Generalizing Graph Foundation Models via Hyperbolic Retrieval-Augmented Generation
Pith reviewed 2026-06-28 08:23 UTC · model grok-4.3
The pith
Hyperbolic space indexing for external knowledge lets graph foundation models retrieve hierarchical structures without losing granularity or encountering hubness during zero-shot inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
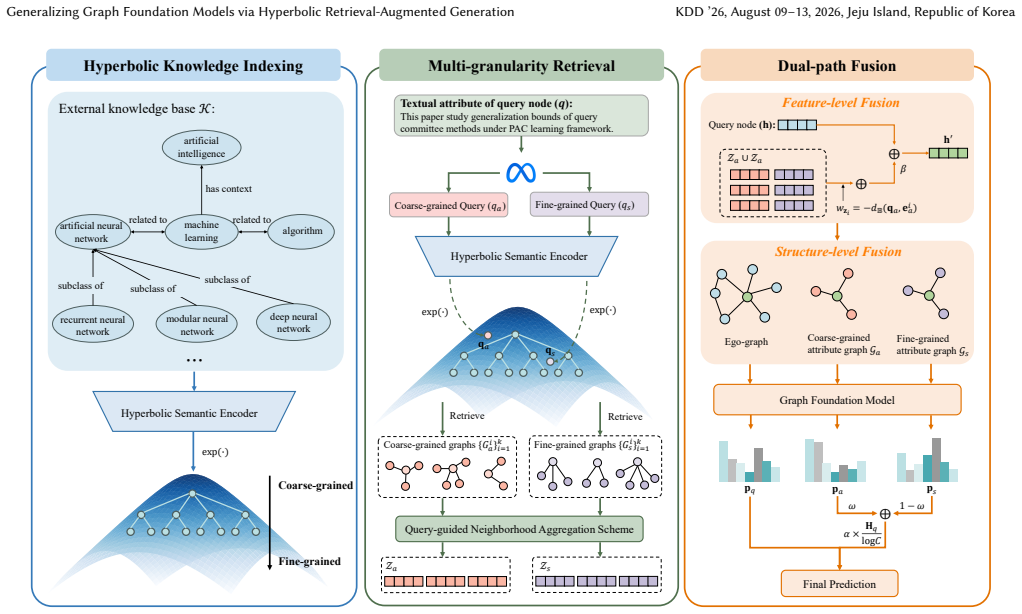
The HyRAG framework indexes external knowledge bases inside hyperbolic space so that tree-like hierarchies are preserved, performs coarse- and fine-grained retrieval to supply global semantic anchors and local nuances, and fuses the results into graph foundation models along both feature and structural paths, yielding improved zero-shot performance on graph tasks.
What carries the argument
Hyperbolic Knowledge Indexing module that embeds external knowledge bases in hyperbolic space to retain their tree-like hierarchies for subsequent retrieval.
If this is right
- Retrieval precision improves because semantic granularity is retained at multiple scales.
- The hubness phenomenon is reduced when nearest-neighbor search operates in a space whose volume growth matches the data structure.
- Knowledge integration occurs simultaneously at feature and structural levels inside the downstream graph model.
- Zero-shot inference on graph benchmarks improves without any parameter updates to the foundation model.
Where Pith is reading between the lines
- The same hyperbolic indexing step could be applied to retrieval-augmented systems outside graphs whenever the external corpus is organized as a taxonomy or tree.
- If the performance gap disappears once Euclidean retrieval is given an explicit hierarchy-aware distance, the advantage would trace to the geometry rather than to the retrieval logic itself.
Load-bearing premise
External knowledge bases possess tree-like hierarchical structure that hyperbolic geometry matches more closely than Euclidean geometry.
What would settle it
If a Euclidean retrieval baseline that uses the identical knowledge base and the same coarse/fine retrieval logic produces equal zero-shot accuracy gains on the same graph benchmarks, the geometric mismatch claim would be falsified.
Figures

read the original abstract
Graph foundation models (GFMs) emerged as a dominant paradigm in graph representation learning by leveraging large-scale pre-training for cross-domain inference. However, the parameterized knowledge encoded within these models is insufficient to cope with distribution shifts, limiting their generalization ability. To mitigate this issue, retrieval-augmented generation (RAG) has been introduced to incorporate external knowledge at inference time. Nevertheless, existing RAG frameworks operating in Euclidean space suffer from a fundamental geometric limitation: the polynomial volume growth of Euclidean space is inherently mismatched with the tree-structured external knowledge bases. This mismatch leads to the loss of semantic granularity in retrieval and gives rise to the hubness phenomenon.To address this limitation, we propose a Hyperbolic Retrieval-Augmented Generation (HyRAG) framework designed to enhance the generalization capabilities of GFMs. Specifically, the introduced Hyperbolic Knowledge Indexing module retains the tree-like hierarchies of the external knowledge base by modeling them within hyperbolic space. The Multi-granularity Retrieval module then provides GFMs with the global semantic anchors and local semantic nuances through coarse-grained and fine-grained knowledge retrieval, respectively. Finally, the Dual-path Fusion module achieves effective knowledge integration for graph tasks at both the feature and structural levels. Experiments on multiple graph benchmarks demonstrate significant improvements in the zero-shot setting, highlighting the generalization of our method for robust GFMs inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HyRAG, a hyperbolic retrieval-augmented generation framework to improve zero-shot generalization of graph foundation models (GFMs). It identifies a geometric mismatch between Euclidean RAG (polynomial volume growth) and tree-structured external knowledge bases, leading to semantic granularity loss and hubness. The framework consists of a Hyperbolic Knowledge Indexing module to preserve hierarchies in hyperbolic space, a Multi-granularity Retrieval module for coarse- and fine-grained retrieval, and a Dual-path Fusion module for feature- and structure-level integration. Experiments on multiple graph benchmarks are claimed to show significant zero-shot improvements.
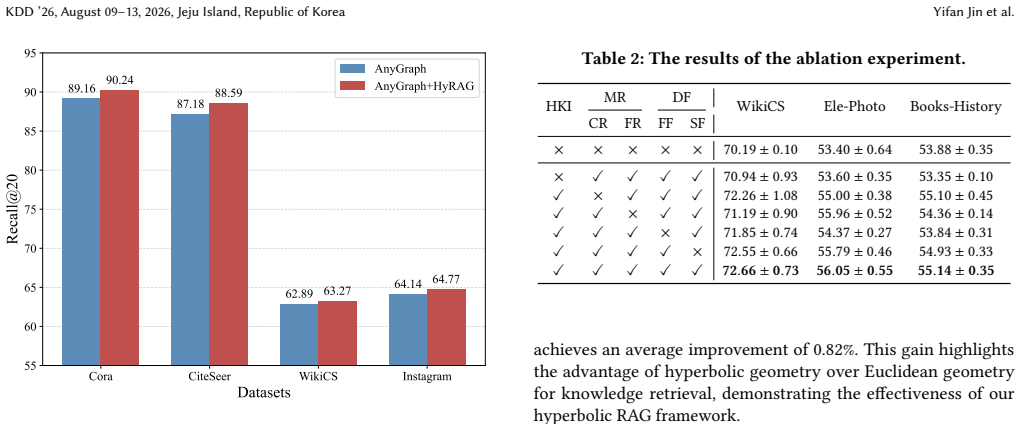
Significance. If the framework and empirical results hold under detailed scrutiny, the geometric motivation could offer a principled way to handle hierarchical external knowledge in graph tasks, addressing a plausible limitation of Euclidean RAG. The approach is externally motivated and introduces no free parameters in the abstract, which is a positive feature. However, the provided abstract supplies no equations, algorithms, ablation studies, or quantitative results, preventing assessment of whether the claimed gains are load-bearing or reproducible.
major comments (2)
- [Abstract] Abstract: the central claim that 'experiments on multiple graph benchmarks demonstrate significant improvements in the zero-shot setting' is presented without any datasets, baselines, metrics, error bars, or verification steps. This renders the empirical contribution unexaminable and is load-bearing for the generalization assertion.
- [Abstract] Abstract (paragraph on geometric limitation): the statement that Euclidean polynomial volume growth is 'inherently mismatched' with tree-structured KBs is asserted without a supporting derivation, volume-growth comparison, or reference to prior hyperbolic graph work; this motivates the entire framework but remains unverified.
Simulated Author's Rebuttal
We thank the referee for the feedback. The abstract is intentionally concise, but the full manuscript supplies the requested experimental details, derivations, and references. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'experiments on multiple graph benchmarks demonstrate significant improvements in the zero-shot setting' is presented without any datasets, baselines, metrics, error bars, or verification steps. This renders the empirical contribution unexaminable and is load-bearing for the generalization assertion.
Authors: The abstract summarizes the contribution at a high level, as is standard. The full manuscript contains Section 4 (Experiments) that specifies the graph benchmarks, baselines, metrics (including zero-shot accuracy and other measures), and reports results with standard deviations from multiple runs. These elements allow direct examination of the empirical claims. The abstract itself is not intended to contain this level of detail due to length constraints. revision: no
-
Referee: [Abstract] Abstract (paragraph on geometric limitation): the statement that Euclidean polynomial volume growth is 'inherently mismatched' with tree-structured KBs is asserted without a supporting derivation, volume-growth comparison, or reference to prior hyperbolic graph work; this motivates the entire framework but remains unverified.
Authors: The abstract states the core geometric motivation concisely. The manuscript's Introduction and Related Work sections provide the supporting discussion, including references to established results on exponential volume growth in hyperbolic space versus polynomial growth in Euclidean space, as well as prior hyperbolic graph embedding literature. A short formal comparison of volume growth can be added to an appendix if the editor requests it. revision: partial
Circularity Check
No significant circularity
full rationale
The provided abstract and description contain no equations, fitted parameters, derivations, or self-citations. The framework is motivated by an external geometric observation (Euclidean volume growth vs. tree-structured KBs) and introduces named modules (Hyperbolic Knowledge Indexing, Multi-granularity Retrieval, Dual-path Fusion) whose claimed benefits are presented as experimental outcomes rather than reductions to prior fitted quantities or self-referential definitions. No load-bearing step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption External knowledge bases exhibit tree-like hierarchies.
- domain assumption Euclidean polynomial volume growth mismatches tree structures and produces semantic loss plus hubness.
invented entities (3)
-
Hyperbolic Knowledge Indexing module
no independent evidence
-
Multi-granularity Retrieval module
no independent evidence
-
Dual-path Fusion module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Yushi Bai, Zhitao Ying, Hongyu Ren, and Jure Leskovec. 2021. Modeling hetero- geneous hierarchies with relation-specific hyperbolic cones.Advances in Neural Information Processing Systems34 (2021), 12316–12327
2021
-
[2]
Jaime Carbonell and Jade Goldstein. 1998. The use of MMR, diversity-based reranking for reordering documents and producing summaries. InProceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval. 335–336
1998
-
[3]
Runjin Chen, Tong Zhao, Ajay Jaiswal, Neil Shah, and Zhangyang Wang. 2024. Llaga: Large language and graph assistant.arXiv preprint arXiv:2402.08170(2024)
arXiv 2024
-
[4]
Yuntao Du, Xinjun Zhu, Lu Chen, Baihua Zheng, and Yunjun Gao. 2022. HAKG: Hierarchy-aware knowledge gated network for recommendation. InProceedings of the 45th international ACM SIGIR conference on Research and development in Information Retrieval. 1390–1400
2022
-
[5]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130(2024)
Pith/arXiv arXiv 2024
-
[6]
C Lee Giles, Kurt D Bollacker, and Steve Lawrence. 1998. CiteSeer: An automatic citation indexing system. InProceedings of the third ACM conference on Digital libraries
1998
-
[7]
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. 2024. Lightrag: Simple and fast retrieval-augmented generation.arXiv preprint arXiv:2410.05779 (2024)
Pith/arXiv arXiv 2024
-
[8]
Bernal Jiménez Gutiérrez, Yiheng Shu, Weijian Qi, Sizhe Zhou, and Yu Su. 2025. From rag to memory: Non-parametric continual learning for large language models.arXiv preprint arXiv:2502.14802(2025)
Pith/arXiv arXiv 2025
-
[9]
Yufei He, Yuan Sui, Xiaoxin He, and Bryan Hooi. 2025. Unigraph: Learning a unified cross-domain foundation model for text-attributed graphs. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
2025
-
[10]
Zhenyu Hou, Xiao Liu, Yukuo Cen, Yuxiao Dong, Hongxia Yang, Chunjie Wang, and Jie Tang. 2022. Graphmae: Self-supervised masked graph autoencoders. In Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining. 594–604
2022
-
[11]
Xuanwen Huang, Kaiqiao Han, Yang Yang, Dezheng Bao, Quanjin Tao, Ziwei Chai, and Qi Zhu. 2024. Can GNN be Good Adapter for LLMs?(WWW ’24). Association for Computing Machinery, New York, NY, USA, 893–904. doi:10. 1145/3589334.3645627
arXiv 2024
-
[12]
Filip Ilievski, Pedro Szekely, and Bin Zhang. 2021. Cskg: The commonsense knowledge graph. InEuropean Semantic Web Conference. Springer, 680–696
2021
-
[13]
Gautier Izacard and Edouard Grave. 2021. Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, EACL 2021, Online, April 19 - 23, 2021, Paola Merlo, Jörg Tiedemann, and Reut Tsarfaty (Eds.). Associati...
-
[14]
Xinke Jiang, Rihong Qiu, Yongxin Xu, Yichen Zhu, Ruizhe Zhang, Yuchen Fang, Chu Xu, Junfeng Zhao, and Yasha Wang. 2024. Ragraph: A general retrieval- augmented graph learning framework.Advances in Neural Information Processing Systems37 (2024), 29948–29985
2024
-
[15]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[16]
Haoyang Li, Haibo Chen, Xin Wang, and Wenwu Zhu. 2026. Out-of-Distribution Generalization in Graph Foundation Models.arXiv preprint arXiv:2601.21067 (2026)
arXiv 2026
-
[17]
Yuhan Li, Peisong Wang, Zhixun Li, Jeffrey Xu Yu, and Jia Li. 2024. Zerog: Investigating cross-dataset zero-shot transferability in graphs. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1725–1735
2024
-
[18]
Hao Liu, Jiarui Feng, Lecheng Kong, Ningyue Liang, Dacheng Tao, Yixin Chen, and Muhan Zhang. 2023. One for all: Towards training one graph model for all classification tasks.arXiv preprint arXiv:2310.00149(2023)
arXiv 2023
-
[19]
Haoran Luo, Guanting Chen, Yandan Zheng, Xiaobao Wu, Yikai Guo, Qika Lin, Yu Feng, Zemin Kuang, Meina Song, Yifan Zhu, et al. 2025. HyperGraphRAG: Retrieval-Augmented Generation via Hypergraph-Structured Knowledge Repre- sentation.arXiv preprint arXiv:2503.21322(2025)
arXiv 2025
-
[20]
Péter Mernyei and Cătălina Cangea. 2020. Wiki-cs: A wikipedia-based benchmark for graph neural networks.arXiv preprint arXiv:2007.02901(2020)
arXiv 2020
-
[21]
Maximillian Nickel and Douwe Kiela. 2017. Poincaré embeddings for learning hierarchical representations.Advances in neural information processing systems 30 (2017)
2017
-
[22]
Maximillian Nickel and Douwe Kiela. 2018. Learning continuous hierarchies in the lorentz model of hyperbolic geometry. InInternational conference on machine learning. PMLR, 3779–3788
2018
-
[23]
Zhe Pan and Peng Wang. 2021. Hyperbolic hierarchy-aware knowledge graph embedding for link prediction. InFindings of the Association for Computational Linguistics: EMNLP 2021. 2941–2948
2021
-
[24]
Miloš Radovanović, Alexandros Nanopoulos, and Mirjana Ivanović. 2009. Nearest neighbors in high-dimensional data: The emergence and influence of hubs. In Proceedings of the 26th Annual International Conference on Machine Learning. 865–872
2009
-
[25]
Nils Reimers and Iryna Gurevych. 2020. Making monolingual sentence embed- dings multilingual using knowledge distillation.arXiv preprint arXiv:2004.09813 (2020)
arXiv 2020
-
[26]
Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. 2008. Collective classification in network data.AI magazine (2008)
2008
-
[27]
Bin Shang, Yinliang Zhao, Jun Liu, and Di Wang. 2024. Mixed geometry message and trainable convolutional attention network for knowledge graph completion. InProceedings of the AAAI conference on artificial intelligence, Vol. 38. 8966–8974
2024
-
[28]
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. 2024. Graphgpt: Graph instruction tuning for large language models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 491–500
2024
-
[29]
Yixuan Tang and Yi Yang. 2024. MultiHop-RAG: Benchmarking Retrieval- Augmented Generation for Multi-Hop Queries.CoRRabs/2401.15391 (2024). arXiv:2401.15391 doi:10.48550/ARXIV.2401.15391
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.15391 2024
-
[30]
Zhen Tao, Xinke Jiang, Qingshuai Feng, Haoyu Zhang, Lun Du, Yuchen Fang, Hao Miao, Bangquan Xie, and Qingqiang Sun. 2026. Task-Aware Retrieval Aug- mentation for Dynamic Recommendation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 15779–15787
2026
-
[31]
Shantanu Thakoor, Corentin Tallec, Mohammad Gheshlaghi Azar, Rémi Munos, Petar Veličković, and Michal Valko. 2021. Bootstrapped representation learning on graphs. InICLR 2021 workshop on geometrical and topological representation learning
2021
-
[32]
Raja Vavekanand and Kira Sam. 2024. Llama 3.1: An in-depth analysis of the next-generation large language model
2024
-
[33]
Petar Velickovic, William Fedus, William L Hamilton, Pietro Liò, Yoshua Bengio, and R Devon Hjelm. 2019. Deep graph infomax.ICLR (poster)2, 3 (2019), 4
2019
-
[34]
Xingliang Wang, Zemin Liu, Junxiao Han, and Shuiguang Deng. [n. d.]. RAG4GFM: Bridging Knowledge Gaps in Graph Foundation Models through Graph Retrieval Augmented Generation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[35]
Zhihao Wen and Yuan Fang. 2023. Augmenting low-resource text classification with graph-grounded pre-training and prompting. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 506–516
2023
-
[36]
Lianghao Xia and Chao Huang. 2024. AnyGraph: Graph Foundation Model in the Wild.CoRRabs/2408.10700 (2024). arXiv:2408.10700 doi:10.48550/ARXIV. 2408.10700
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[37]
Zheming Xu, He Liu, Congyan Lang, Tao Wang, Yidong Li, and Michael C. Kampffmeyer. 2025. A Hubness Perspective on Representation Learning for Graph-Based Multi-View Clustering. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. Com- puter Vision Foundation / IEEE, 15528–15537. doi:10.1109/CVP...
-
[38]
Hao Yan, Chaozhuo Li, Ruosong Long, Chao Yan, Jianan Zhao, Wenwen Zhuang, Jun Yin, Peiyan Zhang, Weihao Han, Hao Sun, et al. 2023. A Comprehensive Study on Text-attributed Graphs: Benchmarking and Rethinking. InProc. of NeurIPS
2023
-
[39]
Xingtong Yu, Zechuan Gong, Chang Zhou, Yuan Fang, and Hui Zhang. 2025. Samgpt: Text-free graph foundation model for multi-domain pre-training and cross-domain adaptation. InProceedings of the ACM on Web Conference 2025. 1142–1153
2025
-
[40]
Haonan Yuan, Qingyun Sun, Jiacheng Tao, Xingcheng Fu, and Jianxin Li. 2026. RAG-GFM: Overcoming In-Memory Bottlenecks in Graph Foundation Models via Retrieval-Augmented Generation.arXiv e-prints(2026), arXiv–2601
2026
-
[41]
Yifei Zhang, Hao Zhu, Menglin Yang, Jiahong Liu, Rex Ying, Irwin King, and Piotr Koniusz. 2025. Understanding and mitigating hyperbolic dimensional collapse in graph contrastive learning. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1. 1984–1995
2025
-
[42]
Haihong Zhao, Aochuan Chen, Xiangguo Sun, Hong Cheng, and Jia Li. 2024. All in one and one for all: A simple yet effective method towards cross-domain graph pretraining. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4443–4454
2024
-
[43]
Yun Zhu, Haizhou Shi, Xiaotang Wang, Yongchao Liu, Yaoke Wang, Boci Peng, Chuntao Hong, and Siliang Tang. 2025. GraphCLIP: Enhancing Transferability in Graph Foundation Models for Text-Attributed Graphs. InProceedings of the ACM on Web Conference 2025, WWW 2025, Sydney, NSW, Australia, 28 April 2025- 2 May 2025, Guodong Long, Michale Blumestein, Yi Chang,...
-
[44]
Yanqiao Zhu, Yichen Xu, Feng Yu, Qiang Liu, Shu Wu, and Liang Wang. 2020. Deep graph contrastive representation learning.arXiv preprint arXiv:2006.04131 (2020). Generalizing Graph Foundation Models via Hyperbolic Retrieval-Augmented Generation KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea A Datasets In this paper, we employ seven widely used...
arXiv 2020
-
[45]
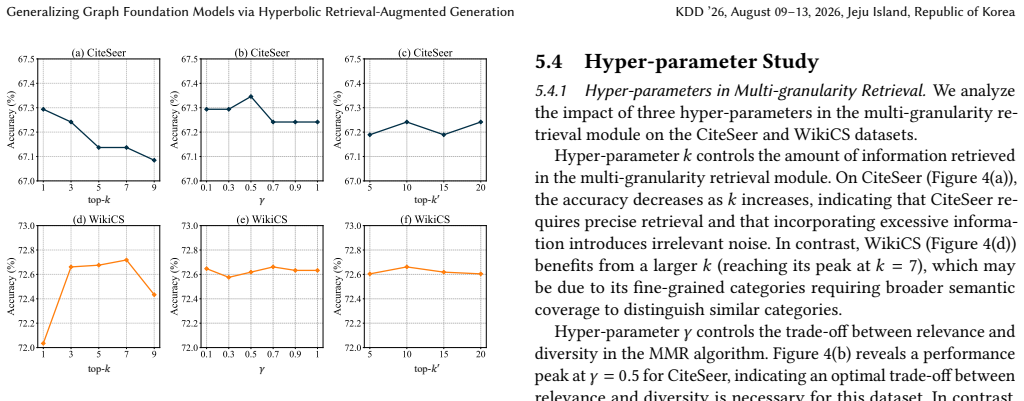
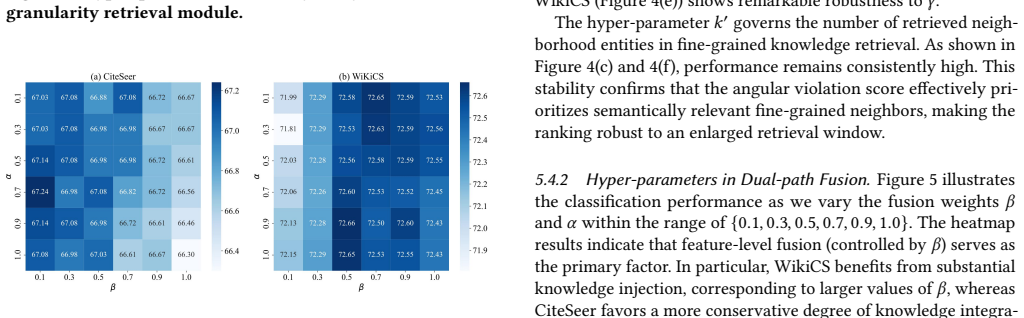
as the LLM to generate the corresponding coarse-grained and fine-grained queries. The number of retrieved central enti- ties 𝑘 is selected from {1, 3, 5, 7, 9}, the diversity factor 𝛾 is tuned within {0.1, 0.3, 0.5, 0.7, 0.9, 1}, and the number of retrieved neigh- borhood entities in fine-grained knowledge retrieval 𝑘 ′ is chosen from {5, 10, 15, 20}. Fin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.