Local Guidance, Global Impact: Gaussian-Reshaped Trust Region Unlocks Behavior Transitions
Pith reviewed 2026-06-28 10:48 UTC · model grok-4.3
The pith
By reshaping the trust region with a Gaussian kernel, GTR creates a non-monotonic constraint that supports behavior transitions in non-stationary RL environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
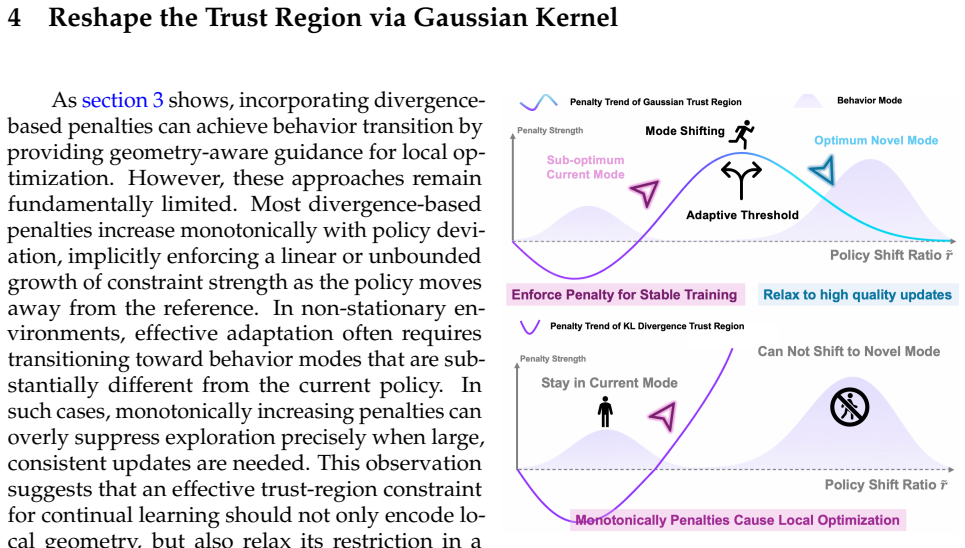
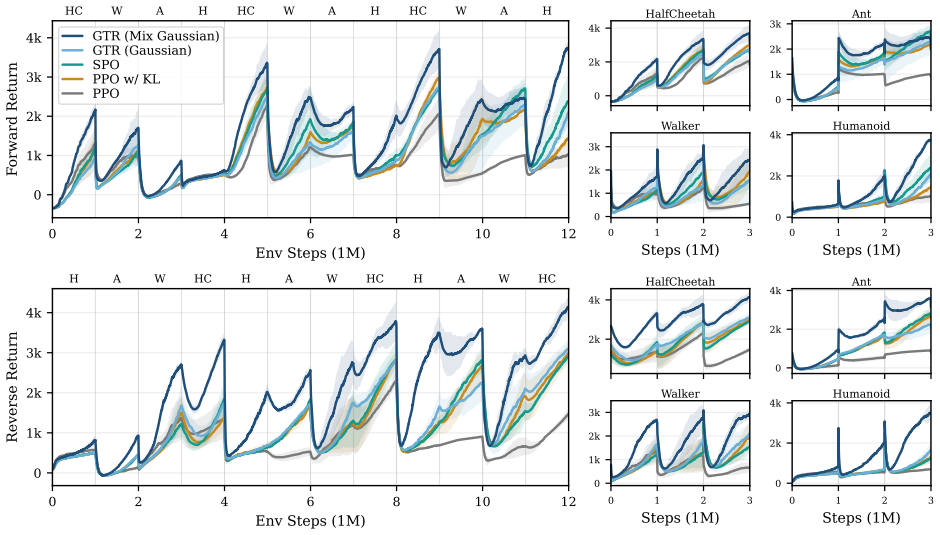
Gaussian Trust Region Policy Optimization (GTR) reshapes the trust region using a Gaussian kernel to produce a bounded and non-monotonic constraint that provides strong local stability while progressively relaxing under sustained high-advantage updates, unlocking behavior transitions. To further improve robustness, a Mixture Gaussian Anchor adapts to recent policy trajectories, reducing variance induced by stale references. GTR is architecture-agnostic and achieves strong performance across games, simulated robotic control, open-world exploration, and language model post-training.
What carries the argument
Gaussian kernel reshaping of the trust region to create a bounded non-monotonic constraint
If this is right
- Unlocks transitions toward new behavior patterns in continual and non-stationary environments
- Provides strong local stability alongside the ability to make large policy deviations when necessary
- Reduces variance from stale references via the Mixture Gaussian Anchor
- Delivers strong performance across multiple domains including robotic control and language model post-training
Where Pith is reading between the lines
- The non-monotonic design could inspire similar constraints in other optimization algorithms facing shifting objectives
- In practice, this might allow RL agents to handle real-world scenarios with gradual or abrupt changes more reliably
- Testing on longer time horizons could reveal how the relaxation accumulates over extended periods
Load-bearing premise
The non-monotonic relaxation property of the Gaussian kernel will reliably accumulate meaningful behavioral change without introducing instability or requiring extensive per-environment tuning of the kernel parameters.
What would settle it
An experiment showing that GTR performs no better than PPO in non-stationary environments, or that performance degrades due to instability from the relaxation, would falsify the central claim.
Figures


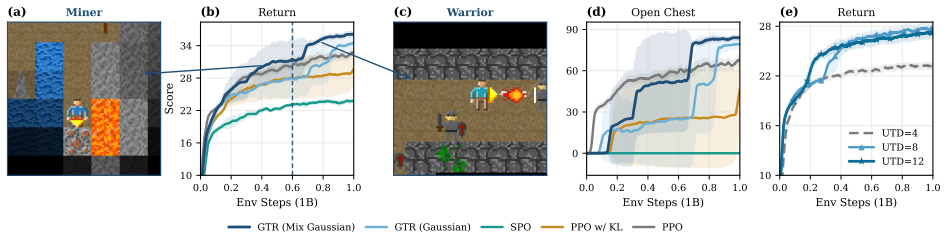
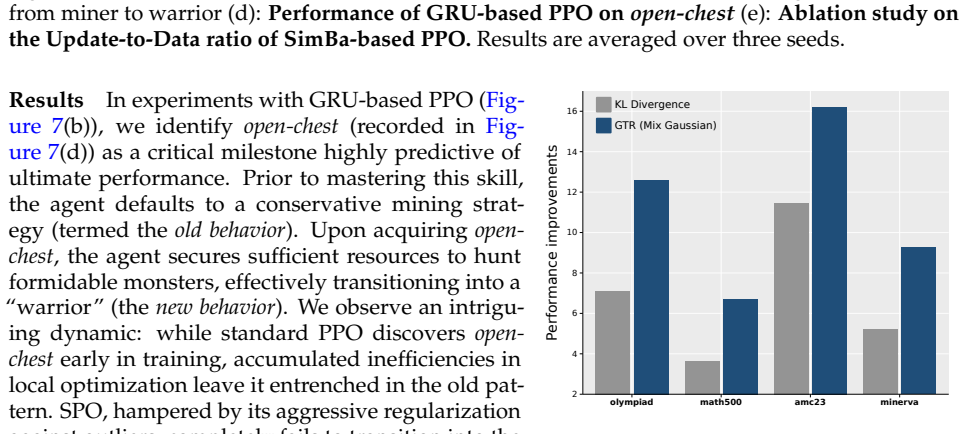
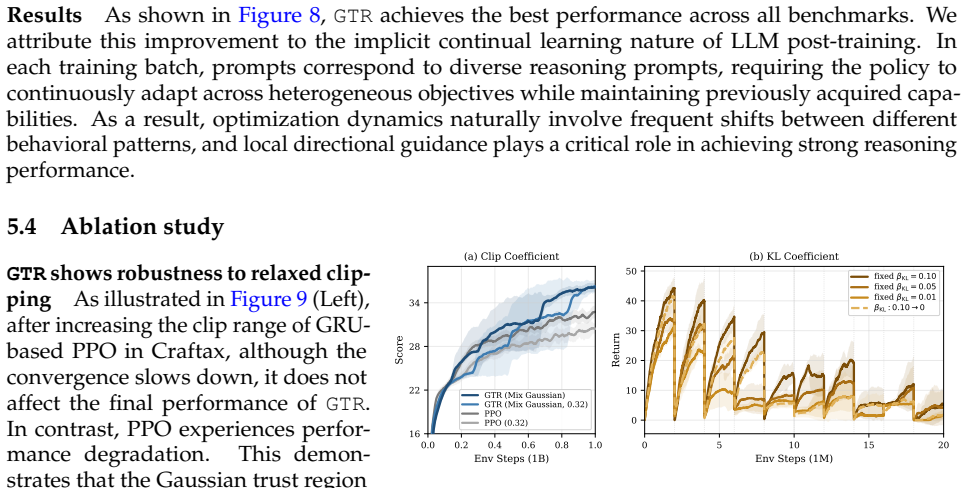
read the original abstract
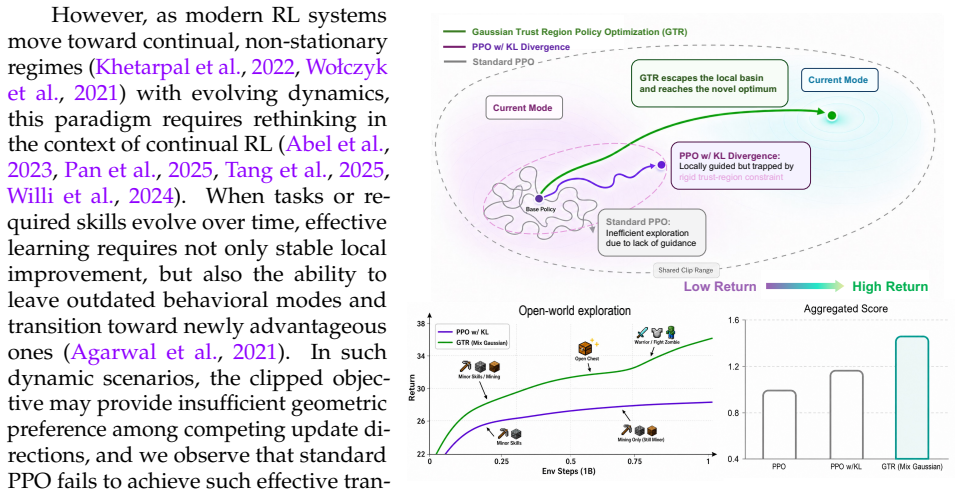
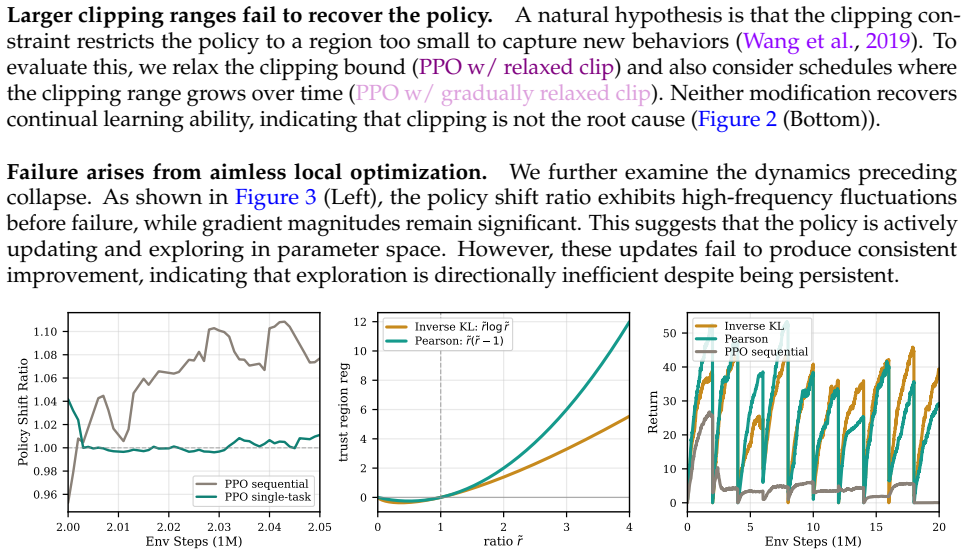
While Proximal Policy Optimization (PPO) demonstrates strong performance in stationary settings, we show that its standard optimization paradigm struggles in continual and non-stationary environments. The failure does not stem from insufficient model capacity or overly restrictive clipping. Instead, PPO performs persistent, directionally inefficient local updates, which indicates a lack of geometry-aware guidance for accumulating meaningful behavioral change and ultimately hindering transitions toward new behavior patterns. Although divergence-based regularization introduces partial geometric awareness, its monotonically increasing penalties implicitly discourage large policy deviations, even when such shifts are necessary for effective adaptation. To address this limitation, we propose Gaussian Trust Region Policy Optimization (GTR), which reshapes the trust region using a Gaussian kernel. The resulting constraint is bounded and non-monotonic, providing strong local stability while progressively relaxing under sustained high-advantage updates. To further improve robustness, we introduce a Mixture Gaussian Anchor that adapts to recent policy trajectories, reducing variance induced by stale references. GTR is architecture-agnostic and achieves strong performance across games, simulated robotic control, open-world exploration, and language model post-training. These results demonstrate that geometry-aware trust-region design can be a promising direction for robust reinforcement learning in complex non-stationary environments. Our code is available at https://anonymous.4open.science/r/GTR_demo/README.md.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that PPO's standard clipping produces persistent, directionally inefficient local updates in non-stationary environments because it lacks geometry-aware guidance and because divergence penalties are monotonically increasing. It proposes Gaussian Trust Region Policy Optimization (GTR), which reshapes the trust region via a Gaussian kernel to yield a bounded, non-monotonic constraint that supplies local stability yet progressively relaxes under sustained high-advantage updates; a Mixture Gaussian Anchor is added to adapt to recent trajectories and reduce variance from stale references. The method is stated to be architecture-agnostic and to deliver strong empirical performance across games, robotic control, open-world exploration, and language-model post-training.
Significance. If the non-monotonic relaxation property can be shown to accumulate stable behavioral change without excessive sensitivity to advantage noise or kernel hyperparameters, the work would offer a concrete geometric alternative to monotonic trust-region penalties and could influence continual-RL algorithm design. The architecture-agnostic framing and public code release are positive attributes that would facilitate follow-up work.
major comments (2)
- [Abstract] Abstract: the central claim that the Gaussian kernel produces a 'bounded and non-monotonic' constraint that 'progressively relaxes under sustained high-advantage updates' is load-bearing for the entire contribution, yet the manuscript provides neither the explicit functional form of the kernel nor the operational definition of 'sustained,' preventing verification that relaxation occurs only on true advantage rather than on noisy estimates.
- [Abstract] Abstract (and implied methods): the paper lists Gaussian kernel width and shape parameters as free parameters and introduces a Mixture Gaussian Anchor with its own mixture parameters, but supplies no analysis or ablation demonstrating that performance remains stable across environments without per-task retuning; this directly bears on the claim of robustness in non-stationary settings.
minor comments (1)
- The abstract states that 'our code is available at https://anonymous.4open.science/r/GTR_demo/README.md' but does not indicate whether the repository contains the exact hyper-parameter settings used in the reported experiments.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the Gaussian kernel produces a 'bounded and non-monotonic' constraint that 'progressively relaxes under sustained high-advantage updates' is load-bearing for the entire contribution, yet the manuscript provides neither the explicit functional form of the kernel nor the operational definition of 'sustained,' preventing verification that relaxation occurs only on true advantage rather than on noisy estimates.
Authors: We agree that the abstract would benefit from greater precision. The full manuscript provides the Gaussian kernel form in Equation (3) of Section 3.1 and defines 'sustained' in the surrounding text and Algorithm 1 as consecutive updates where the advantage remains above a positive threshold. We will revise the abstract to include a concise reference to the kernel equation and the operational definition of sustained updates. revision: yes
-
Referee: [Abstract] Abstract (and implied methods): the paper lists Gaussian kernel width and shape parameters as free parameters and introduces a Mixture Gaussian Anchor with its own mixture parameters, but supplies no analysis or ablation demonstrating that performance remains stable across environments without per-task retuning; this directly bears on the claim of robustness in non-stationary settings.
Authors: The referee is correct that the current manuscript does not include a dedicated ablation or sensitivity analysis demonstrating stability without per-task retuning. We will add such an analysis (including cross-environment results for kernel width, shape, and mixture parameters) to the revised version to better support the robustness claim. revision: yes
Circularity Check
No circularity: independent algorithmic proposal with no self-referential reductions
full rationale
The paper introduces GTR as a novel trust-region reshaping via Gaussian kernel, presented as an explicit design choice to achieve bounded non-monotonic constraints. The abstract and provided text contain no equations, fitted parameters, or self-citations that reduce the central claim (geometry-aware relaxation unlocking transitions) to a tautology or prior result by the same authors. The derivation chain consists of problem diagnosis followed by an independent algorithmic modification, with no load-bearing steps that equate outputs to inputs by construction. This is the expected non-circular case for a methods paper proposing a new regularizer.
Axiom & Free-Parameter Ledger
free parameters (1)
- Gaussian kernel width and shape parameters
axioms (1)
- domain assumption Policy gradient methods remain valid when the trust region constraint is replaced by a non-monotonic Gaussian kernel.
invented entities (1)
-
Mixture Gaussian Anchor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
1998 , publisher=
Reinforcement learning: An introduction , author=. 1998 , publisher=
1998
-
[3]
Proceedings of the nineteenth international conference on machine learning , pages=
Approximately optimal approximate reinforcement learning , author=. Proceedings of the nineteenth international conference on machine learning , pages=
-
[4]
Finding the Frame: An RLC Workshop for Examining Conceptual Frameworks , year=
Pick up the PACE: A Parameter-Free Optimizer for Lifelong Reinforcement Learning , author=. Finding the Frame: An RLC Workshop for Examining Conceptual Frameworks , year=
-
[5]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Addressing action oscillations through learning policy inertia , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[6]
International conference on machine learning , pages=
Trust region policy optimization , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[7]
arXiv preprint arXiv:2512.21852 , year=
A Comedy of Estimators: On KL Regularization in RL Training of LLMs , author=. arXiv preprint arXiv:2512.21852 , year=
-
[8]
arXiv preprint arXiv:2401.16025 , year=
Simple policy optimization , author=. arXiv preprint arXiv:2401.16025 , year=
-
[9]
nature , volume=
Human-level control through deep reinforcement learning , author=. nature , volume=. 2015 , publisher=
2015
-
[10]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
Empirical evaluation of gated recurrent neural networks on sequence modeling , author=. arXiv preprint arXiv:1412.3555 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[12]
2012 IEEE/RSJ international conference on intelligent robots and systems , pages=
Mujoco: A physics engine for model-based control , author=. 2012 IEEE/RSJ international conference on intelligent robots and systems , pages=. 2012 , organization=
2012
-
[13]
Deepmind control suite , author=. arXiv preprint arXiv:1801.00690 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
International conference on machine learning , pages=
Leveraging procedural generation to benchmark reinforcement learning , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[15]
Advances in neural information processing systems , volume=
On warm-starting neural network training , author=. Advances in neural information processing systems , volume=
-
[16]
Advances in neural information processing systems , volume=
A natural policy gradient , author=. Advances in neural information processing systems , volume=
-
[17]
Neural computation , volume=
Natural gradient works efficiently in learning , author=. Neural computation , volume=. 1998 , publisher=
1998
-
[18]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Advances in Neural Information Processing Systems , volume=
Continual world: A robotic benchmark for continual reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Advances in Neural Information Processing Systems , volume=
A definition of continual reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
A Survey of Continual Reinforcement Learning
A survey of continual reinforcement learning , author=. arXiv preprint arXiv:2506.21872 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
arXiv preprint arXiv:2507.09177 , year=
Continual reinforcement learning by planning with online world models , author=. arXiv preprint arXiv:2507.09177 , year=
-
[23]
Conference on lifelong learning agents , pages=
Loss of plasticity in continual deep reinforcement learning , author=. Conference on lifelong learning agents , pages=. 2023 , organization=
2023
-
[24]
Proceedings of the Twentieth European Conference on Computer Systems , pages=
Hybridflow: A flexible and efficient rlhf framework , author=. Proceedings of the Twentieth European Conference on Computer Systems , pages=
-
[25]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Lipschitz lifelong reinforcement learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[26]
Advances in Neural Information Processing Systems , volume=
Trust region-guided proximal policy optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
arXiv preprint arXiv:2512.06547 , year=
A-3PO: Accelerating Asynchronous LLM Training with Staleness-aware Proximal Policy Approximation , author=. arXiv preprint arXiv:2512.06547 , year=
-
[28]
arXiv preprint arXiv:2406.03894 , year=
Transductive off-policy proximal policy optimization , author=. arXiv preprint arXiv:2406.03894 , year=
-
[29]
Advances in Neural Information Processing Systems , volume=
Batch size-invariance for policy optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
Journal of Machine Learning Research , volume=
New insights and perspectives on the natural gradient method , author=. Journal of Machine Learning Research , volume=
-
[31]
Machine Learning , volume=
Compatible natural gradient policy search , author=. Machine Learning , volume=. 2019 , publisher=
2019
-
[32]
Revisiting Natural Gradient for Deep Networks
Revisiting natural gradient for deep networks , author=. arXiv preprint arXiv:1301.3584 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Layer normalization , author=. arXiv preprint arXiv:1607.06450 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
The twelfth international conference on learning representations , year=
Let's verify step by step , author=. The twelfth international conference on learning representations , year=
-
[36]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[37]
Advances in neural information processing systems , volume=
Solving quantitative reasoning problems with language models , author=. Advances in neural information processing systems , volume=
-
[38]
arXiv preprint arXiv:2509.02479 , year=
Simpletir: End-to-end reinforcement learning for multi-turn tool-integrated reasoning , author=. arXiv preprint arXiv:2509.02479 , year=
-
[39]
International Conference on Machine Learning , pages=
Phasic policy gradient , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[40]
Machine learning , volume=
Q-learning , author=. Machine learning , volume=. 1992 , publisher=
1992
-
[41]
Proceedings of the national academy of sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the national academy of sciences , volume=. 2017 , publisher=
2017
-
[42]
Proceedings of the IEEE conference on Computer Vision and Pattern Recognition , pages=
Packnet: Adding multiple tasks to a single network by iterative pruning , author=. Proceedings of the IEEE conference on Computer Vision and Pattern Recognition , pages=
-
[43]
Nature , volume=
Loss of plasticity in deep continual learning , author=. Nature , volume=. 2024 , publisher=
2024
-
[44]
International Conference on Machine Learning , pages=
Understanding plasticity in neural networks , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[45]
arXiv preprint arXiv:2402.18762 , year=
Disentangling the causes of plasticity loss in neural networks , author=. arXiv preprint arXiv:2402.18762 , year=
-
[46]
Advances in Neural Information Processing Systems , volume=
Normalization and effective learning rates in reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
International Conference on Machine Learning , pages=
The dormant neuron phenomenon in deep reinforcement learning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[48]
arXiv preprint arXiv:2506.09477 , year=
On a few pitfalls in kl divergence gradient estimation for rl , author=. arXiv preprint arXiv:2506.09477 , year=
-
[49]
Proceedings of the AAAI conference on artificial intelligence , volume=
The value-improvement path: Towards better representations for reinforcement learning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[50]
Science robotics , volume=
Learning agile and dynamic motor skills for legged robots , author=. Science robotics , volume=. 2019 , publisher=
2019
-
[51]
Solving Rubik's Cube with a Robot Hand
Solving rubik's cube with a robot hand , author=. arXiv preprint arXiv:1910.07113 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[52]
Dota 2 with Large Scale Deep Reinforcement Learning
Dota 2 with large scale deep reinforcement learning , author=. arXiv preprint arXiv:1912.06680 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[53]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[54]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[55]
Journal of Artificial Intelligence Research , volume=
Towards continual reinforcement learning: A review and perspectives , author=. Journal of Artificial Intelligence Research , volume=
-
[56]
Reinforcement Learning Conference , year=
Weight Clipping for Deep Continual and Reinforcement Learning , author=. Reinforcement Learning Conference , year=
-
[57]
The Thirteenth International Conference on Learning Representations , year=
Neuroplastic Expansion in Deep Reinforcement Learning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[58]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Measure gradients, not activations! Enhancing neuronal activity in deep reinforcement learning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[59]
Forty-second International Conference on Machine Learning , year=
The Impact of On-Policy Parallelized Data Collection on Deep Reinforcement Learning Networks , author=. Forty-second International Conference on Machine Learning , year=
-
[60]
Forty-first International Conference on Machine Learning , year=
Overestimation, Overfitting, and Plasticity in Actor-Critic: the Bitter Lesson of Reinforcement Learning , author=. Forty-first International Conference on Machine Learning , year=
-
[61]
Simplicial Embeddings Improve Sample Efficiency in Actor
Johan Obando-Ceron and Walter Mayor and Samuel Lavoie and Scott Fujimoto and Aaron Courville and Pablo Samuel Castro , booktitle=. Simplicial Embeddings Improve Sample Efficiency in Actor. 2026 , url=
2026
-
[62]
Mixture of Experts in a Mixture of
Timon Willi and Johan Samir Obando Ceron and Jakob Nicolaus Foerster and Gintare Karolina Dziugaite and Pablo Samuel Castro , booktitle=. Mixture of Experts in a Mixture of. 2024 , url=
2024
-
[63]
Forty-second International Conference on Machine Learning , year=
Mitigating Plasticity Loss in Continual Reinforcement Learning by Reducing Churn , author=. Forty-second International Conference on Machine Learning , year=
-
[64]
Meta-World+: An Improved, Standardized,
Reginald McLean and Evangelos Chatzaroulas and Luc McCutcheon and Frank R. Meta-World+: An Improved, Standardized,. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[65]
Forty-first International Conference on Machine Learning , year=
Craftax: A Lightning-Fast Benchmark for Open-Ended Reinforcement Learning , author=. Forty-first International Conference on Machine Learning , year=
-
[66]
The Thirteenth International Conference on Learning Representations , year=
SimBa: Simplicity Bias for Scaling Up Parameters in Deep Reinforcement Learning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[67]
International conference on machine learning , pages=
The primacy bias in deep reinforcement learning , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[68]
Journal of Machine Learning Research , volume=
On the theory of policy gradient methods: Optimality, approximation, and distribution shift , author=. Journal of Machine Learning Research , volume=
-
[69]
Advances in neural information processing systems , volume=
f-gan: Training generative neural samplers using variational divergence minimization , author=. Advances in neural information processing systems , volume=
-
[70]
Residual policy learning , author=. arXiv preprint arXiv:1812.06298 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
International Conference on Machine Learning , pages=
Efficient online reinforcement learning with offline data , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[72]
2008 , publisher=
Stochastic approximation: a dynamical systems viewpoint , author=. 2008 , publisher=
2008
-
[73]
The annals of mathematical statistics , pages=
A stochastic approximation method , author=. The annals of mathematical statistics , pages=. 1951 , publisher=
1951
-
[74]
International conference on machine learning , pages=
Learning dynamics and generalization in deep reinforcement learning , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[75]
International Conference on Machine Learning , pages=
Towards a better understanding of representation dynamics under TD-learning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[76]
International Conference on Machine Learning , pages=
Interference and generalization in temporal difference learning , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[77]
Advances in Neural Information Processing Systems , volume=
Deep reinforcement learning with plasticity injection , author=. Advances in Neural Information Processing Systems , volume=
-
[78]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Stable Gradients for Stable Learning at Scale in Deep Reinforcement Learning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[79]
Forty-first International Conference on Machine Learning , year=
In value-based deep reinforcement learning, a pruned network is a good network , author=. Forty-first International Conference on Machine Learning , year=
-
[80]
2022 , eprint=
The State of Sparse Training in Deep Reinforcement Learning , author=. 2022 , eprint=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.