Learn When and Where to Connect: Adaptive Virtual Nodes for Dynamic Message Passing on Graphs
Pith reviewed 2026-06-28 11:12 UTC · model grok-4.3
The pith
MAVN learns to dynamically introduce and connect virtual nodes in message passing neural networks based on learned importance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
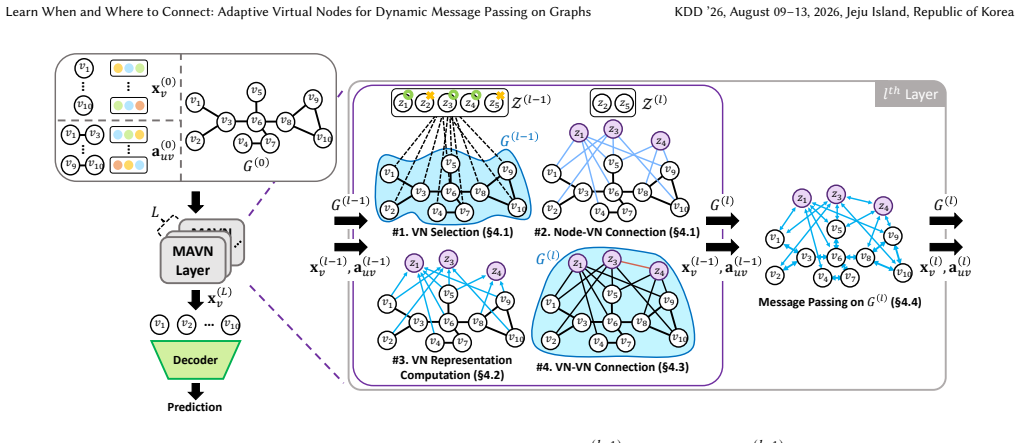
MAVN is an end-to-end differentiable MPNN framework that allows non-constrained connections between nodes and VNs and dynamically introduces VNs on demand in response to evolving node representations across layers. Specifically, MAVN learns to adaptively determine when (at which layer) and where (to which nodes) to introduce and connect VNs based on the relative importance of connections. From a pool of candidate VNs, MAVN selects the necessary VNs in each layer, where each selected VN is connected to a nonempty subset of nodes, guided by a dual-perspective scoring mechanism that jointly captures the nodes' preferences for VNs and the VNs' preferences for nodes. The authors theoretically pro
What carries the argument
The dual-perspective scoring mechanism that jointly captures nodes' preferences for VNs and VNs' preferences for nodes to decide dynamic introductions and connections.
If this is right
- MAVN can simulate any node-VN connectivity pattern with appropriate parameter choices.
- MAVN consistently improves the performance of backbone MPNNs.
- MAVN outperforms baselines on nine real-world datasets with gains up to 46.5 percent over the backbones.
Where Pith is reading between the lines
- The per-layer selection could allow virtual nodes to be used more sparingly, reducing computation on large graphs compared with always-on fixed VNs.
- Similar mutual-preference scoring might be applied to other adaptive choices in graph models, such as which edges or attention heads to activate.
- Because it can emulate any fixed pattern, MAVN offers a single implementation for comparing many different virtual-node strategies without changing the model architecture.
Load-bearing premise
The dual-perspective scoring mechanism, when trained end-to-end, reliably identifies the relative importance of node-VN connections without optimization difficulties or overfitting to the training graphs.
What would settle it
Training MAVN on a graph where optimal VN connections are known in advance and checking whether the learned connections recover a pattern close to the optimum or deliver the expected performance gain over fixed baselines.
Figures

read the original abstract
While Virtual Nodes (VNs) are often utilized in Message Passing Neural Networks (MPNNs) to facilitate effective message passing, existing VN-based methods have limitations, such as constraining all nodes to connect to the same number of VNs, fixing the connections before applying MPNNs, and connecting a node to a VN independently of the other nodes that connect to the same VN. We propose MAVN, an end-to-end differentiable MPNN framework that allows non-constrained connections between nodes and VNs and dynamically introduces VNs on demand in response to evolving node representations across layers. Specifically, MAVN learns to adaptively determine when (at which layer) and where (to which nodes) to introduce and connect VNs based on the relative importance of connections. From a pool of candidate VNs, MAVN selects the necessary VNs in each layer, where each selected VN is connected to a nonempty subset of nodes, guided by a dual-perspective scoring mechanism that jointly captures the nodes' preferences for VNs and the VNs' preferences for nodes. We theoretically prove that for any node-VN connectivity pattern, there exists a set of MAVN's parameters that can simulate the pattern. Experiments on nine real-world datasets demonstrate that MAVN consistently improves the performance of backbone MPNNs, achieving up to 46.5% improvement over the backbones and outperforms the baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MAVN, an end-to-end differentiable MPNN framework with adaptive virtual nodes that dynamically selects and connects VNs across layers via a dual-perspective scoring mechanism. It proves that for any fixed node-VN connectivity pattern there exist MAVN parameters realizing it, and reports that MAVN improves backbone MPNNs by up to 46.5% while outperforming baselines on nine real-world datasets.
Significance. If the reported gains prove robust, the adaptive VN mechanism could meaningfully extend MPNN expressiveness for tasks requiring dynamic, non-uniform message routing. The existence proof is a clear theoretical strength, establishing that the architecture is at least as expressive as any fixed VN connectivity pattern.
major comments (3)
- [§3] §3 (Theoretical Result): The proof shows existence of parameters simulating any connectivity pattern but provides no analysis of whether gradient-based training of the dual-perspective scores can reach non-trivial patterns; the non-convex joint optimization landscape is not characterized.
- [§5] §5 (Experiments): The 46.5% improvement figure and all accuracy gains are reported without error bars, number of runs, dataset statistics, or specification of which backbone/dataset yields the maximum; this prevents assessment of robustness or post-hoc selection.
- [§2.3] §2.3 (Dual-Perspective Scoring): No ablation or diagnostic is given on whether the learned node-to-VN and VN-to-node scores avoid collapse to uniform or training-set-specific connections, which is load-bearing for the claim that end-to-end training discovers useful dynamic patterns.
minor comments (2)
- [Abstract] The abstract and §5 do not state the precise backbone, dataset, and metric underlying the 46.5% figure.
- [§2] Notation for the candidate VN pool size and selection threshold is introduced without an explicit equation reference in the method section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [§3] §3 (Theoretical Result): The proof shows existence of parameters simulating any connectivity pattern but provides no analysis of whether gradient-based training of the dual-perspective scores can reach non-trivial patterns; the non-convex joint optimization landscape is not characterized.
Authors: Our theoretical result in §3 establishes that MAVN can realize any fixed node-VN connectivity pattern via suitable parameter choices, which is the intended claim. We agree that the manuscript does not analyze whether gradient-based optimization of the dual-perspective scores reliably reaches non-trivial patterns in the non-convex landscape. The empirical improvements over fixed-VN baselines on nine datasets provide indirect evidence that useful patterns are discovered in practice, but a full characterization of the optimization dynamics is beyond the scope of this work. revision: no
-
Referee: [§5] §5 (Experiments): The 46.5% improvement figure and all accuracy gains are reported without error bars, number of runs, dataset statistics, or specification of which backbone/dataset yields the maximum; this prevents assessment of robustness or post-hoc selection.
Authors: We agree that the experimental section lacks sufficient statistical detail. In the revised manuscript we will report all results with error bars (standard deviation over multiple random seeds), explicitly state the number of runs, include key dataset statistics, and identify the specific backbone and dataset achieving the 46.5% maximum improvement. revision: yes
-
Referee: [§2.3] §2.3 (Dual-Perspective Scoring): No ablation or diagnostic is given on whether the learned node-to-VN and VN-to-node scores avoid collapse to uniform or training-set-specific connections, which is load-bearing for the claim that end-to-end training discovers useful dynamic patterns.
Authors: We acknowledge that an explicit ablation or diagnostic on score collapse would strengthen the claim that end-to-end training discovers useful dynamic patterns. Although the performance gains relative to fixed-connectivity baselines already suggest non-uniform, task-adaptive connections are learned, we will add an ablation study (including connectivity statistics or visualizations across layers) in the revision to directly address this concern. revision: yes
Circularity Check
No circularity; expressiveness proof and empirical gains are independent of fitted inputs or self-citations.
full rationale
The paper introduces MAVN as a new differentiable architecture for adaptive virtual nodes in MPNNs. Its central theoretical result is an existence claim (parameters exist to realize any fixed node-VN connectivity pattern), which is a standard expressiveness argument rather than a reduction of outputs to inputs by construction. No equations or steps are shown to rename fitted quantities as predictions, smuggle ansatzes via self-citation, or rely on load-bearing self-citations whose content is unverified. Empirical improvements (up to 46.5% on nine datasets) are reported from end-to-end training and benchmarking, not from any self-referential derivation. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- candidate VN pool size
axioms (1)
- domain assumption Dual-perspective scoring functions are differentiable
Reference graph
Works this paper leans on
-
[1]
Uri Alon and Eran Yahav. 2021. On the Bottleneck of Graph Neural Networks and its Practical Implications. InProceedings of the 9th International Conference on Learning Representations
2021
-
[2]
Adrián Arnaiz-Rodríguez, Ahmed Begga, Francisco Escolano, and Nuria M Oliver
-
[3]
InProceedings of the 1st Learning on Graphs Conference
DiffWire: Inductive Graph Rewiring via the Lovász Bound. InProceedings of the 1st Learning on Graphs Conference. 15:1–15:27
-
[4]
Bronstein, and Francesco Di Giovanni
Federico Barbero, Ameya Velingker, Amin Saberi, Michael M. Bronstein, and Francesco Di Giovanni. 2024. Locality-Aware Graph Rewiring in GNNs. In Proceedings of the 12th International Conference on Learning Representations
2024
-
[5]
Kostylev, Mikael Monet, Jorge Pérez, Juan Reutter, and Juan Pablo Silva
Pablo Barceló, Egor V. Kostylev, Mikael Monet, Jorge Pérez, Juan Reutter, and Juan Pablo Silva. 2020. The Logical Expressiveness of Graph Neural Networks. InProceedings of the 8th International Conference on Learning Representations
2020
-
[6]
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. 2013. Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation. arXiv preprint arXiv.1308.3432(2013). doi:10.48550/arXiv.1308.3432
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1308.3432 2013
-
[7]
Mitchell Black, Zhengchao Wan, Amir Nayyeri, and Yusu Wang. 2023. Under- standing Oversquashing in GNNs through the Lens of Effective Resistance. In Proceedings of the 40th International Conference on Machine Learning. 2528–2547
2023
-
[8]
Xavier Bresson and Thomas Laurent. 2017. Residual Gated Graph ConvNets. arXiv preprint arXiv.1711.07553(2017). doi:10.48550/arXiv.1711.07553
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1711.07553 2017
-
[9]
Chen Cai, Truong Son Hy, Rose Yu, and Yusu Wang. 2023. On the Connection Between MPNN and Graph Transformer. InProceedings of the 40th International Conference on Machine Learning. 3408–3430
2023
-
[10]
Rebekka Burkholz Celia Rubio-Madrigal, Adarsh Jamadandi. 2025. GNNs Getting ComFy: Community and Feature Similarity Guided Rewiring. InProceedings of the 13th International Conference on Learning Representations
2025
-
[11]
Chenhui Deng, Zichao Yue, and Zhiru Zhang. 2024. Polynormer: Polynomial- Expressive Graph Transformer in Linear Time. InProceedings of the 12th Interna- tional Conference on Learning Representations
2024
-
[12]
Bronstein
Francesco Di Giovanni, Lorenzo Giusti, Federico Barbero, Giulia Luise, Pietro Lio, and Michael M. Bronstein. 2023. On Over-Squashing in Message Passing Neural Networks: The Impact of Width, Depth, and Topology. InProceedings of the 40th International Conference on Machine Learning. 7865–7885
2023
-
[13]
Maddison, and Lei Han
Honghua Dong, Jiawei Xu, Yu Yang, Rui Zhao, Shiwen Wu, Chun Yuan, Xiu Li, Chris J. Maddison, and Lei Han. 2023. MeGraph: Capturing Long-Range Interactions by Alternating Local and Hierarchical Aggregation on Multi-Scaled Graph Hierarchy. InProceedings of the 37th Conference on Neural Information Processing Systems
2023
-
[14]
Vijay Prakash Dwivedi, Ladislav Rampášek, Michael Galkin, Ali Parviz, Guy Wolf, Anh Tuan Luu, and Dominique Beaini. 2022. Long Range Graph Benchmark. InProceedings of the 36th Conference on Neural Information Processing Systems. 22326–22340
2022
-
[15]
Ellens, F.M
W. Ellens, F.M. Spieksma, P. Van Mieghem, A. Jamakovic, and R.E. Kooij. 2011. Effective graph resistance.Linear Algebra Appl.435, 10 (2011), 2491–2506
2011
-
[16]
Federico Errica, Henrik Christiansen, Viktor Zaverkin, Takashi Maruyama, Math- ias Niepert, and Francesco Alesiani. 2023. Adaptive Message Passing: A General Framework to Mitigate Oversmoothing, Oversquashing, and Underreaching. arXiv preprint arXiv.2312.16560(2023). doi:10.48550/arXiv.2312.16560
-
[17]
Bronstein, and Ismail Ilkan Ceylan
Ben Finkelshtein, Xingyue Huang, Michael M. Bronstein, and Ismail Ilkan Ceylan
-
[18]
InProceedings of the 41st International KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Jaejun Lee and Joyce Jiyoung Whang Conference on Machine Learning
Cooperative Graph Neural Networks. InProceedings of the 41st International KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Jaejun Lee and Joyce Jiyoung Whang Conference on Machine Learning
2026
-
[19]
Dongqi Fu, Zhigang Hua, Yan Xie, Jin Fang, Si Zhang, Kaan Sancak, Hao Wu, Andrey Malevich, Jingrui He, and Bo Long. 2024. VCR-Graphormer: A Mini- batch Graph Transformer via Virtual Connections. InProceedings of the 12th International Conference on Learning Representations
2024
-
[20]
Simon Geisler, Arthur Kosmala, Daniel Herbst, and Stephan Günnemann. 2024. Spatio-Spectral Graph Neural Networks. InProceedings of the 38th Conference on Neural Information Processing Systems
2024
-
[21]
Schoenholz, Patrick F
Justin Gilmer, Samuel S. Schoenholz, Patrick F. Riley, Oriol Vinyals, and George E. Dahl. 2017. Neural Message Passing for Quantum Chemistry. InProceedings of the 34th International Conference on Machine Learning. 1263–1272
2017
-
[22]
M. Gori, G. Monfardini, and F. Scarselli. 2005. A new model for learning in graph domains. InProceedings of the 2005 IEEE International Joint Conference on Neural Networks, Vol. 2. 729–734 vol. 2
2005
-
[23]
Bronstein, and Francesco Di Giovanni
Benjamin Gutteridge, Xiaowen Dong, Michael M. Bronstein, and Francesco Di Giovanni. 2023. DRew: Dynamically Rewired Message Passing with De- lay. InProceedings of the 40th International Conference on Machine Learning. 12252–12267
2023
-
[24]
Hamilton, Rex Ying, and Jure Leskovec
William L. Hamilton, Rex Ying, and Jure Leskovec. 2017. Inductive Representa- tion Learning on Large Graphs. InProceedings of the 31st Conference on Neural Information Processing Systems. 1025–1034
2017
-
[25]
Xiaoxin He, Bryan Hooi, Thomas Laurent, Adam Perold, Yann Lecun, and Xavier Bresson. 2023. A Generalization of ViT/MLP-Mixer to Graphs. InProceedings of the 40th International Conference on Machine Learning. 12724–12745
2023
-
[26]
Kurt Hornik, Maxwell Stinchcombe, and Halbert White. 1989. Multilayer feed- forward networks are universal approximators.Neural Networks2, 5 (1989), 359 – 366
1989
-
[27]
Weihua Hu, Bowen Liu, Joseph Gomes, Marinka Zitnik, Percy Liang, Vijay Pande, and Jure Leskovec. 2020. Strategies for Pre-training Graph Neural Networks. In Proceedings of the 8th International Conference on Learning Representations
2020
-
[28]
Eric Jang, Shixiang Gu, and Ben Poole. 2017. Categorical Reparameterization with Gumbel-Softmax. InProceedings of the 5th International Conference on Learning Representations
2017
-
[29]
Wei Jin, Yao Ma, Xiaorui Liu, Xianfeng Tang, Suhang Wang, and Jiliang Tang. 2020. Graph Structure Learning for Robust Graph Neural Networks. InProceedings of the 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 66–74
2020
-
[30]
Banerjee, and Guido Montufar
Kedar Karhadkar, Pradeep Kr. Banerjee, and Guido Montufar. 2023. FoSR: First- order spectral rewiring for addressing oversquashing in GNNs. InProceedings of the 11th International Conference on Learning Representations
2023
-
[31]
Bobak Kiani, Lukas Fesser, and Melanie Weber. 2024. Unitary Convolutions for Learning on Graphs and Groups. InProceedings of the 38th Conference on Neural Information Processing Systems. 136922–136961
2024
-
[32]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. InProceedings of the 5th International Conference on Learning Representations
2017
-
[33]
Jianqing Liang, Min Chen, and Jiye Liang. 2024. Graph External Attention Enhanced Transformer. InProceedings of the 41st International Conference on Machine Learning
2024
-
[34]
Jonas Linkerhägner, Cheng Shi, and Ivan Dokmanić. 2025. Joint Graph Rewiring and Feature Denoising via Spectral Resonance. InProceedings of the 13th Interna- tional Conference on Learning Representations
2025
-
[35]
Yuankai Luo, Lei Shi, and Xiao-Ming Wu. 2024. Classic GNNs are Strong Baselines: Reassessing GNNs for Node Classification. InProceedings of the 38th Conference on Neural Information Processing Systems. 97650–97669
2024
-
[36]
Jiahong Ma, Mingguo He, and Zhewei Wei. 2024. PolyFormer: Scalable Node- wise Filters via Polynomial Graph Transformer. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2118–2129
2024
-
[37]
Dokania, Mark Coates, Philip Torr, and Ser-Nam Lim
Liheng Ma, Chen Lin, Derek Lim, Adriana Romero-Soriano, Puneet K. Dokania, Mark Coates, Philip Torr, and Ser-Nam Lim. 2023. Graph Inductive Biases in Transformers without Message Passing. InProceedings of the 40th International Conference on Machine Learning. 23321–23337
2023
-
[38]
Khang Nguyen, Nong Minh Hieu, Vinh Duc Nguyen, Nhat Ho, Stanley Osher, and Tan Minh Nguyen. 2023. Revisiting Over-smoothing and Over-squashing Using Ollivier-Ricci Curvature. InProceedings of the 40th International Conference on Machine Learning. 25956–25979
2023
-
[39]
Kenta Oono and Taiji Suzuki. 2020. Graph Neural Networks Exponentially Lose Expressive Power for Node Classification. InProceedings of the 8th International Conference on Learning Representations
2020
-
[40]
Moonjeong Park, Jaeseung Heo, and Dongwoo Kim. 2024. Mitigating Over- smoothing Through Reverse Process of GNNs for Heterophilic Graphs. InPro- ceedings of the 41st International Conference on Machine Learning. 39667–39681
2024
-
[41]
Seonghyun Park, Narae Ryu, Gahee Kim, Dongyeop Woo, Se-Young Yun, and Sungsoo Ahn. 2024. Non-backtracking Graph Neural Networks.Transactions on Machine Learning Research(2024)
2024
-
[42]
Oleg Platonov, Denis Kuznedelev, Michael Diskin, Artem Babenko, and Liudmila Prokhorenkova. 2023. A critical look at the evaluation of GNNs under heterophily: Are we really making progress?. InProceedings of the 11th International Conference on Learning Representations
2023
-
[43]
Chendi Qian, Andrei Manolache, Kareem Ahmed, Zhe Zeng, Guy Van den Broeck, Mathias Niepert, and Christopher Morris. 2024. Probabilistically Rewired Message-Passing Neural Networks. InProceedings of the 12th International Con- ference on Learning Representations
2024
-
[44]
Chendi Qian, Andrei Manolache, Christopher Morris, and Mathias Niepert. 2024. Probabilistic Graph Rewiring via Virtual Nodes. InProceedings of the 38th Con- ference on Neural Information Processing Systems
2024
-
[45]
Ladislav Rampášek, Michael Galkin, Vijay Prakash Dwivedi, Anh Tuan Luu, Guy Wolf, and Dominique Beaini. 2022. Recipe for a General, Powerful, Scalable Graph Transformer. InProceedings of the 36th Conference on Neural Information Processing Systems. 14501–14515
2022
-
[46]
Eran Rosenbluth, Jan Tönshoff, Martin Ritzert, Berke Kisin, and Martin Grohe
-
[47]
Virtual Nodes
Distinguished In Uniform: Self-Attention Vs. Virtual Nodes. InProceedings of the 12th International Conference on Learning Representations
-
[48]
T. Konstantin Rusch, Michael M. Bronstein, and Siddhartha Mishra. 2023. A Sur- vey on Oversmoothing in Graph Neural Networks.arXiv preprint arXiv.2303.10993 (2023). doi:10.48550/arXiv.2303.10993
-
[49]
Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. 2009. The Graph Neural Network Model.IEEE Transactions on Neural Networks and Learning Systems20, 1 (2009), 61–80
2009
-
[50]
Sutherland, and Ali Kemal Sinop
Hamed Shirzad, Ameya Velingker, Balaji Venkatachalam, Danica J. Sutherland, and Ali Kemal Sinop. 2023. Exphormer: Sparse Transformers for Graphs. In Proceedings of the 40th International Conference on Machine Learning. 31613– 31632
2023
-
[51]
Zixing Song, Yifei Zhang, and Irwin King. 2022. Towards an Optimal Asymmetric Graph Structure for Robust Semi-supervised Node Classification. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1656–1665
2022
-
[52]
Bronstein, and Johannes F
Joshua Southern, Francesco Di Giovanni, Michael M. Bronstein, and Johannes F. Lutzeyer. 2025. Understanding Virtual Nodes: Oversquashing and Node Hetero- geneity. InProceedings of the 13th International Conference on Learning Represen- tations
2025
-
[53]
Junshu Sun, Chenxue Yang, Xiangyang Ji, Qingming Huang, and Shuhui Wang
-
[54]
InProceedings of the 38th Conference on Neural Information Processing Systems
Towards Dynamic Message Passing on Graphs. InProceedings of the 38th Conference on Neural Information Processing Systems
-
[55]
Jan Tönshoff, Martin Ritzert, Eran Rosenbluth, and Martin Grohe. 2024. Where Did the Gap Go? Reassessing the Long-Range Graph Benchmark.Transactions on Machine Learning Research(2024)
2024
-
[56]
Bronstein
Jake Topping, Francesco Di Giovanni, Benjamin Paul Chamberlain, Xiaowen Dong, and Michael M. Bronstein. 2022. Understanding over-squashing and bottlenecks on graphs via curvature. InProceedings of the 10th International Conference on Learning Representations
2022
-
[57]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is All You Need. InProceedings of the 31st Conference on Neural Information Processing Systems. 5998–6008
2017
-
[58]
Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. 2018. Graph Attention Networks. InProceedings of the 6th International Conference on Learning Representations
2018
-
[59]
Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and Philip S. Yu. 2021. A Comprehensive Survey on Graph Neural Networks.IEEE Transactions on Neural Networks and Learning Systems32, 1 (2021), 4–24
2021
-
[60]
Zhiyao Zhou, Sheng Zhou, Bochao Mao, Xuanyi Zhou, Jiawei Chen, Qiaoyu Tan, Daochen Zha, Yan Feng, Chun Chen, and Can Wang. 2023. OpenGSL: A Comprehensive Benchmark for Graph Structure Learning. InProceedings of the 37th Conference on Neural Information Processing Systems. 17904–17928
2023
-
[61]
Yanqiao Zhu, Weizhi Xu, Jinghao Zhang, Yuanqi Du, Jieyu Zhang, Qiang Liu, Carl Yang, and Shu Wu. 2021. A Survey on Graph Structure Learning: Progress and Opportunities.arXiv preprint arXiv.2103.03036(2021). doi:10.48550/arXiv.2 103.03036 A Proof of Theorem 1 In Section 5, we present Theorem 1 to demonstrate that, for any set of additional message passing ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.