Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models
Pith reviewed 2026-06-28 10:54 UTC · model grok-4.3
The pith
YOLO26 reaches 40.9-57.5 mAP on COCO at 1.7-11.8 ms latency with a dual-head design that enables native end-to-end inference without NMS.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
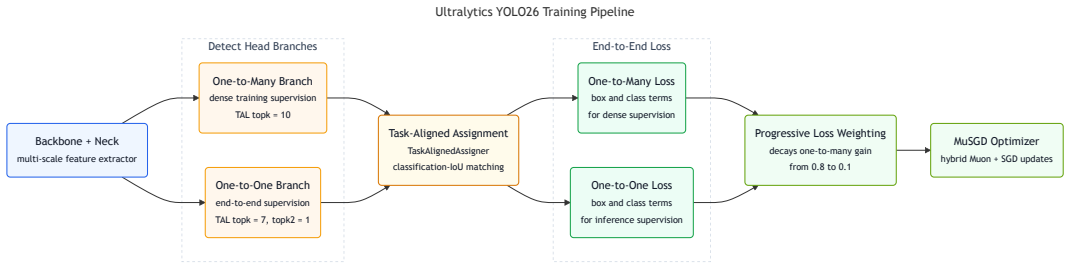
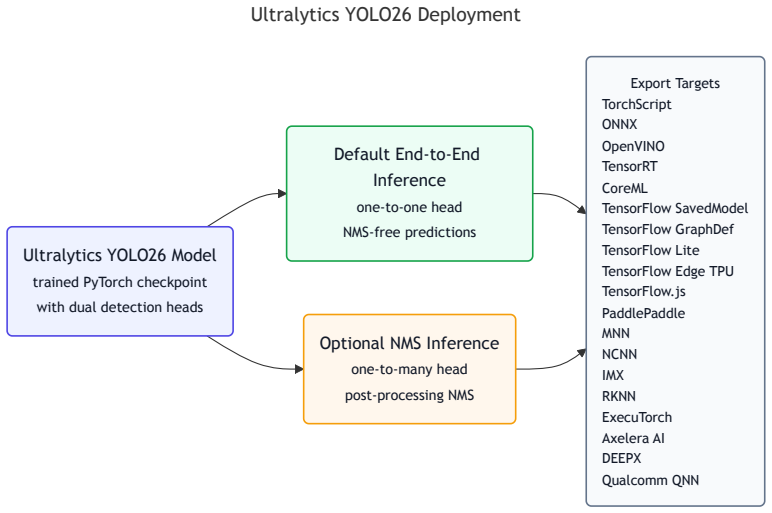
YOLO26 uses a dual-head design for native NMS-free end-to-end inference and removes DFL entirely, yielding a lighter head with unconstrained regression range. Its training pipeline combines MuSGD, a hybrid Muon-SGD optimizer; Progressive Loss, which shifts supervision toward the inference-time head; and STAL, a label assignment strategy that guarantees positive coverage for small objects. Beyond detection, task-specific heads and losses extend the approach to instance segmentation, pose estimation, and oriented detection, with an open-vocabulary YOLOE-26 variant for text-, visual-, and prompt-free inference.
What carries the argument
The dual-head design combined with Progressive Loss, which enables end-to-end inference without NMS by aligning training and inference heads.
If this is right
- Inference pipelines no longer require a separate NMS step, reducing deployment complexity across hardware.
- Lighter heads from removing DFL allow faster inference while maintaining or improving regression range.
- STAL ensures small objects receive positive labels, raising recall on fine-scale targets without extra cost.
- The same architecture and training recipe produces consistent gains when extended to segmentation, pose, and oriented detection.
- YOLOE-26x reaches 40.6 AP on LVIS minival under text prompting, extending the family to open-vocabulary use.
Where Pith is reading between the lines
- If the dual-head and loss-alignment pattern generalizes, other single-stage detectors could adopt similar end-to-end training to drop NMS.
- Unconstrained regression after removing DFL might improve performance on datasets with object sizes outside the COCO distribution.
- A single unified pipeline for multiple tasks could reduce the engineering overhead of maintaining separate models in production.
- The open-vocabulary extension suggests the core architecture may support prompt-driven adaptation with limited additional training.
Load-bearing premise
The performance improvements come from the dual-head design, removal of DFL, MuSGD, Progressive Loss, and STAL rather than from unreported differences in training data, schedule length, or hyperparameter choices.
What would settle it
An ablation that trains a YOLO26 variant and a prior YOLO baseline on identical data, schedule, and augmentation, then measures whether the accuracy-latency gap remains.
Figures



read the original abstract
Real-time vision demands models that are accurate, efficient, and simple to deploy across diverse hardware. The YOLO family has become widely deployed for this reason, yet most YOLO detectors still rely on non-maximum suppression at inference, carry heavy detection heads due to Distribution Focal Loss, require long training schedules, and can leave the smallest objects without positive label assignments. We present Ultralytics YOLO26, a unified real-time vision model family that addresses these limitations through coordinated architecture and training advances. YOLO26 uses a dual-head design for native NMS-free end-to-end inference and removes DFL entirely, yielding a lighter head with unconstrained regression range. Its training pipeline combines MuSGD, a hybrid Muon-SGD optimizer adapted from large language model training; Progressive Loss, which shifts supervision toward the inference-time head; and STAL, a label assignment strategy that guarantees positive coverage for small objects. Beyond detection, YOLO26 introduces task-specific head and loss designs for instance segmentation, pose estimation, and oriented detection, producing consistent gains across tasks and scales. The family spans five scales (n/s/m/l/x) and supports detection, instance segmentation, pose estimation, classification, and oriented detection in a single pipeline, with an open-vocabulary extension, YOLOE-26, for text-, visual-, and prompt-free inference. Across all scales, YOLO26 achieves 40.9-57.5 mAP on COCO at 1.7-11.8 ms T4 TensorRT latency, advancing the accuracy-latency Pareto front over prior real-time detectors, while YOLOE-26x reaches 40.6 AP on LVIS minival under text prompting. Code and models are available at https://github.com/ultralytics/ultralytics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Ultralytics YOLO26, a family of real-time vision models (n/s/m/l/x scales) that replace NMS with a dual-head design, eliminate Distribution Focal Loss, introduce MuSGD (a Muon-SGD hybrid), Progressive Loss, and STAL label assignment. It reports 40.9-57.5 mAP on COCO at 1.7-11.8 ms T4 TensorRT latency, 40.6 AP on LVIS minival for the open-vocabulary YOLOE-26x variant, and consistent gains on segmentation, pose, and oriented detection tasks, claiming these changes advance the accuracy-latency Pareto front over prior real-time detectors.
Significance. If the reported gains are shown to result from the listed architectural and training changes under controlled conditions, the work would strengthen the YOLO lineage with simpler deployment and broader task support; the open release of code and models would further increase impact for practitioners.
major comments (2)
- [Abstract] Abstract: the central claim that the dual-head design, DFL removal, MuSGD, Progressive Loss, and STAL advance the COCO accuracy-latency Pareto front is unsupported because no ablation studies, fixed-baseline comparisons, or training-protocol details (data augmentation, epoch count, hyper-parameters) are supplied to isolate these factors from unreported differences versus prior YOLO models.
- [Abstract] Abstract and §1: the experimental protocol (training schedule, optimizer settings for MuSGD mixing coefficients, Progressive Loss transition weights, STAL thresholds) is omitted, preventing verification that the 40.9-57.5 mAP range and latency figures are reproducible or attributable to the claimed innovations rather than implementation details.
minor comments (1)
- [Abstract] The abstract introduces several new terms (MuSGD, STAL, Progressive Loss) without a brief definition or reference to their first appearance in the methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and experimental details. We address each point below and will revise the manuscript to strengthen support for the claims and improve reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the dual-head design, DFL removal, MuSGD, Progressive Loss, and STAL advance the COCO accuracy-latency Pareto front is unsupported because no ablation studies, fixed-baseline comparisons, or training-protocol details (data augmentation, epoch count, hyper-parameters) are supplied to isolate these factors from unreported differences versus prior YOLO models.
Authors: We agree that dedicated ablation studies would more rigorously isolate the contribution of each component. The manuscript reports end-to-end system performance and direct comparisons against prior YOLO models on COCO and other benchmarks. In the revision we will add a concise ablation table summarizing the impact of the dual-head design, DFL removal, MuSGD, Progressive Loss, and STAL. revision: yes
-
Referee: [Abstract] Abstract and §1: the experimental protocol (training schedule, optimizer settings for MuSGD mixing coefficients, Progressive Loss transition weights, STAL thresholds) is omitted, preventing verification that the 40.9-57.5 mAP range and latency figures are reproducible or attributable to the claimed innovations rather than implementation details.
Authors: We acknowledge that the abstract and introduction do not list every hyper-parameter. The full training schedule, MuSGD coefficients, loss weights, and STAL thresholds appear in the methods section and are implemented in the released code. We will expand §3 (and add a short protocol summary to §1) to make these values explicit in the main text. revision: yes
Circularity Check
Minor self-citation to prior YOLO lineage but no load-bearing derivations or predictions that reduce to inputs by construction
full rationale
The paper is an empirical engineering contribution reporting benchmark results on external datasets (COCO, LVIS) for a new model family. It references its own prior YOLO work for context but the central accuracy-latency claims rest on standard external evaluation rather than any mathematical derivation chain, fitted-parameter predictions, or self-definitional steps. No equations or first-principles results are presented that collapse to the inputs.
Axiom & Free-Parameter Ledger
free parameters (3)
- MuSGD mixing coefficients and learning-rate schedule
- Progressive Loss transition schedule and weighting
- STAL positive-assignment thresholds and small-object criteria
axioms (2)
- domain assumption COCO and LVIS minival splits are representative and unbiased testbeds for real-time multi-task vision performance.
- domain assumption TensorRT latency on T4 hardware is a fair and reproducible proxy for real-world deployment speed.
invented entities (2)
-
MuSGD optimizer
no independent evidence
-
STAL label assignment strategy
no independent evidence
Forward citations
Cited by 1 Pith paper
-
A Smart Classroom Behavior Analysis Framework with a New Highly Congested Classroom Dataset
Introduces HCCB dataset and ODER-HSFNet achieving 60.60%/80.12% mAP50:95/mAP50 on HCCB for seven-class student behavior detection in congested classrooms.
Reference graph
Works this paper leans on
-
[1]
Core ML Tools.https://github.com/ apple/coremltools, 2024
Apple. Core ML Tools.https://github.com/ apple/coremltools, 2024. Accessed: 2026-02-05. 2
2024
-
[2]
Yolact: Real-time instance segmentation
Daniel Bolya, Chong Zhou, Fanyi Xiao, and Yong Jae Lee. Yolact: Real-time instance segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion (ICCV), pages 9157–9166, 2019. 4, 8
2019
-
[3]
The opencv library.Dr
Gary Bradski. The opencv library.Dr. Dobb’s Journal of Software Tools, 2000. 9
2000
-
[4]
OpenPose: Realtime multi-person 2D pose estimation using part affinity fields.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(1):172–186,
Zhe Cao, Gines Hidalgo, Tomas Simon, Shih-En Wei, and Yaser Sheikh. OpenPose: Realtime multi-person 2D pose estimation using part affinity fields.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(1):172–186,
-
[5]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nico- las Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InCom- puter Vision – ECCV 2020, pages 213–229. Springer, Cham, 2020. 2, 3
2020
-
[6]
Group DETR: Fast DETR training with group-wise one-to-many assignment
Qiang Chen, Xiaokang Chen, Jian Wang, Shan Zhang, Kun Yao, Haocheng Feng, Junyu Han, Errui Ding, Gang Zeng, and Jingdong Wang. Group DETR: Fast DETR training with group-wise one-to-many assignment. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6633–6642, 2023. 4
2023
-
[7]
Qiang Chen, Xiangbo Su, Xinyu Zhang, Jian Wang, Jiahui Chen, Yunpeng Shen, Chuchu Han, Ziliang Chen, Weix- iang Xu, Fanrong Li, Shan Zhang, Kun Yao, Errui Ding, Gang Zhang, and Jingdong Wang. LW-DETR: A trans- former replacement to YOLO for real-time detection.arXiv preprint arXiv:2406.03459, 2024. 4
-
[8]
Schwing, Alexander Kirillov, and Rohit Girdhar
Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1290–1299, 2022. 4
2022
-
[9]
YOLO-World: Real-time open-vocabulary object detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xing- gang Wang, and Ying Shan. YOLO-World: Real-time open-vocabulary object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 5, 29
2024
-
[10]
Learning RoI transformer for oriented object detection in aerial images
Jian Ding, Nan Xue, Yang Long, Gui-Song Xia, and Qikai Lu. Learning RoI transformer for oriented object detection in aerial images. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 2849–2858, 2019. 4
2019
-
[11]
Density estimation using real-valued non-volume preserv- ing (Real NVP) transformations
Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using real-valued non-volume preserv- ing (Real NVP) transformations. InInternational Confer- ence on Learning Representations (ICLR), 2017. 8
2017
-
[12]
Centernet: Keypoint triplets for object detection
Kaiwen Duan, Song Bai, Lingxi Xie, Honggang Qi, Qing- ming Huang, and Qi Tian. Centernet: Keypoint triplets for object detection. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 6569–6578,
-
[13]
Toshev, Oncel Tuzel, and Hadi Pouransari
Fartash Faghri, Pavan Kumar Anasosalu Vasu, Cem Koc, Vaishaal Shankar, Alexander T. Toshev, Oncel Tuzel, and Hadi Pouransari. MobileCLIP2: Improving multi-modal reinforced training.Transactions on Machine Learning Re- search (TMLR), 2025. 3, 11
2025
-
[14]
Scott, and Weilin Huang
Chengjian Feng, Yujie Zhong, Yu Gao, Matthew R. Scott, and Weilin Huang. Tood: Task-aligned one-stage object detection. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3490–3499,
-
[15]
Fast r-cnn
Ross Girshick. Fast r-cnn. InProceedings of the IEEE international conference on computer vision, pages 1440– 1448, 2015. 3
2015
-
[16]
Rich feature hierarchies for accurate object de- tection and semantic segmentation
Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurate object de- tection and semantic segmentation. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 580–587, 2014. 3
2014
-
[17]
TensorFlow Lite.https://ai.google
Google. TensorFlow Lite.https://ai.google. dev/edge/litert, 2024. Accessed: 2026-02-05. 2
2024
-
[18]
Align deep features for oriented object detection.IEEE Transac- tions on Geoscience and Remote Sensing, 60:1–11, 2022
Jiaming Han, Jian Ding, Jie Li, and Gui-Song Xia. Align deep features for oriented object detection.IEEE Transac- tions on Geoscience and Remote Sensing, 60:1–11, 2022. 5
2022
-
[19]
Mask r-cnn
Kaiming He, Georgia Gkioxari, Piotr Doll ´ar, and Ross Gir- shick. Mask r-cnn. InProceedings of the IEEE interna- tional conference on computer vision, pages 2961–2969,
-
[20]
Real-time object detection meets DINOv3
Shihua Huang, Yongjie Hou, Longfei Liu, Xuanlong Yu, and Xi Shen. Real-time object detection meets DINOv3. arXiv preprint arXiv:2509.20787, 2025. 4
-
[21]
DEIM: DETR with improved matching for fast convergence
Shihua Huang, Zhichao Lu, Xiaodong Cun, Yongjun Yu, Xiao Zhou, and Xi Shen. DEIM: DETR with improved matching for fast convergence. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15162–15171, 2025. 2, 4, 27
2025
-
[22]
Open-set image tagging with multi-grained text su- pervision
Xinyu Huang, Yi-Jie Huang, Youcai Zhang, Weiwei Tian, Rui Feng, Yuejie Zhang, Yanchun Xie, Yaqian Li, and Lei Zhang. Open-set image tagging with multi-grained text su- pervision. InProceedings of the 33rd ACM International Conference on Multimedia, pages 4117–4126, 2025. 11
2025
-
[23]
Hudson and Christopher D
Drew A. Hudson and Christopher D. Manning. Gqa: A new dataset for real-world visual reasoning and composi- tional question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6700–6709, 2019. 15, 24, 30
2019
-
[24]
Intel Distribution of OpenVINO Toolkit.https: / / github
Intel. Intel Distribution of OpenVINO Toolkit.https: / / github . com / openvinotoolkit / openvino,
-
[25]
Accessed: 2026-02-05. 2
2026
-
[26]
DETRs with hybrid matching
Ding Jia, Yuhui Yuan, Haodi He, Xiaopei Wu, Haojun Yu, Weihong Lin, Lei Sun, Chao Zhang, and Han Hu. DETRs with hybrid matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19702–19712, 2023. 4
2023
-
[27]
Qing Jiang, Feng Li, Zhaoyang Zeng, Tianhe Ren, Shi- long Liu, and Lei Zhang. T-Rex2: Towards generic ob- ject detection via text-visual prompt synergy.arXiv preprint arXiv:2403.14610, 2024. 5, 29 18
-
[28]
RTMPose: Real-time multi-person pose estimation based on MMPose
Tao Jiang, Peng Lu, Li Zhang, Ningsheng Ma, Rui Han, Chengqi Lyu, Yining Li, and Kai Chen. RTMPose: Real-time multi-person pose estimation based on MMPose. arXiv preprint arXiv:2303.07399, 2023. 4
-
[29]
ultralytics/yolov5: Initial release, 2020
Glenn Jocher et al. ultralytics/yolov5: Initial release, 2020. 2, 3
2020
-
[30]
Ni, and Lei Zhang
Feng Li, Hao Zhang, Shilong Liu, Jian Guo, Lionel M. Ni, and Lei Zhang. DN-DETR: Accelerate DETR train- ing by introducing query denoising. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13619–13627, 2022. 4
2022
-
[31]
Feng Li, Hao Zhang, Peize Sun, Xueyan Zou, Shilong Liu, Jianwei Yang, Chunyuan Li, Lei Zhang, and Jianfeng Gao. Semantic-sam: Segment and recognize anything at any granularity.arXiv preprint arXiv:2307.04767, 2023. 5
-
[32]
Ni, and Heung-Yeung Shum
Feng Li, Hao Zhang, Huaizhe Xu, Shilong Liu, Lei Zhang, Lionel M. Ni, and Heung-Yeung Shum. Mask dino: To- wards a unified transformer-based framework for object de- tection and segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3041–3050, 2023. 4
2023
-
[33]
Visual in- context prompting
Feng Li, Qing Jiang, Hao Zhang, Tianhe Ren, Shilong Liu, Xueyan Zou, Huaizhe Xu, Hongyang Li, Jianwei Yang, Chunyuan Li, Lei Zhang, and Jianfeng Gao. Visual in- context prompting. InCVPR, pages 12861–12871, 2024. 5
2024
-
[34]
Human pose regression with residual log-likelihood estimation
Jiefeng Li, Siyuan Bian, Ailing Zeng, Can Wang, Bo Pang, Wentao Liu, and Cewu Lu. Human pose regression with residual log-likelihood estimation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11025–11034, 2021. 3, 4, 8
2021
-
[35]
Grounded language-image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jian- wei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, and Jianfeng Gao. Grounded language-image pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2022. 5, 29
2022
-
[36]
Generalized fo- cal loss: Learning qualified and distributed bounding boxes for dense object detection
Xiang Li, Wenhai Wang, Lijun Wu, Shuo Chen, Xiaolin Hu, Jun Li, Jinhui Tang, and Jian Yang. Generalized fo- cal loss: Learning qualified and distributed bounding boxes for dense object detection. InAdvances in Neural Informa- tion Processing Systems, pages 21002–21012. Curran As- sociates, Inc., 2020. 6
2020
-
[37]
LSKNet: A foundation lightweight backbone for remote sensing
Yuxuan Li, Qibin Hou, Zhaohui Zheng, Ming-Ming Cheng, Jian Yang, and Xiang Li. LSKNet: A foundation lightweight backbone for remote sensing. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4829–4840, 2023. 5
2023
-
[38]
Zijun Liao, Yian Zhao, Xin Shan, Yu Yan, Chang Liu, Lei Lu, Xiangyang Ji, and Jie Chen. RT-DETRv4: Painlessly furthering real-time object detection with vision foundation models.arXiv preprint arXiv:2510.25257, 2025. 4
-
[39]
Generative region-language pretraining for open- ended object detection
Chuang Lin, Yi Jiang, Lizhen Qu, Zehuan Yuan, and Jian- fei Cai. Generative region-language pretraining for open- ended object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 5, 26, 30
2024
-
[40]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll ´ar. Focal loss for dense object detection. In Proceedings of the IEEE international conference on com- puter vision, pages 2980–2988, 2017. 2, 3
2017
-
[41]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, Yanru Chen, Huabin Zheng, Yibo Liu, Bo- hong Yin, Weiran He, Han Zhu, Yuzhi Wang, Jianzhou Wang, Mengnan Dong, Zheng Zhang, Yongsheng Kang, Hao Zhang, Xinran Xu, Yutao Zhang, Yuxin Wu, Xinyu Zhou, and Zhilin Yang. Muon is scalable for l...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Yolo-uniow: Effi- cient universal open-world object detection.arXiv preprint arXiv:2412.20645, 2024
Lihao Liu, Juexiao Zeng, Xu Gao, Baize Yan, Yi Luo, Guang Wang, and Yunzhe Zhuge. Yolo-uniow: Effi- cient universal open-world object detection.arXiv preprint arXiv:2412.20645, 2024. 5
-
[43]
DAB-DETR: Dynamic anchor boxes are better queries for DETR
Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, and Lei Zhang. DAB-DETR: Dynamic anchor boxes are better queries for DETR. InInternational Conference on Learning Representations (ICLR), 2022. 4
2022
-
[44]
Grounding DINO: Mar- rying DINO with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding DINO: Mar- rying DINO with grounded pre-training for open-set object detection. InProceedings of the European Conference on Computer Vision (ECCV), 2024. 5, 29
2024
-
[45]
Ssd: Single shot multibox detector
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. InEuropean con- ference on computer vision, pages 21–37. Springer, 2016. 2, 3
2016
-
[46]
Llerena, Luis Felipe Zeni, Lucas N
Jeffri M. Llerena, Luis Felipe Zeni, Lucas N. Kristen, and Claudio Jung. Gaussian bounding boxes and probabilistic intersection-over-union for object detection.arXiv preprint arXiv:2106.06072, 2021. 5, 9
-
[47]
Wenyu Lv, Yian Zhao, Qinyao Chang, Kui Huang, Guanzhong Wang, and Yi Liu. Rt-detrv2: Improved baseline with bag-of-freebies for real-time detection trans- former.arXiv preprint arXiv:2407.17140, 2024. 27
-
[48]
Arbitrary-oriented scene text detection via rotation proposals.IEEE Trans- actions on Multimedia, 20(11):3111–3122, 2018
Jianqi Ma, Weiyuan Shao, Hao Ye, Li Wang, Hong Wang, Yingbin Zheng, and Xiangyang Xue. Arbitrary-oriented scene text detection via rotation proposals.IEEE Trans- actions on Multimedia, 20(11):3111–3122, 2018. 4
2018
-
[49]
YOLO-Pose: Enhancing YOLO for multi per- son pose estimation using object keypoint similarity loss
Debapriya Maji, Soyeb Nagori, Manu Mathew, and Deepak Poddar. YOLO-Pose: Enhancing YOLO for multi per- son pose estimation using object keypoint similarity loss. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 2637–2646, 2022. 4, 8
2022
-
[50]
Simple open-vocabulary object detec- tion with vision transformers
Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby. Simple open-vocabulary object detec- tion with vision transformers. InECCV, 2022. 5
2022
-
[51]
Kimi K2: Open Agentic Intelligence
Moonshot AI. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025. 7 19
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
ncnn documentation.https:// ncnn.readthedocs.io/en/latest/, 2026
ncnn Contributors. ncnn documentation.https:// ncnn.readthedocs.io/en/latest/, 2026. Offi- cial documentation for the ncnn inference framework. Ac- cessed: 2026-04-10. 2
2026
-
[53]
Stacked hourglass networks for human pose estimation
Alejandro Newell, Kaiyu Yang, and Jia Deng. Stacked hourglass networks for human pose estimation. InCom- puter Vision – ECCV 2016, pages 483–499. Springer, Cham, 2016. 4
2016
-
[54]
NVIDIA TensorRT: High-performance deep learning inference sdk.https : / / github
NVIDIA. NVIDIA TensorRT: High-performance deep learning inference sdk.https : / / github . com / NVIDIA/TensorRT, 2024. Accessed: 2026-02-05. 2
2024
-
[55]
ONNX: Open neural network ex- change.https://github.com/onnx/onnx, 2019
ONNX Contributors. ONNX: Open neural network ex- change.https://github.com/onnx/onnx, 2019. Accessed: 2026-02-05. 2
2019
-
[56]
D-FINE: Redefine regression task of DETRs as fine-grained distribution refinement
Yansong Peng, Hebei Li, Peixi Wu, Yueyi Zhang, Xiaoyan Sun, and Feng Wu. D-FINE: Redefine regression task of DETRs as fine-grained distribution refinement. InInter- national Conference on Learning Representations (ICLR),
-
[57]
Plummer, Liwei Wang, Chris M
Bryan A. Plummer, Liwei Wang, Chris M. Cervantes, Juan C. Caicedo, Julia Hockenmaier, and Svetlana Lazeb- nik. Flickr30k entities: Collecting region-to-phrase corre- spondences for richer image-to-sentence models. InPro- ceedings of the IEEE International Conference on Com- puter Vision (ICCV), pages 2641–2649, 2015. 15, 24, 30
2015
-
[58]
Executorch documentation
PyTorch Contributors. Executorch documentation. https : / / docs . pytorch . org / executorch / stable/, 2026. Official documentation for ExecuTorch. Accessed: 2026-04-10. 2
2026
-
[59]
torch.optim.sgd.https : / / docs.pytorch.org/docs/stable/generated/ torch.optim.SGD.html, 2026
PyTorch Contributors. torch.optim.sgd.https : / / docs.pytorch.org/docs/stable/generated/ torch.optim.SGD.html, 2026. Accessed: 2026-02-
2026
-
[60]
YOLOv3: An Incremental Improvement
Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement.arXiv preprint arXiv:1804.02767, 2018. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[61]
Faster r-cnn: Towards real-time object detection with re- gion proposal networks.Advances in neural information processing systems, 28, 2015
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with re- gion proposal networks.Advances in neural information processing systems, 28, 2015. 2, 3
2015
-
[62]
Tianhe Ren, Shilong Liu, Zhaoyang Zeng, Hao Lin, Feng Li, Hao Tang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding DINO 1.5: Advance the “edge” of open-set object detection.arXiv preprint arXiv:2405.10300, 2024. 29
-
[63]
Isaac Robinson, Peter Robicheaux, Matvei Popov, Deva Ramanan, and Neehar Peri. RF-DETR: Neural architecture search for real-time detection transformers.arXiv preprint arXiv:2511.09554, 2025. 2, 4
-
[64]
Objects365: A large-scale, high-quality dataset for object detection
Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Jing Li, Xiangyu Zhang, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8425–8434, 2019. 11, 15, 24, 30
2019
-
[65]
Deep high-resolution representation learning for human pose es- timation
Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep high-resolution representation learning for human pose es- timation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5693–5703, 2019. 4
2019
-
[66]
Yolov12: Attention-centric real-time object detectors
Yunjie Tian, Qixiang Ye, and David Doermann. Yolov12: Attention-centric real-time object detectors. InAdvances in Neural Information Processing Systems, 2025. 27
2025
-
[67]
Fcos: Fully convolutional one-stage object detection
Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. Fcos: Fully convolutional one-stage object detection. InProceed- ings of the IEEE/CVF international conference on com- puter vision, pages 9627–9636, 2019. 2, 3
2019
-
[68]
Conditional con- volutions for instance segmentation
Zhi Tian, Chunhua Shen, and Hao Chen. Conditional con- volutions for instance segmentation. InComputer Vision – ECCV 2020. Springer, Cham, 2020. 4
2020
-
[69]
DeepPose: Hu- man pose estimation via deep neural networks
Alexander Toshev and Christian Szegedy. DeepPose: Hu- man pose estimation via deep neural networks. InProceed- ings of the IEEE Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 1653–1660, 2014. 4
2014
-
[70]
Explore ultralytics yolov8.https://docs
Ultralytics. Explore ultralytics yolov8.https://docs. ultralytics.com/models/yolov8/, 2023. On- line documentation (no formal paper). 2, 3, 4, 5, 6
2023
-
[71]
Ultralytics yolo11.https : / / docs
Ultralytics. Ultralytics yolo11.https : / / docs . ultralytics.com/models/yolo11/, 2024. On- line documentation (no formal paper). Accessed: 2026-02-
2024
-
[72]
Ultralytics export mode.https://docs
Ultralytics. Ultralytics export mode.https://docs. ultralytics.com/modes/export/, 2026. Online documentation describing supported export formats and de- ployment targets. Accessed: 2026-04-10. 2, 9
2026
-
[73]
Ultralytics predict mode.https://docs
Ultralytics. Ultralytics predict mode.https://docs. ultralytics.com/modes/predict/, 2026. On- line documentation describing model inference workflows. Accessed: 2026-06-01. 9
2026
-
[74]
Ultralytics computer vision tasks.https: //docs.ultralytics.com/tasks/, 2026
Ultralytics. Ultralytics computer vision tasks.https: //docs.ultralytics.com/tasks/, 2026. Online documentation describing supported computer vision tasks. Accessed: 2026-06-01. 2, 9
2026
-
[75]
Ultralytics train mode.https://docs
Ultralytics. Ultralytics train mode.https://docs. ultralytics.com/modes/train/, 2026. Online documentation describing model training workflows. Ac- cessed: 2026-06-01. 9
2026
-
[76]
Ultralytics val mode.https://docs
Ultralytics. Ultralytics val mode.https://docs. ultralytics.com/modes/val/, 2026. Online doc- umentation describing model validation workflows. Ac- cessed: 2026-06-01. 9
2026
-
[77]
Ultralytics yolo26.https : / / docs
Ultralytics. Ultralytics yolo26.https : / / docs . ultralytics.com/models/yolo26/, 2026. On- line documentation and released benchmark tables. Ac- cessed: 2026-03-13. 13, 14
2026
-
[78]
Mobile- CLIP: Fast image-text models through multi-modal rein- forced training
Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Raviteja Vemulapalli, and Oncel Tuzel. Mobile- CLIP: Fast image-text models through multi-modal rein- forced training. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[79]
Yolov10: Real-time end-to-end object de- tection.Advances in Neural Information Processing Sys- tems, 37:107984–108011, 2024
Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jun- gong Han, et al. Yolov10: Real-time end-to-end object de- tection.Advances in Neural Information Processing Sys- tems, 37:107984–108011, 2024. 2, 3, 6, 27
2024
-
[80]
YOLOE: Real-time seeing anything
Ao Wang, Lihao Liu, Hui Chen, Zijia Lin, Jungong Han, and Guiguang Ding. YOLOE: Real-time seeing anything. 20 InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. 3, 5, 10, 24, 29, 30
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.