Cost-Aware Optimization for Agentic Query Execution
Pith reviewed 2026-06-28 08:20 UTC · model grok-4.3
The pith
EnumGRPO optimizes agentic queries with LLM operators by enumerating plans over placement and granularity then distilling runtime quality-cost feedback into reusable heuristics via in-context reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
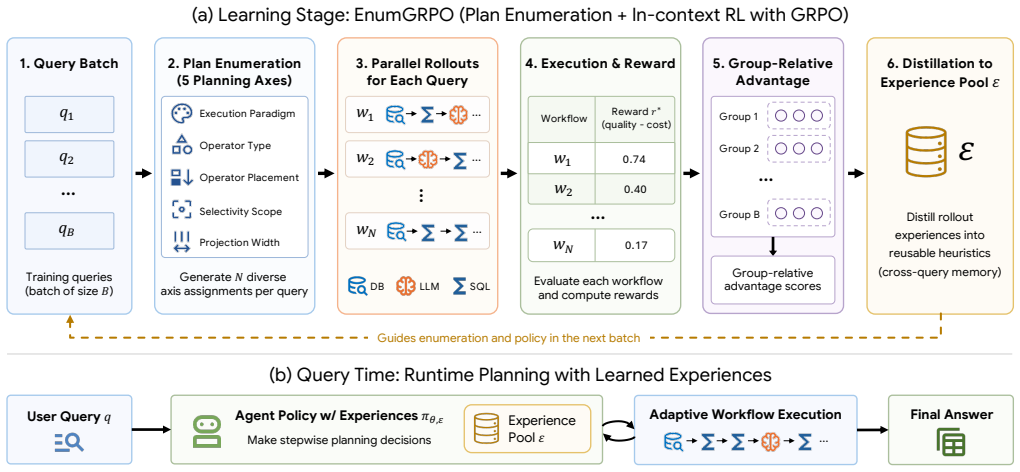
Agentic query execution requires joint optimization of cost and quality because LLM operators expose trade-offs only at runtime; EnumGRPO meets this requirement by enumerating candidate plans over multiple decision dimensions and converting the collected quality-cost pairs into reusable planning heuristics through in-context reinforcement learning, thereby eliminating the need for repeated per-query enumeration while producing concrete gains in both accuracy and cost on the SWAN benchmark.
What carries the argument
EnumGRPO, a self-improving optimizer that enumerates plans across execution paradigm, operator type, placement, selectivity, and projection decisions, then distills quality-cost feedback into planning heuristics via in-context reinforcement learning.
If this is right
- Query planners must jointly consider dollar cost and answer quality rather than cost alone when LLM operators are present.
- In-context reinforcement learning can convert runtime feedback into reusable heuristics that avoid repeated enumeration for each new query.
- The enumerated decisions on paradigm, operator type, placement, selectivity, and projection width suffice to produce large cost reductions while preserving or improving accuracy.
- The same learning procedure yields consistent gains across multiple independent databases without database-specific retraining.
Where Pith is reading between the lines
- The same enumeration-plus-distillation loop could be applied to other agentic pipelines whose operators carry both monetary cost and output quality, such as scientific workflow orchestration.
- If the heuristics prove sensitive to the diversity of training queries, future work could test whether deliberately broadening the enumeration set improves cross-domain transfer.
- Integration into existing database systems would allow users to trade a modest upfront learning cost for dramatically lower ongoing LLM expenses on repeated analytical workloads.
Load-bearing premise
Quality-cost feedback collected during enumeration can be turned into planning heuristics that generalize to new queries and databases without per-query re-enumeration or overfitting to the training set.
What would settle it
Run EnumGRPO on a fifth database and query distribution never seen during enumeration; if the learned heuristics fail to match the reported accuracy and cost levels without additional enumeration, the generalization claim does not hold.
Figures
read the original abstract
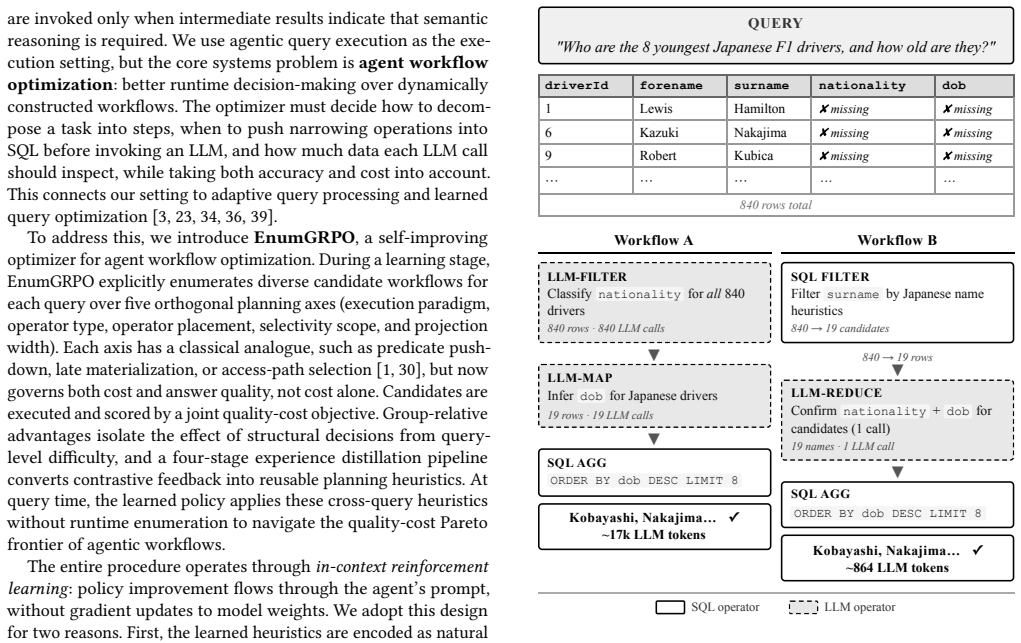
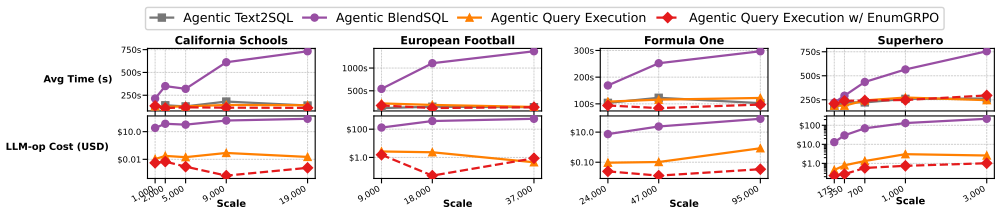
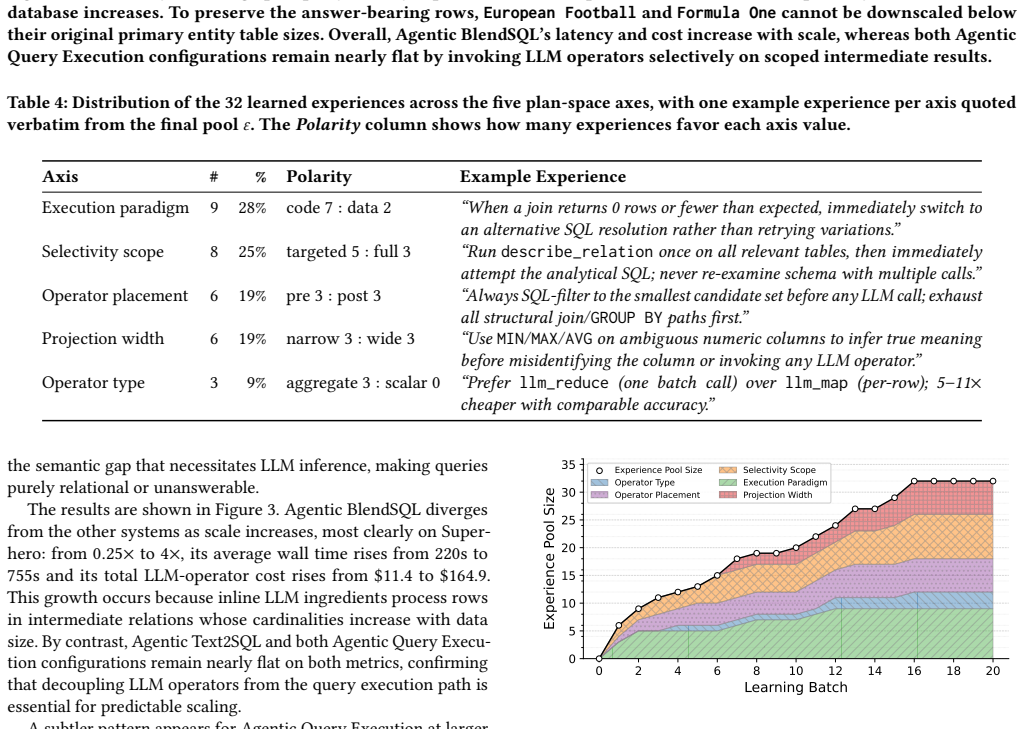
Classical query optimization searches over algebraically equivalent plans that differ only in cost. This assumption breaks once LLM-backed operators enter the picture: their placement, ordering, and granularity jointly determine both dollar cost and answer quality, and the right choice among the alternatives is often revealed only at runtime. We formalize this setting as agentic query execution, a query execution paradigm in which agent-based planning is interleaved with execution, and agent workflow optimization becomes the analogue of classical query optimization. We then present EnumGRPO, a self-improving optimizer for this setting. During a learning stage, EnumGRPO enumerates query plans over decisions such as execution paradigm, operator type, operator placement, selectivity scope, and projection width, then distills quality-cost feedback into reusable planning heuristics via in-context reinforcement learning. Across four databases in SWAN, EnumGRPO achieves 35.4% execution accuracy at $0.011 per query in LLM-operator cost, a ~317x cost reduction over the hybrid query baseline with an 18% relative improvement in answer accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces agentic query execution as a paradigm where LLM-backed operators require joint optimization of dollar cost and answer quality through interleaved agent-based planning and execution. It presents EnumGRPO, which enumerates plans over decisions including execution paradigm, operator type/placement, selectivity, and projection width during a learning stage, then distills quality-cost feedback into reusable planning heuristics via in-context reinforcement learning. The central empirical claim is that EnumGRPO achieves 35.4% execution accuracy at $0.011 per query in LLM-operator cost across four SWAN databases, yielding a ~317x cost reduction and 18% relative accuracy improvement over the hybrid query baseline.
Significance. If the reported cost and accuracy figures are reproducible and the distilled heuristics generalize beyond the enumerated training distribution, the work would represent a meaningful contribution to cost-aware optimization for LLM-augmented database systems, potentially enabling practical deployment of agentic workflows at scale.
major comments (2)
- [Abstract] Abstract: the headline performance numbers (35.4% accuracy at $0.011/query, ~317x cost reduction, 18% accuracy lift) are stated without any description of experimental design, statistical significance testing, exact baseline definitions, number of runs, or measurement protocols for accuracy and cost, rendering the central empirical claim unverifiable from the manuscript text.
- [Abstract] Abstract: no information is supplied on train/test splits, cross-database transfer testing across the four SWAN databases, or ablations that isolate the contribution of the in-context RL-distilled heuristics versus per-query re-enumeration; this directly bears on whether the reported cost/accuracy figures can be attributed to reusable planning heuristics rather than overfitting or query-specific enumeration.
minor comments (1)
- [Abstract] The abstract introduces several new terms (agentic query execution, EnumGRPO) without a brief forward reference to where formal definitions or pseudocode appear in the body.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the focus on verifiability of the central claims. We address each comment below and will revise the abstract to incorporate the requested context while preserving its length constraints.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline performance numbers (35.4% accuracy at $0.011/query, ~317x cost reduction, 18% accuracy lift) are stated without any description of experimental design, statistical significance testing, exact baseline definitions, number of runs, or measurement protocols for accuracy and cost, rendering the central empirical claim unverifiable from the manuscript text.
Authors: We agree the abstract should supply minimal experimental context. In revision we will append a single sentence stating that results are averages across four SWAN databases on a held-out query set, that the hybrid baseline combines rule-based and unoptimized LLM operators, that accuracy is exact-result match, and that costs are measured via LLM API pricing; full protocols, run counts, and significance tests remain in Section 5. revision: yes
-
Referee: [Abstract] Abstract: no information is supplied on train/test splits, cross-database transfer testing across the four SWAN databases, or ablations that isolate the contribution of the in-context RL-distilled heuristics versus per-query re-enumeration; this directly bears on whether the reported cost/accuracy figures can be attributed to reusable planning heuristics rather than overfitting or query-specific enumeration.
Authors: We agree the abstract omits these details. The manuscript already contains the requested information (70/30 per-database splits, explicit cross-database transfer results, and an ablation isolating the distilled-heuristic component from per-query re-enumeration). We will add one concise clause to the abstract noting that the reported gains are obtained under cross-database evaluation and that ablations attribute the cost reduction to the reusable heuristics rather than query-specific enumeration. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical procedure in which EnumGRPO enumerates candidate plans, collects runtime quality-cost feedback, and distills it into heuristics via in-context reinforcement learning; the headline metrics (35.4% accuracy, $0.011/query cost, 317x reduction) are presented as direct experimental measurements on four SWAN databases rather than quantities obtained by algebraic rearrangement or parameter fitting inside the paper's own equations. No self-definitional loops, fitted-input-as-prediction reductions, or load-bearing self-citations appear in the abstract or described method. The derivation chain therefore consists of an experimental pipeline whose outputs are independent of the inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abadi, Samuel Madden, and Nabil Hachem
Daniel J. Abadi, Samuel Madden, and Nabil Hachem. 2008. Column-stores vs. row-stores: how different are they really?. InProceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2008, Vancouver, BC, Canada, June 10-12, 2008, Jason Tsong-Li Wang (Ed.). ACM, 967–980. https: //doi.org/10.1145/1376616.1376712
-
[2]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A. Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J. Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Daniel Klein, Matei Zaharia, and Omar Khattab. 2025. GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning.CoRRabs/250...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.19457 2025
-
[3]
Ron Avnur and Joseph M. Hellerstein. 2000. Eddies: Continuously Adaptive Query Processing. InProceedings of the 2000 ACM SIGMOD International Conference on Management of Data, May 16-18, 2000, Dallas, Texas, USA, Weidong Chen, Jeffrey F. Naughton, and Philip A. Bernstein (Eds.). ACM, 261–272. https: //doi.org/10.1145/342009.335420
-
[4]
Yuzheng Cai, Siqi Cai, Yuchen Shi, Zihan Xu, Lichao Chen, Yulei Qin, Xiaoyu Tan, Gang Li, Zongyi Li, Haojia Lin, Yong Mao, Ke Li, and Xing Sun. 2025. Training-Free Group Relative Policy Optimization.CoRRabs/2510.08191 (2025). https://doi.org/10.48550/ARXIV.2510.08191 arXiv:2510.08191
-
[5]
Surajit Chaudhuri. 1998. An Overview of Query Optimization in Relational Systems. InProceedings of the Seventeenth ACM SIGACT-SIGMOD-SIGART Sym- posium on Principles of Database Systems, June 1-3, 1998, Seattle, Washing- ton, USA, Alberto O. Mendelzon and Jan Paredaens (Eds.). ACM Press, 34–43. https://doi.org/10.1145/275487.275492
-
[6]
Benoit Dherin, Michael Munn, Hanna Mazzawi, Michael Wunder, and Javier Gonzalvo. 2025. Learning without training: The implicit dynamics of in-context learning.CoRRabs/2507.16003 (2025). https://doi.org/10.48550/ARXIV.2507. 16003 arXiv:2507.16003
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507 2025
-
[7]
Eltabakh, Zan Ahmad Naeem, Mohammad Shahmeer Ahmad, Mourad Ouzzani, and Nan Tang
Mohamed Y. Eltabakh, Zan Ahmad Naeem, Mohammad Shahmeer Ahmad, Mourad Ouzzani, and Nan Tang. 2024. RetClean: Retrieval-Based Tabular Data Cleaning Using LLMs and Data Lakes.Proc. VLDB Endow.17, 12 (2024), 4421–4424. https://doi.org/10.14778/3685800.3685890
-
[8]
Yannis Foufoulas and Alkis Simitsis. 2023. Efficient Execution of User-Defined Functions in SQL Queries.Proc. VLDB Endow.16, 12 (2023), 3874–3877. https: //doi.org/10.14778/3611540.3611574
-
[9]
Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. 2024. Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation.Proc. VLDB Endow.17, 5 (2024), 1132–1145. https: //doi.org/10.14778/3641204.3641221
-
[10]
Parker Glenn, Parag Dakle, Liang Wang, and Preethi Raghavan. 2024. BlendSQL: A Scalable Dialect for Unifying Hybrid Question Answering in Relational Algebra. InFindings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024 (Findings of ACL), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds....
-
[11]
Goetz Graefe. 1995. The Cascades Framework for Query Optimization.IEEE Data Eng. Bull.18, 3 (1995), 19–29. http://sites.computer.org/debull/95SEP-CD.pdf
1995
-
[12]
Rohit Khoja, Devanshu Gupta, Yanjie Fu, Dan Roth, and Vivek Gupta. 2025. Weaver: Interweaving SQL and LLM for Table Reasoning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, Suzhou, China, November 4-9, 2025, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Associ...
-
[13]
Hyeonji Kim, Byeong-Hoon So, Wook-Shin Han, and Hongrae Lee. 2020. Natural language to SQL: Where are we today?Proc. VLDB Endow.13, 10 (2020), 1737–
2020
-
[14]
https://doi.org/10.14778/3401960.3401970
-
[15]
Hanna Köpcke, Andreas Thor, and Erhard Rahm. 2010. Evaluation of entity resolution approaches on real-world match problems.Proc. VLDB Endow.3, 1 (2010), 484–493. https://doi.org/10.14778/1920841.1920904
-
[16]
Udesh Kumarasinghe, Tyler Liu, Chunwei Liu, and Walid G. Aref. 2026. iPDB – Optimizing SQL Queries with ML and LLM Predicates.CoRRabs/2601.16432 (2026). https://doi.org/10.48550/ARXIV.2601.16432 arXiv:2601.16432
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.16432 2026
-
[17]
Jiale Lao, Andreas Zimmerer, Olga Ovcharenko, Tianji Cong, Matthew Russo, Gerardo Vitagliano, Michael Cochez, Fatma Özcan, Gautam Gupta, Thibaud Hot- telier, H. V. Jagadish, Kris Kissel, Sebastian Schelter, Andreas Kipf, and Immanuel Trummer. 2025. SemBench: A Benchmark for Semantic Query Processing En- gines.CoRRabs/2511.01716 (2025). https://doi.org/10....
-
[18]
Boyan Li, Yuyu Luo, Chengliang Chai, Guoliang Li, and Nan Tang. 2024. The Dawn of Natural Language to SQL: Are We Fully Ready? [Experiment, Analysis & Benchmark ].Proc. VLDB Endow.17, 11 (2024), 3318–3331. https://doi.org/10. 14778/3681954.3682003
arXiv 2024
-
[19]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al. 2024. Can LLM Already Serve as a Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to- SQLs.Advances in Neural Information Processing Systems36 (2024)
2024
-
[20]
Yuliang Li, Jinfeng Li, Yoshihiko Suhara, AnHai Doan, and Wang-Chiew Tan
-
[21]
VLDB Endow.14, 1 (2020), 50–60
Deep Entity Matching with Pre-Trained Language Models.Proc. VLDB Endow.14, 1 (2020), 50–60. https://doi.org/10.14778/3421424.3421431
-
[22]
Yan Li, Liwei Wang, Sheng Wang, Yuan Sun, Bolong Zheng, and Zhiyong Peng
-
[23]
A learned cost model for big data query processing.Inf. Sci.670 (2024), 120650. https://doi.org/10.1016/J.INS.2024.120650
-
[24]
Cafarella, Lei Cao, Peter Baile Chen, Zui Chen, Michael J
Chunwei Liu, Matthew Russo, Michael J. Cafarella, Lei Cao, Peter Baile Chen, Zui Chen, Michael J. Franklin, Tim Kraska, Samuel Madden, Rana Shahout, and Gerardo Vitagliano. 2025. Palimpzest: Optimizing AI-Powered Analyt- ics with Declarative Query Processing. In15th Conference on Innovative Data Systems Research, CIDR 2025, Amsterdam, The Netherlands, Jan...
2025
-
[25]
https://vldb.org/cidrdb/2025/palimpzest-optimizing-ai- powered-analytics-with-declarative-query-processing.html
www.cidrdb.org. https://vldb.org/cidrdb/2025/palimpzest-optimizing-ai- powered-analytics-with-declarative-query-processing.html
2025
-
[26]
Gonzalez, Ion Stoica, and Matei Zaharia
Shu Liu, Asim Biswal, Audrey Cheng, Xiangxi Mo, Shiyi Cao, Joseph E. Gonzalez, Ion Stoica, and Matei Zaharia. 2024. Optimizing LLM Queries in Relational Workloads.CoRRabs/2403.05821 (2024). https://doi.org/10.48550/ARXIV.2403. 05821 arXiv:2403.05821
-
[27]
Ryan Marcus, Parimarjan Negi, Hongzi Mao, Nesime Tatbul, Mohammad Al- izadeh, and Tim Kraska. 2021. Bao: Making Learned Query Optimization Practical. InProceedings of the 2021 International Conference on Management of Data, SIGMOD 2021, Virtual Event, China, June 20-25, 2021. ACM, 1275–1288. https://doi.org/10.1145/3448016.3452838
-
[28]
David Menestrina, Steven Whang, and Hector Garcia-Molina. 2010. Evaluating Entity Resolution Results.Proc. VLDB Endow.3, 1 (2010), 208–219. https: //doi.org/10.14778/1920841.1920871
-
[29]
Prashanth Menon, Andrew Pavlo, and Todd C. Mowry. 2017. Relaxed Opera- tor Fusion for In-Memory Databases: Making Compilation, Vectorization, and Prefetching Work Together At Last.Proc. VLDB Endow.11, 1 (2017), 1–13. https://doi.org/10.14778/3151113.3151114
-
[30]
Guido Moerkotte and Thomas Neumann. 2006. Analysis of Two Existing and One New Dynamic Programming Algorithm for the Generation of Optimal Bushy Join Trees without Cross Products. InProceedings of the 32nd International Conference on Very Large Data Bases, Seoul, Korea, September 12-15, 2006, Umeshwar Dayal, Kyu-Young Whang, David B. Lomet, Gustavo Alonso...
2006
-
[31]
Thomas Neumann. 2011. Efficiently Compiling Efficient Query Plans for Modern Hardware.Proc. VLDB Endow.4, 9 (2011), 539–550. https://doi.org/10.14778/ 2002938.2002940
arXiv 2011
-
[32]
Liana Patel, Siddharth Jha, Carlos Guestrin, and Matei Zaharia. 2024. LOTUS: En- abling Semantic Queries with LLMs Over Tables of Unstructured and Structured Data.CoRRabs/2407.11418 (2024). https://doi.org/10.48550/ARXIV.2407.11418 arXiv:2407.11418
-
[33]
Liana Patel, Siddharth Jha, Melissa Pan, Harshit Gupta, Parth Asawa, Carlos Guestrin, and Matei Zaharia. 2025. Semantic Operators and Their Optimization: Enabling LLM-Based Data Processing with Accuracy Guarantees in LOTUS.Proc. VLDB Endow.18, 11 (2025), 4171–4184. https://doi.org/10.14778/3749646.3749685
-
[34]
Patricia G. Selinger, Morton M. Astrahan, Donald D. Chamberlin, Raymond A. Lorie, and Thomas G. Price. 1979. Access Path Selection in a Relational Database Management System. InProceedings of the 1979 ACM SIGMOD International Conference on Management of Data, Boston, Massachusetts, USA, May 30 - June 1, Philip A. Bernstein (Ed.). ACM, 23–34. https://doi.o...
-
[35]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.CoRRabs/2402.03300 (2024). https://doi.org/10.48550/ARXIV.2402.03300 arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[36]
Kefan Song, Amir Moeini, Peng Wang, Lei Gong, Rohan Chandra, Yanjun Qi, and Shangtong Zhang. 2026. Reward Is Enough: LLMs Are In-Context Reinforcement Learners. InProceedings of the Fourteenth International Conference on Learning Representations, ICLR 2026. arXiv:2506.06303
Pith/arXiv arXiv 2026
-
[37]
Wendt, Lauro Beltrão Costa, Marc Najork, and Beliz Gunel
Sandeep Tata, Navneet Potti, James B. Wendt, Lauro Beltrão Costa, Marc Najork, and Beliz Gunel. 2021. Glean: Structured Extractions from Templatic Documents. Proc. VLDB Endow.14, 6 (2021), 997–1005. https://doi.org/10.14778/3447689. 3447703
-
[38]
Immanuel Trummer, Junxiong Wang, Ziyun Wei, Deepak Maram, Samuel Mose- ley, Saehan Jo, Joseph Antonakakis, and Ankush Rayabhari. 2021. SkinnerDB: Regret-bounded Query Evaluation via Reinforcement Learning.ACM Trans. Database Syst.46, 3 (2021), 1–45. https://doi.org/10.1145/3464389
-
[39]
Matthias Urban and Carsten Binnig. 2024. CAESURA: Language Models as Multi-Modal Query Planners. In14th Conference on Innovative Data Systems Research, CIDR 2024, Chaminade, CA, USA, January 14-17, 2024. www.cidrdb.org. https://www.cidrdb.org/cidr2024/papers/p14-urban.pdf
2024
-
[40]
Zongheng Yang, Wei-Lin Chiang, Sifei Luan, Gautam Mittal, Michael Luo, and Ion Stoica. 2022. Balsa: Learning a Query Optimizer Without Expert Demon- strations. InProceedings of the 2022 International Conference on Management of Data, SIGMOD 2022, Philadelphia, PA, USA, June 12-17, 2022. ACM, 931–944. 13 https://doi.org/10.1145/3514221.3517885
-
[41]
Ye Yuan, Bo Tang, Tianfei Zhou, Zhiwei Zhang, and Jianbin Qin. 2024. nsDB: Architecting the Next Generation Database by Integrating Neural and Symbolic Systems (Vision).Proc. VLDB Endow.17, 11 (2024), 3283–3289. https://doi.org/ 10.14778/3681954.3682000
-
[42]
Fuheng Zhao, Divyakant Agrawal, and Amr El Abbadi. 2024. Hybrid Querying Over Relational Databases and Large Language Models.CoRRabs/2408.00884 (2024). https://doi.org/10.48550/ARXIV.2408.00884 arXiv:2408.00884
-
[43]
Rong Zhu, Wei Chen, Bolin Ding, Xingguang Chen, Andreas Pfadler, Ziniu Wu, and Jingren Zhou. 2023. Lero: A Learning-to-Rank Query Optimizer.Proc. VLDB Endow.16, 6 (2023), 1466–1479. https://doi.org/10.14778/3583140.3583160 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.