UnsOcc: 3D Semantic Occupancy Prediction in Unstructured Scene via Rendering Fusion
Pith reviewed 2026-06-28 10:38 UTC · model grok-4.3
The pith
Bidirectional rendering supervision aligns multi-modal features to improve 3D semantic occupancy prediction in sparse unstructured scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
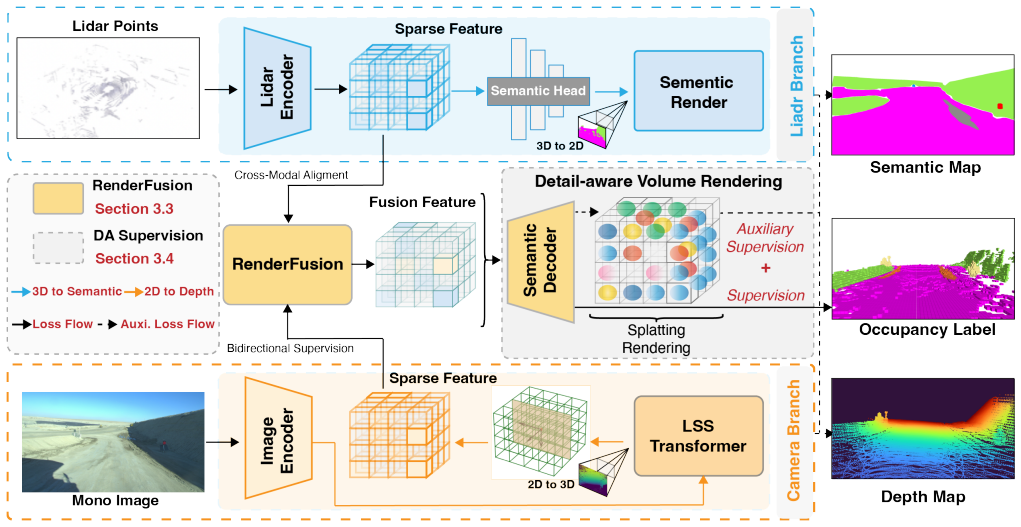
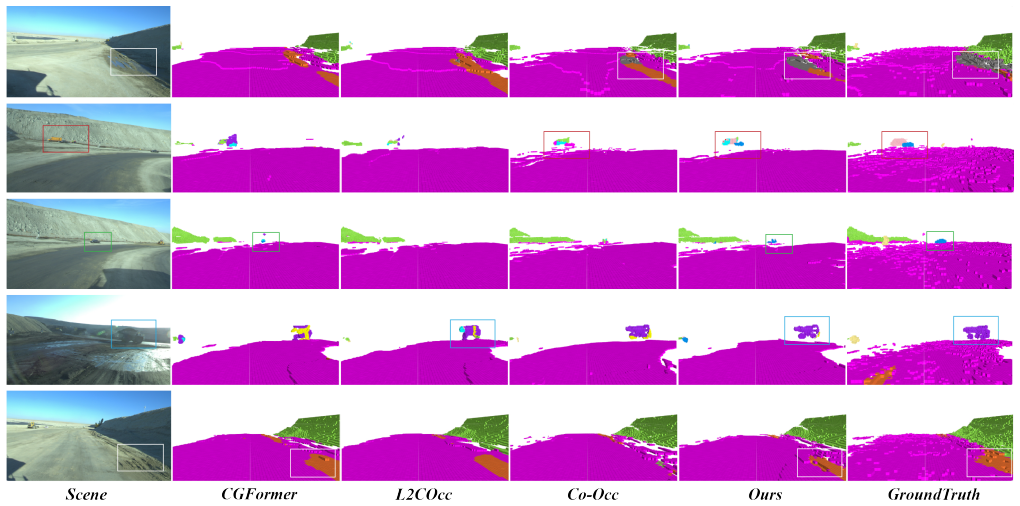
UnsOcc is a multi-modal framework whose RenderFusion module improves cross-modal feature alignment via bidirectional rendering supervision and whose GSRefinement module supplies detail-aware auxiliary supervision by projecting sparse 3D occupancy outputs into dense 2D semantic segmentation maps with Gaussian Splatting, jointly addressing sparsity and long-tail problems to produce more accurate voxel-level semantic predictions in unstructured scenes.
What carries the argument
RenderFusion, a rendering-based fusion module that performs bidirectional rendering supervision to align cross-modal features despite scene sparsity.
If this is right
- Dense 3D voxel semantic maps become feasible in environments with irregular obstacles and sparse layouts.
- Cross-modal fusion succeeds even when direct feature matching is hindered by low point density.
- Long-tail categories receive effective supervision through the 2D projection step.
- Performance improves on both the custom open-pit mine dataset and the nuScenes benchmark.
Where Pith is reading between the lines
- The same rendering supervision pattern could reduce reliance on dense 3D labels in other perception tasks.
- The approach may transfer to other sparse outdoor settings such as forests or construction zones.
- Combining the projection step with online rendering pipelines could support real-time deployment.
Load-bearing premise
Bidirectional rendering supervision together with Gaussian Splatting projection can overcome sparsity and long-tail issues without creating alignment artifacts or requiring dataset-specific tuning.
What would settle it
Apply UnsOcc to an additional unstructured scene dataset and check whether voxel accuracy gains disappear or visible misalignment appears between rendered 2D maps and ground-truth semantics.
Figures

read the original abstract
Unstructured scenes present unique challenges for autonomous driving, as irregular obstacles and sparse scene layouts undermine the effectiveness of traditional perception methods such as 3D object detection. 3D semantic occupancy prediction has emerged as a prominent focus due to its ability to provide dense spatial representations by assigning semantic labels to individual voxels in 3D space. However, directly applying 3D semantic occupancy prediction to unstructured scenes remains challenging because scene sparsity hinders effective cross-modal fusion and the more severe long-tail distribution in these scenarios further degrades prediction performance. To validate the effectiveness of our approach, we construct a dedicated dataset of unstructured scenes collected from open-pit mines. Based on this, we propose UnsOcc, a multi-modal 3D semantic occupancy prediction framework that improves robustness in unstructured environments. At its core, we introduce a rendering-based fusion module, RenderFusion, which enhances cross-modal feature alignment through bidirectional rendering supervision. Furthermore, we propose GSRefinement, a detail-aware auxiliary supervision method based on Gaussian Splatting that projects sparse 3D occupancy predictions into dense 2D semantic segmentation maps, enabling effective supervision for long-tail categories. Extensive experiments on both the open-pit mine dataset and the nuScenes dataset demonstrate that our method significantly outperforms existing state-of-the-art approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to address the challenges of 3D semantic occupancy prediction in unstructured scenes by constructing a new open-pit mine dataset and proposing the UnsOcc framework. The core contributions are RenderFusion, which enhances cross-modal feature alignment via bidirectional rendering supervision, and GSRefinement, which uses Gaussian Splatting to project sparse 3D occupancy predictions into dense 2D semantic maps for effective supervision of long-tail categories. Extensive experiments are reported to demonstrate significant outperformance over state-of-the-art methods on both the new dataset and nuScenes.
Significance. Should the claims prove correct upon detailed inspection of the methods and results, the work would be significant for the field of computer vision applied to autonomous systems in non-standard environments. It highlights the limitations of existing approaches in sparse and imbalanced scenes and offers practical solutions through rendering-based techniques. The new dataset could serve as a benchmark for future research in this area.
major comments (1)
- [Abstract] The assertion that the method 'significantly outperforms existing state-of-the-art approaches' on the open-pit mine dataset and nuScenes is central to the paper's contribution but lacks any supporting quantitative evidence, ablation details, or error analysis in the abstract, which is necessary to substantiate the effectiveness against scene sparsity and long-tail distribution issues.
minor comments (1)
- Consider adding specific performance metrics or improvement percentages in the abstract to better convey the strength of the results.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on our manuscript. We address the point regarding the abstract below and will make the suggested revision.
read point-by-point responses
-
Referee: [Abstract] The assertion that the method 'significantly outperforms existing state-of-the-art approaches' on the open-pit mine dataset and nuScenes is central to the paper's contribution but lacks any supporting quantitative evidence, ablation details, or error analysis in the abstract, which is necessary to substantiate the effectiveness against scene sparsity and long-tail distribution issues.
Authors: We agree that including quantitative evidence in the abstract would better substantiate the claim of significant outperformance. While space constraints in abstracts typically preclude detailed ablations or error analyses (which are provided in Sections 4.3 and 4.4 of the manuscript), we will revise the abstract to incorporate key quantitative results, such as the mIoU improvements on both the open-pit mine dataset and nuScenes, to directly support the effectiveness claims against sparsity and long-tail issues. revision: yes
Circularity Check
No significant circularity
full rationale
The abstract and available description introduce RenderFusion (bidirectional rendering supervision) and GSRefinement (Gaussian Splatting projection) as independent modules for cross-modal alignment and long-tail supervision. No equations, parameter fits, self-citations, or uniqueness theorems are referenced that would reduce any claimed prediction or result to its own inputs by construction. The central claims rest on empirical outperformance on constructed and public datasets rather than any definitional or fitted-input equivalence.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Scene sparsity hinders effective cross-modal fusion
- domain assumption More severe long-tail distribution in unstructured scenes degrades prediction performance
Reference graph
Works this paper leans on
-
[1]
Pointpillars: Fast encoders for object detection from point clouds,
A. H. Lang, S. V ora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “Pointpillars: Fast encoders for object detection from point clouds,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019, pp. 12 697–12 705
2019
-
[2]
Bevfusion: Multi-task multi-sensor fusion with unified bird’s- eye view representation,
Z. Liu, H. Tang, A. Amini, X. Yang, H. Mao, D. L. Rus, and S. Han, “Bevfusion: Multi-task multi-sensor fusion with unified bird’s- eye view representation,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 2774–2781
2023
-
[3]
Monoscene: Monocular 3d semantic scene completion,
A.-Q. Cao and R. De Charette, “Monoscene: Monocular 3d semantic scene completion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2022, pp. 3991–4001
2022
-
[4]
Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving,
Y . Wei, L. Zhao, W. Zheng, Z. Zhu, J. Zhou, and J. Lu, “Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2023, pp. 21 729–21 740
2023
-
[5]
Occformer: Dual-path transformer for vision-based 3d semantic occupancy prediction,
Y . Zhang, Z. Zhu, and D. Du, “Occformer: Dual-path transformer for vision-based 3d semantic occupancy prediction,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2023, pp. 9433–9443
2023
-
[6]
Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception,
X. Wang, Z. Zhu, W. Xu, Y . Zhang, Y . Wei, X. Chi, Y . Ye, D. Du, J. Lu, and X. Wang, “Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2023, pp. 17 850–17 859
2023
-
[7]
Z. Ming, J. Stephany Berrio, M. Shan, and S. Worrall, “Occfusion: A straightforward and effective multi-sensor fusion framework for 3d occupancy prediction,”arXiv preprint arXiv:2403.00000, 2024
-
[8]
A novel calibration method between a camera and a 3d lidar with infrared images,
S. Chen, J. Liu, X. Liang, S. Zhang, J. Hyyppä, and R. Chen, “A novel calibration method between a camera and a 3d lidar with infrared images,” in2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 4963–4969
2020
-
[9]
Occdepth: A depth-aware method for 3d semantic scene completion,
R. Miao, W. Liu, M. Chen, Z. Gong, W. Xu, C. Hu, and S. Zhou, “Occdepth: A depth-aware method for 3d semantic scene completion,” arXiv preprint arXiv:2302.13540, 2023
-
[10]
V oxformer: Sparse voxel transformer for camera- based 3d semantic scene completion,
Y . Li, Z. Yu, C. Choy, C. Xiao, J. M. Alvarez, S. Fidler, C. Feng, and A. Anandkumar, “V oxformer: Sparse voxel transformer for camera- based 3d semantic scene completion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2023, pp. 9087–9098
2023
-
[11]
Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving,
X. Tian, T. Jiang, L. Yun, Y . Mao, H. Yang, Y . Wang, Y . Wang, and H. Zhao, “Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving,”Advances in Neural Information Processing Systems, vol. 36, pp. 64 318–64 330, 2023
2023
-
[12]
Scene as occupancy,
W. Tong, C. Sima, T. Wang, L. Chen, S. Wu, H. Deng, Y . Gu, L. Lu, P. Luo, D. Linet al., “Scene as occupancy,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2023, pp. 8406–8415
2023
-
[13]
Occupancy as set of points,
Y . Shi, T. Cheng, Q. Zhang, W. Liu, and X. Wang, “Occupancy as set of points,” inProceedings of the European Conference on Computer Vision (ECCV). Springer, 2024, pp. 72–87
2024
-
[14]
Tri-perspective view for vision-based 3d semantic occupancy prediction,
Y . Huang, W. Zheng, Y . Zhang, J. Zhou, and J. Lu, “Tri-perspective view for vision-based 3d semantic occupancy prediction,” inProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2023, pp. 9223–9232
2023
-
[15]
Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction,
Y . Huang, W. Zheng, Y . Zhang, and J. Zhou, “Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction,” in European Conference on Computer Vision. Springer, 2024, pp. 376– 393
2024
-
[16]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoor- thi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,”Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021
2021
-
[17]
Nerf++: Analyzing and improving neural radiance fields,
K. Zhang, G. Riegler, N. Snavely, and V . Koltun, “Nerf++: Analyzing and improving neural radiance fields,”arXiv preprint arXiv:2010.07492, 2020
-
[18]
Mip-nerf: A multiscale representation for anti- aliasing neural radiance fields,
J. T. Barron, B. Mildenhall, M. Tancik, P. Hedman, R. Martin-Brualla, and P. P. Srinivasan, “Mip-nerf: A multiscale representation for anti- aliasing neural radiance fields,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2021, pp. 5855–5864
2021
-
[19]
Occnerf: Self-supervised multi-camera occupancy prediction with neural radiance fields,
C. Zhang, J. Yan, Y . Wei, J. Li, L. Liu, Y . Tang, Y . Duan, and J. Lu, “Occnerf: Self-supervised multi-camera occupancy prediction with neural radiance fields,”CoRR, 2023
2023
-
[20]
Renderocc: Vision-centric 3d occupancy prediction with 2d rendering supervision,
M. Pan, J. Liu, R. Zhang, P. Huang, X. Li, H. Xie, B. Wang, L. Liu, and S. Zhang, “Renderocc: Vision-centric 3d occupancy prediction with 2d rendering supervision,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 12 404–12 411
2024
-
[21]
3d gaussian splatting for real-time radiance field rendering,
B. Kerbl, G. Kopanas, T. Leimkühler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering,”ACM Transactions on Graphics, vol. 42, no. 4, pp. 139:1–139:14, 2023
2023
-
[22]
W. Gan, F. Liu, H. Xu, N. Mo, and N. Yokoya, “Gaussianocc: Fully self-supervised and efficient 3d occupancy estimation with gaussian splatting,”arXiv preprint arXiv:2408.11447, 2024
-
[23]
H. Jiang, L. Liu, T. Cheng, X. Wang, T. Lin, Z. Su, W. Liu, and X. Wang, “Gausstr: Foundation model-aligned gaussian trans- former for self-supervised 3d spatial understanding,”arXiv preprint arXiv:2412.13193, 2024
-
[24]
Gaussianbev: 3d gaussian representation meets perception models for bev segmentation,
F. Chabot, N. Granger, and G. Lapouge, “Gaussianbev: 3d gaussian representation meets perception models for bev segmentation,” in2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). IEEE, 2025, pp. 2250–2259
2025
-
[25]
Gaussrender: Learning 3d occupancy with gaussian rendering,
L. Chambon, E. Zablocki, A. Boulch, M. Chen, and M. Cord, “Gaussrender: Learning 3d occupancy with gaussian rendering,”arXiv preprint arXiv:2502.05040, 2025
-
[26]
Mvx-net: Multimodal voxelnet for 3d object detection,
V . A. Sindagi, Y . Zhou, and O. Tuzel, “Mvx-net: Multimodal voxelnet for 3d object detection,” in2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 7276–7282
2019
-
[27]
Unitr: A unified and efficient multi-modal transformer for bird’s-eye- view representation,
H. Wang, H. Tang, S. Shi, A. Li, Z. Li, B. Schiele, and L. Wang, “Unitr: A unified and efficient multi-modal transformer for bird’s-eye- view representation,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2023, pp. 6792–6802
2023
-
[28]
Uniseg: A unified multi-modal lidar segmen- tation network and the openpcseg codebase,
Y . Liu, R. Chen, X. Li, L. Kong, Y . Yang, Z. Xia, Y . Bai, X. Zhu, Y . Ma, Y . Liet al., “Uniseg: A unified multi-modal lidar segmen- tation network and the openpcseg codebase,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2023, pp. 21 662–21 673
2023
-
[29]
Mseg3d: Multi-modal 3d semantic segmentation for autonomous driving,
J. Li, H. Dai, H. Han, and Y . Ding, “Mseg3d: Multi-modal 3d semantic segmentation for autonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2023, pp. 21 694–21 704
2023
-
[30]
Co-occ: Coupling explicit feature fu- sion with volume rendering regularization for multi-modal 3d semantic occupancy prediction,
J. Pan, Z. Wang, and L. Wang, “Co-occ: Coupling explicit feature fu- sion with volume rendering regularization for multi-modal 3d semantic occupancy prediction,”IEEE Robotics and Automation Letters, 2024
2024
-
[31]
Occgen: Generative multi-modal 3d occupancy prediction for autonomous driving,
G. Wang, Z. Wang, P. Tang, J. Zheng, X. Ren, B. Feng, and C. Ma, “Occgen: Generative multi-modal 3d occupancy prediction for autonomous driving,” inProceedings of the European Conference on Computer Vision (ECCV). Springer, 2024, pp. 95–112
2024
-
[32]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,
J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” inProceedings of the European Conference on Computer Vision (ECCV). Springer, 2020, pp. 194–210
2020
-
[33]
Context and geometry aware voxel transformer for semantic scene completion,
Z. Yu, R. Zhang, J. Ying, J. Yu, X. Hu, L. Luo, S.-Y . Cao, and H.-l. Shen, “Context and geometry aware voxel transformer for semantic scene completion,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 37, 2024, pp. 1531–1555
2024
-
[34]
L2cocc: Lightweight camera-centric semantic scene completion via distillation of lidar model,
R. Wang, Y . Ma, Y . Yao, S. Tao, H. Li, Z. Zhu, Y . Liu, and X. Zuo, “L2cocc: Lightweight camera-centric semantic scene completion via distillation of lidar model,”arXiv preprint arXiv:2503.12369, 2025
-
[35]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 621–11 631
2020
-
[36]
Bev- former: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai, “Bev- former: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[37]
Fb-occ: 3d occupancy prediction based on forward-backward view transformation,
Z. Li, Z. Yu, D. Austin, M. Fang, S. Lan, J. Kautz, and J. M. Alvarez, “Fb-occ: 3d occupancy prediction based on forward-backward view transformation,”arXiv preprint arXiv:2307.01492, 2023
-
[38]
Lmscnet: Lightweight multiscale 3d semantic completion,
L. Roldao, R. De Charette, and A. Verroust-Blondet, “Lmscnet: Lightweight multiscale 3d semantic completion,” in2020 International Conference on 3D Vision (3DV). IEEE, 2020, pp. 111–119
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.