The Variance Brain Foundation Models Forgot: Third-Order Statistics Predict Cognition Where Billion-Parameter Models Fail
Pith reviewed 2026-06-28 19:05 UTC · model grok-4.3
The pith
Brain foundation models predict cognition worse than linear functional connectivity because pretraining destroys third-order co-skewness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
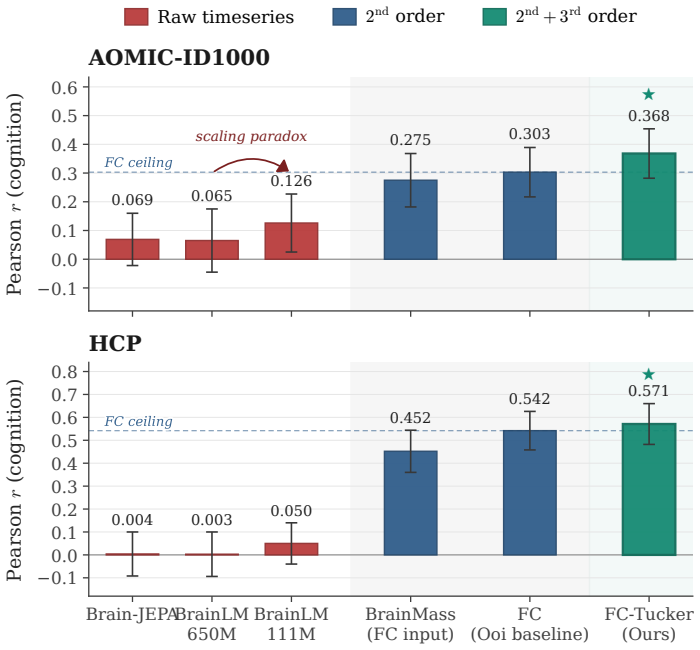
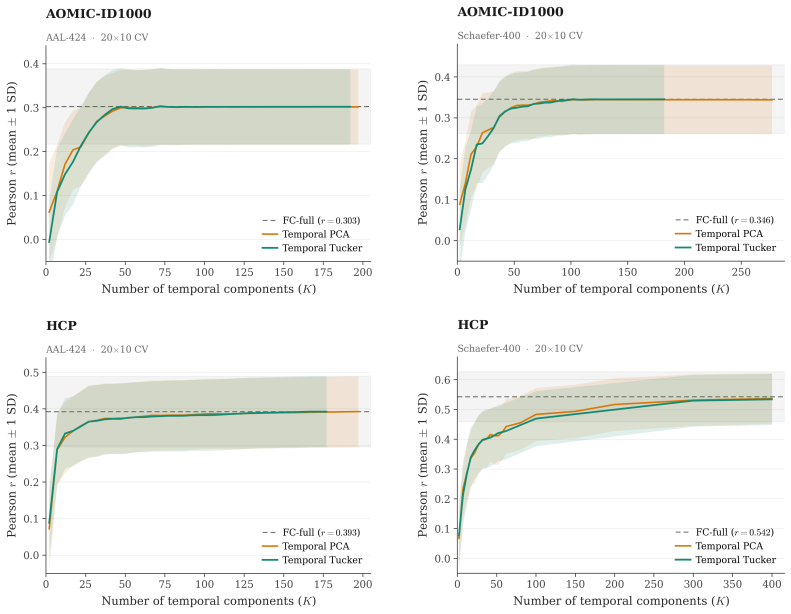
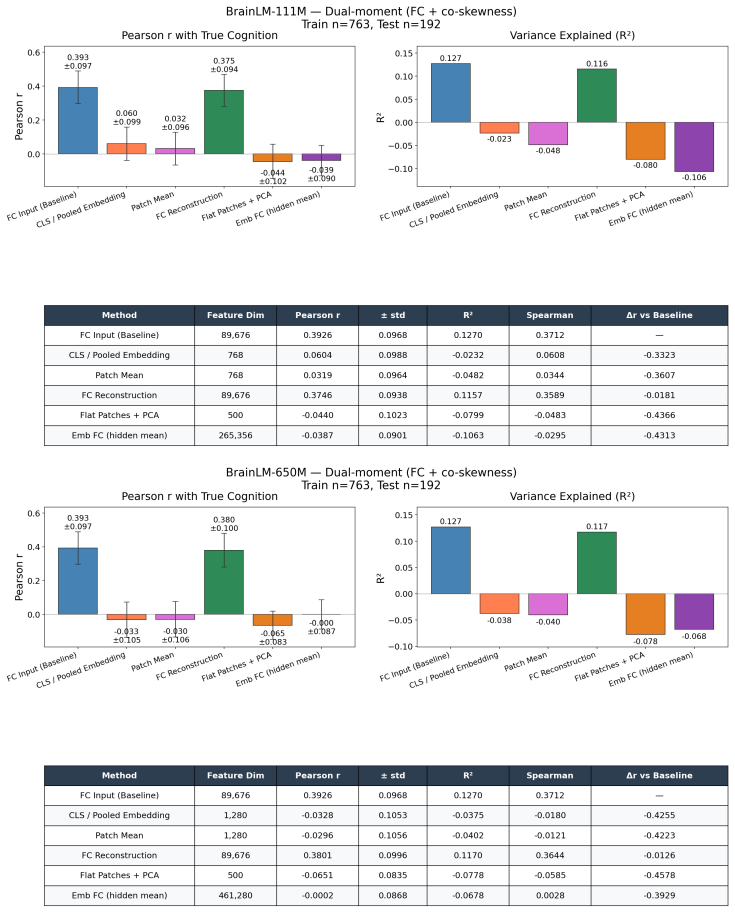
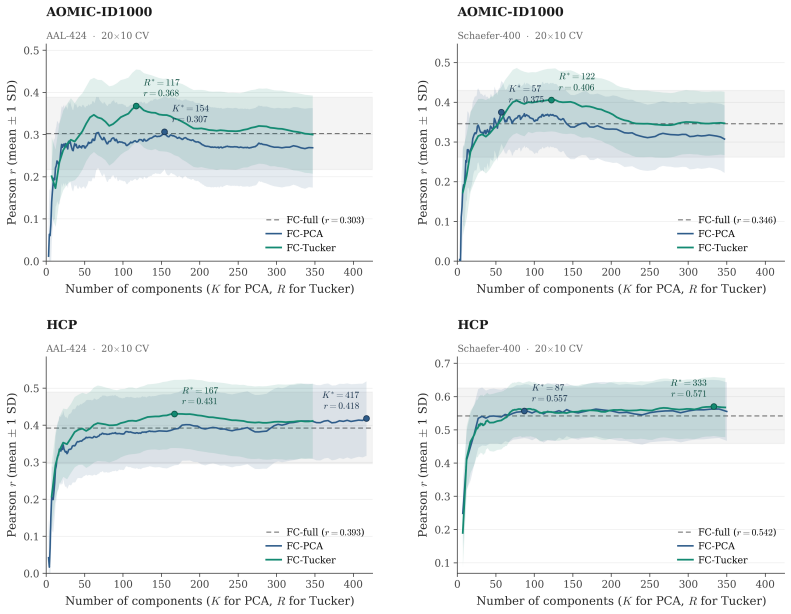
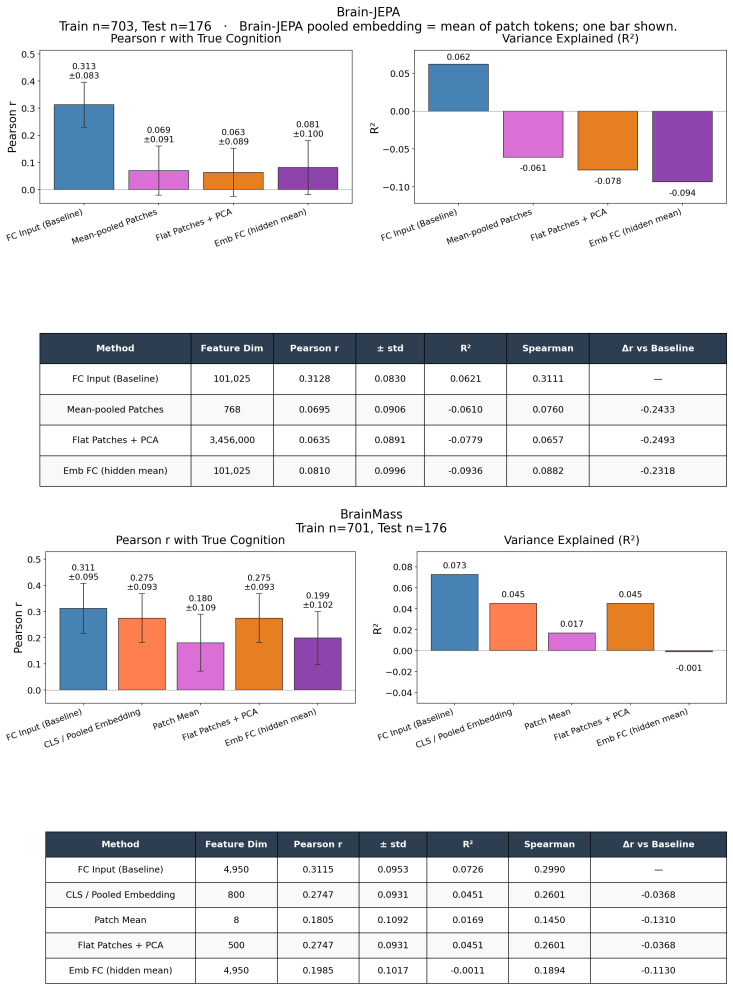
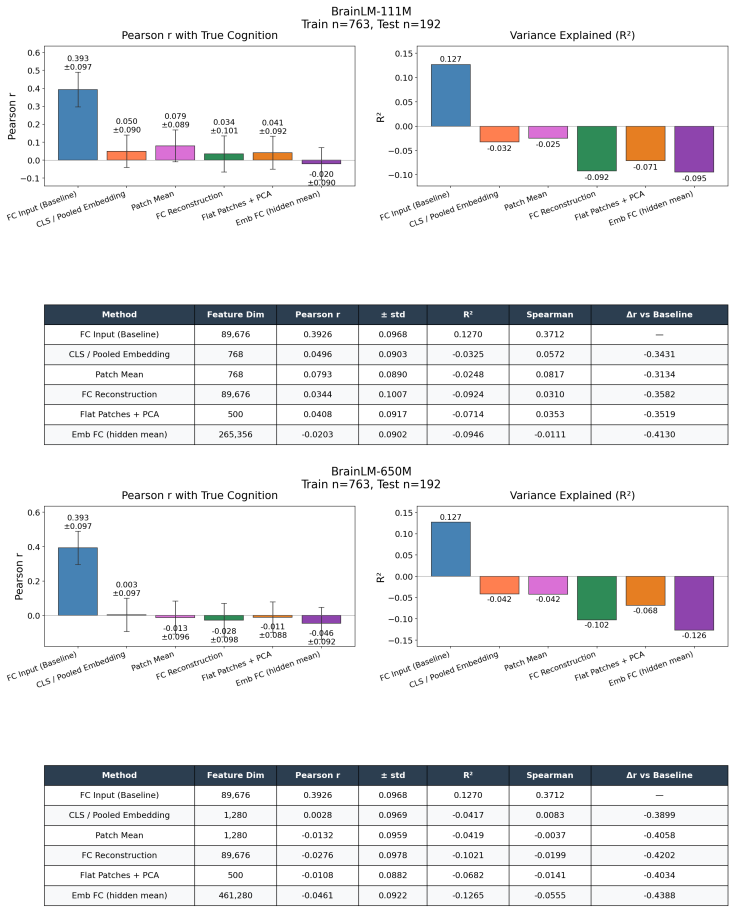
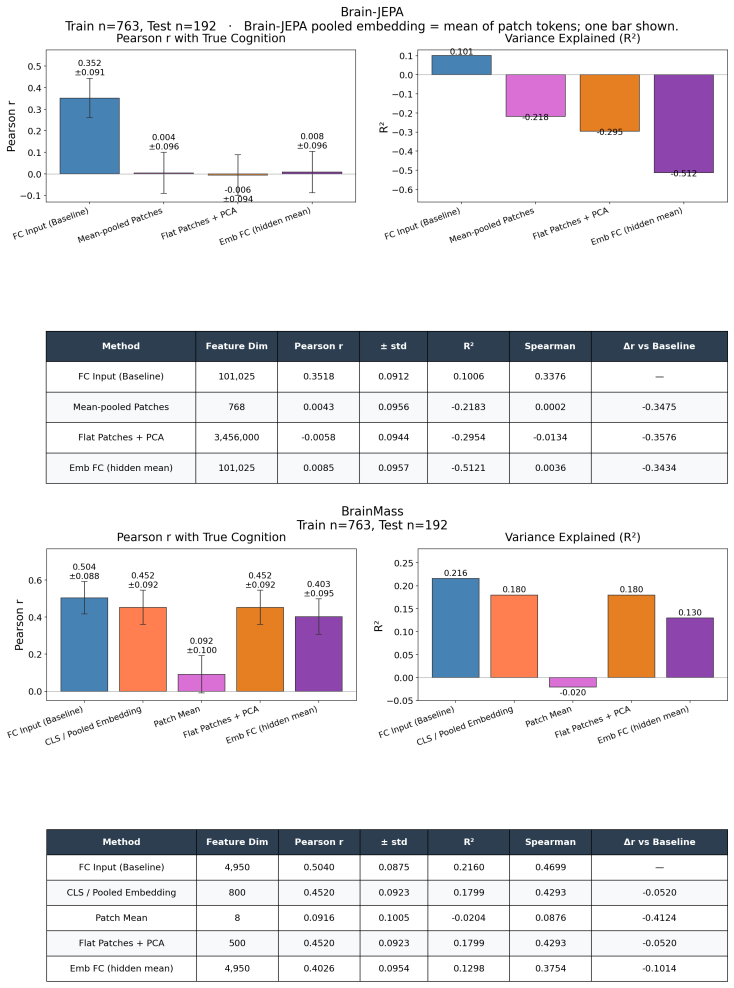
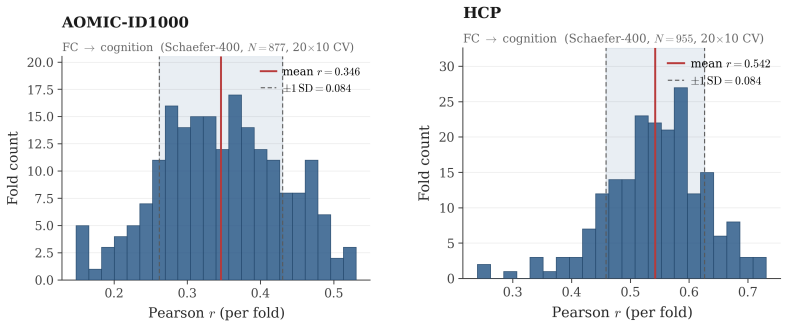
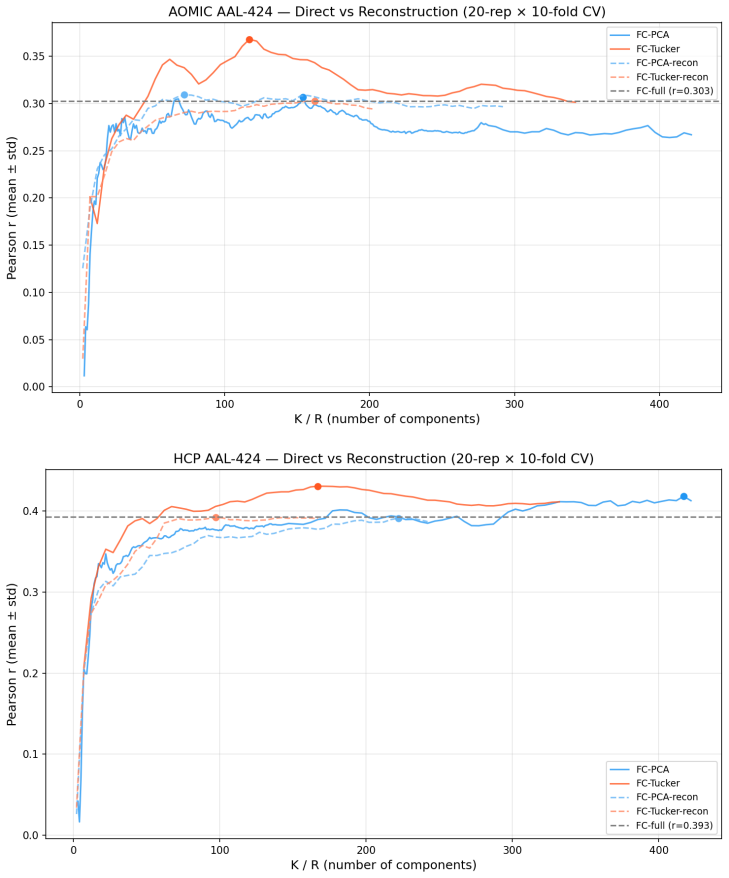
Brain foundation models pretrained on fMRI capture the dominant variance components but discard the co-skewness tensor that carries cognitive information. Per-cumulant comparison of original and reconstructed signals confirms partial preservation of second-order statistics alongside near-total loss of third-order structure. Projecting the signal into the co-skewness-preserving subspace and computing functional connectivity in that space produces predictions that surpass both the raw connectivity matrix and every pretrained model tested.
What carries the argument
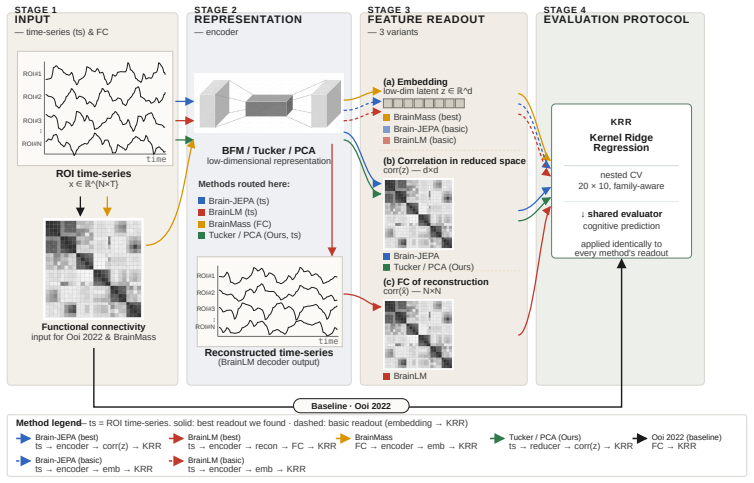
The co-skewness-preserving subspace projection, which selects directions in the fMRI signal that retain third-order moments before computing functional connectivity.
If this is right
- Larger BFMs predict cognition more poorly than smaller ones when evaluated on the same readouts.
- Finetuning any BFM with a loss that targets the co-skewness subspace recovers performance up to the raw-FC ceiling.
- The performance limit in current BFMs is set by the pretraining objective, not parameter count or Transformer architecture.
- A linear pipeline using the co-skewness subspace outperforms prior state-of-the-art cognitive prediction methods on every tested dataset and parcellation.
Where Pith is reading between the lines
- Future self-supervised objectives for fMRI should explicitly regularize or reconstruct higher-order moments rather than variance alone.
- The result raises the possibility that cognitive signals in brain data live primarily in non-Gaussian structure, which standard variance-based pretraining discards by design.
- Similar variance-allocation problems may appear in other high-dimensional time-series domains where second-order statistics dominate the training loss.
Load-bearing premise
The subspace that best preserves co-skewness is the one that also holds the information relevant for predicting cognition, and the per-cumulant breakdown reflects genuine loss rather than selection artifacts.
What would settle it
A controlled test in which BFMs are finetuned with an explicit co-skewness preservation loss yet still fail to match the linear subspace method on held-out cognitive prediction tasks would falsify the claim that the pretraining objective is the decisive bottleneck.
Figures
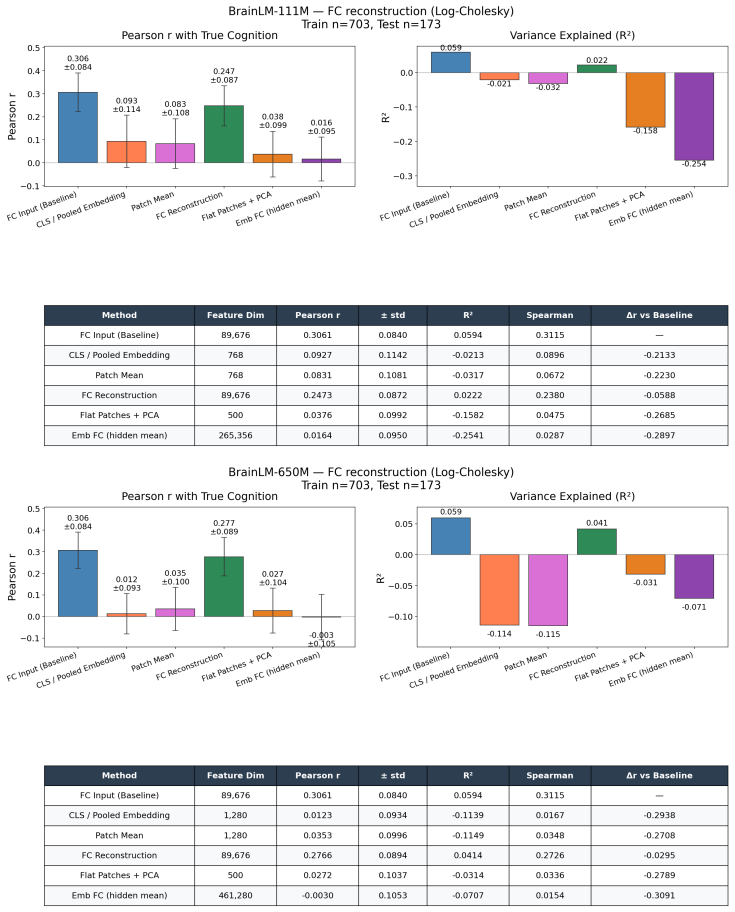
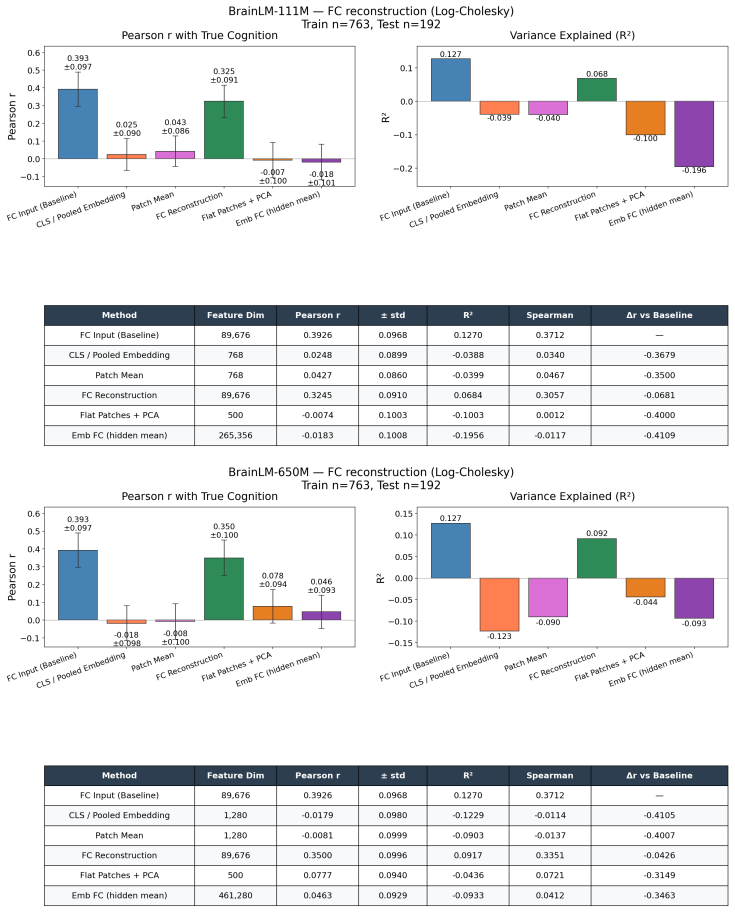
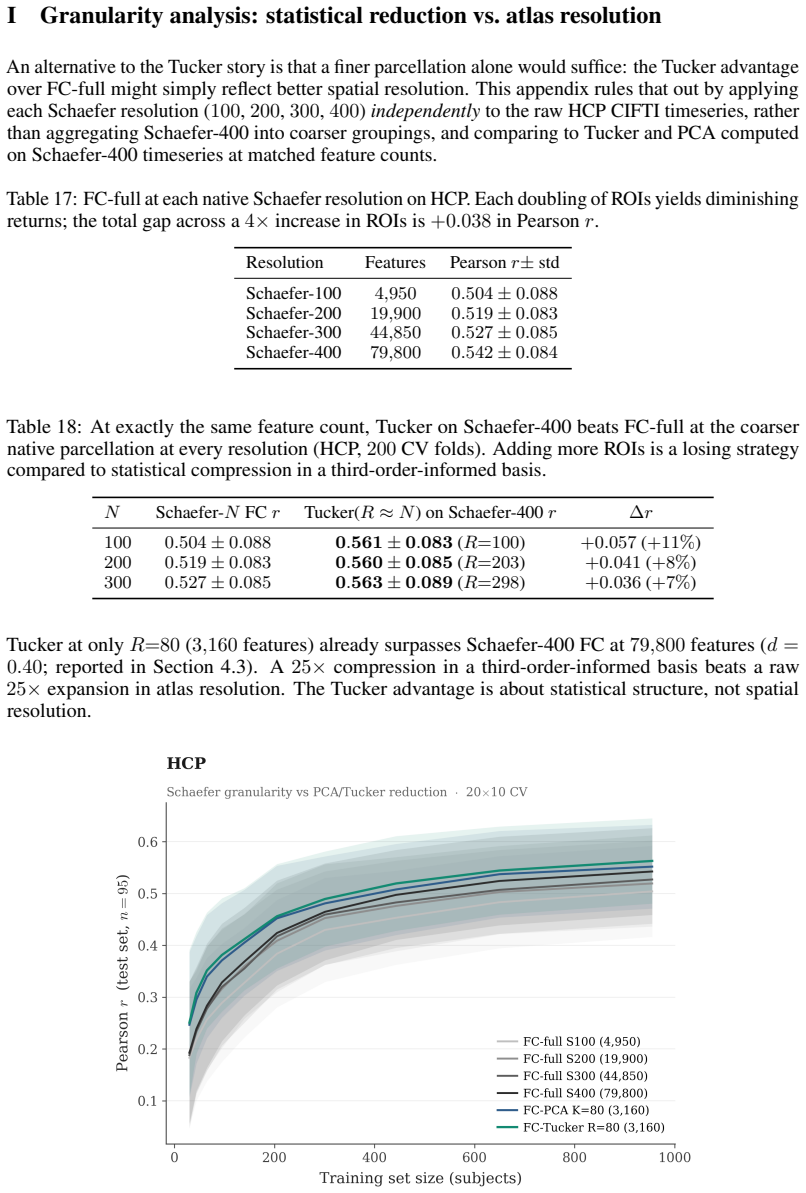
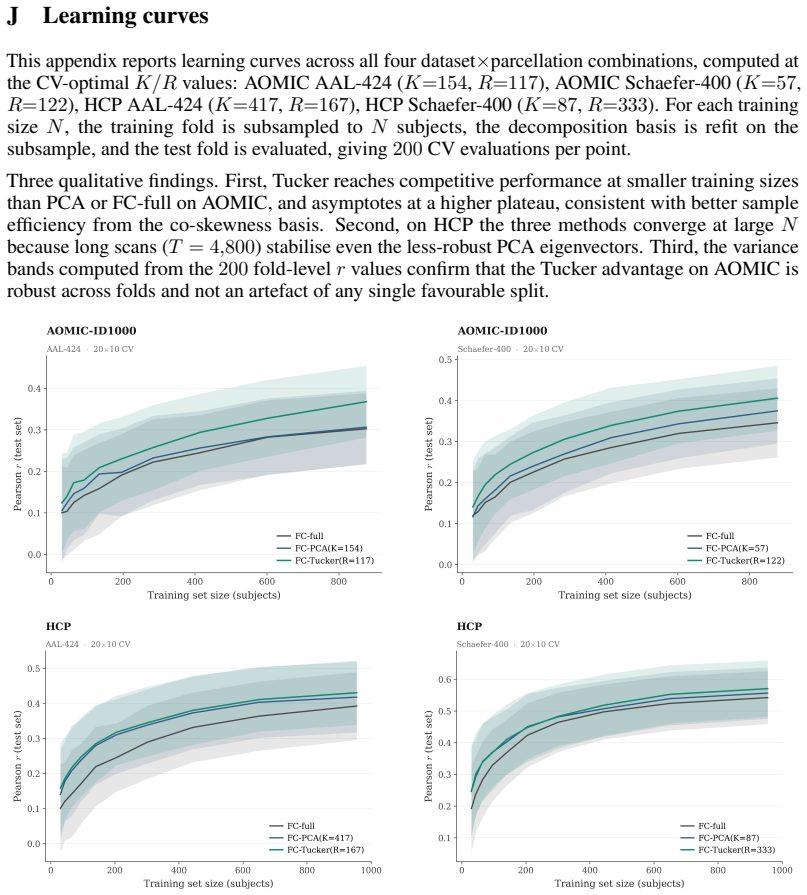


read the original abstract
Brain foundation models (BFMs) are self-supervised Transformers pretrained on fMRI data. We posit that these models should capture each subject's cognitive performance from their fMRI signal. Yet across three state-of-the-art BFMs and every readout we test, they predict cognition worse than a linear regression from the $\sim$80K parameters of the functional connectivity matrix (FC). The gap widens with scale: BrainLM's 650M model predicts cognition worse than its 111M. We attribute this to a \textbf{variance allocation problem}: BFM pretraining captures the variance components that dominate fMRI but not the higher-order structure that predicts cognition. Our per-cumulant analysis of the reconstructed signal shows that the second-order covariance is partially preserved, while the third-order co-skewness tensor is largely destroyed. To recover what BFMs lose, we design a linear pipeline that projects the fMRI signal into the subspace that best preserves its co-skewness and computes FC there. This \textbf{exceeds raw FC and every pretrained BFM} on every dataset and parcellation we test, outperforming prior state-of-the-art under controlled evaluation \textbf{with no pretraining and no GPU}. We \textbf{recover the raw-FC ceiling on BrainLM's forward pass} by finetuning with a loss targeted at this same subspace. This shows that the bottleneck is the pretraining objective, not the architecture or the model size.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that brain foundation models (BFMs) underperform linear regression on the ~80K parameters of the functional connectivity (FC) matrix when predicting cognition from fMRI, with the performance gap increasing with model scale. It attributes this to a variance allocation problem in which BFM pretraining preserves second-order covariance but largely destroys third-order co-skewness. The authors introduce a linear pipeline that projects fMRI signals into the subspace best preserving co-skewness before computing FC; this exceeds both raw FC and all tested BFMs. They further show that finetuning a BFM with a loss targeted at the same subspace recovers the raw-FC performance ceiling, concluding that the pretraining objective—not architecture or scale—is the bottleneck.
Significance. If the results are free of selection effects, the work would be significant for demonstrating that higher-order statistics, rather than model capacity, limit BFM utility for cognitive prediction. The per-cumulant analysis of reconstructions and the targeted finetuning experiment provide concrete evidence linking a specific statistical loss to downstream failure. The proposed linear method offers a reproducible, GPU-free baseline that outperforms large pretrained models, which could shift emphasis toward objective design in neuroimaging foundation models.
major comments (2)
- [Methods (linear pipeline and subspace identification)] Methods section describing the co-skewness-preserving subspace: the procedure for identifying the subspace (via tensor decomposition or optimization) must be shown to be performed strictly unsupervised on data held out from the cognition regression task. The abstract and per-cumulant analysis do not specify whether the 'best preserves' criterion is computed on the same fMRI sessions later used for label prediction or whether any post-hoc metric correlates with cognition scores; if either occurs, the reported gains over raw FC could arise from implicit label leakage rather than recovery of destroyed third-order structure.
- [Results (per-cumulant analysis)] Results on per-cumulant analysis of BFM reconstructions: the claim that co-skewness is 'largely destroyed' while covariance is 'partially preserved' requires explicit quantification (e.g., Frobenius norms or explained variance per cumulant order) on the exact same held-out sessions used for cognition prediction. Without these numbers and without confirming independence from label information, it is unclear whether the observed performance ordering is driven by the claimed statistical loss.
minor comments (2)
- [Abstract] The abstract states that the subspace projection 'exceeds raw FC and every pretrained BFM on every dataset and parcellation'; please add a table or supplementary figure reporting exact effect sizes and statistical tests for each comparison.
- [Methods] Notation for the co-skewness tensor and its projection operator should be defined once in the main text with consistent symbols across equations.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will revise the manuscript to incorporate the requested clarifications and quantifications.
read point-by-point responses
-
Referee: [Methods (linear pipeline and subspace identification)] Methods section describing the co-skewness-preserving subspace: the procedure for identifying the subspace (via tensor decomposition or optimization) must be shown to be performed strictly unsupervised on data held out from the cognition regression task. The abstract and per-cumulant analysis do not specify whether the 'best preserves' criterion is computed on the same fMRI sessions later used for label prediction or whether any post-hoc metric correlates with cognition scores; if either occurs, the reported gains over raw FC could arise from implicit label leakage rather than recovery of destroyed third-order structure.
Authors: The subspace is identified via an unsupervised optimization (or tensor decomposition) performed exclusively on fMRI time series from the training portion of each cross-validation fold; cognition labels are never accessed during this step. The preservation criterion is computed solely from the third-order cumulant of the training data. We will expand the Methods section with pseudocode and an explicit statement confirming that no label information enters the subspace selection, thereby ruling out leakage. revision: yes
-
Referee: [Results (per-cumulant analysis)] Results on per-cumulant analysis of BFM reconstructions: the claim that co-skewness is 'largely destroyed' while covariance is 'partially preserved' requires explicit quantification (e.g., Frobenius norms or explained variance per cumulant order) on the exact same held-out sessions used for cognition prediction. Without these numbers and without confirming independence from label information, it is unclear whether the observed performance ordering is driven by the claimed statistical loss.
Authors: We agree that explicit numerical quantification on the identical held-out sessions is required. We will add a supplementary table (or figure panel) reporting the Frobenius-norm ratios and explained-variance percentages for both the second-order covariance and third-order co-skewness tensors, computed on the test folds used for the cognition regressions. These metrics are derived from the reconstruction step alone and are therefore independent of the downstream labels. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's derivation rests on three independent empirical steps: (1) direct comparison of BFM readouts vs. linear regression on raw FC parameters, (2) per-cumulant decomposition of BFM reconstructions showing differential preservation of covariance vs. co-skewness, and (3) construction of a linear projection whose sole selection criterion is maximization of co-skewness preservation on the fMRI signal itself, followed by FC computation and cognition regression on that projection. The finetuning experiment targets the same co-skewness subspace with an auxiliary loss and shows recovery of the raw-FC performance ceiling. None of these steps reduces by construction to the downstream cognition labels; the subspace criterion is defined solely from third-order moments of the input signal without reference to labels, and all performance numbers are reported under controlled evaluation. No self-citation chain or uniqueness theorem is invoked to force the result. The chain is therefore self-contained against the external benchmarks of BFM outputs and raw FC regression.
Axiom & Free-Parameter Ledger
free parameters (1)
- co-skewness preserving subspace
axioms (1)
- domain assumption Third-order co-skewness in fMRI signals is predictive of cognitive performance
Reference graph
Works this paper leans on
-
[1]
NeuroImage , volume=
Comparison of individualized behavioral predictions across anatomical, diffusion and functional connectivity MRI , author=. NeuroImage , volume=. 2022 , publisher=
2022
-
[2]
NeuroImage , volume=
Comparison between gradients and parcellations for functional connectivity prediction of behavior , author=. NeuroImage , volume=. 2023 , publisher=
2023
-
[3]
Philosophical Transactions of the Royal Society B: Biological Sciences , volume=
A distributed brain network predicts general intelligence from resting-state human neuroimaging data , author=. Philosophical Transactions of the Royal Society B: Biological Sciences , volume=. 2018 , publisher=
2018
-
[4]
Scientific Data , volume=
The Amsterdam Open MRI Collection, a set of multimodal MRI datasets for individual difference analyses , author=. Scientific Data , volume=. 2021 , publisher=
2021
-
[5]
The WU-Minn Human Connectome Project: An overview , journal =
David C. The WU-Minn Human Connectome Project: An overview , journal =. 2013 , note =. doi:https://doi.org/10.1016/j.neuroimage.2013.05.041 , url =
-
[6]
BioRxiv , pages=
BrainLM: A foundation model for brain activity recordings , author=. BioRxiv , pages=. 2023 , publisher=
2023
-
[7]
Advances in Neural Information Processing Systems , volume=
Brain-jepa: Brain dynamics foundation model with gradient positioning and spatiotemporal masking , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
arXiv preprint arXiv:2509.24693 , year=
Brain Harmony: A Multimodal Foundation Model Unifying Morphology and Function into 1D Tokens , author=. arXiv preprint arXiv:2509.24693 , year=
-
[9]
Nature Neuroscience , volume=
Functional connectome fingerprinting: identifying individuals using patterns of brain connectivity , author=. Nature Neuroscience , volume=. 2015 , publisher=
2015
-
[10]
Nature Communications , volume=
Shared and unique brain network features predict cognitive, personality, and mental health scores in the ABCD study , author=. Nature Communications , volume=. 2022 , publisher=
2022
-
[11]
IEEE transactions on medical imaging , volume=
Brainmass: Advancing brain network analysis for diagnosis with large-scale self-supervised learning , author=. IEEE transactions on medical imaging , volume=. 2024 , publisher=
2024
-
[12]
IEEE Signal Processing Magazine , volume=
Brain foundation models: A survey on advancements in neural signal processing and brain discovery , author=. IEEE Signal Processing Magazine , volume=. 2025 , publisher=
2025
-
[13]
Nature Neuroscience , volume=
A synergistic core for human brain evolution and cognition , author=. Nature Neuroscience , volume=. 2022 , publisher=
2022
-
[14]
Brain Connectivity , volume=
High-Order Interdependencies in the Aging Brain , author=. Brain Connectivity , volume=. 2021 , doi=
2021
-
[15]
PLOS Computational Biology , volume=
High-order functional redundancy in ageing explained via alterations in the connectome in a whole-brain model , author=. PLOS Computational Biology , volume=. 2022 , publisher=
2022
-
[16]
Varley and Maria Pope and Olaf Sporns , title =
Thomas F. Varley and Maria Pope and Olaf Sporns , title =. Proceedings of the National Academy of Sciences , volume =. 2023 , doi =
2023
-
[17]
arXiv preprint arXiv:1912.10077 , year=
Are transformers universal approximators of sequence-to-sequence functions? , author=. arXiv preprint arXiv:1912.10077 , year=
-
[18]
Nature Physics , volume=
Higher-order organization of multivariate time series , author=. Nature Physics , volume=. 2023 , publisher=
2023
-
[19]
Nature Communications , volume=
Higher-order connectomics of human brain function reveals local topological signatures of task decoding, individual identification, and behavior , author=. Nature Communications , volume=. 2024 , publisher=
2024
-
[20]
Advances in Neural Information Processing Systems , volume=
Lexicon3d: Probing visual foundation models for complex 3d scene understanding , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Advances in neural information processing systems , volume=
Are emergent abilities of large language models a mirage? , author=. Advances in neural information processing systems , volume=
-
[22]
arXiv preprint arXiv:2306.09479 , year=
Inverse scaling: When bigger isn't better , author=. arXiv preprint arXiv:2306.09479 , year=
-
[23]
Advances in neural information processing systems , volume=
Can contrastive learning avoid shortcut solutions? , author=. Advances in neural information processing systems , volume=
-
[24]
Noise contributions to the fMRI signal: An overview , journal =. 2016 , issn =. doi:https://doi.org/10.1016/j.neuroimage.2016.09.008 , url =
-
[25]
Nature Machine Intelligence , volume=
Shortcut learning in deep neural networks , author=. Nature Machine Intelligence , volume=. 2020 , publisher=
2020
-
[26]
Benchmarking of participant-level confound regression strategies for the control of motion artifact in studies of functional connectivity , journal =. 2017 , note =. doi:https://doi.org/10.1016/j.neuroimage.2017.03.020 , url =
-
[27]
and Bader, Brett W
Kolda, Tamara G. and Bader, Brett W. , title =. SIAM Review , volume =. 2009 , doi =
2009
-
[28]
SIAM Journal on Matrix Analysis and Applications , volume =
Lin, Zhenhua , title =. SIAM Journal on Matrix Analysis and Applications , volume =. 2019 , doi =
2019
-
[29]
Psychometrika , volume=
Some mathematical notes on three-mode factor analysis , author=. Psychometrika , volume=. 1966 , publisher=
1966
-
[30]
Nature , volume=
Learnable latent embeddings for joint behavioural and neural analysis , author=. Nature , volume=. 2023 , publisher=
2023
-
[31]
1994 , publisher=
Kendall's Advanced Theory of Statistics, Volume 1: Distribution Theory , author=. 1994 , publisher=
1994
-
[32]
Local-global parcellation of the human cerebral cortex from intrinsic functional connectivity
Schaefer, Alexander and Kong, Ru and Gordon, Evan M and Laumann, Timothy O and Zuo, Xi-Nian and Holmes, Avram J and Eickhoff, Simon B and Yeo, BT Thomas , journal=. Local-global parcellation of the human cerebral cortex from intrinsic functional connectivity. 2018 , publisher=
2018
-
[33]
Nature Neuroscience , volume=
Topographic organization of the human subcortex unveiled with functional connectivity gradients , author=. Nature Neuroscience , volume=. 2020 , publisher=
2020
-
[34]
Scientific Reports , volume=
Determining the hierarchical architecture of the human brain using subject-level clustering of functional networks , author=. Scientific Reports , volume=. 2019 , publisher=
2019
-
[35]
iScience , volume=
A unique brain connectome fingerprint predates and predicts response to antidepressants , author=. iScience , volume=. 2020 , publisher=
2020
-
[36]
Esteban, Oscar and Markiewicz, Christopher J and Blair, Ross W and Moodie, Craig A and Isik, A Ilkay and Erramuzpe, Asier and Kent, James D and Goncalves, Mathias and DuPre, Elizabeth and Snyder, Madeleine and Oya, Hiroyuki and Ghosh, Satrajit S and Wright, Jessey and Durnez, Joke and Poldrack, Russell A and Gorgolewski, Krzysztof J , journal=. f. 2019 , ...
2019
-
[37]
arXiv preprint arXiv:2402.11337 , year=
Learning by reconstruction produces uninformative features for perception , author=. arXiv preprint arXiv:2402.11337 , year=
-
[38]
Joint embedding vs reconstruction: Provable benefits of latent space prediction for self supervised learning , author=. arXiv preprint arXiv:2505.12477 , year=
-
[39]
Machine Learning , volume=
Inference for the generalization error , author=. Machine Learning , volume=
-
[40]
Pacific-Asia Conference on Knowledge Discovery and Data Mining , pages=
Evaluating the replicability of significance tests for comparing learning algorithms , author=. Pacific-Asia Conference on Knowledge Discovery and Data Mining , pages=. 2004 , organization=
2004
-
[41]
Journal of Machine Learning Research , volume=
No unbiased estimator of the variance of k-fold cross-validation , author=. Journal of Machine Learning Research , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.