HRNN: A Hybrid Graph Index for Approximate Reverse k-Nearest Neighbor Search on High-Dimensional Vectors
Pith reviewed 2026-06-28 08:16 UTC · model grok-4.3
The pith
HRNN uses proxy points from nearby vectors and precomputed kNN radii to perform approximate reverse nearest neighbor search up to ten times faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HRNN builds a hybrid index from a navigation graph, a ranked KNN graph, and reverse-neighbor lists. It retrieves nearby vectors as proxy points to generate candidates indirectly and accesses pre-materialized high-fidelity kNN-radii for verification. This replaces direct candidate expansion and online radius reconstruction, producing up to an order of magnitude higher throughput while scaling to ten million vectors and supporting append-only maintenance.
What carries the argument
The hybrid graph index that combines a navigation graph, ranked KNN graph, and reverse-neighbor lists to support proxy retrieval for candidate generation and direct lookup of stored kNN radii.
If this is right
- Query throughput reaches up to one order of magnitude higher than existing RkNN methods.
- The index handles collections containing up to ten million high-dimensional vectors.
- Append-only construction and maintenance algorithms keep the index current under insertions without full rebuilds.
Where Pith is reading between the lines
- The proxy technique could reduce verification work in other high-dimensional neighbor searches where direct candidates are costly to check.
- Storing radii ahead of time trades extra index space for lower query latency, which could be measured at different accuracy levels.
- Append-only updates suggest the design could support workloads that require frequent changes without downtime.
Load-bearing premise
A query's reverse nearest neighbors can often be recovered by examining the reverse nearest neighbors of vectors near the query.
What would settle it
A dataset in which the reverse-neighbor sets of nearby vectors share almost no overlap with the query's true reverse neighbors would show whether the proxy approach misses most correct answers.
Figures







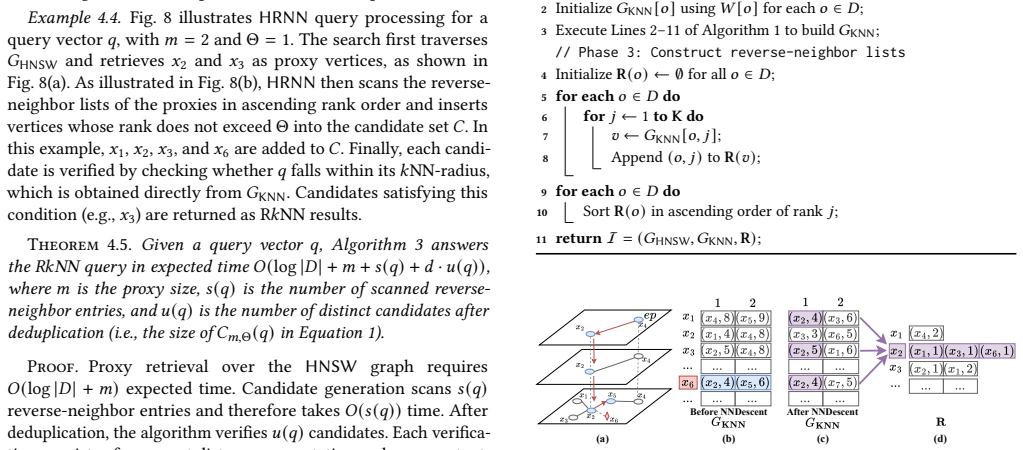
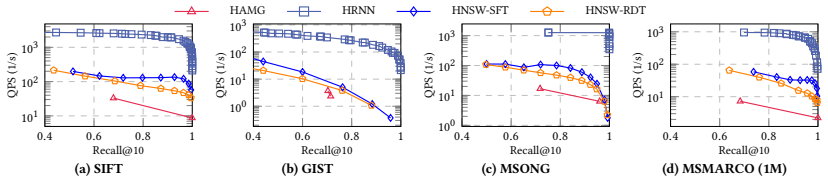

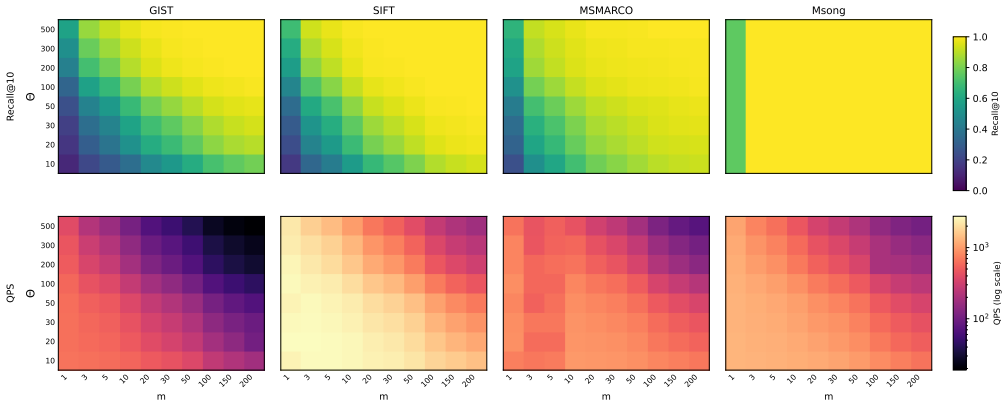



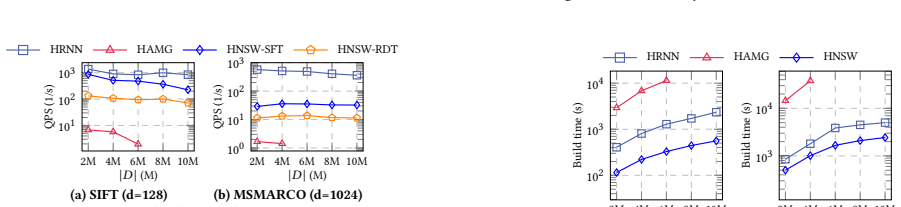
read the original abstract
Reverse k-nearest neighbor (RkNN) search returns all data points that regard a query vector as one of their k-nearest neighbors (kNNs). Existing RkNN methods typically follow a filter-and-verification framework: vectors near the query vector are first collected as candidates and then verified against their kNN-radius (i.e., the distance to their k-th nearest neighbor). However, existing methods face two key limitations in high-dimensional spaces. First, nearby vectors often do not belong to the query's true RkNN set, resulting in excessive candidate expansion overhead. Second, existing methods compute kNN-radius online during verification, incurring substantial query-processing cost. To address these limitations, we propose HRNN, a hybrid graph index for approximate RkNN search. (1) Rather than directly treating nearby vectors as RkNN candidates, HRNN uses them as proxy points based on the assumption that a query's RkNN results can often be discovered through the RkNN results of its nearby vectors. (2) To reduce verification cost, HRNN materializes high-fidelity kNN-radius offline, eliminating expensive online reconstruction while preserving accuracy. HRNN combines a navigation graph, a ranked KNN graph, and reverse-neighbor lists into a hybrid index that supports efficient proxy retrieval, candidate generation, and kNN-radius access. We also develop efficient index construction and append-only maintenance algorithms. Extensive experiments show that HRNN consistently outperforms existing methods, achieving up to one order of magnitude higher throughput. Moreover, HRNN scales to datasets containing up to 10 million high-dimensional vectors while supporting efficient dynamic index maintenance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HRNN, a hybrid graph index for approximate reverse k-nearest neighbor (RkNN) search on high-dimensional vectors. It replaces direct candidate expansion in the filter-and-verification framework with proxy retrieval: nearby vectors are fetched and their precomputed reverse-neighbor lists supply RkNN candidates for the query. It also materializes high-fidelity kNN-radii offline to avoid online reconstruction. The index integrates a navigation graph, a ranked KNN graph, and reverse-neighbor lists, and includes algorithms for construction and append-only maintenance. Experiments are reported to show up to an order of magnitude higher throughput than existing methods together with scalability to 10 million vectors.
Significance. If the proxy assumption is shown to hold with acceptable recall and the throughput gains are reproducible under standard high-dimensional controls, the hybrid index could provide a practical improvement for RkNN workloads in vector databases. The combination of proxy-based candidate generation with offline radius materialization and the append-only maintenance routine are concrete engineering contributions that address two stated limitations of prior filter-and-verification approaches.
major comments (2)
- [Abstract] Abstract: the central efficiency claim rests on the unvalidated proxy assumption that 'a query's RkNN results can often be discovered through the RkNN results of its nearby vectors'. No analytic bound on set overlap, no high-dimensional overlap-probability analysis, and no counter-example evaluation are supplied, leaving open the risk that the curse of dimensionality forces either unacceptable recall loss or expansion that erases the claimed throughput advantage.
- [Abstract] Abstract: the abstract asserts experimental superiority ('up to one order of magnitude higher throughput') yet supplies no information on the datasets, vector dimensionality, baselines, accuracy metrics (recall/precision), or experimental controls, preventing any assessment of whether the reported numbers support the central performance claim.
minor comments (1)
- The abstract could include a one-sentence statement of the vector dimensions and dataset sizes used in the largest-scale experiments to contextualize the 10-million-vector scalability claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. Both points can be addressed by targeted revisions that add context and empirical references without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central efficiency claim rests on the unvalidated proxy assumption that 'a query's RkNN results can often be discovered through the RkNN results of its nearby vectors'. No analytic bound on set overlap, no high-dimensional overlap-probability analysis, and no counter-example evaluation are supplied, leaving open the risk that the curse of dimensionality forces either unacceptable recall loss or expansion that erases the claimed throughput advantage.
Authors: We acknowledge the absence of an analytic bound, which is difficult to derive under the curse of dimensionality. The full manuscript provides extensive empirical validation across multiple high-dimensional datasets (up to 10M vectors) demonstrating that the proxy assumption yields recall above 0.9 while delivering the reported throughput gains; no counter-examples were observed in our test regimes. We will revise the abstract to note this empirical support and direct readers to the experimental section for overlap and recall analysis. revision: yes
-
Referee: [Abstract] Abstract: the abstract asserts experimental superiority ('up to one order of magnitude higher throughput') yet supplies no information on the datasets, vector dimensionality, baselines, accuracy metrics (recall/precision), or experimental controls, preventing any assessment of whether the reported numbers support the central performance claim.
Authors: We agree the abstract should supply more context. The revised abstract will briefly state the dataset scales (up to 10 million vectors), high dimensionality, comparison against existing filter-and-verification baselines, and the metrics of recall and throughput under standard controls. revision: yes
Circularity Check
No circularity; empirical index design with explicit assumption
full rationale
The paper presents a heuristic graph index (HRNN) whose core design rests on an explicitly stated assumption about proxy points for RkNN retrieval. No equations, derivations, parameter fittings, or self-citation chains are described that reduce any claimed result to its own inputs by construction. Performance claims are framed as experimental outcomes on concrete datasets rather than analytic predictions. This matches the default case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption a query's RkNN results can often be discovered through the RkNN results of its nearby vectors
invented entities (1)
-
HRNN hybrid graph index
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Elke Achtert, Christian Böhm, Peer Kröger, Peter Kunath, Alexey Pryakhin, and Matthias Renz. 2006. Efficient reverse k-nearest neighbor search in ar- bitrary metric spaces. InProceedings of the 2006 ACM SIGMOD International Conference on Management of Data(Chicago, IL, USA)(SIGMOD ’06). As- sociation for Computing Machinery, New York, NY, USA, 515–526. ht...
-
[2]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi
-
[3]
InThe Twelfth International Conference on Learning Representations
Self-RAG: Learning to Retrieve, Generate, and Critique through Self- Reflection. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=hSyW5go0v8
-
[4]
Ilias Azizi, Karima Echihabi, and Themis Palpanas. 2023. Elpis: Graph-based similarity search for scalable data science.Proceedings of the VLDB Endowment 16, 6 (2023), 1548–1559
2023
-
[5]
Gautam Bhattacharya, Koushik Ghosh, and Ananda S. Chowdhury. 2015. Outlier detection using neighborhood rank difference.Pattern Recogn. Lett.60, C (Aug. 2015), 24–31. https://doi.org/10.1016/j.patrec.2015.04.004
-
[6]
Avory Bryant and Krzysztof Cios. 2018. RNN-DBSCAN: A Density-Based Clus- tering Algorithm Using Reverse Nearest Neighbor Density Estimates.IEEE Transactions on Knowledge and Data Engineering30, 6 (2018), 1109–1121. https: //doi.org/10.1109/TKDE.2017.2787640
-
[7]
Houle, Peer Kröger, Michael Nett, Erich Schubert, and Arthur Zimek
Guillaume Casanova, Elias Englmeier, Michael E. Houle, Peer Kröger, Michael Nett, Erich Schubert, and Arthur Zimek. 2017. Dimensional testing for reverse k-nearest neighbor search.Proc. VLDB Endow.10, 7 (March 2017), 769–780. https://doi.org/10.14778/3067421.3067426
-
[8]
Muhammad Aamir Cheema, Xuemin Lin, Wenjie Zhang, and Ying Zhang. 2011. Influence zone: Efficiently processing reverse k nearest neighbors queries. In Proceedings of the 2011 IEEE 27th International Conference on Data Engineering (ICDE ’11). IEEE Computer Society, USA, 577–588. https://doi.org/10.1109/ICDE. 2011.5767904
-
[9]
Meng Chen, Kai Zhang, Zhenying He, Yinan Jing, and X. Sean Wang. 2024. RoarGraph: A Projected Bipartite Graph for Efficient Cross-Modal Approximate Nearest Neighbor Search.Proc. VLDB Endow.17, 11 (July 2024), 2735–2749. https://doi.org/10.14778/3681954.3681959
-
[10]
Patrick Chen, Wei-Cheng Chang, Jyun-Yu Jiang, Hsiang-Fu Yu, Inderjit Dhillon, and Cho-Jui Hsieh. 2023. FINGER: Fast Inference for Graph-based Approximate Nearest Neighbor Search. InProceedings of the ACM Web Conference 2023(Austin, TX, USA)(WWW ’23). Association for Computing Machinery, New York, NY, USA, 3225–3235. https://doi.org/10.1145/3543507.3583318
-
[11]
Qi-Zhu Dai, Zhong-Yang Xiong, Jiang Xie, Xiao-Xia Wang, Yu-Fang Zhang, and Jia-Xing Shang. 2019. A novel clustering algorithm based on the natural reverse nearest neighbor structure.Inf. Syst.84, C (Sept. 2019), 1–16. https: //doi.org/10.1016/j.is.2019.04.001
-
[12]
Liwei Deng, Penghao Chen, Ximu Zeng, Tianfu Wang, Yan Zhao, and Kai Zheng. 2024. Efficient Data-Aware Distance Comparison Operations for High- Dimensional Approximate Nearest Neighbor Search.Proc. VLDB Endow.18, 3 (Nov. 2024), 812–821. https://doi.org/10.14778/3712221.3712244
-
[13]
Wei Dong, Charikar Moses, and Kai Li. 2011. Efficient k-nearest neighbor graph construction for generic similarity measures. InProceedings of the 20th International Conference on World Wide Web(Hyderabad, India)(WWW ’11). Association for Computing Machinery, New York, NY, USA, 577–586. https: //doi.org/10.1145/1963405.1963487
-
[14]
Cong Fu, Changxu Wang, and Deng Cai. 2022. High Dimensional Similarity Search With Satellite System Graph: Efficiency, Scalability, and Unindexed Query Compatibility.IEEE Transactions on Pattern Analysis and Machine Intelligence44, 8 (2022), 4139–4150. https://doi.org/10.1109/TPAMI.2021.3067706
-
[15]
Cong Fu, Chao Xiang, Changxu Wang, and Deng Cai. 2019. Fast approximate nearest neighbor search with the navigating spreading-out graph.Proc. VLDB Endow.12, 5 (Jan. 2019), 461–474. https://doi.org/10.14778/3303753.3303754
-
[16]
Jianyang Gao and Cheng Long. 2023. High-Dimensional Approximate Nearest Neighbor Search: with Reliable and Efficient Distance Comparison Operations. Proc. ACM Manag. Data1, 2, Article 137 (June 2023), 27 pages. https://doi.org/ 10.1145/3589282
-
[17]
Yutong Gou, Jianyang Gao, Yuexuan Xu, and Cheng Long. 2025. SymphonyQG: Towards Symphonious Integration of Quantization and Graph for Approximate Nearest Neighbor Search.Proc. ACM Manag. Data3, 1, Article 80 (Feb. 2025), 26 pages. https://doi.org/10.1145/3709730
-
[18]
Hao Guo and Youyou Lu. 2026. Achieving Low-Latency Graph-Based Vector Search via Aligning Best-First Search Algorithm with SSD.ACM Trans. Storage 22, 2, Article 12 (March 2026), 30 pages. https://doi.org/10.1145/3793926
-
[19]
Kiana Hajebi, Yasin Abbasi-Yadkori, Hossein Shahbazi, and Hong Zhang. 2011. Fast approximate nearest-neighbor search with k-nearest neighbor graph. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence - Volume Volume Two(Barcelona, Catalonia, Spain)(IJCAI’11). AAAI Press, 1312–1317
2011
-
[20]
Reza Heydari-Gharaei, Rasoul Sharifi, Shima Kashef, and Hossein Nezamabadi- pour. 2025. A robust approach for outlier detection based on the ratio of number of reverse neighbors to neighbors.Pattern Anal. Appl.28, 1 (Jan. 2025), 30. https://doi.org/10.1007/s10044-024-01372-y
-
[21]
Lihua Hu, Hongkai Liu, Jifu Zhang, and Aiqin Liu. 2022. KR-DBSCAN: A density- based clustering algorithm based on reverse nearest neighbor and influence space. Expert Syst. Appl.186, C (Dec. 2022), 8. https://doi.org/10.1016/j.eswa.2021.115763
-
[22]
Piotr Indyk and Rajeev Motwani. 1998. Approximate nearest neighbors: towards removing the curse of dimensionality. InProceedings of the thirtieth annual ACM symposium on Theory of computing. 604–613
1998
-
[23]
Piotr Indyk and Haike Xu. 2023. Worst-case performance of popular approxi- mate nearest neighbor search implementations: guarantees and limitations. In Proceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Associates Inc., Red Hook, NY, USA, Article 2891, 18 pages
2023
-
[24]
Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. 2019. DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node. InAdvances in Neural Information Pro- cessing Systems, H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett (Eds.), Vol. 32. Curran As...
2019
-
[25]
Herve Jegou, Matthijs Douze, and Cordelia Schmid. 2011. Product Quantization for Nearest Neighbor Search.IEEE Trans. Pattern Anal. Mach. Intell.33, 1 (Jan. 2011), 117–128. https://doi.org/10.1109/TPAMI.2010.57
-
[26]
Proceedings of the ACM Web Conference 2025 , pages=
Sungjun Jung, Yongsang Park, Haeun Lee, Young H. Oh, and Jae W. Lee. 2025. Angular Distance-Guided Neighbor Selection for Graph-Based Approximate Nearest Neighbor Search. InProceedings of the ACM on Web Conference 2025 (Sydney NSW, Australia)(WWW ’25). Association for Computing Machinery, New York, NY, USA, 4014–4023. https://doi.org/10.1145/3696410.3714870
-
[27]
Hervé Jégou, Romain Tavenard, Matthijs Douze, and Laurent Amsaleg. 2011. Searching in one billion vectors: Re-rank with source coding. In2011 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). 861–864. https://doi.org/10.1109/ICASSP.2011.5946540
-
[28]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in Neural Information Processing Systems33 (2020), 9459–9474. 15
2020
-
[29]
Binhong Li, Xiao Yan, and Shangqi Lu. 2026. Fast-Convergent Proximity Graphs for Approximate Nearest Neighbor Search.Proc. ACM Manag. Data4, 1, Article 36 (April 2026), 24 pages. https://doi.org/10.1145/3786650
-
[30]
Liang Li, Shufeng Gong, Yanan Yang, Yiduo Wang, and Jie Wu. 2026. I/O Optimizations for Graph-Based Disk-Resident Approximate Nearest Neighbor Search: A Design Space Exploration. https://doi.org/10.48550/arXiv.2602.21514 arXiv:2602.21514 [cs]
-
[31]
Kejing Lu, Mineichi Kudo, Chuan Xiao, and Yoshiharu Ishikawa. 2021. HVS: hierarchical graph structure based on voronoi diagrams for solving approximate nearest neighbor search.Proceedings of the VLDB Endowment15, 2 (2021), 246– 258
2021
-
[32]
Kejing Lu, Chuan Xiao, and Yoshiharu Ishikawa. 2024. Probabilistic routing for graph-based approximate nearest neighbor search. InProceedings of the 41st International Conference on Machine Learning(Vienna, Austria)(ICML’24). JMLR.org, Article 1347, 19 pages
2024
-
[33]
Shangqi Lu and Yufei Tao. 2025. Proximity Graphs for Similarity Search: Fast Construction, Lower Bounds, and Euclidean Separation.Proc. ACM Manag. Data 3, 5, Article 280 (Nov. 2025), 25 pages. https://doi.org/10.1145/3767716
-
[34]
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom
Yu A. Malkov and D. A. Yashunin. 2020. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. IEEE Trans. Pattern Anal. Mach. Intell.42, 4 (April 2020), 824–836. https://doi. org/10.1109/TPAMI.2018.2889473
-
[35]
Brian McFee, Thierry Bertin-Mahieux, Daniel P.W. Ellis, and Gert R.G. Lanck- riet. 2012. The million song dataset challenge. InProceedings of the 21st In- ternational Conference on World Wide Web(Lyon, France)(WWW ’12 Com- panion). Association for Computing Machinery, New York, NY, USA, 909–916. https://doi.org/10.1145/2187980.2188222
-
[36]
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset.. InCoCo@NIPS (CEUR Workshop Proceedings), Tarek Richard Besold, Antoine Bordes, Artur S. d’Avila Garcez, and Greg Wayne (Eds.), Vol. 1773. CEUR-WS.org. http://dblp.uni-trier.de/db/conf/ni...
2016
-
[37]
Yun Peng, Byron Choi, Tsz Nam Chan, Jianye Yang, and Jianliang Xu. 2023. Efficient Approximate Nearest Neighbor Search in Multi-dimensional Databases. Proc. ACM Manag. Data1, 1, Article 54 (May 2023), 27 pages. https://doi.org/10. 1145/3588908
2023
-
[38]
Miloš Radovanović, Alexandros Nanopoulos, and Mirjana Ivanović. 2015. Reverse Nearest Neighbors in Unsupervised Distance-Based Outlier Detection.IEEE Transactions on Knowledge and Data Engineering27, 5 (2015), 1369–1382. https: //doi.org/10.1109/TKDE.2014.2365790
-
[39]
Payel Sadhukhan and Sarbani Palit. 2019. Reverse-nearest neighborhood based oversampling for imbalanced, multi-label datasets.Pattern Recogn. Lett.125, C (July 2019), 813–820. https://doi.org/10.1016/j.patrec.2019.08.009
-
[40]
Amit Singh, Hakan Ferhatosmanoglu, and Ali Şaman Tosun. 2003. High dimen- sional reverse nearest neighbor queries. InProceedings of the Twelfth International Conference on Information and Knowledge Management(New Orleans, LA, USA) (CIKM ’03). Association for Computing Machinery, New York, NY, USA, 91–98. https://doi.org/10.1145/956863.956882
-
[41]
Anbang Song, Ziqiang Yu, Wei Liu, Yating Xu, and Mingjin Tao. 2025. BRkNN- light: Batch Processing of Reverse k-Nearest Neighbor Queries for Moving Ob- jects on Road Networks. InProceedings of the 19th International Symposium on Spatial and Temporal Data (SSTD ’25). Association for Computing Machinery, New York, NY, USA, 80–89. https://doi.org/10.1145/374...
-
[42]
Yitong Song, Kai Wang, Bin Yao, Zhida Chen, Jiong Xie, and Feifei Li. 2024. Effi- cient Reverse 𝑘 Approximate Nearest Neighbor Search Over High-Dimensional Vectors. In2024 IEEE 40th International Conference on Data Engineering (ICDE). 4262–4274. https://doi.org/10.1109/ICDE60146.2024.00325
-
[43]
Yufei Tao, Dimitris Papadias, and Xiang Lian. 2004. Reverse kNN search in arbitrary dimensionality. InProceedings of the Thirtieth International Conference on Very Large Data Bases - Volume 30(Toronto, Canada)(VLDB ’04). VLDB Endowment, 744–755
2004
-
[44]
Yufei Tao, Dimitris Papadias, Xiang Lian, and Xiaokui Xiao. 2007. Multidi- mensional reverse kNN search.The VLDB Journal16, 3 (July 2007), 293–316. https://doi.org/10.1007/s00778-005-0168-2
-
[45]
Kento Tatsuno, Daisuke Miyashita, Taiga Ikeda, Kiyoshi Ishiyama, Kazunari Sumiyoshi, and Jun Deguchi. 2025. AiSAQ: All-in-Storage ANNS with Product Quantization for DRAM-free Information Retrieval. arXiv:2404.06004 [cs.IR] https://arxiv.org/abs/2404.06004
arXiv 2025
-
[46]
Hongya Wang, Wenlong Wu, Cong Luo, Aobei Bian, Chunguang Meng, Yishuo Wu, and Ji Sun. 2025. Boosting Accuracy and Efficiency for Vector Retrieval with Local Scaling Graph. In2025 IEEE 41st International Conference on Data Engineering (ICDE). 336–348. https://doi.org/10.1109/ICDE65448.2025.00032
-
[47]
Mengzhao Wang, Haotian Wu, Xiangyu Ke, Yunjun Gao, Xiaoliang Xu, and Lu Chen. 2024. An Interactive Multi-Modal Query Answering System with Retrieval-Augmented Large Language Models.Proc. VLDB Endow.17, 12 (Aug. 2024), 4333–4336. https://doi.org/10.14778/3685800.3685868
-
[48]
Mengzhao Wang, Haotian Wu, Xiangyu Ke, Yunjun Gao, Yifan Zhu, and Wenchao Zhou. 2025. Accelerating Graph Indexing for ANNS on Modern CPUs.Proc. ACM Manag. Data3, 3, Article 123 (June 2025), 29 pages. https://doi.org/10.1145/ 3725260
2025
-
[49]
Mengzhao Wang, Weizhi Xu, Xiaomeng Yi, Songlin Wu, Zhangyang Peng, Xi- angyu Ke, Yunjun Gao, Xiaoliang Xu, Rentong Guo, and Charles Xie. 2024. Starling: An I/O-Efficient Disk Graph Index Framework for High-Dimensional Vector Similarity Search on Data Segment.Proc. ACM Manag. Data2, 1, Article 14 (March 2024), 27 pages. https://doi.org/10.1145/3639269
-
[50]
Mengzhao Wang, Xiaoliang Xu, Qiang Yue, and Yuxiang Wang. 2021. A com- prehensive survey and experimental comparison of graph-based approximate nearest neighbor search.Proc. VLDB Endow.14, 11 (July 2021), 1964–1978. https://doi.org/10.14778/3476249.3476255
-
[51]
Zeyu Wang, Peng Wang, Themis Palpanas, and Wei Wang. 2023. Graph- and Tree-based Indexes for High-dimensional Vector Similarity Search: Analyses, Comparisons, and Future Directions.IEEE Data Eng. Bull.47, 3 (2023), 3–21. http://sites.computer.org/debull/A23sept/p3.pdf
2023
-
[52]
Wei Wu, Fei Yang, Chee-Yong Chan, and Kian-Lee Tan. 2008. Finch: Evaluating reverse k-nearest-neighbor queries on location data.Proceedings of the VLDB Endowment1, 1 (2008), 1056–1067
2008
-
[53]
Chenyi Xia, Wynne Hsu, and Mong Li Lee. 2005. ERkNN: efficient reverse k- nearest neighbors retrieval with local kNN-distance estimation. InProceedings of the 14th ACM International Conference on Information and Knowledge Management (Bremen, Germany)(CIKM ’05). Association for Computing Machinery, New York, NY, USA, 533–540. https://doi.org/10.1145/109955...
-
[54]
Jiadong Xie, Jeffrey Xu Yu, and Yingfan Liu. 2025. Graph based k-nearest neighbor search revisited.ACM Transactions on Database Systems50, 4 (2025), 1–30
2025
-
[55]
Congyun Yang and King-Ip Lin. 2001. An index structure for efficient reverse nearest neighbor queries. InProceedings 17th International Conference on Data Engineering. IEEE, 485–492
2001
-
[56]
Mingyu Yang, Liuchang Jing, Wentao Li, and Wei Wang. 2026. Quantization Meets Projection: A Happy Marriage for Approximate k-Nearest Neighbor Search. arXiv:2411.06158 [cs.DB] https://arxiv.org/abs/2411.06158
arXiv 2026
-
[57]
Mingyu Yang, Wentao Li, Jiabao Jin, Xiaoyao Zhong, Xiangyu Wang, Zhitao Shen, Wei Jia, and Wei Wang. 2025. Effective and General Distance Computation for Approximate Nearest Neighbor Search. In2025 IEEE 41st International Conference on Data Engineering (ICDE). 1098–1110. https://doi.org/10.1109/ICDE65448.2025. 00087
-
[58]
Shiyu Yang, Muhammad Aamir Cheema, Xuemin Lin, and Ying Zhang. 2014. SLICE: Reviving regions-based pruning for reverse k nearest neighbors queries. In2014 IEEE 30th International Conference on Data Engineering. 760–771. https: //doi.org/10.1109/ICDE.2014.6816698
-
[59]
Ori Yoran, Tomer Wolfson, Ori Ram, and Jonathan Berant. 2024. Making Retrieval- Augmented Language Models Robust to Irrelevant Context. InThe Twelfth Inter- national Conference on Learning Representations. https://openreview.net/forum? id=ZS4m74kZpH
2024
-
[60]
Yue Yu, Wei Ping, Zihan Liu, Boxin Wang, Jiaxuan You, Chao Zhang, Mohammad Shoeybi, and Bryan Catanzaro. 2024. RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems. https://openreview.net/ forum?id=S1fc92uemC
2024
-
[61]
Aimin Zhang, Hualong Yu, Zhangjun Huan, Xibei Yang, Shang Zheng, and Shang Gao. 2022. SMOTE-RkNN: A hybrid re-sampling method based on SMOTE and reverse k-nearest neighbors.Information Sciences595 (2022), 70–88. https: //doi.org/10.1016/j.ins.2022.02.038
-
[62]
Xiaoyao Zhong, Haotian Li, Jiabao Jin, Mingyu Yang, Deming Chu, Xiangyu Wang, Zhitao Shen, Wei Jia, George Gu, Yi Xie, et al. 2025. VSAG: An Optimized Search Framework for Graph-Based Approximate Nearest Neighbor Search. Proceedings of the VLDB Endowment18, 12 (2025), 5017–5030. 16
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.