and attenuated via layer-wise Z-score suppression without harming semantic content.
What would settle it
Running DCO on Llama-3-8B and finding that hallucination rates on XSum or NQ-Swap remain unchanged while TriviaQA accuracy drops measurably.
Figures



read the original abstract
Hallucination in Large Language Models (LLMs), characterized by the generation of content inconsistent with contextual facts or logical constraints -- remains a persistent challenge for reliable deployment. In this work, we address this issue through a geometric framework rooted in the linear representation hypothesis. We propose that hallucinations manifest as orthogonal noise relative to the semantic manifold of the residual stream. Specifically, we hypothesize that while attention heads ideally propagate information congruent with the context subspace, hallucinations arise when specific heads introduce components orthogonal to this subspace, disrupting the coherence of the latent representation. Based on this formulation, we introduce Dynamic Contextual Orthogonalization (DCO), an inference-time intervention method. DCO utilizes the input residual stream as a dynamic context anchor to perform orthogonal decomposition on attention head outputs. To distinguish between context-aligned semantic updates and divergent noise, DCO employs a layer-wise Z-score suppression mechanism that selectively attenuates outlier orthogonal components based on statistical distributions. Evaluations on Llama-3-8B and 70B across benchmarks such as XSum, NQ-Swap, and IFEval demonstrate that DCO achieves superior contextual faithfulness compared to state-of-the-art intervention baselines. Furthermore, DCO maintains high performance on knowledge-intensive tasks like TriviaQA and TruthfulQA, effectively mitigating the trade-off between hallucination suppression and parametric knowledge retention often observed in existing methods. Our findings validate the geometric interpretation of hallucinations and establish DCO as a computationally efficient approach for enforcing manifold alignment.Our code is available at https://github.com/Harry-Miral/DCO
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that hallucinations arise as orthogonal noise to the context subspace in the residual stream of LLMs. It introduces Dynamic Contextual Orthogonalization (DCO), an inference-time intervention that decomposes attention head outputs against the input residual stream as a dynamic anchor and applies layer-wise Z-score suppression to attenuate outlier orthogonal components. On Llama-3-8B and 70B, DCO is reported to outperform baselines on contextual faithfulness benchmarks (XSum, NQ-Swap, IFEval) while preserving performance on knowledge-intensive tasks (TriviaQA, TruthfulQA).
Significance. If the geometric framing and empirical results hold, the work would offer a lightweight, training-free method for enforcing manifold alignment at inference time, potentially reducing the typical trade-off between hallucination mitigation and retention of parametric knowledge. Code availability supports reproducibility.
major comments (2)
- [Abstract] Abstract: the central claim that DCO achieves superior contextual faithfulness rests on the unvalidated hypothesis that attention heads introduce suppressible orthogonal noise; no equations, ablation studies, or implementation details are provided to confirm that the input residual stream spans the relevant semantic manifold or that flagged outliers are causally responsible for hallucinations rather than carrying useful signals.
- [Experiments] The manuscript does not describe an equivalent-magnitude random-direction ablation; without it, maintained TriviaQA/TruthfulQA scores do not rule out that suppression functions as generic regularization, weakening both the geometric interpretation and the superiority claim over baselines.
minor comments (1)
- The abstract states code is available at a GitHub link but provides no details on hyperparameters, exact layer-wise Z-score thresholds, or how the orthogonal decomposition is computed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications from the manuscript and indicate proposed revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that DCO achieves superior contextual faithfulness rests on the unvalidated hypothesis that attention heads introduce suppressible orthogonal noise; no equations, ablation studies, or implementation details are provided to confirm that the input residual stream spans the relevant semantic manifold or that flagged outliers are causally responsible for hallucinations rather than carrying useful signals.
Authors: The full manuscript details the geometric hypothesis and DCO formulation in Section 3, including the orthogonal decomposition of attention head outputs against the input residual stream (used as dynamic anchor) and the layer-wise Z-score suppression of outlier components. Section 4.3 presents ablations on the Z-score threshold and per-layer application. The input residual stream is selected because it encodes the accumulated context at each step under the linear representation hypothesis. While we do not claim per-component causal proof (which would require head-level interventions not performed here), the pattern of gains on XSum/NQ-Swap/IFEval with no loss on TriviaQA/TruthfulQA supports that the attenuated components function as noise. We will expand the abstract to explicitly reference these sections and add a short paragraph on the manifold assumption. revision: partial
-
Referee: [Experiments] The manuscript does not describe an equivalent-magnitude random-direction ablation; without it, maintained TriviaQA/TruthfulQA scores do not rule out that suppression functions as generic regularization, weakening both the geometric interpretation and the superiority claim over baselines.
Authors: This is a fair point that would strengthen the geometric claim. We will add the requested ablation in the revised Section 4.3: suppression applied along random directions whose magnitudes match those of the DCO-identified orthogonal components. We anticipate this control will degrade both faithfulness and knowledge-task performance, in contrast to DCO's selective effect, thereby supporting the interpretation that the benefit is not generic regularization. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper states a hypothesis that hallucinations arise as orthogonal components to the context subspace and defines DCO as the intervention that performs orthogonal decomposition against the input residual stream followed by layer-wise Z-score suppression. No equations are shown that equate the claimed performance gains to fitted parameters or to the hypothesis by construction. The method is presented as a new inference-time procedure whose superiority is asserted via benchmark results on XSum, NQ-Swap, IFEval, TriviaQA and TruthfulQA rather than by algebraic identity with its inputs. No self-citation load-bearing steps, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation appear in the provided text. The derivation is therefore self-contained as a proposed geometric intervention with external empirical support.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear representation hypothesis
invented entities (1)
-
orthogonal noise
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
A mathematical perspective on Transformers , author=. 2025 , eprint=
2025
-
[2]
2022 , eprint=
In-context Learning and Induction Heads , author=. 2022 , eprint=
2022
-
[3]
2024 , eprint=
Retrieval Head Mechanistically Explains Long-Context Factuality , author=. 2024 , eprint=
2024
-
[4]
2023 , eprint=
Progress measures for grokking via mechanistic interpretability , author=. 2023 , eprint=
2023
-
[5]
2024 , eprint=
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. 2024 , eprint=
2024
-
[6]
Inference-time intervention: eliciting truthful answers from a language model , year =
Li, Kenneth and Patel, Oam and Vi\'. Inference-time intervention: eliciting truthful answers from a language model , year =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
-
[9]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages=
Trusting your evidence: Hallucinate less with context-aware decoding , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages=
2024
-
[11]
2024 , eprint=
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. 2024 , eprint=
2024
-
[12]
2024 , eprint=
Linearity of Relation Decoding in Transformer Language Models , author=. 2024 , eprint=
2024
-
[13]
2025 , eprint=
Representation Engineering: A Top-Down Approach to AI Transparency , author=. 2025 , eprint=
2025
-
[14]
Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[24]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[25]
ArXiv , year=
Instruction-Following Evaluation for Large Language Models , author=. ArXiv , year=
-
[26]
2022 , eprint=
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author=. 2022 , eprint=
2022
-
[27]
2017 , eprint=
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension , author=. 2017 , eprint=
2017
-
[29]
2022 , eprint=
MuSiQue: Multihop Questions via Single-hop Question Composition , author=. 2022 , eprint=
2022
-
[30]
2020 , eprint=
BERTScore: Evaluating Text Generation with BERT , author=. 2020 , eprint=
2020
-
[31]
2024 , eprint=
Language Models Represent Space and Time , author=. 2024 , eprint=
2024
-
[32]
2024 , eprint=
TeleChat Technical Report , author=. 2024 , eprint=
2024
-
[33]
T ele C hat: An Open-source Billingual Large Language Model
Wang, Zihan and Liu, XinZhang and Liu, Shixuan and Yao, Yitong and Huang, Yunyao and Li, Mengxiang and He, Zhongjiang and Li, Yongxian and Pu, Luwen and Xu, Huinan and Wang, Chao and Song, Shuangyong. T ele C hat: An Open-source Billingual Large Language Model. Proceedings of the 10th SIGHAN Workshop on Chinese Language Processing (SIGHAN-10). 2024
2024
-
[34]
2025 , eprint=
Technical Report of TeleChat2, TeleChat2.5 and T1 , author=. 2025 , eprint=
2025
-
[35]
2025 , eprint=
Training Report of TeleChat3-MoE , author=. 2025 , eprint=
2025
-
[36]
2024 , eprint=
Tele-FLM Technical Report , author=. 2024 , eprint=
2024
-
[37]
2024 , eprint=
52B to 1T: Lessons Learned via Tele-FLM Series , author=. 2024 , eprint=
2024
-
[38]
2025 , eprint=
MR-UIE: Multi-Perspective Reasoning with Reinforcement Learning for Universal Information Extraction , author=. 2025 , eprint=
2025
-
[39]
2025 , eprint=
TableReasoner: Advancing Table Reasoning Framework with Large Language Models , author=. 2025 , eprint=
2025
-
[40]
Knowledge-Based Systems , volume=
Enhancing math reasoning ability of large language models via computation logic graphs , author=. Knowledge-Based Systems , volume=. 2025 , publisher=
2025
-
[42]
2025 , eprint=
Mosaic Pruning: A Hierarchical Framework for Generalizable Pruning of Mixture-of-Experts Models , author=. 2025 , eprint=
2025
-
[43]
2025 , eprint=
Making Every Head Count: Sparse Attention Without the Speed-Performance Trade-off , author=. 2025 , eprint=
2025
-
[44]
Shiqi Chen, Miao Xiong, Junteng Liu, Zhengxuan Wu, Teng Xiao, Siyang Gao, and Junxian He. 2024. In-context sharpness as alerts: An inner representation perspective for hallucination mitigation. arXiv preprint arXiv:2403.01548
arXiv 2024
-
[45]
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James Glass, and Pengcheng He. 2023. Dola: Decoding by contrasting layers improves factuality in large language models. arXiv preprint arXiv:2309.03883
Pith/arXiv arXiv 2023
-
[46]
Guy Dar, Mor Geva, Ankit Gupta, and Jonathan Berant. 2023. https://doi.org/10.18653/v1/2023.acl-long.893 Analyzing transformers in embedding space . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16124--16170, Toronto, Canada. Association for Computational Linguistics
-
[47]
Shangbin Feng, Vidhisha Balachandran, Yuyang Bai, and Yulia Tsvetkov. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.59 F act KB : Generalizable factuality evaluation using language models enhanced with factual knowledge . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 933--952, Singapore. Association f...
-
[48]
Aryo Pradipta Gema, Chen Jin, Ahmed Abdulaal, Tom Diethe, Philip Teare, Beatrice Alex, Pasquale Minervini, and Amrutha Saseendran. 2024. Decore: Decoding by contrasting retrieval heads to mitigate hallucinations. arXiv preprint arXiv:2410.18860
arXiv 2024
-
[49]
Ariel Gera, Roni Friedman, Ofir Arviv, Chulaka Gunasekara, Benjamin Sznajder, Noam Slonim, and Eyal Shnarch. 2023. https://doi.org/10.18653/v1/2023.acl-long.580 The benefits of bad advice: Autocontrastive decoding across model layers . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages...
-
[50]
Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.751 Dissecting recall of factual associations in auto-regressive language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12216--12235, Singapore. Association for Computational Linguistics
-
[51]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
Pith/arXiv arXiv 2024
-
[52]
Wes Gurnee and Max Tegmark. 2024. https://arxiv.org/abs/2310.02207 Language models represent space and time . Preprint, arXiv:2310.02207
arXiv 2024
-
[53]
Zhongjiang He, Zihan Wang, Xinzhang Liu, Shixuan Liu, Yitong Yao, Yuyao Huang, Xuelong Li, Yongxiang Li, Zhonghao Che, Zhaoxi Zhang, Yan Wang, Xin Wang, Luwen Pu, Huinan Xu, Ruiyu Fang, Yu Zhao, Jie Zhang, Xiaomeng Huang, Zhilong Lu, and 17 others. 2024. https://arxiv.org/abs/2401.03804 Telechat technical report . Preprint, arXiv:2401.03804
arXiv 2024
-
[54]
Evan Hernandez, Arnab Sen Sharma, Tal Haklay, Kevin Meng, Martin Wattenberg, Jacob Andreas, Yonatan Belinkov, and David Bau. 2024. https://arxiv.org/abs/2308.09124 Linearity of relation decoding in transformer language models . Preprint, arXiv:2308.09124
arXiv 2024
-
[55]
Wentao Hu, Mingkuan Zhao, Shuangyong Song, Xiaoyan Zhu, Xin Lai, and Jiayin Wang. 2025. https://arxiv.org/abs/2511.19822 Mosaic pruning: A hierarchical framework for generalizable pruning of mixture-of-experts models . Preprint, arXiv:2511.19822
arXiv 2025
-
[56]
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. 2017. https://arxiv.org/abs/1705.03551 Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension . Preprint, arXiv:1705.03551
Pith/arXiv arXiv 2017
-
[57]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. https://doi.org/10.1162/tacl_a_00276 Natural questions: A benchma...
-
[58]
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. 2024 a . https://arxiv.org/abs/2306.03341 Inference-time intervention: Eliciting truthful answers from a language model . Preprint, arXiv:2306.03341
Pith/arXiv arXiv 2024
-
[59]
Xiang Li, Yiqun Yao, Xin Jiang, Xuezhi Fang, Chao Wang, Xinzhang Liu, Zihan Wang, Yu Zhao, Xin Wang, Yuyao Huang, Shuangyong Song, Yongxiang Li, Zheng Zhang, Bo Zhao, Aixin Sun, Yequan Wang, Zhongjiang He, Zhongyuan Wang, Xuelong Li, and Tiejun Huang. 2024 b . https://arxiv.org/abs/2407.02783 52b to 1t: Lessons learned via tele-flm series . Preprint, arXi...
arXiv 2024
-
[60]
Xiang Li, Yiqun Yao, Xin Jiang, Xuezhi Fang, Chao Wang, Xinzhang Liu, Zihan Wang, Yu Zhao, Xin Wang, Yuyao Huang, Shuangyong Song, Yongxiang Li, Zheng Zhang, Bo Zhao, Aixin Sun, Yequan Wang, Zhongjiang He, Zhongyuan Wang, Xuelong Li, and Tiejun Huang. 2024 c . https://arxiv.org/abs/2404.16645 Tele-flm technical report . Preprint, arXiv:2404.16645
arXiv 2024
-
[61]
Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori Hashimoto, Luke Zettlemoyer, and Mike Lewis. 2023. https://doi.org/10.18653/v1/2023.acl-long.687 Contrastive decoding: Open-ended text generation as optimization . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers...
-
[62]
Zhongqiu Li, Shiquan Wang, Ruiyu Fang, Mengjiao Bao, Zhenhe Wu, Shuangyong Song, Yongxiang Li, and Zhongjiang He. 2025. https://arxiv.org/abs/2509.09082 Mr-uie: Multi-perspective reasoning with reinforcement learning for universal information extraction . Preprint, arXiv:2509.09082
arXiv 2025
-
[63]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. https://arxiv.org/abs/2109.07958 Truthfulqa: Measuring how models mimic human falsehoods . Preprint, arXiv:2109.07958
Pith/arXiv arXiv 2022
-
[64]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. https://doi.org/10.1162/tacl_a_00638 Lost in the middle: How language models use long contexts . Transactions of the Association for Computational Linguistics, 12:157--173
-
[65]
Xinzhang Liu, Chao Wang, Zhihao Yang, Zhuo Jiang, Xuncheng Zhao, Haoran Wang, Lei Li, Dongdong He, Luobin Liu, Kaizhe Yuan, Han Gao, Zihan Wang, Yitong Yao, Sishi Xiong, Wenmin Deng, Haowei He, Kaidong Yu, Yu Zhao, Ruiyu Fang, and 35 others. 2025. https://arxiv.org/abs/2512.24157 Training report of telechat3-moe . Preprint, arXiv:2512.24157
arXiv 2025
-
[66]
Shayne Longpre, Kartik Perisetla, Anthony Chen, Nikhil Ramesh, Chris DuBois, and Sameer Singh. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.565 Entity-based knowledge conflicts in question answering . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7052--7063, Online and Punta Cana, Dominican Republic....
-
[67]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in gpt. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS '22, Red Hook, NY, USA. Curran Associates Inc
2022
-
[68]
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. 2023. https://arxiv.org/abs/2301.05217 Progress measures for grokking via mechanistic interpretability . Preprint, arXiv:2301.05217
Pith/arXiv arXiv 2023
-
[69]
Shashi Narayan, Shay B. Cohen, and Mirella Lapata. 2018. https://doi.org/10.18653/v1/D18-1206 Don ' t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1797--1807, Brussels, Belgium. Association for Co...
-
[70]
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, and 7 others. 2022. https://arxiv.org/abs/2209.11895 In-context learning and induct...
Pith/arXiv arXiv 2022
-
[71]
Kiho Park, Yo Joong Choe, and Victor Veitch. 2024. https://arxiv.org/abs/2311.03658 The linear representation hypothesis and the geometry of large language models . Preprint, arXiv:2311.03658
Pith/arXiv arXiv 2024
-
[72]
Weijia Shi, Xiaochuang Han, Mike Lewis, Yulia Tsvetkov, Luke Zettlemoyer, and Wen-tau Yih. 2024. Trusting your evidence: Hallucinate less with context-aware decoding. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), pages 783--791
2024
-
[73]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. https://arxiv.org/abs/2108.00573 Musique: Multihop questions via single-hop question composition . Preprint, arXiv:2108.00573
arXiv 2022
-
[74]
Zihan Wang, XinZhang Liu, Shixuan Liu, Yitong Yao, Yunyao Huang, Mengxiang Li, Zhongjiang He, Yongxian Li, Luwen Pu, Huinan Xu, Chao Wang, and Shuangyong Song. 2024. https://aclanthology.org/2024.sighan-1.2/ T ele C hat: An open-source billingual large language model . In Proceedings of the 10th SIGHAN Workshop on Chinese Language Processing (SIGHAN-10), ...
2024
-
[75]
Zihan Wang, Xinzhang Liu, Yitong Yao, Chao Wang, Yu Zhao, Zhihao Yang, Wenmin Deng, Kaipeng Jia, Jiaxin Peng, Yuyao Huang, Sishi Xiong, Zhuo Jiang, Kaidong Yu, Xiaohui Hu, Fubei Yao, Ruiyu Fang, Zhuoru Jiang, Ruiting Song, Qiyi Xie, and 19 others. 2025. https://arxiv.org/abs/2507.18013 Technical report of telechat2, telechat2.5 and t1 . Preprint, arXiv:2507.18013
arXiv 2025
-
[76]
Wenhao Wu, Yizhong Wang, Guangxuan Xiao, Hao Peng, and Yao Fu. 2024. https://arxiv.org/abs/2404.15574 Retrieval head mechanistically explains long-context factuality . Preprint, arXiv:2404.15574
arXiv 2024
-
[77]
Hongrui Xing, Xinzhang Liu, Zhuo Jiang, Zhihao Yang, Yitong Yao, Zihan Wang, Wenmin Deng, Chao Wang, Shuangyong Song, Wang Yang, Zhongjiang He, and Yongxiang Li. 2025. https://doi.org/10.18653/v1/2025.xllm-1.31 LLMSR @ XLLM 25: A language model-based pipeline for structured reasoning data construction . In Proceedings of the 1st Joint Workshop on Large La...
-
[78]
Sishi Xiong, Dakai Wang, Yu Zhao, Jie Zhang, Changzai Pan, Haowei He, Xiangyu Li, Wenhan Chang, Zhongjiang He, Shuangyong Song, and Yongxiang Li. 2025. https://arxiv.org/abs/2507.08046 Tablereasoner: Advancing table reasoning framework with large language models . Preprint, arXiv:2507.08046
arXiv 2025
-
[79]
Lei Yu, Meng Cao, Jackie CK Cheung, and Yue Dong. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.466 Mechanistic understanding and mitigation of language model non-factual hallucinations . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 7943--7956, Miami, Florida, USA. Association for Computational Linguistics
-
[80]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. https://arxiv.org/abs/1904.09675 Bertscore: Evaluating text generation with bert . Preprint, arXiv:1904.09675
Pith/arXiv arXiv 2020
-
[81]
Deji Zhao, Donghong Han, Jia Wu, Zhongjiang He, Bo Ning, Ye Yuan, Yongxiang Li, Chao Wang, and Shuangyong Song. 2025 a . Enhancing math reasoning ability of large language models via computation logic graphs. Knowledge-Based Systems, 325:113905
2025
-
[82]
Mingkuan Zhao, Wentao Hu, Jiayin Wang, Xin Lai, Tianchen Huang, Yuheng Min, Rui Yan, and Xiaoyan Zhu. 2025 b . https://arxiv.org/abs/2511.09596 Making every head count: Sparse attention without the speed-performance trade-off . Preprint, arXiv:2511.09596
arXiv 2025
-
[83]
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. 2023. https://api.semanticscholar.org/CorpusID:265157752 Instruction-following evaluation for large language models . ArXiv, abs/2311.07911
Pith/arXiv arXiv 2023
-
[84]
Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, and 2 others
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, and 2 others. 2025. https://arxiv.org/abs/2310.01405 Representation engineering: A top-...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.