AirDreamer: Generalist Drone Navigation with World Models
Pith reviewed 2026-06-28 09:59 UTC · model grok-4.3
The pith
A world model paired with an RL policy and sparse rewards lets drones navigate unseen cluttered spaces without hand-crafted perception or tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
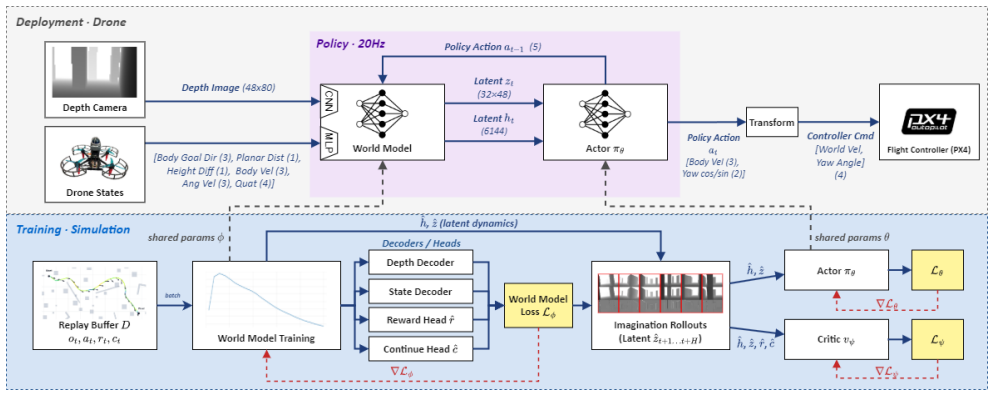
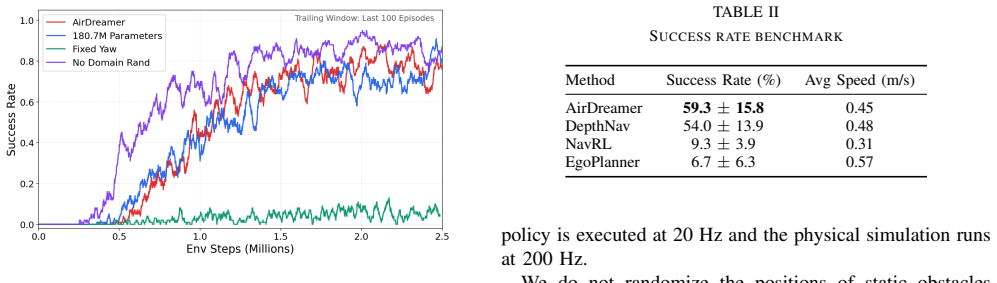
The framework navigates with a reinforcement-learning-based policy on top of a world-model-based environment understanding. A sparse reward function without hand-crafted shaping terms is designed to avoid local minima traps and encourage yaw control behaviors. In simulation and on real drones, the method exhibits emergent capabilities for navigating complex, unseen environments and escaping local optima where other methods fail, achieving a 5.3% higher navigation success rate than the best baseline along with effective sim-to-real transfer without any tuning during deployment.
What carries the argument
World-model-based environment understanding feeding an RL policy, driven by a sparse reward function that avoids local minima.
If this is right
- Drones can succeed in complex unseen environments that trap other methods in local optima.
- Navigation succeeds without environment-specific perception pipelines or hand-crafted rules.
- A 5.3% higher success rate holds in challenging simulation maps.
- Sim-to-real transfer occurs directly without deployment adjustments.
Where Pith is reading between the lines
- The same world-model-plus-RL structure could be tested on other mobile platforms that currently need custom perception stacks.
- Emergent yaw behaviors imply the world model captures dynamics useful beyond position goals.
- Extending the sparse reward to multi-drone coordination would test whether the generalization benefit scales.
Load-bearing premise
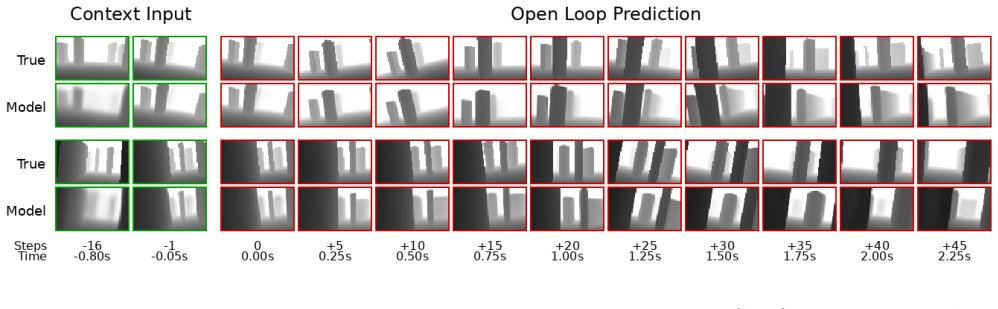
The world model gives sufficiently accurate predictions of environmental structure relative to the drone's motion capabilities in completely new scene layouts.
What would settle it
A controlled test in a new cluttered map where the method records a lower success rate than the strongest baseline or requires any real-world tuning to match simulation performance.
Figures




read the original abstract
Navigating a drone in unseen and cluttered environments requires reliable generalization to unseen scene layouts and understanding of environmental structure relative to the robot's capabilities. Previous methods, which assume the same environment configuration, often rely heavily on human-designed perception pipelines and predefined rules to guide the robot toward the target. This process is environment-dependent and generalizes poorly across environments. Inspired by animal navigation behavior, we design a navigation framework that navigates with a reinforcement-learning-based policy on top of a world-model-based environment understanding to overcome these issues. In addition, a sparse reward function without hand-crafted shaping terms is designed to avoid local minima traps and encourage yaw control behaviors. In simulation and on real drones, our method exhibits emergent capabilities for navigating complex, unseen environments and escaping local optima where other methods fail. In challenging maps, it achieves a 5.3% higher navigation success rate than best baseline. Furthermore, the proposed framework achieves effective sim-to-real transfer without any tuning during deployment. The code will be publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AirDreamer, a drone navigation framework combining a world-model-based environment understanding module with a reinforcement-learning policy trained under a sparse reward function (no hand-crafted shaping). It claims emergent navigation capabilities in complex unseen environments, escape from local optima, a 5.3% higher success rate than the best baseline on challenging maps, and zero-shot sim-to-real transfer without deployment tuning.
Significance. If the performance claims and the role of the world model are substantiated with quantitative validation, the approach could contribute to more generalist drone navigation that reduces reliance on environment-specific perception pipelines and rules.
major comments (3)
- [Abstract] Abstract: the central performance claim of a 5.3% success-rate improvement is stated without identifying the baselines, map definitions, number of trials, or any statistical significance test, preventing assessment of whether the gain is load-bearing or reproducible.
- [Abstract] Abstract and §3 (method description): no prediction-error metrics, reconstruction loss on held-out maps, or ablation isolating the world-model contribution versus the sparse-reward RL policy are reported, leaving the key assumption that the world model supplies sufficiently accurate and generalizable forecasts unquantified.
- [Abstract] Abstract: the sim-to-real transfer claim is presented without any quantitative comparison of world-model prediction accuracy or policy behavior between simulation and real-robot deployment, so the zero-tuning assertion cannot be evaluated.
minor comments (1)
- The abstract states that code will be publicly available, but no repository link or availability statement appears in the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to improve clarity and substantiation of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim of a 5.3% success-rate improvement is stated without identifying the baselines, map definitions, number of trials, or any statistical significance test, preventing assessment of whether the gain is load-bearing or reproducible.
Authors: We agree the abstract would benefit from additional context. In the revision we will expand the abstract to name the baselines, define the challenging maps, state the number of trials, and note that the reported improvement is statistically significant. Full experimental details already appear in the results section. revision: yes
-
Referee: [Abstract] Abstract and §3 (method description): no prediction-error metrics, reconstruction loss on held-out maps, or ablation isolating the world-model contribution versus the sparse-reward RL policy are reported, leaving the key assumption that the world model supplies sufficiently accurate and generalizable forecasts unquantified.
Authors: The manuscript emphasizes end-to-end navigation success. We acknowledge that explicit quantification of the world-model contribution would strengthen the paper and will add, in the revision, an ablation isolating the world-model component together with prediction-error and reconstruction metrics on held-out maps. revision: yes
-
Referee: [Abstract] Abstract: the sim-to-real transfer claim is presented without any quantitative comparison of world-model prediction accuracy or policy behavior between simulation and real-robot deployment, so the zero-tuning assertion cannot be evaluated.
Authors: We will revise the abstract to reference the quantitative sim-to-real results already present in the experiments (success-rate parity between sim and real without tuning). Any additional prediction-accuracy comparisons between domains will be highlighted in the revised text. revision: yes
Circularity Check
No circularity; empirical results rest on external evaluation
full rationale
The paper describes an RL policy trained atop a learned world model for drone navigation, with claims supported by simulation success rates and zero-shot real-robot transfer. No equations, derivations, or parameter-fitting steps are presented that reduce the reported 5.3% success-rate improvement or emergent behaviors to quantities defined by the model's own fitted values. The central performance claims are evaluated against external baselines in held-out environments and physical hardware, rendering them falsifiable outside any internal definitions. No self-citation chains or ansatzes are invoked as load-bearing uniqueness theorems. This is the expected non-finding for an applied robotics paper whose value lies in experimental outcomes rather than closed-form derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CERBERUS in the DARPA subterranean chal- lenge,
M. Tranzattoet al., “CERBERUS in the DARPA subterranean chal- lenge,”Science Robotics, vol. 7, no. 66, p. eabp9742, 2022
2022
-
[2]
FASTER: Fast and safe trajectory planner for navigation in unknown environments,
J. Tordesillas, B. T. Lopez, M. Everett, and J. P. How, “FASTER: Fast and safe trajectory planner for navigation in unknown environments,” IEEE Transactions on Robotics, vol. 38, no. 2, pp. 922–938, 2021
2021
-
[3]
EGO-Planner: An ESDF-free gradient-based local planner for quadrotors,
X. Zhou, Z. Wang, H. Ye, C. Xu, and F. Gao, “EGO-Planner: An ESDF-free gradient-based local planner for quadrotors,”IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 478–485, 2020
2020
-
[4]
Learning high-speed flight in the wild,
A. Loquercio, E. Kaufmann, R. Ranftl, M. M ¨uller, V . Koltun, and D. Scaramuzza, “Learning high-speed flight in the wild,”Science Robotics, vol. 6, no. 59, p. eabg5810, 2021
2021
-
[5]
Quadrotor navigation using reinforcement learning with privileged information,
J. Lee, A. Rathod, K. Goel, J. Stecklein, and W. Tabib, “Quadrotor navigation using reinforcement learning with privileged information,” 2025, arXiv:2509.08177
-
[6]
MA VRL: Learn to fly in cluttered environments with varying speed,
H. Yu, C. De Wagter, and G. C. H. E. de Croon, “MA VRL: Learn to fly in cluttered environments with varying speed,”IEEE Robotics and Automation Letters, vol. 10, no. 2, pp. 1441–1448, 2025
2025
-
[7]
Hippocampal place-cell sequences depict future paths to remembered goals,
B. E. Pfeiffer and D. J. Foster, “Hippocampal place-cell sequences depict future paths to remembered goals,”Nature, vol. 497, no. 7447, pp. 74–79, 2013
2013
-
[8]
An MPC framework for efficient navigation of mobile robots in cluttered environments,
J. K ¨ohler, D. Zhang, R. Soloperto, A. Carron, and M. Zeilinger, “An MPC framework for efficient navigation of mobile robots in cluttered environments,” 2025, arXiv:2509.15917
-
[9]
NavRL: Learning safe flight in dynamic environments,
Z. Xu, X. Han, H. Shen, H. Jin, and K. Shimada, “NavRL: Learning safe flight in dynamic environments,”IEEE Robotics and Automation Letters, vol. 10, no. 4, pp. 3668–3675, 2025
2025
-
[10]
DreamerNav: Learning-based autonomous navigation in dynamic indoor environments using world models,
S. Shanks, J. Embley-Riches, J. Liu, A. M. Delfaki, C. Ciliberto, and D. Kanoulas, “DreamerNav: Learning-based autonomous navigation in dynamic indoor environments using world models,”Frontiers in Robotics and AI, vol. 12, p. 1655171, 2025
2025
-
[11]
Recurrent world models facilitate policy evolution,
D. Ha and J. Schmidhuber, “Recurrent world models facilitate policy evolution,” inAdvances in Neural Information Processing Systems 31 (NeurIPS), 2018, pp. 2451–2463
2018
-
[12]
Learning interactive real-world simulators,
S. Yanget al., “Learning interactive real-world simulators,” inPro- ceedings of the International Conference on Learning Representations (ICLR), 2024
2024
-
[13]
Genie: Generative interactive environments,
J. Bruceet al., “Genie: Generative interactive environments,” in Proceedings of the International Conference on Machine Learning (ICML), 2024, pp. 4603–4623
2024
-
[14]
Path- dreamer: A world model for indoor navigation,
J. Y . Koh, H. Lee, Y . Yang, J. Baldridge, and P. Anderson, “Path- dreamer: A world model for indoor navigation,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 14 718–14 728
2021
-
[15]
Navigation world models,
A. Bar, G. Zhou, D. Tran, T. Darrell, and Y . LeCun, “Navigation world models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 15 791–15 801
2025
-
[16]
Day- Dreamer: World models for physical robot learning,
P. Wu, A. Escontrela, D. Hafner, P. Abbeel, and K. Goldberg, “Day- Dreamer: World models for physical robot learning,” inConference on Robot Learning (CoRL). PMLR, 2023, pp. 2226–2240
2023
-
[17]
A. Verraest, S. Bahnam, R. Ferede, G. de Croon, and C. De Wagter, “SkyDreamer: Interpretable end-to-end vision-based drone racing with model-based reinforcement learning,” 2025, arXiv:2510.14783
-
[18]
Mastering diverse control tasks through world models,
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap, “Mastering diverse control tasks through world models,”Nature, pp. 1–7, 2025
2025
-
[19]
OmniDrones: An efficient and flexible platform for reinforcement learning in drone control,
B. Xu, F. Gao, C. Yu, R. Zhang, Y . Wu, and Y . Wang, “OmniDrones: An efficient and flexible platform for reinforcement learning in drone control,”IEEE Robotics and Automation Letters, vol. 9, no. 3, pp. 2838–2845, 2024
2024
-
[20]
XTDrone: A customizable multi-rotor UA Vs simulation platform,
K. Xiao, S. Tan, G. Wang, X. An, X. Wang, and X. Wang, “XTDrone: A customizable multi-rotor UA Vs simulation platform,” inProceedings of the 4th International Conference on Robotics and Automation Sciences (ICRAS), 2020, pp. 55–61
2020
-
[21]
FAST-LIO2: Fast direct LiDAR-inertial odometry,
W. Xu, Y . Cai, D. He, J. Lin, and F. Zhang, “FAST-LIO2: Fast direct LiDAR-inertial odometry,”IEEE Transactions on Robotics, vol. 38, no. 4, pp. 2053–2073, 2022
2053
-
[22]
One net to rule them all: Domain randomization in quadcopter racing across different platforms,
R. Ferede, T. Blaha, E. Lucassen, C. De Wagter, and G. C. H. E. de Croon, “One net to rule them all: Domain randomization in quadcopter racing across different platforms,” inProceedings of the IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 6357–6363
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.