Worth Remembering: Surprise-Gated Robot Episodic Memory
Pith reviewed 2026-06-28 09:35 UTC · model grok-4.3
The pith
Bayesian surprise in a video model's latent space selects which robot episodes to store in memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
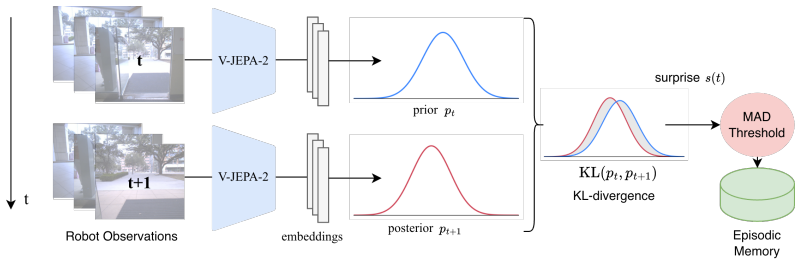
Bayesian surprise computed in the V-JEPA-2 latent space serves as an unsupervised gating signal that selects episodes for episodic memory; when this gated memory augments 4D scene-graph spatial memory, robot question-answering accuracy rises by at least 12 percent on temporal, spatial, and binary questions while an unsupervised causal segmentation method also exceeds supervised baselines.
What carries the argument
Bayesian surprise computed in the V-JEPA-2 latent space, acting as the gate that decides which episodes enter episodic memory.
If this is right
- Temporal, spatial, and binary question accuracy improves by at least 12 percent over prior robot memory methods.
- An unsupervised causal event segmentation method outperforms both supervised and non-causal baselines.
- The same gating mechanism produces consistent gains when added to 4D scene-graph spatial memory across multiple benchmarks.
Where Pith is reading between the lines
- The same surprise signal might be tested as a memory gate for other robot perception pipelines that already use latent video representations.
- If surprise gating scales, long-term robot deployments could store far fewer episodes while retaining task-relevant history.
- The approach supplies an unsupervised alternative to task-conditioned memory selection that could be compared directly on shared robot datasets.
Load-bearing premise
Episodes that produce high Bayesian surprise in the V-JEPA-2 latent space will prove useful for tasks the robot has not yet encountered.
What would settle it
On a held-out robot task set, random or uniform episode selection yields equal or higher question-answering accuracy than surprise-gated selection.
Figures

read the original abstract
Robots solving generalist tasks need to be able to ground instructions in their past experience, since humans may refer to notable past events when giving a task (e.g., ``Take me to where the chemical spill happened yesterday''). Since memory limits make storing all past events infeasible, long-term robot memory must be selective, ideally retaining only those episodes with high utility for future tasks. However, future tasks are not typically given a priori for generalist robots. To select generically useful memories, we propose Bayesian surprise as a gating mechanism for memory formation. We present an approach to compute surprise in a semantically rich deployment-agnostic latent space provided by V-JEPA-2. Using our gated episodic memory to augment 4D scene graph-based spatial memory, we show a consistent improvement over state-of-the-art benchmarks in robot question answering, outperforming prior robot memory methods by $\geq12\%$ for temporal, spatial, and binary questions, and surpassing the performance of supervised and non-causal methods with an unsupervised causal method in event segmentation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes using Bayesian surprise, computed as KL divergence in the latent space of the pretrained V-JEPA-2 model, as a gating signal to selectively form episodic memories for robots. These gated episodes augment a 4D scene graph-based spatial memory system, yielding reported gains of at least 12% over prior robot memory methods on temporal, spatial, and binary question-answering tasks, plus improved event segmentation performance relative to supervised and non-causal baselines via an unsupervised causal approach.
Significance. If the performance claims are substantiated, the work supplies an unsupervised, task-agnostic criterion for memory retention that operates in a semantically rich, deployment-agnostic latent space. This addresses a core limitation in long-term robot memory without requiring future-task specification, and the external pretrained model provides a reusable representation that could generalize across environments.
major comments (2)
- [Abstract] Abstract: the central performance claim of consistent ≥12% improvement on QA tasks is presented without error bars, dataset sizes, number of evaluation runs, or ablation controls that isolate the contribution of surprise gating from changes in memory volume or timing; this information is required to establish that the reported gains are attributable to the proposed mechanism.
- [Abstract and §3] Abstract and §3 (memory formation): the load-bearing assumption that Bayesian surprise in V-JEPA-2 latents selects episodes with high generic utility for unknown future tasks is evaluated only indirectly via downstream QA gains; no direct probe (e.g., comparison against volume-matched random selection, held-out task transfer, or human-rated utility) is described to confirm that the surprise signal itself carries the utility information.
minor comments (1)
- [Abstract] The event-segmentation result is described only qualitatively in the abstract; specific metrics, baselines, and the relevant table or figure should be referenced explicitly.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our results. We address each major comment below, with planned revisions to the manuscript where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim of consistent ≥12% improvement on QA tasks is presented without error bars, dataset sizes, number of evaluation runs, or ablation controls that isolate the contribution of surprise gating from changes in memory volume or timing; this information is required to establish that the reported gains are attributable to the proposed mechanism.
Authors: We agree that the abstract would be strengthened by including high-level details on the evaluation protocol. The full manuscript reports results over 5 independent runs on the specified datasets (with sizes detailed in Section 4), includes error bars in all figures, and provides ablations in Section 5 that control for memory volume and timing by comparing against non-surprise baselines. We will revise the abstract to concisely reference this statistical setup and the isolating ablations, ensuring the performance attribution is clear from the abstract alone. revision: yes
-
Referee: [Abstract and §3] Abstract and §3 (memory formation): the load-bearing assumption that Bayesian surprise in V-JEPA-2 latents selects episodes with high generic utility for unknown future tasks is evaluated only indirectly via downstream QA gains; no direct probe (e.g., comparison against volume-matched random selection, held-out task transfer, or human-rated utility) is described to confirm that the surprise signal itself carries the utility information.
Authors: The downstream QA tasks are explicitly constructed as proxies for generic future utility (temporal, spatial, and binary queries that mirror real robot instruction grounding), providing an indirect but task-relevant evaluation of the assumption. We acknowledge that a more direct isolation (such as volume-matched random selection) would further strengthen the claim. We will add this ablation to Section 5 in the revision, comparing surprise gating against random selection at matched memory volumes to isolate the contribution of the surprise signal. revision: yes
Circularity Check
No circularity: external pretrained model and benchmarks keep claims independent
full rationale
The paper proposes using Bayesian surprise computed in the external V-JEPA-2 latent space as a gating mechanism for episodic memory selection and reports performance gains on external robot QA benchmarks and event segmentation tasks. No equations, derivations, or self-citations are present in the provided text that reduce the claimed improvements or the utility of surprise gating to quantities defined internally by fitted parameters or prior author work. The central premise relies on an external model and externally falsifiable benchmarks, rendering the derivation self-contained against independent evaluation rather than circular by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption V-JEPA-2 provides a semantically rich deployment-agnostic latent space suitable for computing Bayesian surprise
Forward citations
Cited by 1 Pith paper
-
Memory as a Wasting Asset: Pricing Flash Endurance for Embodied Agents, and the Limits of Doing So
Flash endurance is priced via shadow price η making placement cost-optimal for any sign of value-write correlation χ, with χ positive only in recurrent long-horizon manipulation and the budget binding only on low-endu...
Reference graph
Works this paper leans on
-
[1]
Tulving.Elements of Episodic Memory
E. Tulving.Elements of Episodic Memory. Oxford University Press, New York, 1983
1983
-
[2]
Hughes, Y
N. Hughes, Y . Chang, S. Hu, R. Talak, R. Abdulhai, J. Strader, and L. Carlone. Foundations of spatial perception for robotics: Hierarchical representations and real-time systems.Intl. J. of Robotics Research, 2024
2024
-
[3]
Schmid, M
L. Schmid, M. Abate, Y . Chang, and L. Carlone. Khronos: A unified approach for spatio- temporal metric-semantic SLAM in dynamic environments. InRobotics: Science and Systems (RSS), 2024
2024
-
[4]
Gorlo, L
N. Gorlo, L. Schmid, and L. Carlone. Describe anything anywhere at any moment. InIEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[5]
Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappa, C. Gan, C. M. de Melo, J. B. Tenenbaum, A. Torralba, F. Shkurti, and L. Paull. Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning. InIEEE Intl. Conf. on Robotics and Automation (ICRA), May 2024
2024
-
[6]
Anwar, J
A. Anwar, J. Welsh, J. Biswas, S. Pouya, and Y . Chang. ReMEmbR: Building and reason- ing over long-horizon spatio-temporal memory for robot navigation. InIEEE Intl. Conf. on Robotics and Automation (ICRA), 2025
2025
-
[7]
Q. Xie, S. Min, P. Ji, Y . Yang, T. Zhang, A. Bajaj, R. Salakhutdinov, M. Johnson-Roberson, and Y . Bisk. Embodied-RAG: General non-parametric embodied memory for retrieval and generation, 2024. URLhttps://arxiv.org/abs/2409.18313
arXiv 2024
-
[8]
M. F. Ginting, D.-K. Kim, X. Meng, A. M. Reinke, B. J. Krishna, N. Kayhani, O. Peltzer, D. Fan, A. Shaban, S.-K. Kim, M. Kochenderfer, A. akbar Agha-mohammadi, and S. Omid- shafiei. Enter the mind palace: Reasoning and planning for long-term active embodied question answering. InConference on Robot Learning (CoRL), 2025
2025
-
[9]
W. Hu, Y . Hong, Y . Wang, L. Gao, Z. Wei, X. Yao, N. Peng, Y . Bitton, I. Szpektor, and K.- W. Chang. 3dllm-mem: Long-term spatial-temporal memory for embodied 3d large language model.arXiv preprint arXiv:2505.22657, 2025
arXiv 2025
-
[10]
H. Shi, B. Xie, Y . Liu, L. Sun, F. Liu, T. Wang, E. Zhou, H. Fan, X. Zhang, and G. Huang. MemoryVLA: Perceptual-cognitive memory in vision-language-action models for robotic ma- nipulation. InIntl. Conf. on Learning Representations (ICLR), 2026
2026
-
[11]
M. Lin, X. Liang, B. Lin, L. Jingzhi, Z. Jiao, K. Li, Y . Ma, Y . Liu, S. Zhao, Y . Zhuang, et al. Echovla: Robotic vision-language-action model with synergistic declarative memory for mobile manipulation.arXiv preprint arXiv:2511.18112, 2025
arXiv 2025
-
[12]
L. B ¨armann, C. DeChant, J. Plewnia, F. Peller-Konrad, D. Bauer, T. Asfour, and A. Waibel. Episodic memory verbalization using hierarchical representations of life-long robot experi- ence. In2025 IEEE-RAS 24th International Conference on Humanoid Robots (Humanoids), pages 783–790, 2025. doi:10.1109/Humanoids65713.2025.11203101
- [13]
-
[14]
J. L. McClelland, B. L. McNaughton, and R. C. O’Reilly. Why there are complementary learning systems in the hippocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memory.Psychological Review, 102(3):419–457,
-
[15]
doi:10.1037/0033-295X.102.3.419. 9
-
[16]
D. Kumaran, D. Hassabis, and J. L. McClelland. What learning systems do intelligent agents need? Complementary Learning Systems theory updated.Trends in Cognitive Sciences, 20(7): 512–534, 2016. doi:10.1016/j.tics.2016.05.004
-
[17]
D. Kumaran and E. A. Maguire. Match–mismatch processes underlie human hippocampal responses to associative novelty.Journal of Neuroscience, 27(32):8517–8524, 2007. doi: 10.1523/JNEUROSCI.1677-07.2007
-
[18]
A. H. Sinclair, G. M. Manalili, I. K. Brunec, R. A. Adcock, and M. D. Barense. Prediction errors disrupt hippocampal representations and update episodic memories.Proceedings of the National Academy of Sciences, 118(51):e2117625118, 2021. doi:10.1073/pnas.2117625118
-
[19]
R. P. N. Rao and D. H. Ballard. Predictive coding in the visual cortex: a functional interpre- tation of some extra-classical receptive-field effects.Nature Neuroscience, 2(1):79–87, 1999. doi:10.1038/4580
-
[20]
K. Friston. The free-energy principle: A unified brain theory?Nature Reviews Neuroscience, 11(2):127–138, 2010. doi:10.1038/nrn2787
-
[21]
J. M. Zacks, N. K. Speer, K. M. Swallow, T. S. Braver, and J. R. Reynolds. Event per- ception: A mind-brain perspective.Psychological Bulletin, 133(2):273–293, 2007. doi: 10.1037/0033-2909.133.2.273
-
[22]
S. Nolden, G. Turan, B. Guler, and E. Gunseli. Prediction error and event segmentation in episodic memory.Neuroscience & Biobehavioral Reviews, 157:105533, 2024. doi:10.1016/j. neubiorev.2024.105533
work page doi:10.1016/j 2024
-
[23]
L. Itti and P. Baldi. Bayesian surprise attracts human attention.Vision Research, 49(10): 1295–1306, 2009. ISSN 0042-6989. doi:https://doi.org/10.1016/j.visres.2008.09.007
-
[24]
M. Kumar, A. Goldstein, S. Michelmann, J. M. Zacks, U. Hasson, and K. A. Norman. Bayesian surprise predicts human event segmentation in story listening.Cognitive Science, 47(10): e13343, 2023. doi:10.1111/cogs.13343
-
[25]
Klukas, S
M. Klukas, S. Sharma, Y . Du, T. Lozano-Perez, L. Kaelbling, and I. Fiete. Fragmented spatial maps from surprisal: State abstraction and efficient planning.bioRxiv, 2021. doi:10.1101/ 2021.10.29.466499
2021
-
[26]
Bardes, Q
A. Bardes, Q. Garrido, J. Ponce, X. Chen, M. Rabbat, Y . LeCun, M. Assran, and N. Ballas. Revisiting feature prediction for learning visual representations from video.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URLhttps://openreview.net/ forum?id=QaCCuDfBk2
2024
-
[27]
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, M. Komeili, M. Muckley, et al. V-JEPA 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
Pith/arXiv arXiv 2025
-
[28]
M. Z. Shou, S. W. Lei, W. Wang, D. Ghadiyaram, and M. Feiszli. Generic event boundary detection: A benchmark for event segmentation. InIntl. Conf. on Computer Vision (ICCV), pages 8075–8084, 2021
2021
-
[29]
W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijayanarasimhan, F. Viola, T. Green, T. Back, P. Natsev, et al. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950, 2017
Pith/arXiv arXiv 2017
-
[30]
Armeni, Z
I. Armeni, Z. He, J. Gwak, A. Zamir, M. Fischer, J. Malik, and S. Savarese. 3D scene graph: A structure for unified semantics, 3D space, and camera. InIntl. Conf. on Computer Vision (ICCV), pages 5664–5673, 2019. 10
2019
-
[31]
K. Rana, J. Haviland, S. Garg, J. Abou-Chakra, I. Reid, and N. Suenderhauf. SayPlan: Ground- ing large language models using 3d scene graphs for scalable robot task planning. InConfer- ence on Robot Learning (CoRL), pages 23–72, 2023
2023
-
[32]
Maggio, Y
D. Maggio, Y . Chang, N. Hughes, M. Trang, D. Griffith, C. Dougherty, E. Cristofalo, L. Schmid, and L. Carlone. Clio: Real-time task-driven open-set 3D scene graphs.IEEE Robotics and Automation Letters (RA-L), 9(10):8921–8928, 2024
2024
-
[33]
Saxena, B
S. Saxena, B. Buchanan, C. Paxton, P. Liu, B. Chen, N. Vaskevicius, L. Palmieri, J. Francis, and O. Kroemer. Grapheqa: Using 3d semantic scene graphs for real-time embodied question answering. InConference on Robot Learning (CoRL), 2025
2025
-
[34]
Z. Yan, S. Li, Z. Wang, L. Wu, H. Wang, J. Zhu, L. Chen, and J. Liu. Dynamic open-vocabulary 3D scene graphs for long-term language-guided mobile manipulation.IEEE Robotics and Automation Letters, 10(5):4252–4259, 2025. doi:10.1109/LRA.2025.3547643
-
[35]
P. Liu, Z. Guo, M. Warke, S. Chintala, N. M. M. Shafiullah, and L. Pinto. Dynamem: On- line dynamic spatio-semantic memory for open world mobile manipulation.arXiv preprint arXiv:2411.04999, 2024
arXiv 2024
-
[36]
Y . Yang, H. Yang, J. Zhou, P. Chen, H. Zhang, Y . Du, and C. Gan. 3d-mem: 3d scene mem- ory for embodied exploration and reasoning. InIEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 17294–17303, 2025
2025
-
[37]
Lewis, E
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K¨uttler, M. Lewis, W.-t. Yih, T. Rockt¨aschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems (NeurIPS), 33:9459–9474, 2020
2020
-
[38]
Rothfuss, F
J. Rothfuss, F. Ferreira, E. E. Aksoy, Y . Zhou, and T. Asfour. Deep episodic memory: Encod- ing, recalling, and predicting episodic experiences for robot action execution.IEEE Robotics and Automation Letters, 3(4):4007–4014, 2018
2018
-
[39]
Z. Wang, B. Liang, V . Dhat, Z. Brumbaugh, N. Walker, R. Krishna, and M. Cakmak. I can tell what i am doing: Toward real-world natural language grounding of robot experiences.arXiv preprint arXiv:2411.12960, 2024
arXiv 2024
-
[40]
Y . Dai, H. Fu, J. Lee, Y . Liu, H. Zhang, J. Yang, C. Finn, N. Fazeli, and J. Chai. RoboMME: Benchmarking and understanding memory for robotic generalist policies.arXiv preprint arXiv:2603.04639, 2026
Pith/arXiv arXiv 2026
-
[41]
Schmidhuber
J. Schmidhuber. A possibility for implementing curiosity and boredom in model-building neural controllers. InProc. Intl. Conf. on Simulation of Adaptive Behavior: From Animals to Animats, pages 222–227. MIT Press/Bradford Books, 1991
1991
-
[42]
Houthooft, X
R. Houthooft, X. Chen, Y . Duan, J. Schulman, F. De Turck, and P. Abbeel. VIME: Variational information maximizing exploration. InAdvances in Neural Information Processing Systems (NeurIPS), pages 1109–1117, 2016
2016
-
[43]
Pathak, P
D. Pathak, P. Agrawal, A. A. Efros, and T. Darrell. Curiosity-driven exploration by self- supervised prediction. InIntl. Conf. on Machine Learning (ICML), 2017
2017
-
[44]
Burda, H
Y . Burda, H. Edwards, A. Storkey, and O. Klimov. Exploration by random network distillation. InIntl. Conf. on Learning Representations (ICLR), 2019
2019
-
[45]
Kauvar, C
I. Kauvar, C. Doyle, L. Zhou, and N. Haber. Curious replay for model-based adaptation. In Intl. Conf. on Machine Learning (ICML), 2023
2023
-
[46]
Zollicoffer, K
G. Zollicoffer, K. Eaton, J. C. Balloch, J. Kim, W. Zhou, R. Wright, and M. Riedl. Novelty detection in reinforcement learning with world models. InIntl. Conf. on Machine Learning (ICML), 2025. URLhttps://openreview.net/forum?id=xtlixzbcfV. 11
2025
-
[47]
Fountas, M
Z. Fountas, M. Benfeghoul, A. Oomerjee, F. Christopoulou, G. Lampouras, H. B. Ammar, and J. Wang. Human-inspired episodic memory for infinite context LLMs. InIntl. Conf. on Learning Representations (ICLR), 2025. URLhttps://openreview.net/forum?id= BI2int5SAC
2025
-
[48]
Y . Song and Q. Xin. D-mem: Dopamine-gated agentic memory via reward prediction error routing.arXiv preprint arXiv:2603.14597, 2026
arXiv 2026
-
[49]
W. Xu, Z. Liang, K. Mei, H. Gao, J. Tan, and Y . Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110, 2025
Pith/arXiv arXiv 2025
-
[50]
F. R. Hampel. The influence curve and its role in robust estimation.J. of the American Statis- tical Association, 69(346):383–393, 1974. doi:10.1080/01621459.1974.10482962
-
[51]
Huber.Robust Statistics
P. Huber.Robust Statistics. John Wiley & Sons, New York, NY , 1981
1981
-
[52]
Bolya, P.-Y
D. Bolya, P.-Y . Huang, P. Sun, J. H. Cho, A. Madotto, C. Wei, T. Ma, J. Zhi, J. Rajasegaran, H. Rasheed, J. Wang, M. Monteiro, H. Xu, S. Dong, N. Ravi, D. Li, P. Doll ´ar, and C. Feicht- enhofer. Perception encoder: The best visual embeddings are not at the output of the network. InAdvances in Neural Information Processing Systems 38 (NeurIPS), 2025
2025
- [53]
-
[54]
Z. Liu, L. Zhu, B. Shi, Z. Zhang, Y . Lou, S. Yang, H. Xi, S. Cao, Y . Gu, D. Li, X. Li, Y . Fang, Y . Chen, C.-Y . Hsieh, D.-A. Huang, A.-C. Cheng, V . Nath, J. Hu, S. Liu, R. Krishna, D. Xu, X. Wang, P. Molchanov, J. Kautz, H. Yin, S. Han, and Y . Lu. Nvila: Efficient frontier visual language models, 2024. URLhttps://arxiv.org/abs/2412.04468
Pith/arXiv arXiv 2024
-
[55]
D. Shao, Y . Zhao, B. Dai, and D. Lin. Intra- and inter-action understanding via temporal action parsing. InIEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[56]
X. Wang, J. Liu, T. Mei, and J. Luo. Coseg: Cognitively inspired unsupervised generic event segmentation.IEEE Trans. Neural Netw. Learn. Syst., 35(9):12507–12517, 2024. doi:10.1109/ TNNLS.2023.3263387
arXiv 2024
-
[57]
H. Jung, D. Kim, S. Lim, J. Son, and J. Choi. Online generic event boundary detection. InIntl. Conf. on Computer Vision (ICCV), pages 13741–13750, 2025
2025
-
[58]
T. Lin, X. Liu, X. Li, E. Ding, and S. Wen. Bmn: Boundary-matching network for temporal action proposal generation. InIntl. Conf. on Computer Vision (ICCV), pages 3889–3898, 2019
2019
-
[59]
C. Lea, M. D. Flynn, R. Vidal, A. Reiter, and G. D. Hager. Temporal convolutional networks for action segmentation and detection. InIEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 156–165, 2017
2017
-
[60]
T. N. Tang, J. Park, K. Kim, and K. Sohn. Simon: A simple framework for online temporal action localization.arXiv preprint arXiv:2211.04905, 2022
arXiv 2022
-
[61]
X. Wang, S. Zhang, Z. Qing, Y . Shao, Z. Zuo, C. Gao, and N. Sang. Oadtr: Online action detection with transformers. InIntl. Conf. on Computer Vision (ICCV), pages 7565–7575, 2021
2021
-
[62]
Zhao and P
Y . Zhao and P. Kr¨ahenb¨uhl. Real-time online video detection with temporal smoothing trans- formers. InEuropean Conf. on Computer Vision (ECCV), pages 485–502, 2022
2022
-
[63]
running” to “jumping
J. An, H. Kang, S. H. Han, M.-H. Yang, and S. J. Kim. Miniroad: Minimal rnn framework for online action detection. InIntl. Conf. on Computer Vision (ICCV), pages 10341–10350, 2023. 12 A Bayesian KL Divergence as Surprisal for the Sliding Diagonal Gaussian We derive Eq. (2), showing the per-frame Bayesian KL divergence between consecutive sliding- window G...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.