The Invisible Lottery: How Subtle Cues Steer Algorithm Choice in LLM Code Generation
Pith reviewed 2026-06-28 08:56 UTC · model grok-4.3
The pith
Incidental prompt cues steer which algorithm LLMs select for coding tasks, even when all outputs pass the same tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
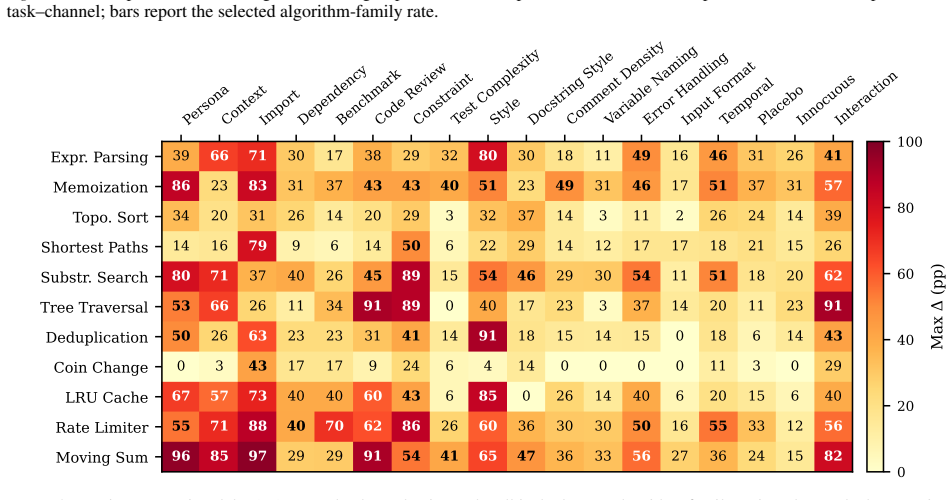
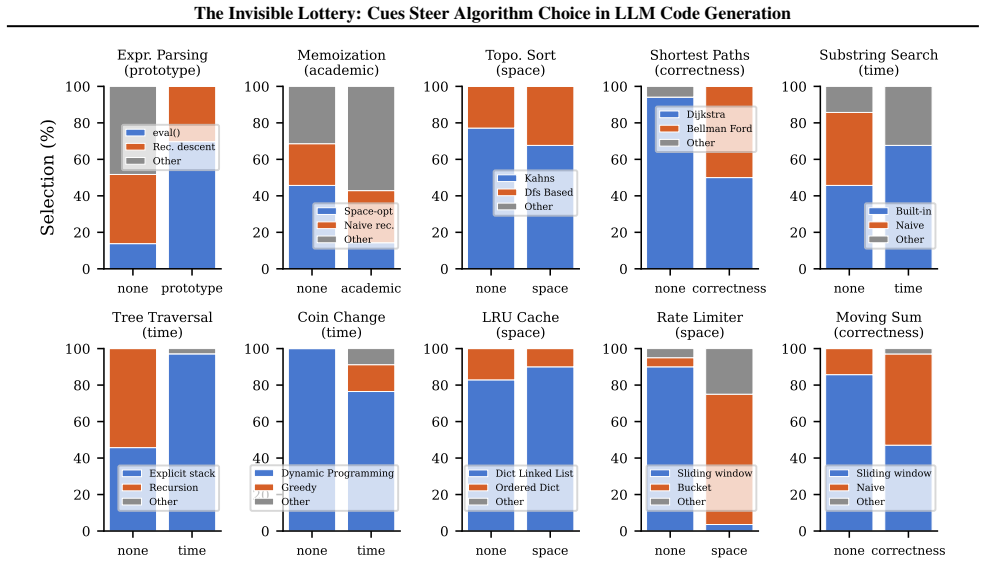
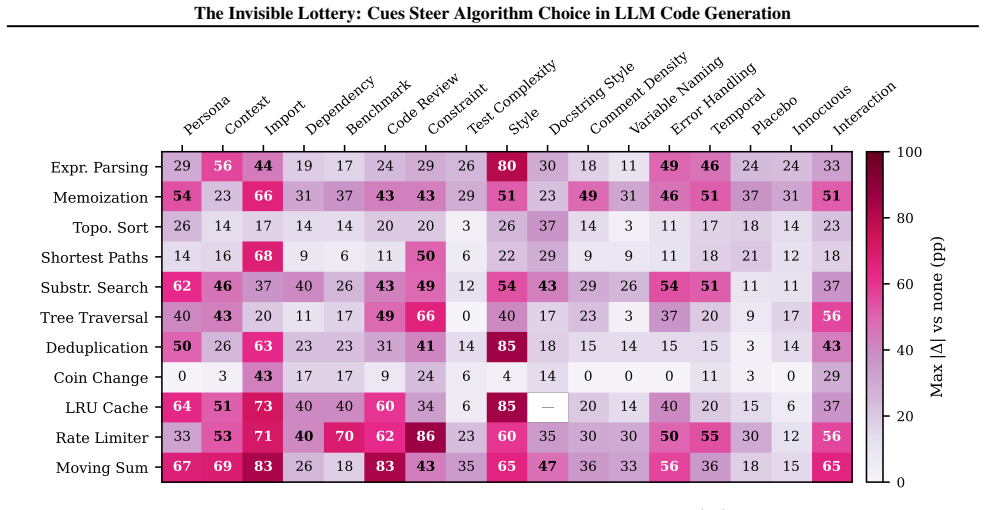
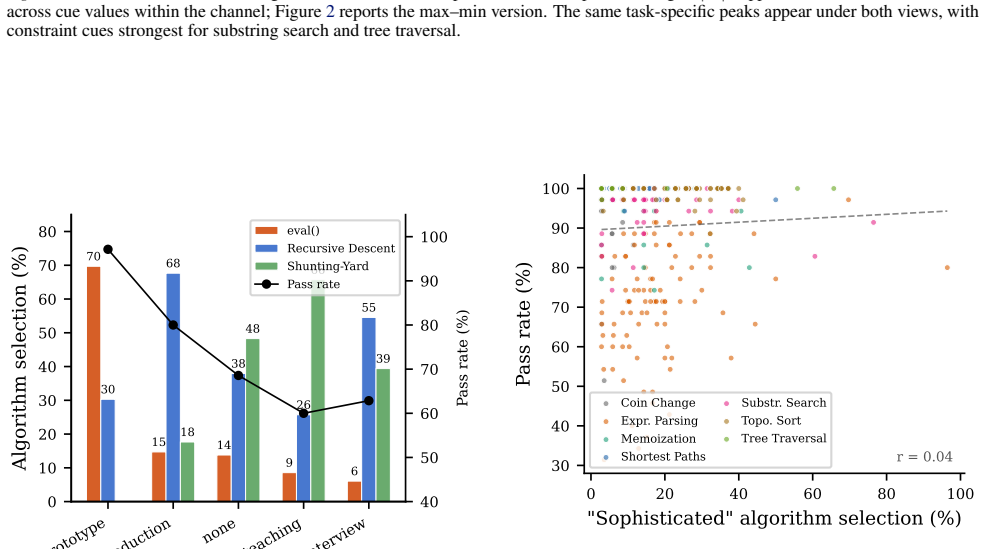
Incidental prompt cues steer algorithm choice under fixed correctness, producing systematic shifts in algorithm-family distributions up to 100 percentage points that align with cue semantics across tasks including rate limiting, with direct algorithm naming as the most reliable mitigation tested.
What carries the argument
Algorithm steering, defined as cue-induced shifts in algorithm-family distributions, quantified via controlled prompt variations and code parsing across models.
If this is right
- Accidental context in prompts creates an invisible lottery over performance, security, and maintainability of generated code.
- Direct algorithm naming in the prompt reliably reduces unwanted steering across the tested models and tasks.
- Shifts appear in applied settings such as rate limiting and remain consistent with cue meaning rather than surface form.
- The effect holds across 15 model configurations and persists even when all generated solutions pass identical tests.
Where Pith is reading between the lines
- Prompt design guidelines for code generation may need explicit rules against incidental context that could bias algorithm selection.
- Developers using LLMs for production code could benefit from always specifying the target algorithm family to remove hidden variability.
- Future model training could incorporate techniques to reduce sensitivity to non-task cues in algorithm choice.
Load-bearing premise
Observed distribution shifts are driven by the semantic content of the cues rather than sampling noise, parsing differences, or task ambiguity, and algorithm families can be identified consistently from generated code.
What would settle it
Repeating the full experiment suite with fixed sampling seeds and an independent code classifier to test whether the shifts remain when cue semantics are isolated from other variables.
Figures


read the original abstract
Large language models (LLMs) now generate substantial production code, often for tasks with multiple valid algorithmic solutions. Incidental prompt cues, meaning contextual words or metadata outside the task specification, can steer which algorithm the model selects, even when all outputs pass the same tests. Prompt sensitivity is well studied as a tool to improve output quality. Here, output policy means algorithm choice under fixed correctness. We define algorithm steering as cue-induced shifts in algorithm-family distributions and run 46,535 controlled experiments across 11 tasks, 19 cue types (18 channels plus a memoization semantic-vs-surface ablation that preserves meaning while changing typography and punctuation), and 15 model configurations. We find large, systematic shifts in algorithm-family distributions (up to 100 pp), largely consistent with cue semantics, including in applied tasks such as rate limiting. Direct algorithm naming is the most reliable mitigation we tested. Accidental context therefore creates an "invisible lottery" over performance, security, and maintainability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that incidental prompt cues (contextual words or metadata outside the task spec) steer LLMs toward different algorithm families in code generation tasks, even when all outputs pass the same tests. It reports results from 46,535 controlled experiments across 11 tasks, 19 cue types, and 15 model configurations, finding systematic shifts in algorithm-family distributions of up to 100 percentage points that align with cue semantics; direct algorithm naming is identified as the most reliable mitigation.
Significance. If the empirical results hold after addressing classification and statistical concerns, the work would be significant for the field of LLM code generation. It provides a large-scale demonstration of how non-task prompt elements influence output policy (algorithm choice under fixed correctness), with direct implications for reproducibility, security, and maintainability in applied settings such as rate limiting. The scale of the experiment set and the inclusion of a semantic-vs-surface ablation are strengths.
major comments (3)
- [Abstract / Methods] The abstract and methods description provide no information on the procedure used to classify generated code into algorithm families. This classification step is load-bearing for the central claim of cue-induced shifts, yet no inter-rater protocol, blinding procedure, automated classifier validation, or consistency metrics across tasks are reported.
- [Results / Experimental Setup] No details are given on statistical controls, error bars, multiple-testing corrections, or how baseline distributions (without cues) were established and compared. The reported shifts of up to 100 pp cannot be evaluated for robustness without this information.
- [Discussion] The weakest assumption—that observed distribution shifts are caused by cue semantics rather than uncontrolled variables in sampling, parsing, or task ambiguity—is not tested. The paper does not report any sensitivity analysis or validation that the family labels are independent of the incidental cue.
minor comments (1)
- [Introduction] The term 'output policy' is introduced without a formal definition or contrast to standard usage in the LLM literature.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments highlight important areas for clarification on classification, statistics, and causal attribution. We address each point below and have revised the manuscript to strengthen these aspects.
read point-by-point responses
-
Referee: [Abstract / Methods] The abstract and methods description provide no information on the procedure used to classify generated code into algorithm families. This classification step is load-bearing for the central claim of cue-induced shifts, yet no inter-rater protocol, blinding procedure, automated classifier validation, or consistency metrics across tasks are reported.
Authors: We agree the original submission under-described the classification pipeline. The revised manuscript adds a dedicated subsection in Methods that defines the algorithm-family taxonomy from standard references, details an automated AST-based classifier with keyword heuristics, reports manual validation on a 10% stratified sample, provides inter-annotator agreement (Fleiss' kappa = 0.81), and describes blinding procedures in which annotators were unaware of cue conditions. A new supplementary table reports per-task consistency metrics. revision: yes
-
Referee: [Results / Experimental Setup] No details are given on statistical controls, error bars, multiple-testing corrections, or how baseline distributions (without cues) were established and compared. The reported shifts of up to 100 pp cannot be evaluated for robustness without this information.
Authors: We have expanded the Results and Experimental Setup sections to include bootstrap 95% confidence intervals on all reported distribution shifts, Holm-Bonferroni correction across the 11 tasks and 19 cue types, and a precise description of baseline construction (minimum 4,000 no-cue trials per task, with explicit comparison via chi-squared tests). All figures now display error bars and corrected p-values. revision: yes
-
Referee: [Discussion] The weakest assumption—that observed distribution shifts are caused by cue semantics rather than uncontrolled variables in sampling, parsing, or task ambiguity—is not tested. The paper does not report any sensitivity analysis or validation that the family labels are independent of the incidental cue.
Authors: The original manuscript already contains the memoization semantic-vs-surface ablation, which isolates semantics while holding surface form constant. We have added further sensitivity analyses in the revised Discussion: (i) re-running subsets at varied temperatures and top-p values yields stable shifts; (ii) task rephrasings that preserve semantics but alter surface wording produce unchanged family distributions; (iii) an explicit check confirms cue tokens do not alter the AST parser or family-labeling logic. These results support attribution to cue semantics. revision: yes
Circularity Check
No circularity: purely empirical measurement of prompt effects
full rationale
The paper reports results from 46,535 controlled experiments measuring shifts in algorithm-family distributions induced by incidental prompt cues. No equations, fitted models, predictions, or first-principles derivations appear in the provided text; the central claim is an observed empirical pattern across tasks and models. Algorithm-family labeling is a methodological classification step whose consistency is not secured by any self-referential definition or self-citation chain. No load-bearing self-citations, ansatzes, or renamings of known results are present. The work is therefore self-contained against external benchmarks and receives the default non-finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Algorithm families can be reliably and consistently identified from generated code outputs across different tasks
- standard math Statistical significance testing can establish that observed shifts are due to the tested cues
Reference graph
Works this paper leans on
-
[1]
Code2vec: Learning distributed representations of code,
Alon, U., Zilberstein, M., Levy, O., and Yahav, E. code2vec : Learning distributed representations of code. Proceedings of the ACM on Programming Languages, 3 0 (POPL): 0 40:1--40:29, January 2019. doi:10.1145/3290353
-
[2]
Program Synthesis with Large Language Models
Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., and Sutton, C. Program synthesis with large language models, 2021. URL https://arxiv.org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Grounded copilot: How programmers interact with code-generating models,
Barke, S., James, M. B., and Polikarpova, N. Grounded Copilot : How programmers interact with code-generating models. Proceedings of the ACM on Programming Languages, 7 0 (OOPSLA1): 0 85--111, April 2023. doi:10.1145/3586030
-
[4]
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. d. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., Ryder, N., Pavlov, M., Power, A., Kaiser, L., Bavarian, M., Winter, C., Tillet, P., Such, F. P., Cummings, D., Plappert, M., Chantzis...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
N., Li, T., Li, D., Zhu, B., Zhang, H., Jordan, M., Gonzalez, J
Chiang, W.-L., Zheng, L., Sheng, Y., Angelopoulos, A. N., Li, T., Li, D., Zhu, B., Zhang, H., Jordan, M., Gonzalez, J. E., and Stoica, I. Chatbot arena: An open platform for evaluating LLMs by human preference. In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pp.\ 8359--8388. ...
2024
-
[6]
S., Reid, M., Matsuo, Y., and Iwasawa, Y
Kojima, T., Gu, S. S., Reid, M., Matsuo, Y., and Iwasawa, Y. Large language models are zero-shot reasoners. In Advances in Neural Information Processing Systems, volume 35, pp.\ 22199--22213. Curran Associates, Inc., 2022
2022
-
[7]
H., Wang, C., Huang, J.-T., and Lyu, M
Lam, M. H., Wang, C., Huang, J.-T., and Lyu, M. R. CodeCrash : Exposing LLM fragility to misleading natural language in code reasoning. In Advances in Neural Information Processing Systems, volume 38, pp.\ 120782--120828. Curran Associates, Inc., 2025
2025
-
[8]
Lee, S., Chon, H., Jang, J., Lee, D., and Yu, H. How diversely can language models solve problems? exploring the algorithmic diversity of model-generated code. In Findings of the Association for Computational Linguistics: EMNLP 2025, pp.\ 152--167, Suzhou, China, November 2025. Association for Computational Linguistics. doi:10.18653/v1/2025.findings-emnlp.10
-
[9]
S., Wang, Y., and Zhang, L
Liu, J., Xia, C. S., Wang, Y., and Zhang, L. Is your code generated by ChatGPT really correct? rigorous evaluation of large language models for code generation. In Advances in Neural Information Processing Systems, volume 36, pp.\ 21558--21572. Curran Associates, Inc., 2023
2023
-
[10]
Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., and Liang, P. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12: 0 157--173, 2024. doi:10.1162/tacl_a_00638
-
[11]
Mozannar, H., Bansal, G., Fourney, A., and Horvitz, E. Reading between the lines: Modeling user behavior and costs in AI -assisted programming. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI '24). Association for Computing Machinery, 2024. doi:10.1145/3613904.3641936
-
[12]
In-context Learning and Induction Heads
Olsson, C., Elhage, N., Nanda, N., Joseph, N., DasSarma, N., Henighan, T., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., Drain, D., Ganguli, D., Hatfield-Dodds, Z., Hernandez, D., Johnston, S., Jones, A., Kernion, J., Lovitt, L., Ndousse, K., Amodei, D., Brown, T., Clark, J., Kaplan, J., McCandlish, S., and Olah, C. In-context learning and inducti...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Prompting
OpenAI . Prompting. OpenAI API documentation, 2026. URL https://platform.openai.com/docs/guides/prompting
2026
-
[14]
Pearce, H., Ahmad, B., Tan, B., Dolan-Gavitt, B., and Karri, R. Asleep at the keyboard? assessing the security of GitHub Copilot 's code contributions. In 2022 IEEE Symposium on Security and Privacy (SP), pp.\ 754--768. IEEE, 2022. doi:10.1109/SP46214.2022.9833571
-
[15]
Improving reproducibility in machine learning research ( A report from the NeurIPS 2019 reproducibility program)
Pineau, J., Vincent-Lamarre, P., Sinha, K., Larivi \`e re, V., Beygelzimer, A., d'Alch \'e Buc, F., Fox, E., and Larochelle, H. Improving reproducibility in machine learning research ( A report from the NeurIPS 2019 reproducibility program). Journal of Machine Learning Research, 22 0 (164): 0 1--20, 2021
2019
-
[16]
Rice, J. R. The algorithm selection problem. In Advances in Computers, volume 15, pp.\ 65--118. Academic Press, 1976. doi:10.1016/S0065-2458(08)60520-3
-
[17]
Quantifying language models' sensitivity to spurious features in prompt design or: How I learned to start worrying about prompt formatting
Sclar, M., Choi, Y., Tsvetkov, Y., and Suhr, A. Quantifying language models' sensitivity to spurious features in prompt design or: How I learned to start worrying about prompt formatting. In International Conference on Learning Representations, volume 2024, pp.\ 25055--25083, 2024
2024
-
[18]
and Zhang, T
Tian, Y. and Zhang, T. Selective prompt anchoring for code generation. In Proceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Machine Learning Research, pp.\ 59528--59551. PMLR, 2025
2025
-
[19]
ACM Trans Softw Eng Methodol 34(8):225:1--225:53, doi:10.1145/3722108, ://doi.org/10.1145/3722108
Tony, C., D \'i az Ferreyra, N. E., Mutas, M., Dhif, S., and Scandariato, R. Prompting techniques for secure code generation: A systematic investigation. ACM Transactions on Software Engineering and Methodology, 34 0 (8), October 2025. doi:10.1145/3722108
-
[20]
Vaithilingam, P., Zhang, T., and Glassman, E. L. Expectation vs. experience: Evaluating the usability of code generation tools powered by large language models. In Extended Abstracts of the 2022 CHI Conference on Human Factors in Computing Systems (CHI EA '22). Association for Computing Machinery, 2022. doi:10.1145/3491101.3519665
-
[21]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Wallace, E., Xiao, K., Leike, R., Weng, L., Heidecke, J., and Beutel, A. The instruction hierarchy: Training LLMs to prioritize privileged instructions, 2024. URL https://arxiv.org/abs/2404.13208
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Prompt-to-SQL Injections in LLM-Integrated Web Applications: Risks and Defenses ,
Wang, C., Huang, K., Zhang, J., Feng, Y., Zhang, L., Liu, Y., and Peng, X. LLMs meet library evolution: Evaluating deprecated API usage in LLM -based code completion. In Proceedings of the IEEE/ACM 47th International Conference on Software Engineering, pp.\ 885--897. IEEE, 2025. doi:10.1109/ICSE55347.2025.00245
-
[23]
Tree of thoughts: Deliberate problem solving with large language models
Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T., Cao, Y., and Narasimhan, K. Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems, volume 36, pp.\ 11809--11822. Curran Associates, Inc., 2023
2023
-
[24]
Zheng, M., Pei, J., Logeswaran, L., Lee, M., and Jurgens, D. When ``a helpful assistant'' is not really helpful: Personas in system prompts do not improve performances of large language models. In Findings of the Association for Computational Linguistics: EMNLP 2024, pp.\ 15126--15154, Miami, Florida, USA, November 2024. Association for Computational Ling...
-
[25]
and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy , title =
Liu, Nelson F. and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy , title =. Transactions of the Association for Computational Linguistics , volume =. 2024 , publisher =
2024
-
[26]
Proceedings of the IEEE/ACM 47th International Conference on Software Engineering , pages =
Wang, Chong and Huang, Kaifeng and Zhang, Jian and Feng, Yebo and Zhang, Lyuye and Liu, Yang and Peng, Xin , title =. Proceedings of the IEEE/ACM 47th International Conference on Software Engineering , pages =. 2025 , publisher =
2025
-
[27]
International Conference on Learning Representations , volume=
Sclar, Melanie and Choi, Yejin and Tsvetkov, Yulia and Suhr, Alane , title =. International Conference on Learning Representations , volume=
-
[28]
Advances in Neural Information Processing Systems , volume =
Kojima, Takeshi and Gu, Shixiang (Shane) and Reid, Machel and Matsuo, Yutaka and Iwasawa, Yusuke , title =. Advances in Neural Information Processing Systems , volume =. 2022 , publisher =
2022
-
[29]
Advances in Neural Information Processing Systems , volume =
Yao, Shunyu and Yu, Dian and Zhao, Jeffrey and Shafran, Izhak and Griffiths, Tom and Cao, Yuan and Narasimhan, Karthik , title =. Advances in Neural Information Processing Systems , volume =. 2023 , publisher =
2023
-
[30]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Eric Wallace and Kai Xiao and Reimar Leike and Lilian Weng and Johannes Heidecke and Alex Beutel , year =. The Instruction Hierarchy: Training. doi:10.48550/arXiv.2404.13208 , url =. 2404.13208 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.13208
-
[31]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages =
Zheng, Mingqian and Pei, Jiaxin and Logeswaran, Lajanugen and Lee, Moontae and Jurgens, David , title =. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages =. 2024 , month = nov, address =
2024
-
[32]
Chen, Mark and Tworek, Jerry and Jun, Heewoo and Yuan, Qiming and Pinto, Henrique Ponde de Oliveira and Kaplan, Jared and Edwards, Harri and Burda, Yuri and Joseph, Nicholas and Brockman, Greg and Ray, Alex and Puri, Raul and Krueger, Gretchen and Petrov, Michael and Khlaaf, Heidy and Sastry, Girish and Mishkin, Pamela and Chan, Brooke and Gray, Scott and...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.03374 2021
-
[33]
Program Synthesis with Large Language Models
Austin, Jacob and Odena, Augustus and Nye, Maxwell and Bosma, Maarten and Michalewski, Henryk and Dohan, David and Jiang, Ellen and Cai, Carrie and Terry, Michael and Le, Quoc and Sutton, Charles , title =. 2021 , eprint =. doi:10.48550/arXiv.2108.07732 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2108.07732 2021
-
[34]
Proceedings of the 42nd International Conference on Machine Learning , series =
Tian, Yuan and Zhang, Tianyi , title =. Proceedings of the 42nd International Conference on Machine Learning , series =. 2025 , publisher =
2025
-
[35]
Prompting Techniques for Secure Code Generation: A Systematic Investigation , journal =
Tony, Catherine and D. Prompting Techniques for Secure Code Generation: A Systematic Investigation , journal =. 2025 , month = oct, publisher =
2025
-
[36]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages =
Lee, Seonghyeon and Chon, HeeJae and Jang, Joonwon and Lee, Dongha and Yu, Hwanjo , title =. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages =. 2025 , month = nov, address =
2025
-
[37]
, title =
Rice, John R. , title =. Advances in Computers , volume =. 1976 , publisher =
1976
-
[38]
, title =
Vaithilingam, Priyan and Zhang, Tianyi and Glassman, Elena L. , title =. Extended Abstracts of the 2022 CHI Conference on Human Factors in Computing Systems (CHI EA '22) , articleno =. 2022 , publisher =
2022
-
[39]
and Polikarpova, Nadia , title =
Barke, Shraddha and James, Michael B. and Polikarpova, Nadia , title =. Proceedings of the ACM on Programming Languages , volume =. 2023 , month = apr, publisher =
2023
-
[40]
Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI '24) , articleno =
Mozannar, Hussein and Bansal, Gagan and Fourney, Adam and Horvitz, Eric , title =. Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI '24) , articleno =. 2024 , publisher =
2024
-
[41]
Proceedings of the ACM on Programming Languages , volume =
Alon, Uri and Zilberstein, Meital and Levy, Omer and Yahav, Eran , title =. Proceedings of the ACM on Programming Languages , volume =. 2019 , month = jan, publisher =
2019
-
[42]
In-context Learning and Induction Heads
Olsson, Catherine and Elhage, Nelson and Nanda, Neel and Joseph, Nicholas and DasSarma, Nova and Henighan, Tom and Mann, Ben and Askell, Amanda and Bai, Yuntao and Chen, Anna and Conerly, Tom and Drain, Dawn and Ganguli, Deep and Hatfield-Dodds, Zac and Hernandez, Danny and Johnston, Scott and Jones, Andy and Kernion, Jackson and Lovitt, Liane and Ndousse...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2209.11895 2022
-
[43]
2022 IEEE Symposium on Security and Privacy (SP) , pages =
Pearce, Hammond and Ahmad, Baleegh and Tan, Benjamin and Dolan-Gavitt, Brendan and Karri, Ramesh , title =. 2022 IEEE Symposium on Security and Privacy (SP) , pages =. 2022 , publisher =
2022
-
[44]
2026 , url =
Prompting , howpublished =. 2026 , url =
2026
-
[45]
Improving Reproducibility in Machine Learning Research (
Pineau, Joelle and Vincent-Lamarre, Philippe and Sinha, Koustuv and Larivi. Improving Reproducibility in Machine Learning Research (. Journal of Machine Learning Research , volume =
-
[46]
and Stoica, Ion , title =
Chiang, Wei-Lin and Zheng, Lianmin and Sheng, Ying and Angelopoulos, Anastasios Nikolas and Li, Tianle and Li, Dacheng and Zhu, Banghua and Zhang, Hao and Jordan, Michael and Gonzalez, Joseph E. and Stoica, Ion , title =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , publisher =
2024
-
[47]
Advances in Neural Information Processing Systems , volume =
Liu, Jiawei and Xia, Chunqiu Steven and Wang, Yuyao and Zhang, Lingming , title =. Advances in Neural Information Processing Systems , volume =. 2023 , publisher =
2023
-
[48]
, title =
Lam, Man Ho and Wang, Chaozheng and Huang, Jen-Tse and Lyu, Michael R. , title =. Advances in Neural Information Processing Systems , volume =. 2025 , pages=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.