FLIPS: Instance-Fingerprinting for LLMs via Pseudo-random Sequences
Pith reviewed 2026-06-28 11:21 UTC · model grok-4.3
The pith
Instance-level parameters create stable biases in LLMs' pseudo-random binary outputs that allow identification of specific configurations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
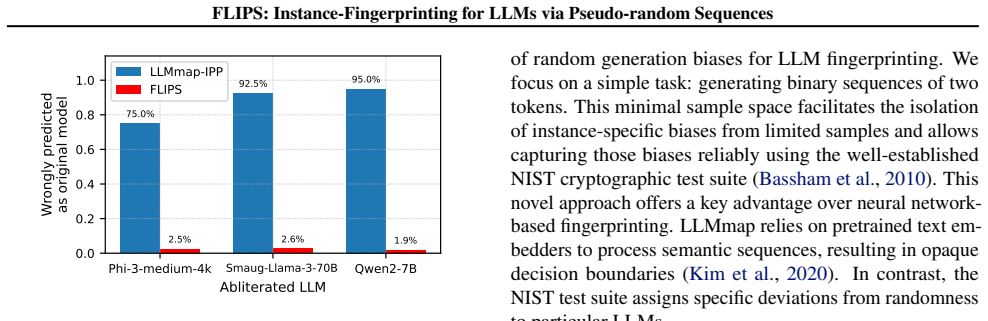
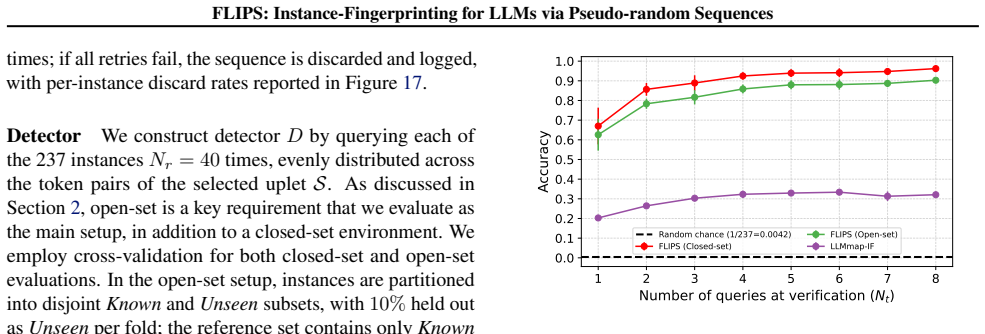
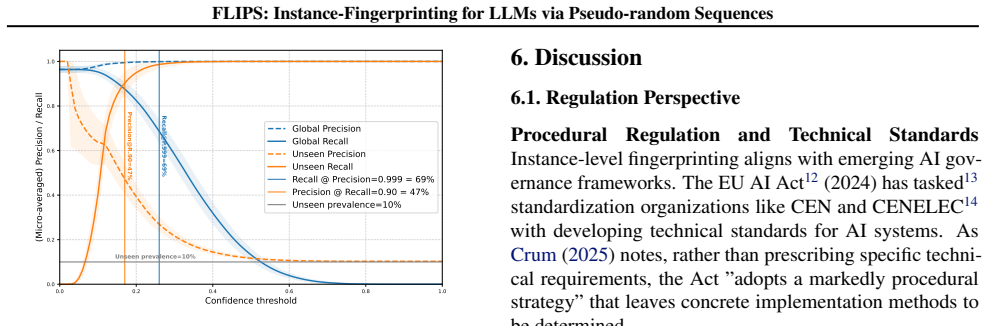
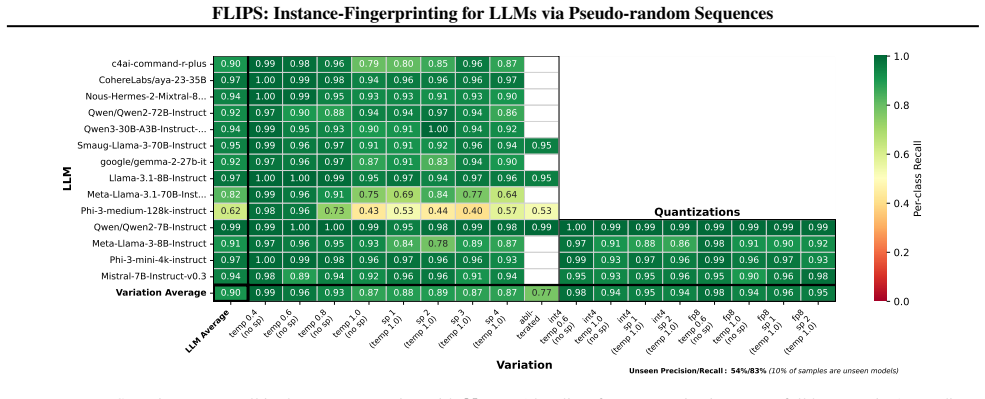
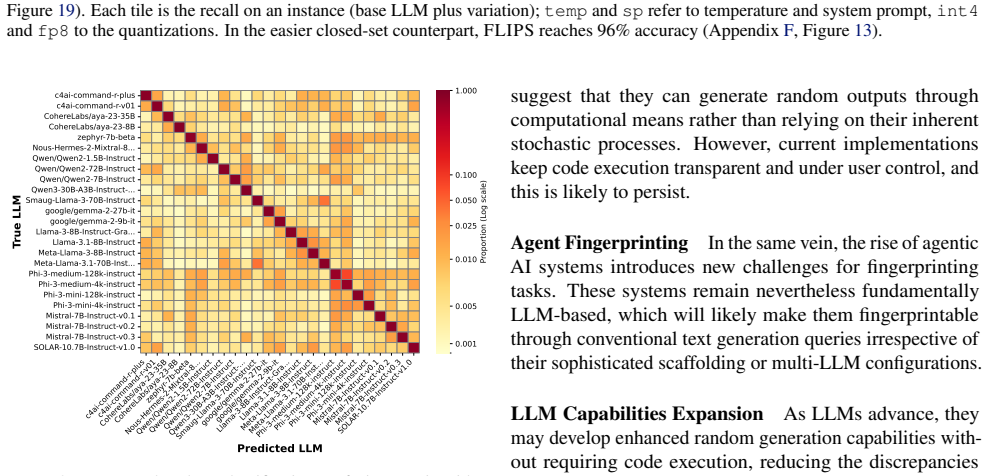
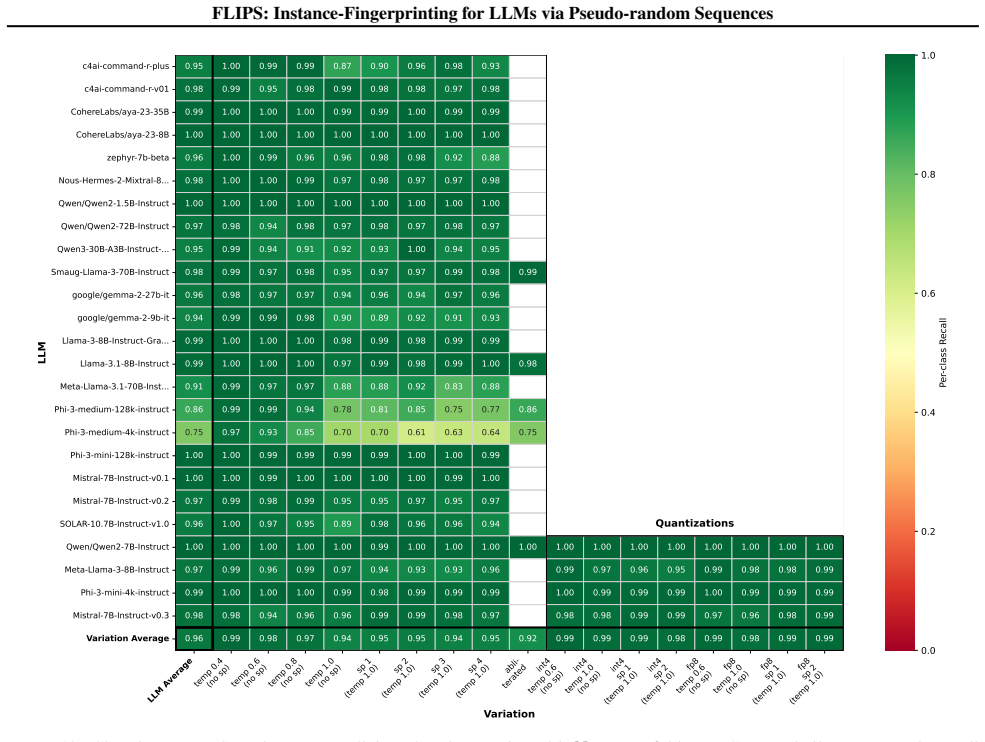
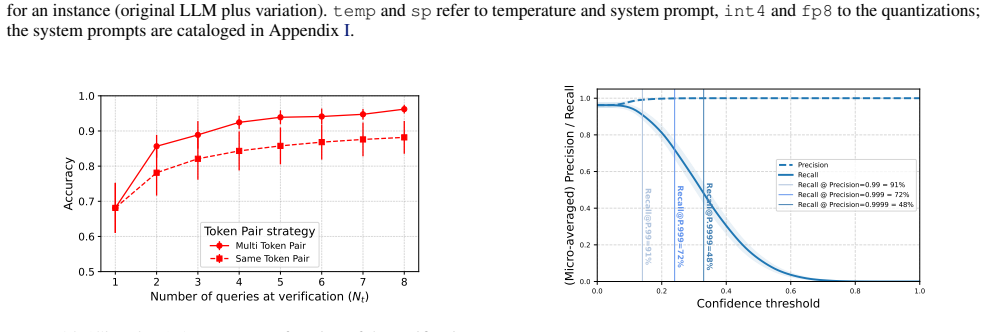
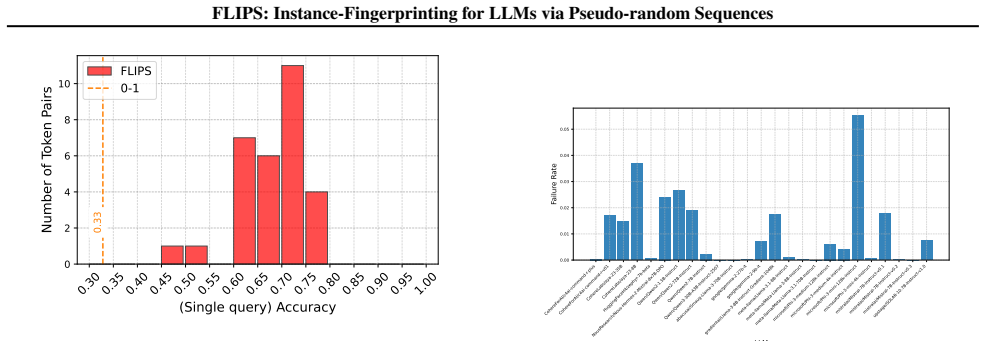
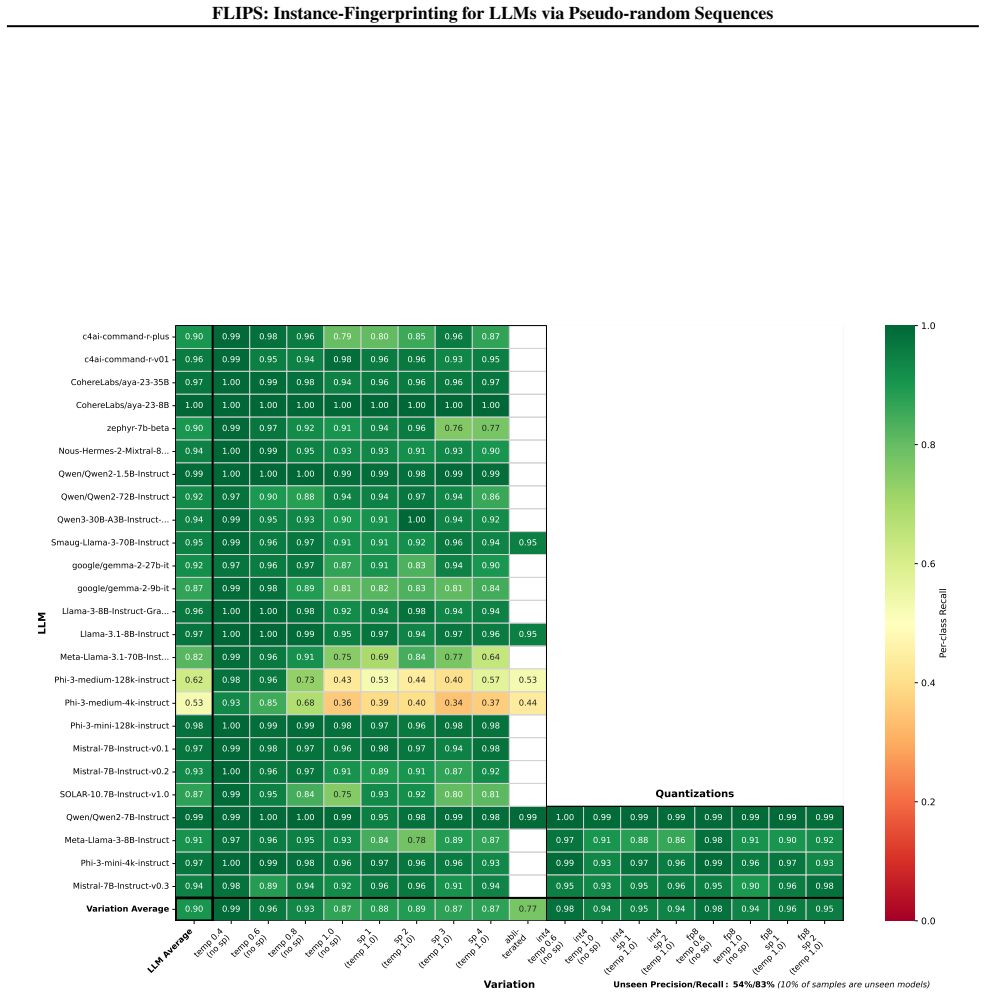
FLIPS exploits biases in generated binary random sequences to distinguish configurations of the same LLM, reaching 96 percent closed-set and 90 percent open-set identification accuracy across 237 model instances versus 35 percent for the adapted baseline. The work shows that instance-level fingerprinting is necessary for regulation and practically feasible.
What carries the argument
FLIPS, the method that identifies LLM instances by exploiting statistical biases in the pseudo-random binary sequences they generate under varying instance parameters.
If this is right
- Regulators can target actual deployed behaviors of LLMs rather than model provenance alone.
- Identification accuracy holds in open-set scenarios where some instances are unknown.
- The approach outperforms adapted existing techniques by a wide margin on hundreds of instances.
- Compliance checks can focus on specific configurations that may produce unsafe outputs under certain settings.
Where Pith is reading between the lines
- The same bias signals could be tested for persistence when models receive updates or additional fine-tuning after initial deployment.
- Combining sequence biases with other observable outputs might increase resistance to attempts to mask the fingerprint.
- Extending the queries beyond pure random-sequence generation to ordinary tasks would show whether the distinguishing patterns survive in typical use.
Load-bearing premise
Instance-level parameters produce stable, distinguishable statistical biases in pseudo-random binary sequences that are not erased by normal usage or prompt variation.
What would settle it
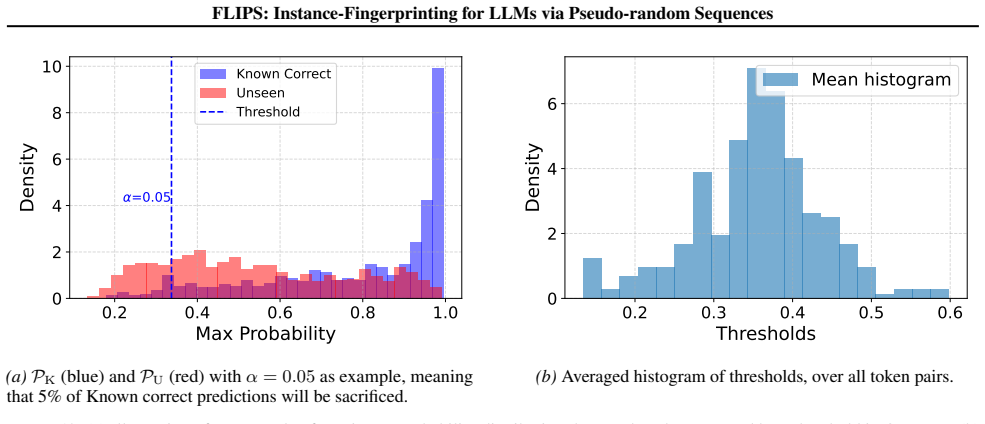
A test showing that different LLM instances produce statistically indistinguishable binary sequence biases, or that repeated queries to the same instance under varied prompts cause identification accuracy to fall below usable levels.
Figures

read the original abstract
Literature reveals that a Large Language Model's (LLM) behavior is not only conditioned by its original weights but also its instance-level parameters, such as instructional prompt, sampling configuration or quantization. A model that generates safe outputs under one configuration may produce toxic content under another. However, current LLM identification techniques (such as fingerprinting) focus on intellectual property protection, and their design favors robustness to changes in these instance-level parameters. This poses a critical challenge for AI regulation in which compliance assessments target actual deployed behaviors, not model provenance. In this paper, we introduce instance-level fingerprinting, a regulator-oriented paradigm that distinguishes configurations of the same LLM. Our method FLIPS, exploits biases in generated binary random sequences to reach 96% (closed-set) and 90% (open-set, where some targets are unknown) identification accuracy across 237 model instances, versus 35% for the adapted LLMmap baseline. This shows that instance-level fingerprinting is both necessary for regulation and practically feasible. Code available at https://github.com/GurvanR/FLIPS-LLM-Instance-Fingerprinting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FLIPS, a regulator-oriented instance-level fingerprinting method for LLMs that exploits statistical biases in pseudo-random binary sequences generated under different instance configurations (prompts, sampling, quantization). It reports 96% closed-set and 90% open-set identification accuracy across 237 model instances, substantially outperforming an adapted LLMmap baseline at 35%, and argues this enables compliance checks on deployed behaviors rather than model provenance alone.
Significance. If the reported accuracies prove robust, the work would be significant for AI regulation by demonstrating a practical, high-accuracy approach to distinguishing instance-specific behaviors that affect safety and compliance. The open-set result and code release are notable strengths that could support further development of falsifiable, regulator-usable fingerprints.
major comments (2)
- Abstract: the 90% open-set accuracy claim is load-bearing for the regulator-oriented contribution, yet the text supplies no quantitative results on bias stability under prompt rephrasing, continued interaction, or sampling variation; without such controls the accuracies may reflect fixed experimental conditions rather than persistent instance fingerprints.
- Abstract / Experiments section: the open-set protocol requires a rejection mechanism for unknown instances, but no description is given of the decision threshold, feature representation of the bit sequences, or how the 237-instance dataset was partitioned, preventing assessment of whether the 90% figure generalizes beyond the reported protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for robustness evidence and methodological transparency in the open-set results. We respond to each major comment below.
read point-by-point responses
-
Referee: Abstract: the 90% open-set accuracy claim is load-bearing for the regulator-oriented contribution, yet the text supplies no quantitative results on bias stability under prompt rephrasing, continued interaction, or sampling variation; without such controls the accuracies may reflect fixed experimental conditions rather than persistent instance fingerprints.
Authors: We agree that explicit stability quantification under prompt rephrasing and continued interaction would strengthen the regulatory claim. The current experiments already incorporate variation in sampling parameters (temperature, top-p) and multiple base prompts across the 237 instances, but dedicated ablations on paraphrased prompts and multi-turn settings are not reported. We will add these quantitative stability results as a new subsection in the revised experiments. revision: yes
-
Referee: Abstract / Experiments section: the open-set protocol requires a rejection mechanism for unknown instances, but no description is given of the decision threshold, feature representation of the bit sequences, or how the 237-instance dataset was partitioned, preventing assessment of whether the 90% figure generalizes beyond the reported protocol.
Authors: We acknowledge these details were omitted and agree they are required for evaluation. The feature representation is the vector of per-bit bias statistics extracted from the generated sequences; the rejection threshold is selected via validation-set cross-validation to control false-positive rate on unknowns; and the 237 instances were partitioned 70/30 for training/testing with a disjoint subset of instances held out entirely as unknowns. We will insert a dedicated paragraph describing the full open-set protocol, threshold selection, and partitioning in the revised experiments section. revision: yes
Circularity Check
No circularity: empirical accuracies measured against external baseline
full rationale
The paper presents FLIPS as an empirical fingerprinting method that generates pseudo-random binary sequences from LLM instances and measures identification accuracy (96% closed-set, 90% open-set) across 237 configurations against an adapted LLMmap baseline (35%). No equations, parameters, or claims are shown to reduce the reported accuracies to fitted inputs, self-definitions, or self-citation chains by construction. The derivation consists of experimental measurements of statistical biases rather than any mathematical or definitional loop. This is the normal case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2309.07875 , year=
Safety-tuned llamas: Lessons from improving the safety of large language models that follow instructions , author=. arXiv preprint arXiv:2309.07875 , year=
-
[2]
arXiv preprint arXiv:2508.19843 , year=
Sok: Large language model copyright auditing via fingerprinting , author=. arXiv preprint arXiv:2508.19843 , year=
-
[3]
International workshop on digital watermarking , pages=
Watermarking is not cryptography , author=. International workshop on digital watermarking , pages=. 2006 , organization=
2006
-
[4]
2001 IEEE Fourth Workshop on Multimedia Signal Processing (Cat
Considerations on watermarking security , author=. 2001 IEEE Fourth Workshop on Multimedia Signal Processing (Cat. No. 01TH8564) , pages=. 2001 , organization=
2001
-
[5]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Fingerprinting deep neural networks globally via universal adversarial perturbations , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[6]
Proceedings of the 2021 ACM asia conference on computer and communications security , pages=
IPGuard: Protecting intellectual property of deep neural networks via fingerprinting the classification boundary , author=. Proceedings of the 2021 ACM asia conference on computer and communications security , pages=
2021
-
[7]
Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining , pages=
Metav: A meta-verifier approach to task-agnostic model fingerprinting , author=. Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[8]
IEEE Transactions on Information Forensics and Security , volume=
Fingerprinting classifiers with benign inputs , author=. IEEE Transactions on Information Forensics and Security , volume=. 2023 , publisher=
2023
-
[9]
2025 , eprint=
LLMmap: Fingerprinting For Large Language Models , author=. 2025 , eprint=
2025
-
[10]
arXiv preprint arXiv:2508.09021 , year=
Attacks and defenses against llm fingerprinting , author=. arXiv preprint arXiv:2508.09021 , year=
-
[11]
arXiv preprint arXiv:2505.16530 , year=
DuFFin: A Dual-Level Fingerprinting Framework for LLMs IP Protection , author=. arXiv preprint arXiv:2505.16530 , year=
-
[12]
arXiv preprint arXiv:2410.20247 , year=
Model Equality Testing: Which Model Is This API Serving? , author=. arXiv preprint arXiv:2410.20247 , year=
-
[13]
Auditing Black-Box LLM APIs with a Rank-Based Uniformity Test
Auditing Black-Box LLM APIs with a Rank-Based Uniformity Test , author=. arXiv preprint arXiv:2506.06975 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
arXiv preprint arXiv:2402.12991 , year=
Trap: Targeted random adversarial prompt honeypot for black-box identification , author=. arXiv preprint arXiv:2402.12991 , year=
-
[15]
2024 IEEE Conference on Communications and Network Security (CNS) , pages=
Proflingo: A fingerprinting-based intellectual property protection scheme for large language models , author=. 2024 IEEE Conference on Communications and Network Security (CNS) , pages=. 2024 , organization=
2024
-
[16]
arXiv preprint arXiv:2505.12682 , year=
RoFL: Robust Fingerprinting of Language Models , author=. arXiv preprint arXiv:2505.12682 , year=
-
[17]
SRAF: Stealthy and Robust Adversarial Fingerprint for Copyright Verification of Large Language Models , author=. arXiv preprint arXiv:2505.06304 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Proceedings of the 1stWorkshop on GenAI Content Detection (GenAIDetect) , pages=
Your large language models are leaving fingerprints , author=. Proceedings of the 1stWorkshop on GenAI Content Detection (GenAIDetect) , pages=
-
[19]
arXiv preprint arXiv:2407.01235 , year=
A fingerprint for large language models , author=. arXiv preprint arXiv:2407.01235 , year=
-
[20]
arXiv preprint arXiv:2505.16785 , year=
CoTSRF: Utilize Chain of Thought as Stealthy and Robust Fingerprint of Large Language Models , author=. arXiv preprint arXiv:2505.16785 , year=
-
[21]
arXiv preprint arXiv:2306.05540 , year=
Detectllm: Leveraging log rank information for zero-shot detection of machine-generated text , author=. arXiv preprint arXiv:2306.05540 , year=
-
[22]
International conference on machine learning , pages=
Detectgpt: Zero-shot machine-generated text detection using probability curvature , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[23]
Spotting llms with binoculars: Zero-shot detection of machine-generated text , author=. arXiv preprint arXiv:2401.12070 , year=
-
[24]
Fast-detectgpt: Efficient zero-shot detection of machine-generated text via conditional probability curvature , author=. arXiv preprint arXiv:2310.05130 , year=
-
[25]
Intrinsic Fingerprint of LLMs: Continue Training is NOT All You Need to Steal A Model!
Intrinsic Fingerprint of LLMs: Continue Training is NOT All You Need to Steal A Model! , author=. arXiv preprint arXiv:2507.03014 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Reef: Representation encoding fingerprints for large language models , author=. arXiv preprint arXiv:2410.14273 , year=
-
[27]
Advances in Neural Information Processing Systems , volume=
WaterMax: breaking the LLM watermark detectability-robustness-quality trade-off , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
International Conference on Machine Learning , pages=
A watermark for large language models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[29]
arXiv preprint arXiv:2502.07760 , year=
Scalable fingerprinting of large language models , author=. arXiv preprint arXiv:2502.07760 , year=
-
[30]
Hey, That's My Model! Introducing Chain & Hash, An LLM Fingerprinting Technique
Hey, That's My Model! Introducing Chain & Hash, An LLM Fingerprinting Technique , author=. arXiv preprint arXiv:2407.10887 , year=
work page internal anchor Pith review arXiv
-
[31]
arXiv preprint arXiv:2401.12255 , year=
Instructional fingerprinting of large language models , author=. arXiv preprint arXiv:2401.12255 , year=
-
[32]
arXiv preprint arXiv:2505.16723 , year=
Robust LLM Fingerprinting via Domain-Specific Watermarks , author=. arXiv preprint arXiv:2505.16723 , year=
-
[33]
Scientific reports , volume=
A cognitive fingerprint in human random number generation , author=. Scientific reports , volume=. 2021 , publisher=
2021
-
[34]
2023 , organization=
Can llms generate random numbers? evaluating llm sampling in controlled domains , author=. 2023 , organization=
2023
-
[35]
arXiv preprint arXiv:2408.09656 , year=
A Comparison of Large Language Model and Human Performance on Random Number Generation Tasks , author=. arXiv preprint arXiv:2408.09656 , year=
-
[36]
Deterministic or probabilistic? the psychology of llms as random number generators, 2025
Deterministic or probabilistic? The psychology of LLMs as random number generators , author=. arXiv preprint arXiv:2502.19965 , year=
-
[37]
How random is random? evaluating the random- ness and humaness of llms’ coin flips, 2024
How Random is Random? Evaluating the Randomness and Humaness of LLMs' Coin Flips , author=. arXiv preprint arXiv:2406.00092 , year=
-
[38]
Applied Network Science , year=
LLMs prompted for graphs: hallucinations and generative capabilities , author=. Applied Network Science , year=
-
[39]
arXiv preprint arXiv:2502.00873 , year=
Language models use trigonometry to do addition , author=. arXiv preprint arXiv:2502.00873 , year=
-
[40]
Neural Networks , volume=
Arithmetic with language models: From memorization to computation , author=. Neural Networks , volume=. 2024 , publisher=
2024
-
[41]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Queries, Representation & Detection: The Next 100 Model Fingerprinting Schemes , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[42]
ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Model fingerprinting with benign inputs , author=. ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2023 , organization=
2023
-
[43]
Decision Support Systems , volume=
Transparency and accountability in AI decision support: Explaining and visualizing convolutional neural networks for text information , author=. Decision Support Systems , volume=. 2020 , publisher=
2020
-
[44]
arXiv preprint arXiv:2505.04796 , year=
Robust ML Auditing using Prior Knowledge , author=. arXiv preprint arXiv:2505.04796 , year=
-
[45]
AI , volume=
Local ai governance: Addressing model safety and policy challenges posed by decentralized ai , author=. AI , volume=. 2025 , publisher=
2025
-
[46]
Non-determinism of" deterministic" llm settings , author=. arXiv preprint arXiv:2408.04667 , year=
-
[47]
2010 , number=
A statistical test suite for random and pseudorandom number generators for cryptographic applications , author=. 2010 , number=
2010
-
[48]
Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining , pages=
Xgboost: A scalable tree boosting system , author=. Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining , pages=
-
[49]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[50]
Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , pages=
Position is Power: System Prompts as a Mechanism of Bias in Large Language Models (LLMs) , author=. Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , pages=
2025
-
[51]
Advances in Neural Information Processing Systems , volume=
Sg-bench: Evaluating llm safety generalization across diverse tasks and prompt types , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
arXiv preprint arXiv:2405.20947 , year =
Or-bench: An over-refusal benchmark for large language models , author=. arXiv preprint arXiv:2405.20947 , year=
-
[53]
arXiv preprint arXiv:2502.05234 , year=
Optimizing temperature for language models with multi-sample inference , author=. arXiv preprint arXiv:2502.05234 , year=
-
[54]
arXiv preprint arXiv:2502.18389 , year=
Monte Carlo Temperature: a robust sampling strategy for LLM's uncertainty quantification methods , author=. arXiv preprint arXiv:2502.18389 , year=
-
[55]
Forty-second International Conference on Machine Learning , year=
Assessing Safety Risks and Quantization-aware Safety Patching for Quantized Large Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[56]
arXiv preprint arXiv:2411.06835 , year=
Harmlevelbench: Evaluating harm-level compliance and the impact of quantization on model alignment , author=. arXiv preprint arXiv:2411.06835 , year=
-
[57]
arXiv preprint arXiv:2407.03211 , year=
How does quantization affect multilingual LLMs? , author=. arXiv preprint arXiv:2407.03211 , year=
-
[58]
arXiv preprint arXiv:2502.15799 , year=
Investigating the impact of quantization methods on the safety and reliability of large language models , author=. arXiv preprint arXiv:2502.15799 , year=
-
[59]
arXiv preprint arXiv:2508.18088 , year=
How Quantization Shapes Bias in Large Language Models , author=. arXiv preprint arXiv:2508.18088 , year=
-
[60]
How benchmark prediction from fewer data misses the mark.arXiv preprint arXiv:2506.07673, 2025
How Benchmark Prediction from Fewer Data Misses the Mark , author=. arXiv preprint arXiv:2506.07673 , year=
-
[61]
2025 , eprint=
A Systematic Survey of Model Extraction Attacks and Defenses: State-of-the-Art and Perspectives , author=. 2025 , eprint=
2025
-
[62]
13th International Conference on Learning Representations, ICLR 2025 , pages=
CAN WATERMARKS BE USED TO DETECT LARGE LANGUAGE MODEL INTELLECTUAL PROPERTY INFRINGEMENT FOR FREE? , author=. 13th International Conference on Learning Representations, ICLR 2025 , pages=. 2025 , organization=
2025
-
[63]
Advances in Neural Information Processing Systems , volume=
Refusal in language models is mediated by a single direction , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
arXiv preprint arXiv:2407.14981 , year=
Open problems in technical ai governance , author=. arXiv preprint arXiv:2407.14981 , year=
-
[65]
Internet Policy Review , volume=
The European approach to regulating AI through technical standards , author=. Internet Policy Review , volume=. 2024 , publisher=
2024
-
[66]
Internet Policy Review , volume=
Brussels effect or experimentalism? The EU AI Act and global standard-setting , author=. Internet Policy Review , volume=. 2025 , publisher=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.