CodegenBench: Can LLMs Write Efficient Code Across Architectures?
Pith reviewed 2026-06-28 13:36 UTC · model grok-4.3
The pith
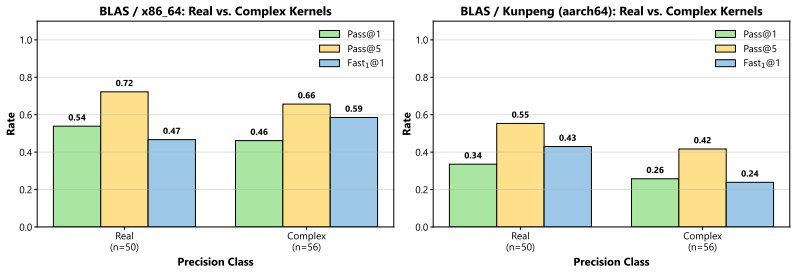
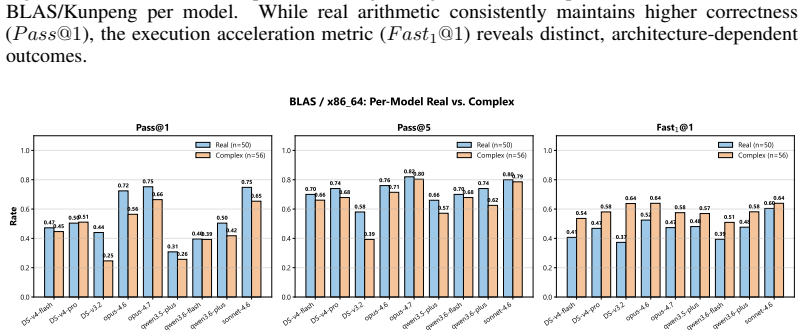
Large language models generate optimized parallel code for x86_64 but show sharp performance drops on Sunway and Kunpeng.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
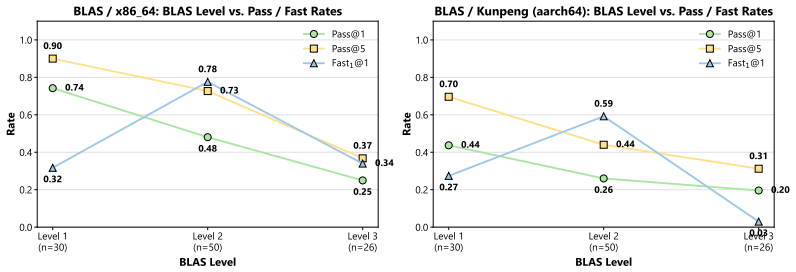
State-of-the-art LLMs can generate optimized code for ubiquitous architectures like x86_64, yet they exhibit significant performance degradation on domain-specific architectures with limited public documentation and training data. Analysis of implementation length and task complexity shows current LLMs work best on moderately difficult problems that need concise snippets.
What carries the argument
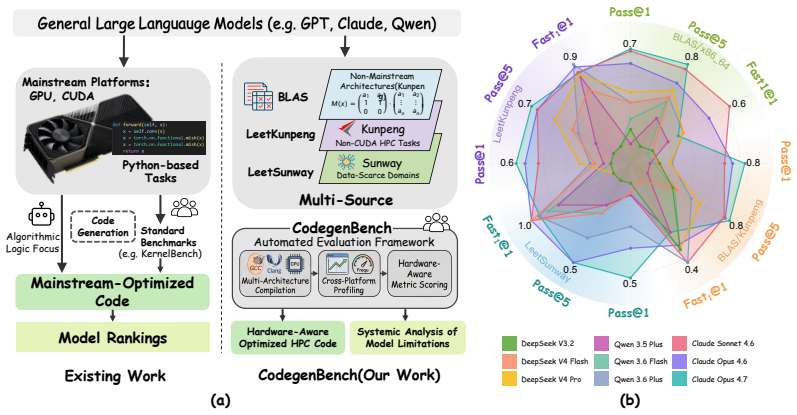
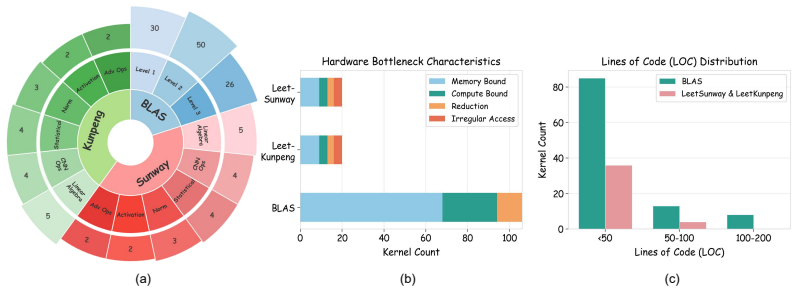
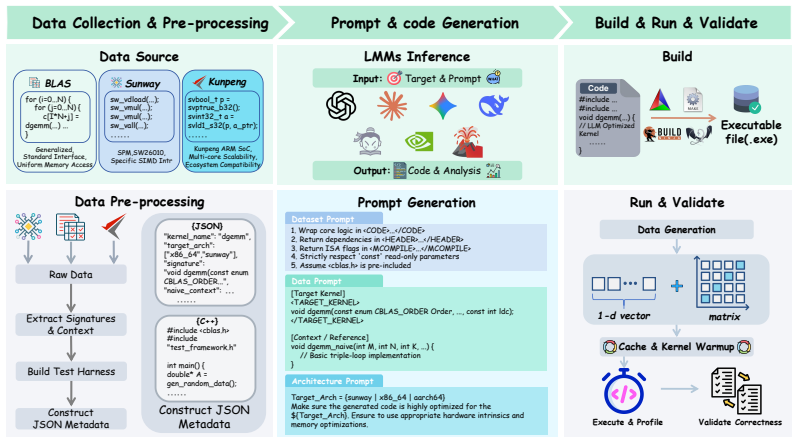
CodegenBench, a benchmark suite of 106 BLAS routines and 20 architecture-specific kernels that measures runtime performance of LLM-generated parallel code on x86_64, Sunway, and Kunpeng.
If this is right
- LLMs remain most reliable when asked for concise implementations of moderate complexity.
- Code quality declines as target architecture documentation becomes scarcer.
- Open-sourced dataset and evaluation tools can support further work on LLM-driven HPC code generation.
Where Pith is reading between the lines
- Architectures with sparse public data may need targeted retrieval or fine-tuning before LLMs can match x86_64 results.
- The same benchmark approach could reveal similar limits when applied to other emerging or proprietary hardware.
- Widespread use of LLMs for cross-platform optimization may be delayed until data scarcity is addressed.
Load-bearing premise
Performance gaps across architectures arise mainly from differences in the amount of public documentation and training data rather than from how the benchmark tasks were chosen or how speed was measured.
What would settle it
An experiment that applies identical BLAS and kernel tasks to all three architectures and finds comparable LLM code efficiency, or that shows the chosen tasks differ systematically in inherent difficulty.
Figures
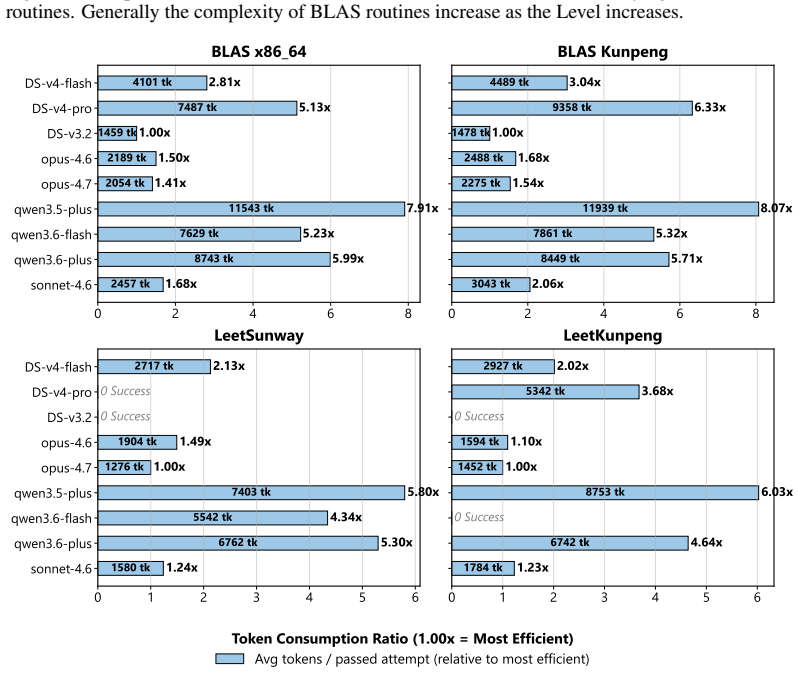
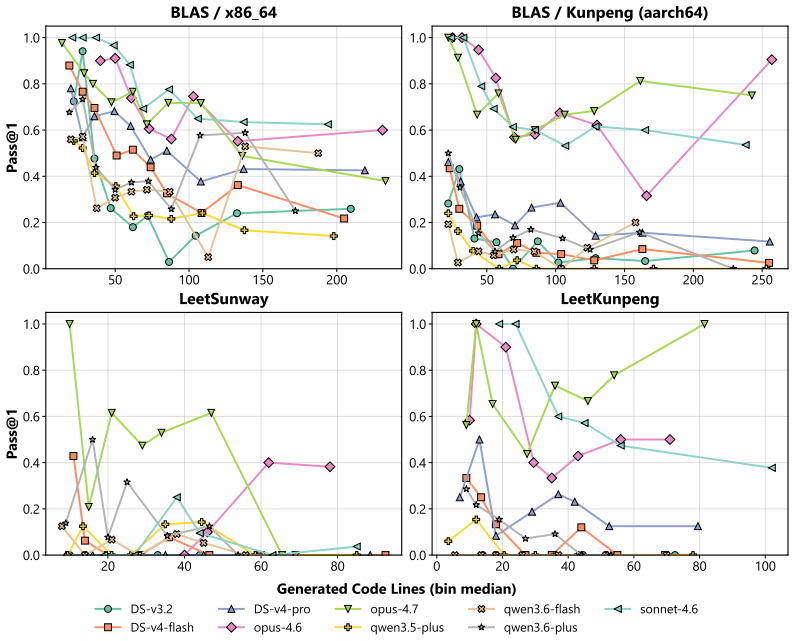











read the original abstract
While large language models (LLMs) have been extensively evaluated on code generation tasks for general-purpose programming and GPU-accelerated environments (e.g., PyTorch, CUDA), their capabilities in CPU-oriented high-performance computing (HPC) across diverse architectures remain underexplored. To bridge this gap, we introduce CodegenBench, a comprehensive benchmark suite designed to evaluate the generation of efficient parallel code across three distinct hardware platforms: x86_64, Sunway, and Kunpeng. Our benchmark comprises 106 standard Basic Linear Algebra Subprograms (BLAS) routines establishing a fundamental baseline, alongside 20 specialized computational kernels adapted for each of the unique supercomputing architectures (LeetSunway and LeetKunpeng). Our extensive evaluation reveals that while state-of-the-art LLMs can generate optimized code for ubiquitous architectures like x86_64, they exhibit significant performance degradation on domain-specific architectures with limited public documentation and training data, highlighting critical limitations in cross-platform generalization. Furthermore, our analysis of factors influencing code quality such as implementation length and task complexity indicates that current LLMs are most effective for moderately difficult problems requiring concise code snippets. We open-source our dataset and automated evaluation infrastructure to facilitate future research in LLM-driven high-performance code generation. The resources are available at https://anonymous.4open.science/r/CodegenBench-EDE1/ and https://anonymous.4open.science/r/CodegenBenchDataset-2551.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CodegenBench, a benchmark suite consisting of 106 standard BLAS routines (identical across platforms) plus 20 specialized kernels adapted for each of three architectures (x86_64, Sunway, Kunpeng), to evaluate LLMs' ability to generate efficient parallel code. The central claim is that state-of-the-art LLMs produce optimized code for ubiquitous architectures like x86_64 but exhibit significant performance degradation on domain-specific architectures with limited public documentation and training data; the authors also analyze factors such as implementation length and task complexity, and open-source the dataset and evaluation infrastructure.
Significance. If the central claim holds after addressing confounds, the work would usefully extend LLM code-generation evaluation into CPU-oriented HPC across heterogeneous supercomputing architectures, an area noted as underexplored. The open-sourcing of the dataset and automated evaluation infrastructure is a clear strength that supports reproducibility and follow-on research.
major comments (1)
- [benchmark design and evaluation sections describing the 20 specialized kernels (LeetSunway and LeetKunpeng)] The attribution of performance degradation primarily to limited public documentation and training data (abstract and benchmark description) is not supported without controls for task adaptation. The 20 specialized kernels are explicitly 'adapted for each' architecture, yet no evidence is provided that the adaptations preserve equivalent algorithmic complexity, optimization targets, or measurement definitions (e.g., absolute runtime vs. relative speedup, correctness thresholds) across platforms. This leaves open the possibility that observed gaps arise from platform-specific task difficulty rather than data volume.
minor comments (1)
- [abstract] The abstract states the main finding but provides no quantitative results, error bars, or evaluation protocol details (e.g., how efficiency is scored or statistical significance of degradation). While abstracts often summarize, the full paper should include these in the results section for the claim to be assessable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting a potential confound in our benchmark design. The concern regarding controls for task adaptation in the specialized kernels is well-taken and points to an area where additional clarification will strengthen the manuscript.
read point-by-point responses
-
Referee: [benchmark design and evaluation sections describing the 20 specialized kernels (LeetSunway and LeetKunpeng)] The attribution of performance degradation primarily to limited public documentation and training data (abstract and benchmark description) is not supported without controls for task adaptation. The 20 specialized kernels are explicitly 'adapted for each' architecture, yet no evidence is provided that the adaptations preserve equivalent algorithmic complexity, optimization targets, or measurement definitions (e.g., absolute runtime vs. relative speedup, correctness thresholds) across platforms. This leaves open the possibility that observed gaps arise from platform-specific task difficulty rather than data volume.
Authors: We agree this is a valid point that requires strengthening. The 106 BLAS routines are identical across platforms and serve as the primary controlled baseline for cross-architecture comparison. The 20 specialized kernels (LeetSunway and LeetKunpeng) were adapted to exercise architecture-unique features while targeting comparable problem sizes and computational patterns. However, the current manuscript does not include explicit quantitative controls (e.g., operation counts, memory access patterns, or parallelism metrics) demonstrating equivalence. In the revised manuscript we will add: (1) a table of per-kernel complexity metrics across the three architectures; (2) explicit statement that all evaluations use identical correctness thresholds and report normalized speedup relative to architecture-specific naive baselines; and (3) clarification in the abstract and benchmark description that the main performance-degradation claim rests on the identical BLAS subset. These additions will better isolate the effect of training-data availability. revision: yes
Circularity Check
Empirical benchmark with no derivation chain or self-referential reductions
full rationale
The paper presents an empirical benchmark study (CodegenBench) consisting of 106 BLAS routines and 20 architecture-adapted kernels, followed by direct LLM evaluations on x86_64, Sunway, and Kunpeng. No equations, fitted parameters, or mathematical derivations are present that could reduce any result to prior inputs by construction. The central claim rests on new test data and measurements; the abstract and provided text contain no self-citations invoked as load-bearing uniqueness theorems or ansatzes. This is a standard non-circular empirical report.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions about what constitutes efficient parallel code in HPC benchmarking
Reference graph
Works this paper leans on
-
[1]
Evaluating the performance of kunpeng 920 processors on modern hpc applications
Ilya Afanasyev and Dmitry Lichmanov. Evaluating the performance of kunpeng 920 processors on modern hpc applications. InInternational Conference on Parallel Computing Technologies, pages 301–321. Springer, 2021
2021
-
[2]
Qwen3.5, March 2026
Alibaba. Qwen3.5, March 2026. URLhttps://qwen.ai/blog?id=qwen3.5. Accessed: 2026-05-06
2026
-
[3]
Qwen3.6, March 2026
Alibaba. Qwen3.6, March 2026. URLhttps://qwen.ai/blog?id=qwen3.6. Accessed: 2026-05-06
2026
-
[4]
Qwen3.6-35b-a3b, March 2026
Alibaba. Qwen3.6-35b-a3b, March 2026. URL https://qwen.ai/blog?id=qwen3.6-35b-a3b. Ac- cessed: 2026-05-06
2026
-
[5]
SantaCoder: don’t reach for the stars!
Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, et al. Santacoder: don’t reach for the stars!arXiv preprint arXiv:2301.03988, 2023
-
[6]
Introducing claude opus 4.6, February 2026
Anthropic. Introducing claude opus 4.6, February 2026. URL https://www.anthropic.com/news/ claude-opus-4-6. Accessed: 2026-05-06
2026
-
[7]
Introducing claude opus 4.7, March 2026
Anthropic. Introducing claude opus 4.7, March 2026. URL https://www.anthropic.com/news/ claude-opus-4-7. Accessed: 2026-05-06
2026
-
[8]
Introducing claude sonnet 4.6, February 2026
Anthropic. Introducing claude sonnet 4.6, February 2026. URLhttps://www.anthropic.com/news/ claude-sonnet-4-6. Accessed: 2026-05-06
2026
-
[9]
Multi-lingual evaluation of code generation models,
Ben Athiwaratkun, Sanjay Krishna Gouda, Zijian Wang, Xiaopeng Li, Yuchen Tian, Ming Tan, Wasi Uddin Ahmad, Shiqi Wang, Qing Sun, Mingyue Shang, et al. Multi-lingual evaluation of code generation models. arXiv preprint arXiv:2210.14868, 2022
-
[10]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Hosna: A dpc++ benchmark suite for heterogeneous architectures
Najmeh Nazari Bavarsad, Hosein Mohammadi Makrani, Hossein Sayadi, Lawrence Landis, Setareh Rafatirad, and Houman Homayoun. Hosna: A dpc++ benchmark suite for heterogeneous architectures. In 2021 IEEE 39th International Conference on Computer Design (ICCD), pages 509–516. IEEE, 2021
2021
-
[13]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[14]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention. arXiv preprint arXiv:2506.13585, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Data race detection using large language models
Le Chen, Xianzhong Ding, Murali Emani, Tristan Vanderbruggen, Pei-Hung Lin, and Chunhua Liao. Data race detection using large language models. InProceedings of the SC’23 Workshops of the International Conference on High Performance Computing, Network, Storage, and Analysis, pages 215–223, 2023
2023
-
[16]
Pcebench: A multi-dimensional benchmark for evaluating large language models in parallel code generation
Le Chen, Nesreen Ahmed, Mihai Capot˘a, Ted Willke, Niranjan Hasabnis, and Ali Jannesari. Pcebench: A multi-dimensional benchmark for evaluating large language models in parallel code generation. In2025 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 546–557. IEEE, 2025
2025
-
[17]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
Deepseek-v4-flash, April 2026
DeepSeek AI. Deepseek-v4-flash, April 2026. URL https://api-docs.deepseek.com/news/ news260424#deepseek-v4-flash. Accessed: 2026-05-06
2026
-
[19]
Deepseek-v4-pro, April 2026
DeepSeek AI. Deepseek-v4-pro, April 2026. URL https://api-docs.deepseek.com/news/ news260424#deepseek-v4-pro. Accessed: 2026-05-06. 10
2026
-
[20]
An overview of the sparse basic linear algebra subprograms: The new standard from the blas technical forum.ACM Transactions on Mathematical Software (TOMS), 28(2):239–267, 2002
Iain S Duff, Michael A Heroux, and Roldan Pozo. An overview of the sparse basic linear algebra subprograms: The new standard from the blas technical forum.ACM Transactions on Mathematical Software (TOMS), 28(2):239–267, 2002
2002
-
[21]
The sunway taihulight supercomputer: system and applications
Haohuan Fu, Junfeng Liao, Jinzhe Yang, Lanning Wang, Zhenya Song, Xiaomeng Huang, Chao Yang, Wei Xue, Fangfang Liu, Fangli Qiao, et al. The sunway taihulight supercomputer: system and applications. Science China Information Sciences, 59(7):072001, 2016
2016
-
[22]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yifan Wu, YK Li, et al. Deepseek-coder: when the large language model meets programming–the rise of code intelligence.arXiv preprint arXiv:2401.14196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Effibench: Benchmarking the efficiency of automatically generated code.Advances in Neural Information Processing Systems, 37: 11506–11544, 2024
Dong Huang, Yuhao Qing, Weiyi Shang, Heming Cui, and Jie M Zhang. Effibench: Benchmarking the efficiency of automatically generated code.Advances in Neural Information Processing Systems, 37: 11506–11544, 2024
2024
-
[24]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Ds-1000: A natural and reliable benchmark for data science code generation
Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Wen-tau Yih, Daniel Fried, Sida Wang, and Tao Yu. Ds-1000: A natural and reliable benchmark for data science code generation. InInternational Conference on Machine Learning, pages 18319–18345. PMLR, 2023
2023
-
[26]
Tritonbench: Benchmarking large language model capabilities for generating triton operators
Jianling Li, Shangzhan Li, Zhenye Gao, Qi Shi, Yuxuan Li, Zefan Wang, Jiacheng Huang, WangHaojie WangHaojie, Jianrong Wang, Xu Han, et al. Tritonbench: Benchmarking large language model capabilities for generating triton operators. InFindings of the Association for Computational Linguistics: ACL 2025, pages 23053–23066, 2025
2025
-
[27]
StarCoder: may the source be with you!
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. Starcoder: may the source be with you!arXiv preprint arXiv:2305.06161, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Competition-level code generation with alphacode
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode. Science, 378(6624):1092–1097, 2022
2022
-
[29]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81, 2004
2004
-
[30]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Is your code gen- erated by chatgpt really correct? rigorous evaluation of large language models for code genera- tion
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and LINGMING ZHANG. Is your code gen- erated by chatgpt really correct? rigorous evaluation of large language models for code genera- tion. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Ad- vances in Neural Information Processing Systems, volume 36, pages 21558–21572. Curran Ass...
2023
-
[32]
Daichi Mukunoki, Shun-ichiro Hayashi, Tetsuya Hoshino, and Takahiro Katagiri. Performance evaluation of general purpose large language models for basic linear algebra subprograms code generation.arXiv preprint arXiv:2507.04697, 2025
-
[33]
Llm4vv: Developing llm-driven testsuite for compiler validation.Future Generation Computer Systems, 160:1–13, 2024
Christian Munley, Aaron Jarmusch, and Sunita Chandrasekaran. Llm4vv: Developing llm-driven testsuite for compiler validation.Future Generation Computer Systems, 160:1–13, 2024
2024
-
[34]
Can large language models write parallel code? InProceedings of the 33rd International Symposium on High-Performance Parallel and Distributed Computing, pages 281–294, 2024
Daniel Nichols, Joshua H Davis, Zhaojun Xie, Arjun Rajaram, and Abhinav Bhatele. Can large language models write parallel code? InProceedings of the 33rd International Symposium on High-Performance Parallel and Distributed Computing, pages 281–294, 2024
2024
-
[35]
KernelBench: Can LLMs Write Efficient GPU Kernels?
Anne Ouyang, Simon Guo, Simran Arora, Alex L Zhang, William Hu, Christopher Ré, and Azalia Mirhoseini. Kernelbench: Can llms write efficient gpu kernels?arXiv preprint arXiv:2502.10517, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022. 11
2022
-
[37]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002
2002
-
[38]
Aman Priyanshu, Yash Maurya, and Zuofei Hong. Ai governance and accountability: An analysis of anthropic’s claude.arXiv preprint arXiv:2407.01557, 2024
-
[39]
Ruizhong Qiu, Weiliang Will Zeng, James Ezick, Christopher Lott, and Hanghang Tong. How efficient is llm-generated code? a rigorous & high-standard benchmark.arXiv preprint arXiv:2406.06647, 2024
-
[40]
Code Llama: Open Foundation Models for Code
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Evaluating llms for code generation in hri: A comparative study of chatgpt, gemini, and claude.Applied Artificial Intelligence, 39 (1):2439610, 2025
Andrei Sobo, Awes Mubarak, Almas Baimagambetov, and Nikolaos Polatidis. Evaluating llms for code generation in hri: A comparative study of chatgpt, gemini, and claude.Applied Artificial Intelligence, 39 (1):2439610, 2025
2025
-
[42]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Heterobench: Multi-kernel benchmarks for heterogeneous systems
Hongzheng Tian, Alok Mishra, Zhiheng Chen, Rolando P Hong Enriquez, Dejan Milojicic, Eitan Frachten- berg, and Sitao Huang. Heterobench: Multi-kernel benchmarks for heterogeneous systems. InProceedings of the 16th ACM/SPEC International Conference on Performance Engineering, pages 320–333, 2025
2025
-
[44]
Comparing llama-2 and gpt-3 llms for hpc kernels generation
Pedro Valero-Lara, Alexis Huante, Mustafa Al Lail, William F Godoy, Keita Teranishi, Prasanna Bal- aprakash, and Jeffrey S Vetter. Comparing llama-2 and gpt-3 llms for hpc kernels generation. In International Workshop on Languages and Compilers for Parallel Computing, pages 20–32. Springer, 2023
2023
-
[45]
Multikernelbench: A multi-platform benchmark for kernel generation.arXiv e-prints, pp
Zhongzhen Wen, Yinghui Zhang, Zhong Li, Zhongxin Liu, Linna Xie, and Tian Zhang. Multikernelbench: A multi-platform benchmark for kernel generation.arXiv e-prints, pp. arXiv–2507, 2025
2025
-
[46]
Kunpeng 920: The first 7-nm chiplet-based 64-core arm soc for cloud services.IEEE Micro, 41(5):67–75, 2021
Jing Xia, Chuanning Cheng, Xiping Zhou, Yuxing Hu, and Peter Chun. Kunpeng 920: The first 7-nm chiplet-based 64-core arm soc for cloud services.IEEE Micro, 41(5):67–75, 2021
2021
-
[47]
Jian Yang, Wei Zhang, Yibo Miao, Shanghaoran Quan, Zhenhe Wu, Qiyao Peng, Liqun Yang, Tianyu Liu, Zeyu Cui, Binyuan Hui, et al. Qwen2. 5-xcoder: Multi-agent collaboration for multilingual code instruction tuning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13121–13131, 2025
2025
-
[48]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models.arXiv preprint arXiv:2508.06471, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. Glm-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
Cudabench: Benchmarking llms for text-to-cuda generation.arXiv preprint arXiv:2603.02236, 2026
Jiace Zhu, Wentao Chen, Qi Fan, Zhixing Ren, Junying Wu, Xing Zhe Chai, Chotiwit Rungrueangwutthi- non, Yehan Ma, and An Zou. Cudabench: Benchmarking llms for text-to-cuda generation.arXiv preprint arXiv:2603.02236, 2026
-
[51]
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
Qihao Zhu, Daya Guo, Zhihong Shao, Dejian Yang, Peiyi Wang, Runxin Xu, Y Wu, Yukun Li, Huazuo Gao, Shirong Ma, et al. Deepseek-coder-v2: Breaking the barrier of closed-source models in code intelligence. arXiv preprint arXiv:2406.11931, 2024. 12 CodegenBench: Can LLMs Write Efficient Code Across Architectures? (Supplemental Materials) Table of Contents in...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
DeepSeek v3.2
You must pay attention to the const constraints of the parameters. You should not violate any of the read-only constraints specified in the function signature. 6.<complex> will be included for any complex related function. Besides, you must include any C++ standard library header if you have used any of these functions or features, for example, <algorithm...
-
[53]
DeepSeek v3.2
You must pay attention to the const constraints of the parameters. You should not violate any of the read-only constraints specified in the function signature. 6.<complex> will be included for any complex related function. Besides, you must include any C++ standard library header if you have used any of these functions or features, for example, <algorithm...
-
[54]
You should not violate any of the read-only constraints specified in the function signature
You must pay attention to the const constraints of the parameters. You should not violate any of the read-only constraints specified in the function signature. 4.For the codes that you have to generate multiple parts, you should generate the code for each seperately, and return with <CODE1></CODE1>, <CODE2> </CODE2>... tag pairs. For example, if you have ...
-
[55]
For any other functions that you want to define to support your implementation, you can use <HELPER></HELPER> tag pair to return the code, for example: <HELPER> //contents for assist functions </HELPER>
-
[56]
func(){ //contents }
For any ARM SME codes, you must understand that the function should be modified with __arm_locally_streaming to enter streaming mode, and __arm_new("za") to use za register.The following lines is the context for code generation, which may include code snippets, API specifications, and other information. You can use this information to generate the target ...
-
[57]
Qwen 3.6 Plus
You must pay attention to the const constraints of the parameters. You should not violate any of the read-only constraints specified in the function signature. 6.<complex> will be included for any complex related function. Besides, you must include any C++ standard library header if you have used any of these functions or features, for example, <algorithm...
-
[58]
func(){ //contents }
You must pay attention to the const constraints of the parameters. You should not violate any of the read-only constraints specified in the function signature. 6.<complex> will be included for any complex related function. Besides, you must include any C++ standard library header if you have used any of these functions or features, for example, <algorithm...
-
[59]
func(){ //contents }
You must pay attention to the const constraints of the parameters. You should not violate any of the read-only constraints specified in the function signature. 6.<complex> will be included for any complex related function. Besides, you must include any C++ standard library header if you have used any of these functions or features, for example, <algorithm...
-
[60]
You should not violate any of the read-only constraints specified in the function signature
You must pay attention to the const constraints of the parameters. You should not violate any of the read-only constraints specified in the function signature. 6.<complex> will be included for any complex related function. Besides, you must include any C++ standard library header if you have used any of these functions or features, for example, <algorithm...
-
[61]
use_upper_triangle\
return;\n\n // Handle beta * Y\n if (beta == 0.0) {\n if (incY == 1) {\n int i = 0;\n for (; i + 3 < N; i += 4) {\n _mm256_storeu_pd(Y + i, _mm256_setzero_pd());\n }\n for (; i < N; i++) Y[i] = 0.0;\n } else {\n for (int i = 0; i < N; i++) Y[i * incY] = 0.0;\n }\n } else if (beta != 1.0) {\n if (incY == 1) {\n __m256d vbeta = _mm256_set1_pd(beta);\n int i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.