AlignAtt4LLM: Fast AlignAtt for Decoder-Only LLMs at IWSLT 2026 Simultaneous Speech Translation Task
Pith reviewed 2026-06-28 10:28 UTC · model grok-4.3
The pith
AlignAtt4LLM recovers a usable AlignAtt policy for decoder-only LLMs via prompt source spans and selected alignment heads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
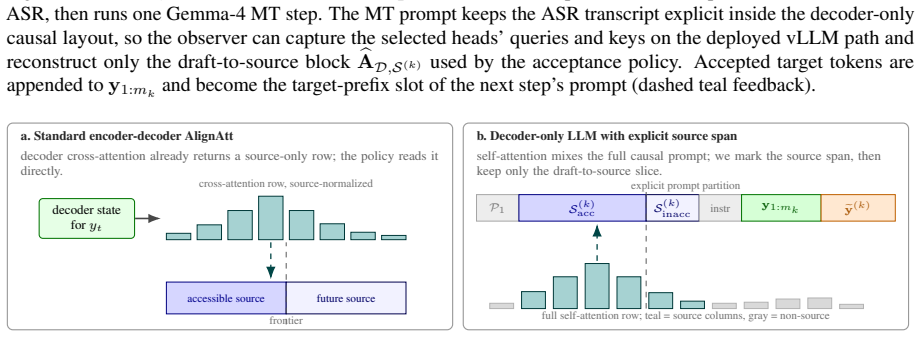
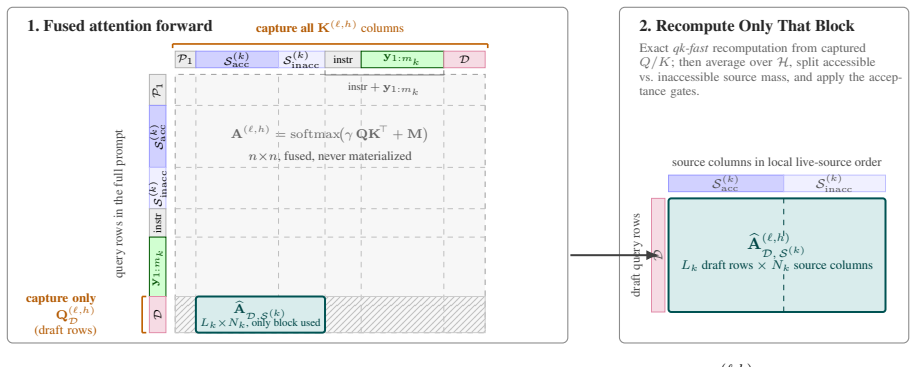
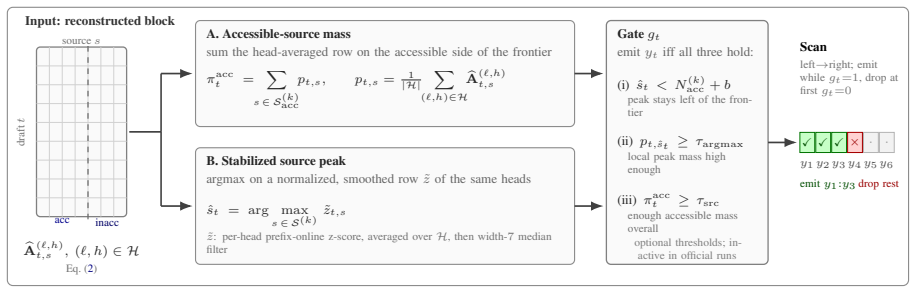
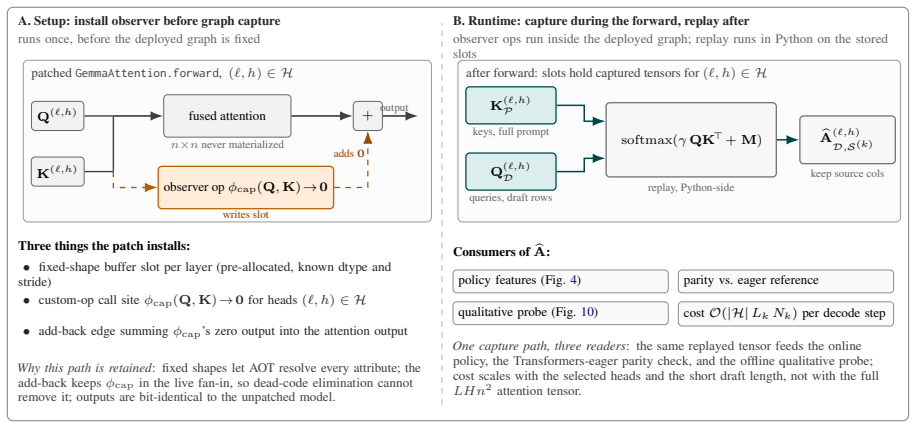
AlignAtt4LLM is the first reported use of AlignAtt on a decoder-only LLM. The system runs Qwen3-ASR with forced alignment to produce an incrementally updated source transcript and then applies Gemma-4 under an MT-side AlignAtt policy recovered by (1) inserting an explicit source span into the prompt, (2) offline selection of translation-specific alignment heads, (3) selective qk-fast replay of the draft-to-source attention block, and (4) runtime query/key capture that leaves model outputs bit-identical. The resulting policy outperforms the IWSLT 2026 baselines for English-German and English-Italian in both the low-latency regime near two seconds and the high-latency regime below four seconds
What carries the argument
The adapted AlignAtt policy recovered through an explicit source span in the prompt, offline-selected translation-specific alignment heads, selective qk-fast replay of the draft-to-source attention block, and runtime query/key capture.
If this is right
- The system outperforms supplied baselines for English to German and English to Italian in both the low-latency regime near two seconds and the high-latency regime below four seconds.
- The same policy can be reapplied to stronger translation-focused decoder-only MT backbones.
- The method is not tied to Gemma-4 and requires only a deterministic prompt layout, calibrated attention heads, and query/key capture.
- Results for English to Chinese are more mixed.
Where Pith is reading between the lines
- The same four adaptations could be tested on other decoder-only translation models to check whether the performance gain generalizes beyond Gemma-4.
- The approach might be combined with larger or domain-fine-tuned LLMs to improve quality at the same latency targets.
- If the offline head selection step proves stable across language pairs, it could reduce the engineering cost of deploying AlignAtt on new decoder-only backbones.
Load-bearing premise
The four listed adaptations together suffice to recover a usable AlignAtt-style policy even though the model has no encoder-decoder cross-attention.
What would settle it
If AlignAtt4LLM does not outperform the supplied baselines on the IWSLT 2026 development set for English to German or English to Italian in the regimes around two seconds and below four seconds, the performance claim is falsified.
Figures





read the original abstract
We describe AlignAtt4LLM, an IWSLT 2026 simultaneous speech translation system for English to German, Italian, and Chinese. The system is a synchronous cascade: Qwen3-ASR with forced alignment produces an incrementally updated source transcript, and Gemma-4 E4B-it translates that prefix under an MT-side AlignAtt policy. To our knowledge, this is the first application of AlignAtt to a decoder-only LLM, where the encoder-decoder cross-attention used by earlier AlignAtt systems is absent. We recover a usable policy by proposing (1) an explicit source span in the prompt, (2) offline selection of translation-specific alignment heads, (3) selective qk-fast replay of the draft-to-source attention block, and (4) runtime query/key capture that preserves model outputs bit-identically. On the IWSLT 2026 development set, AlignAtt4LLM outperforms the supplied baselines for the European target languages, English to German and English to Italian, in both the low-latency regime around 2 seconds and the high-latency regime below 4 seconds CU-LongYAAL. Results for English to Chinese are more mixed, but the method is not tied to Gemma-4: because AlignAtt4LLM only requires a deterministic prompt layout, calibrated attention heads, and query/key capture, the same policy can be reapplied to stronger translation-focused decoder-only MT backbones for non-European target languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents AlignAtt4LLM, the first adaptation of AlignAtt to decoder-only LLMs for the IWSLT 2026 simultaneous speech translation task. It describes a synchronous cascade using Qwen3-ASR with forced alignment followed by Gemma-4 E4B-it translation under an MT-side AlignAtt policy. Four adaptations are proposed to recover an AlignAtt-style policy without encoder-decoder cross-attention: (1) explicit source span in the prompt, (2) offline selection of translation-specific alignment heads, (3) selective qk-fast replay of the draft-to-source attention block, and (4) runtime query/key capture preserving outputs bit-identically. The central empirical claim is that the system outperforms supplied baselines on the IWSLT 2026 development set for English-to-German and English-to-Italian in both the ~2s low-latency and <4s high-latency regimes under the CU-LongYAAL metric; results for English-to-Chinese are mixed, with the method presented as generalizable to other decoder-only backbones.
Significance. If the empirical results hold with proper statistical support, the work would be significant for enabling alignment-based simultaneous translation policies in decoder-only LLMs, which are increasingly dominant in MT. The explicit generality claim—that the policy depends only on deterministic prompt layout, calibrated heads, and query/key capture—is a strength, as is the focus on bit-identical output preservation. These elements support potential reuse on stronger translation-focused models.
major comments (2)
- [Abstract] Abstract: the claim that AlignAtt4LLM 'outperforms the supplied baselines' for En-De and En-It is presented without any quantitative results, error bars, statistical tests, or details on development-set usage or baseline definitions. This directly undermines evaluation of the central empirical claim.
- [Adaptations section] Description of the four adaptations (explicit source span, offline head selection, qk-fast replay, runtime capture): the central claim that these adaptations are jointly sufficient to recover a usable AlignAtt-style policy rests on the assumption that selected heads track source prefixes and that qk-fast replay preserves alignment behavior. No ablation studies, attention-map analysis, or verification that the induced policy matches original AlignAtt behavior are referenced, leaving open the possibility that reported gains arise from prompt layout or model choice rather than the recovered policy.
minor comments (2)
- [Abstract] The metric CU-LongYAAL is used without definition or reference in the abstract; a brief parenthetical or citation would improve clarity.
- [Abstract] The manuscript states results are 'more mixed' for English-to-Chinese but provides no further detail on the nature of the mixed outcomes.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on the manuscript. We address each major comment below and indicate where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that AlignAtt4LLM 'outperforms the supplied baselines' for En-De and En-It is presented without any quantitative results, error bars, statistical tests, or details on development-set usage or baseline definitions. This directly undermines evaluation of the central empirical claim.
Authors: We agree that the abstract would benefit from quantitative support to allow readers to evaluate the central claim. In the revised version, we will update the abstract to include specific performance metrics (e.g., CU-LongYAAL improvements and latency values for En-De and En-It on the IWSLT 2026 development set), clarify the baseline definitions, and note that results are reported under the supplied evaluation protocol. revision: yes
-
Referee: [Adaptations section] Description of the four adaptations (explicit source span, offline head selection, qk-fast replay, runtime capture): the central claim that these adaptations are jointly sufficient to recover a usable AlignAtt-style policy rests on the assumption that selected heads track source prefixes and that qk-fast replay preserves alignment behavior. No ablation studies, attention-map analysis, or verification that the induced policy matches original AlignAtt behavior are referenced, leaving open the possibility that reported gains arise from prompt layout or model choice rather than the recovered policy.
Authors: We acknowledge the absence of ablation studies or attention-map analysis in the current manuscript. The empirical outperformance on the development set for En-De and En-It provides indirect support for the adaptations, and the bit-identical output preservation ensures faithful implementation. To directly address the concern, we will add a brief verification subsection in the revision that includes sample attention pattern comparisons confirming that the selected heads track source prefixes as intended. revision: yes
Circularity Check
No circularity: empirical engineering adaptation validated externally
full rationale
The paper presents an engineering adaptation of AlignAtt to decoder-only LLMs via four listed techniques (explicit source span, offline head selection, qk-fast replay, runtime capture). Performance is reported as direct comparison to supplied external baselines on IWSLT 2026 dev sets for En-De/En-It. No equations, no fitted parameters renamed as predictions, no derivation chain, and no self-citation invoked as a uniqueness theorem or load-bearing premise. The central claim reduces to measured latency-quality tradeoffs against independent references, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 23rd In- ternational Conference on Spoken Language Trans- 8 lation (IWSLT 2026), San Diego, California, US
Speech translation and metrics in 2026: Findings of the IWSLT campaign. InProceedings of the 23rd In- ternational Conference on Spoken Language Trans- 8 lation (IWSLT 2026), San Diego, California, US. As- sociation for Computational Linguistics. Marco Gaido, Sara Papi, Mauro Cettolo, Matteo Ne- gri, and Luisa Bentivogli
2026
-
[2]
Simulstream: Open-source toolkit for evaluation and demonstra- tion of streaming speech-to-text translation systems. Preprint, arXiv:2512.17648. Google DeepMind
-
[3]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Ef- ficient memory management for large language model serving with PagedAttention.Preprint, arXiv:2309.06180. Binbin Liu, Wenhan Han, Feng Chen, Yifan Zhang, Ping Guo, Haobin Lin, Bingni Zhang, Taifeng Wang, and Yin Zheng
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
ICLR 2026 poster, OpenReview
Token alignment heads: Unveil- ing attention’s role in LLM multilingual translation. ICLR 2026 poster, OpenReview. Dominik Macháˇcek and Peter Polák
2026
-
[5]
Association for Computational Lin- guistics
InProceed- ings of the 22nd International Conference on Spoken Language Translation (IWSLT 2025), pages 389–398, Vienna, Austria. Association for Computational Lin- guistics. OpenAI
2025
-
[6]
InProceedings of Interspeech 2023, pages 3974–3978
Alig- nAtt: Using attention-based audio-translation align- ments as a guide for simultaneous speech transla- tion. InProceedings of Interspeech 2023, pages 3974–3978. Kishore Papineni, Salim Roukos, Todd Ward, and Wei- Jing Zhu
2023
-
[7]
Better late than never: Meta-evaluation of latency metrics for simultaneous speech-to-text translation.Preprint, arXiv:2509.17349. Peter Polák, Ngoc-Quan Pham, Tuan Nam Nguyen, Danni Liu, Carlos Mullov, Jan Niehues, Ondˇrej Bo- jar, and Alexander Waibel
-
[8]
Association for Computational Linguis- tics
InProceedings of the 19th International Con- ference on Spoken Language Translation (IWSLT 2022), pages 277–285, Dublin, Ireland (in-person and online). Association for Computational Linguis- tics. Peter Polák, Brian Yan, Shinji Watanabe, Alex Waibel, and Ond ˇrej Bojar
2022
-
[9]
Incremental Blockwise Beam Search for Simultaneous Speech Translation with Controllable Quality-Latency Tradeoff. InProc. INTERSPEECH 2023, pages 3979–3983. Maja Popovi´c
2023
-
[10]
Scaling model and data for multi- lingual machine translation with open large language models.Preprint, arXiv:2602.11961. Xian Shi, Xiong Wang, Zhifang Guo, Yongqi Wang, Pei Zhang, Xinyu Zhang, Zishan Guo, Hongkun Hao, Yu Xi, Baosong Yang, Jin Xu, Jingren Zhou, and Junyang Lin
-
[11]
Qwen3-ASR technical report. Preprint, arXiv:2601.21337. Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
RoFormer: Enhanced Transformer with Rotary Position Embedding
RoFormer: En- hanced transformer with rotary position embedding. Preprint, arXiv:2104.09864. 9 Mao Zheng, Zheng Li, Tao Chen, Mingyang Song, and Di Wang
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
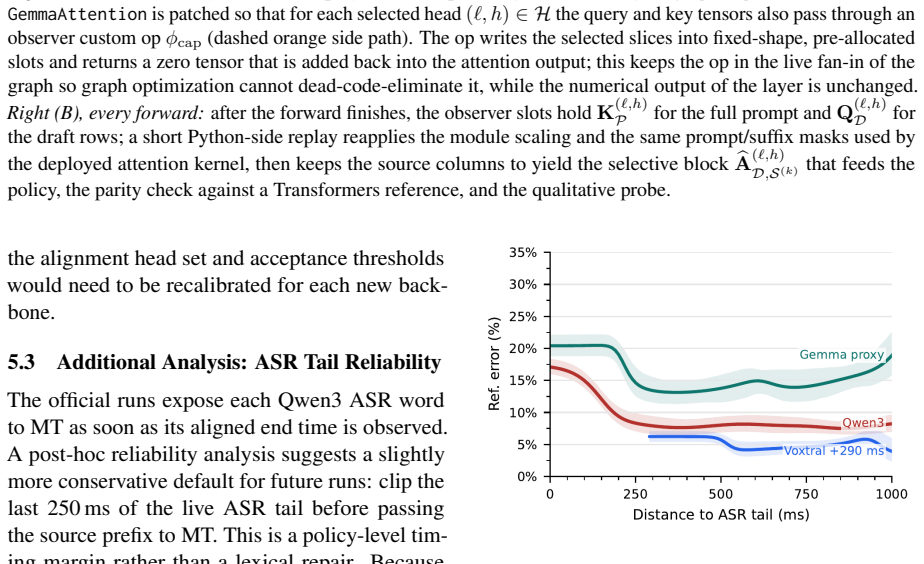
HY-MT1.5 technical report. Preprint, arXiv:2512.24092. A Additional ASR Analysis The analysis below justifies the source ASR front end used by the cascade and the recommended source-tail default for future runs. ASR front-end selection.We tested three ASR front ends during development: Qwen3-ASR with the Qwen3 forced aligner, V oxtral Realtime 4B, and a d...
-
[14]
Pair Top-8 TS All-336 TS Gain Aligned tokens EN→DE 90.40 68.49+21.9111,209 EN→ZH 93.48 65.79+27.707,582 EN→IT 91.90 67.42+24.4912,056 Table 4:MT head-set filtering ablation on held-out word-aligned dev examples.Scores are reported in points (100×TS) against gold aligned source tokens. D Observer Replay and Qualitative Diagnostics Below we report the promp...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.