CLAW: Learning Continuous Latent Action World Models via Adversarial Latent Regularization
Pith reviewed 2026-06-28 09:53 UTC · model grok-4.3
The pith
CLAW jointly trains latent action models and world models from action-free videos using adversarial regularization and diffusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By simultaneously training the Latent Action Model and world model, CLAW learns to reason about how inferred actions induce environment transitions from visual observations alone and supports both imitation learning from observation and goal-directed planning.
What carries the argument
Joint optimization of the Latent Action Model via adversarial latent regularization and the diffusion-based world model for video generation.
If this is right
- Latent actions extracted from raw videos enable behavior cloning for imitation learning from observation without action labels.
- Sequences of latent actions can be generated and mapped to executable actions to perform goal-directed planning.
- The approach produces semantically meaningful representations that transfer across tasks and robot embodiments.
- Performance exceeds prior methods on diverse tasks while relying solely on visual observations.
Where Pith is reading between the lines
- Large unlabeled video corpora could now be used directly to bootstrap robotics world models at scale.
- Continuous rather than discrete latent actions may better capture fine-grained dynamics in complex environments.
- The same joint training pattern could be tested on non-robotics domains such as video game agents or simulation environments.
Load-bearing premise
Adversarial latent regularization combined with diffusion-based generation will produce structured, semantically meaningful continuous latent actions that can be reliably mapped to executable actions.
What would settle it
If mapping the learned latent actions to real actions yields no better imitation or planning success rates than existing unsupervised baselines across the paper's evaluation tasks, the central claim would be falsified.
Figures















read the original abstract
We introduce CLAW, a fully end-to-end self-supervised framework for learning a world model jointly with continuous latent action representations directly from action-free videos. Our approach leverages adversarial latent regularization and diffusion-based video generation to capture structured and semantically meaningful action representations while modeling rich, predictive environment dynamics, without relying on any action labels or annotations. By simultaneously training the Latent Action Model and world model, CLAW learns to reason about how inferred actions induce environment transitions from visual observations alone. We show that the resulting latent action world model supports both imitation learning from observation and goal-directed planning. In imitation learning, latent actions extracted from raw videos enable behavior cloning. For planning, CLAW generates sequences of latent actions and maps them to executable actions to reach desired goals. Extensive experiments across diverse tasks and embodiments demonstrate that CLAW produces semantically meaningful latent action representations, supports effective action transfer, and enables planning and imitation from observation, outperforming existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CLAW, an end-to-end self-supervised method that jointly learns a continuous latent action model and a world model directly from action-free videos. It uses adversarial latent regularization together with diffusion-based video generation to produce structured latent actions, enabling both imitation learning from observation (via behavior cloning on extracted latents) and goal-directed planning (by generating and mapping latent action sequences to executable actions). Experiments across multiple tasks and robot embodiments are reported to show semantically meaningful representations, effective action transfer, and superior performance relative to prior methods.
Significance. If the empirical results and the claimed semantic structure of the latent actions hold under scrutiny, the work would be a meaningful contribution to self-supervised world-model learning in robotics. The joint training of latent actions and dynamics without any action supervision, combined with the adversarial-plus-diffusion mechanism for inducing structure, addresses a long-standing bottleneck in imitation-from-observation and model-based planning from raw video. The absence of free parameters or invented entities in the core construction is a strength.
minor comments (3)
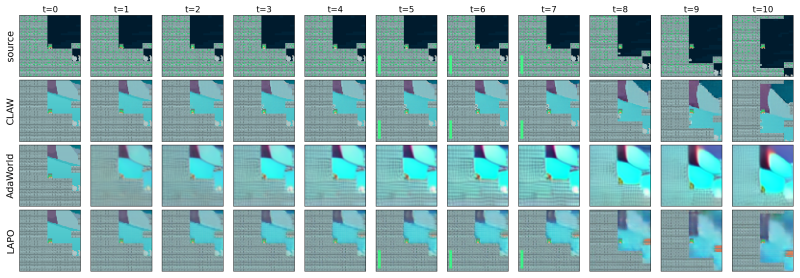
- [§4.2] §4.2 and Figure 4: the qualitative visualization of latent-action trajectories would benefit from an explicit comparison to a non-adversarial ablation (e.g., plain VAE or reconstruction-only baseline) so that the contribution of the adversarial term is visually evident.
- [Table 2] Table 2: success rates are reported without standard deviations or number of seeds; adding these would strengthen the claim that CLAW outperforms the listed baselines.
- [§3.3] §3.3, Eq. (7): the precise form of the diffusion loss and its weighting relative to the adversarial term should be stated explicitly rather than referred to the supplementary material.
Simulated Author's Rebuttal
We thank the referee for the supportive summary, significance assessment, and recommendation of minor revision. No major comments are provided in the report.
Circularity Check
No significant circularity detected
full rationale
The paper describes an end-to-end self-supervised framework that jointly trains a latent action model and world model from action-free videos using adversarial latent regularization and diffusion-based generation. No equations, loss formulations, or derivation steps are provided in the abstract or text that reduce a claimed prediction or result to a fitted parameter or self-referential definition by construction. The central claims rest on the joint training procedure and subsequent empirical validation for imitation and planning tasks rather than any load-bearing self-citation chain, imported uniqueness theorem, or ansatz smuggled via prior work. This is a standard empirical contribution in which the method is presented as independent of the target quantities it is evaluated on.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
D. P. Bertsekas.Dynamic Programming and Optimal Control: V olume I. Athena Scientific, 2012
2012
-
[2]
Tassa, T
Y . Tassa, T. Erez, and E. Todorov. Synthesis and stabilization of complex behaviors through online trajectory optimization. InProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4906–4913, 2012
2012
-
[3]
R. S. Sutton. Integrated architectures for learning, planning, and reacting based on approximating dynamic programming. InMachine Learning Proceedings, pages 216–224. 1990
1990
-
[4]
R. S. Sutton. Dyna, an integrated architecture for learning, planning, and reacting.ACM SIGART Bulletin, 2(4):160–163, 1991
1991
-
[5]
C. G. Atkeson and J. C. Santamar´ıa. A comparison of direct and model-based reinforcement learning. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages 3557–3564, 1997
1997
-
[6]
M. P. Deisenroth and C. E. Rasmussen. PILCO: A model-based and data-efficient approach to policy search. InProceedings of the International Conference on Machine Learning (ICML), 2011
2011
-
[7]
G. A. Miller, G. Eugene, and K. H. Pribram. Plans and the structure of behaviour. InSystems Research for Behavioral Science, pages 369–382. Routledge, 2017
2017
-
[8]
R. C. Conant and W. Ross Ashby. Every good regulator of a system must be a model of that system.International Journal of Systems Science, 1(2):89–97, 1970
1970
-
[9]
Richalet, A
J. Richalet, A. Rault, J.-L. Testud, and J. Papon. Model predictive heuristic control.Automatica, 14(5):413–428, 1978
1978
-
[10]
Lozano-Perez
T. Lozano-Perez. Robot programming.Proceedings of the IEEE, 71(7):821–841, 1983
1983
-
[11]
A. E. Bryson.Applied optimal control: Optimization, estimation and control. Routledge, 2018
2018
-
[12]
A. Clark. Whatever next? Predictive brains, situated agents, and the future of cognitive science. Behavioral and Brain Sciences, 36(3):181–204, 2013
2013
-
[13]
Bubic, D
A. Bubic, D. Y . V on Cramon, and R. I. Schubotz. Prediction, cognition and the brain.Frontiers in Human Neuroscience, 4, 2010
2010
-
[14]
D. Ha and J. Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Learning Latent Dynamics for Planning from Pixels
D. Hafner, T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson. Learning latent dynamics for planning from pixels.arXiv preprint arXiv:1811.04551, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[16]
Hafner, T
D. Hafner, T. P. Lillicrap, J. Ba, and M. Norouzi. Dream to control: Learning behaviors by latent imagination. InProceedings of the International Conference on Learning Representations (ICLR), 2020
2020
-
[17]
Schrittwieser, I
J. Schrittwieser, I. Antonoglou, T. Hubert, K. Simonyan, L. Sifre, S. Schmitt, A. Guez, E. Lock- hart, D. Hassabis, T. Graepel, T. Lillicrap, and D. Silver. Mastering Atari, Go, chess and Shogi by planning with a learned model.Nature, 588(7839):604–609, 2020. ISSN 1476-4687
2020
-
[18]
Mastering Diverse Domains through World Models
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
A. Hu, L. Russell, H. Yeo, Z. Murez, G. Fedoseev, A. Kendall, J. Shotton, and G. Corrado. GAIA-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080, 2023. 9
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [20]
- [21]
-
[22]
Q. Garrido, T. Nagarajan, B. Terver, N. Ballas, Y . LeCun, and M. Rabbat. Learning latent action world models in the wild.arXiv preprint arXiv:2601.05230, 2026
-
[23]
S. Ye, J. Jang, B. Jeon, S. Joo, J. Yang, B. Peng, A. Mandlekar, R. Tan, Y .-W. Chao, B. Y . Lin, L. Liden, K. Lee, J. Gao, L. Zettlemoyer, D. Fox, and M. Seo. Latent action pretraining from videos.arXiv preprint arXiv:2410.11758, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Bruce, M
J. Bruce, M. D. Dennis, A. Edwards, J. Parker-Holder, Y . Shi, E. Hughes, M. Lai, A. Mavalankar, R. Steigerwald, C. Apps, et al. Genie: Generative interactive environments. InProceedings of the International Conference on Machine Learning (ICML), 2024
2024
-
[25]
D. Schmidt and M. Jiang. Learning to act without actions.arXiv preprint arXiv:2312.10812, 2024
- [26]
-
[27]
Zhang, T
C. Zhang, T. Pearce, P. Zhang, K. Wang, X. Chen, W. Shen, L. Zhao, and J. Bian. What do latent action models actually learn? InAdvances in Neural Information Processing Systems (NeurIPS), pages 146676–146697, 2026
2026
-
[28]
J. M. Lee, T. Cho, L. Zhao, and J. Lee. Why latent actions fail, and how to prevent it.arXiv preprint arXiv:2605.20223, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Y . Wang, F. Zhang, D.-C. Zhan, L. Zhao, K. Wang, and J. Bian. Co-evolving latent action world models.arXiv preprint arXiv:2510.26433, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
A. Nikulin, I. Zisman, D. Tarasov, N. Lyubaykin, A. Polubarov, I. Kiselev, and V . Kurenkov. Latent action learning requires supervision in the presence of distractors.arXiv preprint arXiv:2502.00379, 2025
-
[31]
Recent Advances in Imitation Learning from Observation
F. Torabi, G. Warnell, and P. Stone. Recent advances in imitation learning from observation. arXiv preprint arXiv:1905.13566, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[32]
Mendonca, S
R. Mendonca, S. Bahl, and D. Pathak. Structured world models from human videos. In Proceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[33]
Visual Foresight: Model-Based Deep Reinforcement Learning for Vision-Based Robotic Control
F. Ebert, C. Finn, S. Dasari, A. Xie, A. Lee, and S. Levine. Visual foresight: Model-based deep reinforcement learning for vision-based robotic control.arXiv preprint arXiv:1812.00568, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[34]
B. Hou, G. Li, J. Jia, T. An, X. Guo, S. Leng, H. Geng, Y . Ze, T. Harada, P. Torr, O. Mees, M. Pollefeys, Z. Liu, J. Wu, P. Abbeel, J. Malik, Y . Du, and J. Yang. World model for robot learning: A comprehensive survey.arXiv preprint arXiv:2605.00080, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Williams, N
G. Williams, N. Wagener, B. Goldfain, P. Drews, J. M. Rehg, B. Boots, and E. A. Theodorou. Information theoretic MPC for model-based reinforcement learning. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages 1714–1721, 2017
2017
-
[36]
Neural Network Dynamics for Model-Based Deep Reinforcement Learning with Model-Free Fine-Tuning
A. Nagabandi, G. Kahn, R. S. Fearing, and S. Levine. Neural network dynamics for model-based deep reinforcement learning with model-free fine-tuning.arXiv preprint arXiv:1708.02596, 2017. 10
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[37]
Mastering Atari with Discrete World Models
D. Hafner, T. Lillicrap, M. Norouzi, and J. Ba. Mastering Atari with discrete world models. arXiv preprint arXiv:2010.02193, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2010
- [38]
- [39]
-
[40]
V . Micheli, E. Alonso, and F. Fleuret. Transformers are sample-efficient world models.arXiv preprint arXiv:2209.00588, 2023
- [41]
- [42]
-
[43]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, Mojtaba, Komeili, M. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zholus, S. Arnaud, A. Gejji, A. Martin, F. R. Hogan, D. Dugas, P. Bojanowski, V . Khalidov, P. Labatut, F. Massa, M. Szafraniec, K. Krishnakumar, Y . Li, X. Ma, S. Chandar, F. Meier, Y . LeCun, M. Rabbat, and N. Ballas. V-JEPA 2: Self-super...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [44]
-
[45]
G. Zhou, H. Pan, Y . LeCun, and L. Pinto. DINO-WM: World models on pre-trained visual features enable zero-shot planning.arXiv preprint arXiv:2411.04983, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [46]
-
[47]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. UniVLA: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [48]
-
[49]
Cosmos World Foundation Model Platform for Physical AI
NVIDIA, :, N. Agarwal, A. Ali, M. Bala, Y . Balaji, E. Barker, T. Cai, P. Chattopadhyay, Y . Chen, Y . Cui, Y . Ding, D. Dworakowski, J. Fan, M. Fenzi, F. Ferroni, S. Fidler, D. Fox, S. Ge, Y . Ge, J. Gu, S. Gururani, E. He, J. Huang, J. Huffman, P. Jannaty, J. Jin, S. W. Kim, G. Kl´ar, G. Lam, S. Lan, L. Leal-Taixe, A. Li, Z. Li, C.-H. Lin, T.-Y . Lin, H...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [50]
- [51]
-
[52]
Huang, W
Y . Huang, W. Wan, Y . Yang, C. Callison-Burch, M. Yatskar, and L. Liu. CoMO: Controllable motion generation through language guided pose code editing. InProceedings of the European Conference on Computer Vision (ECCV), pages 180–196, 2024. 11
2024
-
[53]
J. Yang, Y . Shi, H. Zhu, M. Liu, K. Ma, Y . Wang, G. Wu, T. He, and L. Wang. CoMo: Learning continuous latent motion from internet videos for scalable robot learning.arXiv preprint arXiv:2505.17006, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success, 2025. URLhttps://arxiv.org/abs/2502.19645
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Lynch, M
C. Lynch, M. Khansari, T. Xiao, V . Kumar, J. Tompson, S. Levine, and P. Sermanet. Learning latent plans from play. InProceedings of the Conference on Robot Learning (CoRL), pages 1113–1132, 2020
2020
-
[57]
Edwards, H
A. Edwards, H. Sahni, Y . Schroecker, and C. Isbell. Imitating latent policies from observation. InProceedings of the International Conference on Machine Learning (ICML), pages 1755–1763, 2019
2019
-
[58]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[59]
F. Bao, S. Nie, K. Xue, Y . Cao, C. Li, H. Su, and J. Zhu. All are worth words: A vit backbone for diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22669–22679, 2023
2023
-
[60]
Ganin, E
Y . Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, M. March, and V . Lempitsky. Domain-adversarial training of neural networks.Journal of Machine Learning Research, 17(59):1–35, 2016
2016
-
[61]
S. Tian, C. Finn, and J. Wu. A control-centric benchmark for video prediction. InProceedings of the International Conference on Learning Representations (ICLR), 2023
2023
-
[62]
Y . Zhu, J. Wong, A. Mandlekar, R. Mart´ın-Mart´ın, A. Joshi, K. Lin, A. Maddukuri, S. Nasiriany, and Y . Zhu. robosuite: A modular simulation framework and benchmark for robot learning. arXiv preprint arXiv:2009.12293, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[63]
Kannan, D
H. Kannan, D. Hafner, C. Finn, and D. Erhan. RoboDesk: A multi-task reinforcement learning benchmark.https://github.com/google-research/robodesk, 2021
2021
-
[64]
S. Park, K. Frans, B. Eysenbach, and S. Levine. Ogbench: Benchmarking offline goal- conditioned rl. InInternational Conference on Learning Representations, volume 2025, pages 94937–94982, 2025
2025
- [65]
- [66]
-
[67]
De Boer, D
P.-T. De Boer, D. P. Kroese, S. Mannor, and R. Y . Rubinstein. A tutorial on the cross-entropy method.Annals of Operations Research, 134(1):19–67, 2005
2005
-
[68]
Goyal, S
R. Goyal, S. Ebrahimi Kahou, V . Michalski, J. Materzynska, S. Westphal, H. Kim, V . Haenel, I. Fruend, P. Yianilos, M. Mueller-Freitag, et al. The” something something” video database for learning and evaluating visual common sense. InProceedings of the IEEE international conference on computer vision, pages 5842–5850, 2017. 12
2017
-
[69]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[70]
H. Kress-Gazit, K. Hashimoto, N. Kuppuswamy, P. Shah, P. Horgan, G. Richardson, S. Feng, and B. Burchfiel. Robot learning as an empirical science: Best practices for policy evaluation. arXiv preprint arXiv:2409.09491, 2024
-
[71]
K. He, X. Chen, S. Xie, Y . Li, P. Doll´ar, and R. Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16000–16009, 2022
2022
-
[72]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016
2016
-
[73]
S. Moon, J. Yeom, B. Park, and H. O. Song. Discovering hierarchical achievements in reinforce- ment learning via contrastive learning. InAdvances in Neural Information Processing Systems (NeurIPS), pages 63674–63686, 2023
2023
-
[74]
Baker, D
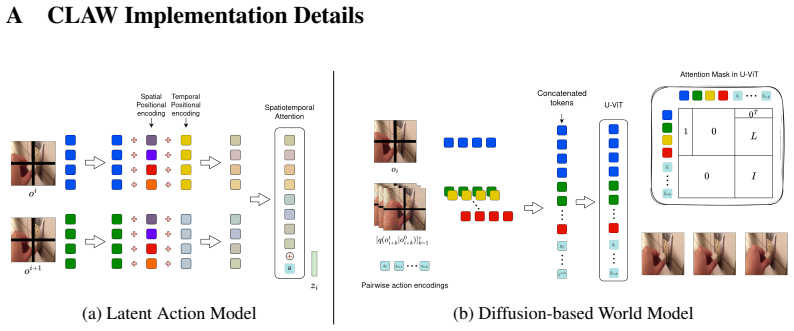
S. Baker, D. Scharstein, J. P. Lewis, S. Roth, M. J. Black, and R. Szeliski. A database and evaluation methodology for optical flow.International journal of computer vision, 92(1):1–31, 2011. 13 A CLA W Implementation Details (a) Latent Action Model (b) Diffusion-based World Model Figure 4: CLAW consists of two main components: a ViT based latent action m...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.