Supportive Token Revealing for Fast Diffusion Language Model Decoding
Pith reviewed 2026-06-28 09:47 UTC · model grok-4.3
The pith
AXON adds a training-free module to diffusion language models that selects supportive confident tokens via attention to ease the quality-latency tradeoff in parallel decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
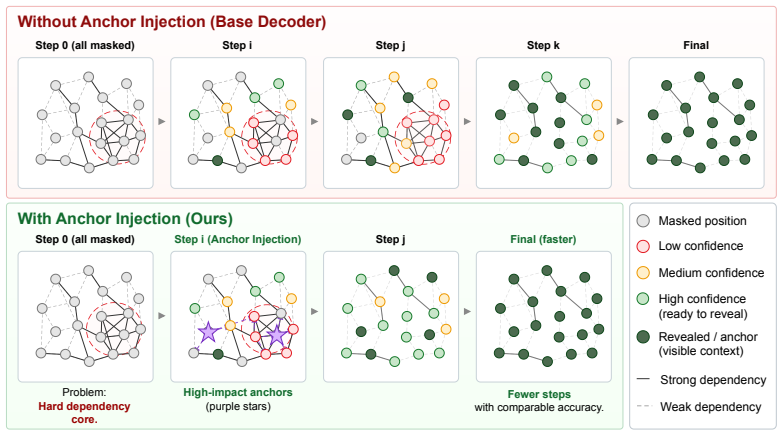
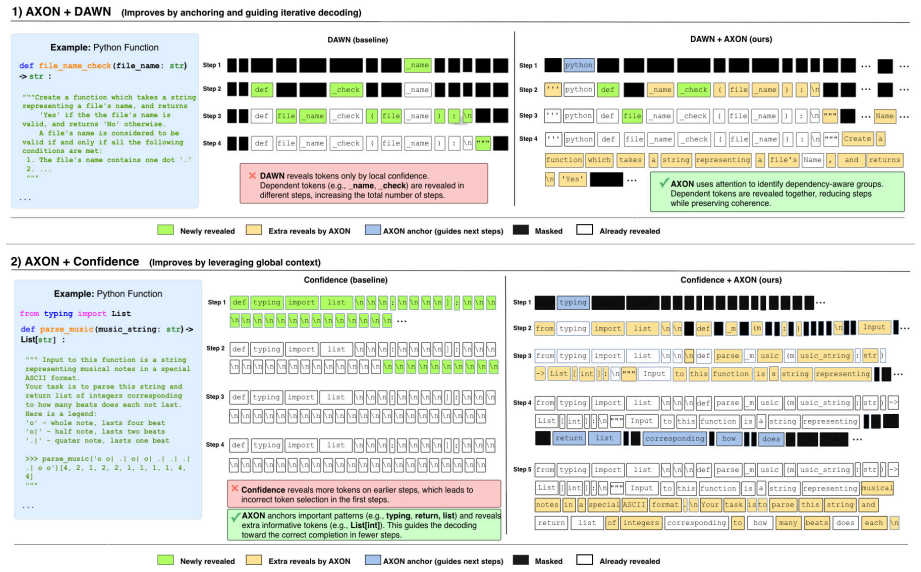
Rather than deciding which tokens are safest to reveal, AXON shifts the criterion to which confident reveals would best support later denoising of uncertain positions. It does so by selecting anchors—confident masked tokens that uncertain positions attend to—using attention, uncertainty, and confidence signals from the base diffusion model, and adds this module on top of existing parallel decoders without training.
What carries the argument
AXON, the training-free module that selects anchors (confident masked tokens attended to by uncertain positions) using attention, uncertainty, and confidence signals.
If this is right
- Existing parallel decoders for diffusion language models can be augmented without retraining to achieve better quality-latency curves.
- The number of denoising function evaluations can often be reduced while maintaining or improving accuracy on reasoning and code tasks.
- The approach applies across multiple diffusion language models without requiring changes to their training.
- Shifting focus from safe token reveals to supportive ones addresses dependency bottlenecks among masked positions.
Where Pith is reading between the lines
- Similar supportive selection logic could be tested in non-diffusion masked generation settings where attention maps are available.
- If attention reliably signals support, one could explore using it for dynamic step-size adjustment rather than fixed reveal schedules.
- The method might interact with different base decoders in ways that amplify gains on tasks with long-range dependencies.
Load-bearing premise
Attention signals from the base diffusion model can reliably identify which confident tokens will provide useful support for later denoising of uncertain positions without the selection process introducing new errors or biases.
What would settle it
Run the same benchmarks with a control version of AXON that selects anchors randomly or by confidence alone instead of attention-weighted support; if the reduction in function evaluations disappears or accuracy drops, the central claim does not hold.
Figures



read the original abstract
Discrete diffusion language models can generate text efficiently by updating multiple masked positions in parallel, but this parallelism introduces a quality-latency trade-off. Aggressive decoding may commit mutually dependent tokens too early, while conservative decoding requires many denoising steps. Existing methods address this tension by deciding which tokens are safe to reveal using confidence or dependency criteria. However, avoiding unsafe commits does not necessarily make the remaining masked sequence easy to decode, since uncertain tokens may depend on masked tokens, creating a bottleneck for denoising steps. We propose AXON, a training-free module that can be added on top of existing parallel decoding strategies for diffusion language models. Rather than replacing the base decoder, AXON monitors the remaining uncertain masked tokens and intervenes only when their current state suggests that additional context is needed. It then shifts the criterion from which tokens are safest to reveal to which confident reveals would best support later denoising. AXON selects anchors, confident masked tokens that uncertain positions attend to, using attention, uncertainty, and confidence signals. Experiments on reasoning and code-generation benchmarks across multiple diffusion language models show that AXON improves the quality-latency trade-off of existing parallel decoders, often reducing the number of function evaluations while maintaining or improving accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AXON, a training-free module added atop existing parallel decoders for discrete diffusion language models. AXON monitors uncertain masked tokens and selects 'anchor' tokens—confident positions attended to by uncertain ones—using the base model's attention map together with uncertainty and confidence signals. The central claim is that these supportive reveals break mutual-dependency bottlenecks, yielding a better quality-latency trade-off: experiments across reasoning and code-generation benchmarks on multiple diffusion LMs show reduced function evaluations while maintaining or improving accuracy.
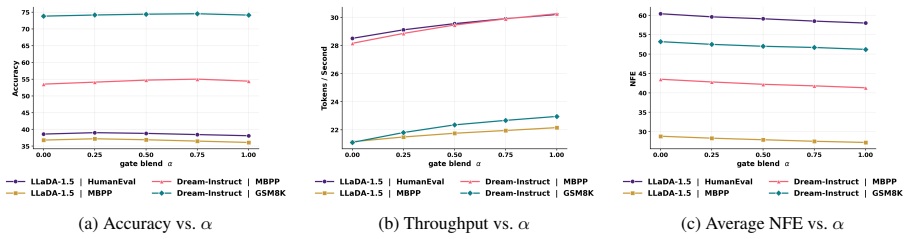
Significance. If the reported gains prove robust, AXON supplies a lightweight, plug-in improvement to parallel diffusion decoding that directly targets the remaining masked-token dependency problem without retraining or new parameters. This could be practically useful for efficiency-sensitive generation tasks where existing confidence- or dependency-based heuristics fall short.
major comments (2)
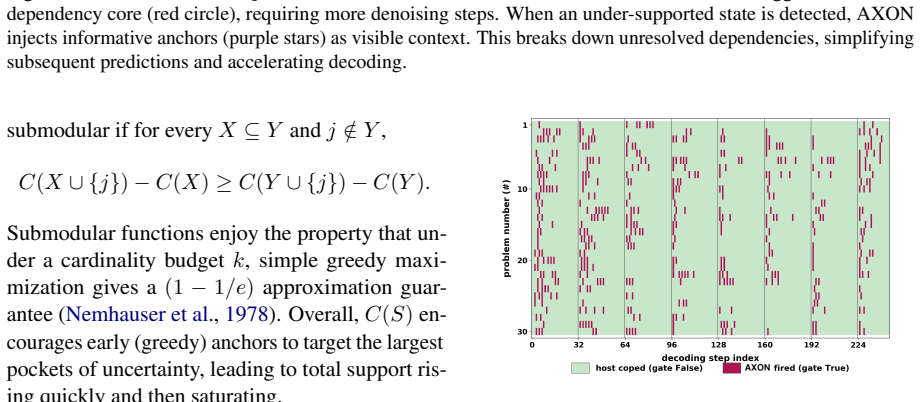
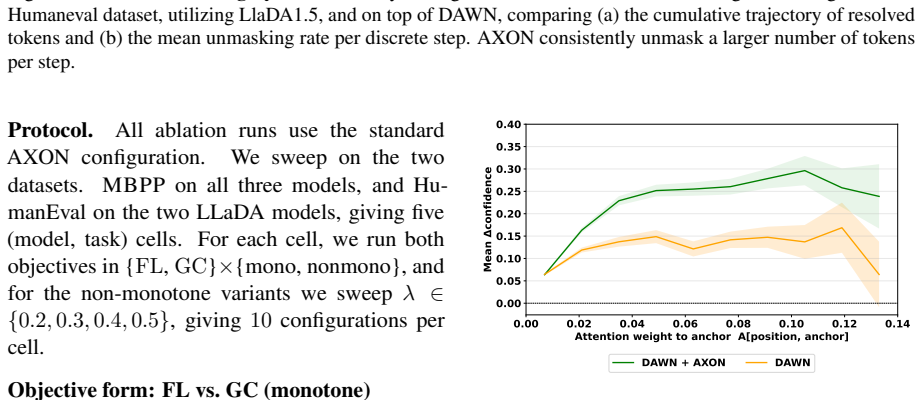
- [§3.2] §3.2 (AXON selection rule): the core hypothesis that attention weights from uncertain positions identify tokens whose early reveal measurably reduces later denoising difficulty is stated but not derived or tested; no ablation compares attention-guided anchors against confidence-only or random selection on the same uncertain set, leaving open whether the attention signal is load-bearing or incidental.
- [§4] §4 (experimental results): the abstract and results claim 'often reducing the number of function evaluations while maintaining or improving accuracy,' yet no quantitative tables, baseline numbers, variance estimates, or statistical tests are referenced in the provided description; without these, the magnitude and reliability of the quality-latency improvement cannot be assessed.
minor comments (2)
- [§3.1] Notation for the anchor selection criterion (attention × confidence product) should be given an explicit equation number and contrasted with the base decoder's own reveal rule.
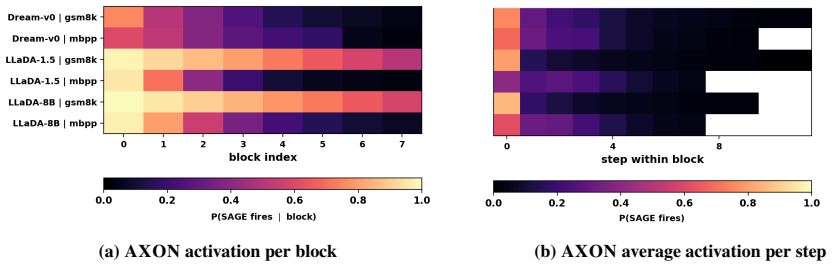
- [§3.3] The manuscript should clarify whether AXON is invoked at every denoising step or only when a threshold on uncertain tokens is crossed; the current description leaves the intervention schedule ambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the claims and presentation.
read point-by-point responses
-
Referee: [§3.2] §3.2 (AXON selection rule): the core hypothesis that attention weights from uncertain positions identify tokens whose early reveal measurably reduces later denoising difficulty is stated but not derived or tested; no ablation compares attention-guided anchors against confidence-only or random selection on the same uncertain set, leaving open whether the attention signal is load-bearing or incidental.
Authors: The AXON design selects anchors using attention from uncertain tokens to confident positions, motivated by the goal of providing supportive context to resolve dependency bottlenecks in parallel decoding. While the manuscript does not include a formal derivation, the rule is directly derived from the base model's attention maps combined with uncertainty and confidence signals. We agree that an explicit ablation is needed to isolate the contribution of attention. In the revision we will add an ablation comparing attention-guided selection against random and confidence-only selection on identical uncertain token sets. revision: yes
-
Referee: [§4] §4 (experimental results): the abstract and results claim 'often reducing the number of function evaluations while maintaining or improving accuracy,' yet no quantitative tables, baseline numbers, variance estimates, or statistical tests are referenced in the provided description; without these, the magnitude and reliability of the quality-latency improvement cannot be assessed.
Authors: Section 4 reports quantitative results across reasoning and code-generation benchmarks on multiple diffusion LMs, with tables comparing function evaluations and accuracy for baselines versus AXON. To improve clarity we will revise the section to explicitly reference the tables, add variance estimates across runs, and include statistical significance tests for the reported improvements. revision: yes
Circularity Check
No circularity; training-free heuristic on base-model signals with no self-referential reductions.
full rationale
The paper describes AXON as a training-free module added atop existing parallel decoders, selecting anchors solely via attention, uncertainty, and confidence signals already produced by the base diffusion model. No equations, fitted parameters, or derivations appear that reduce the selection criterion to its own outputs by construction. The quality-latency claim rests on end-to-end benchmark results rather than any load-bearing self-citation chain or ansatz smuggled from prior author work. This is a self-contained empirical intervention with no detectable circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
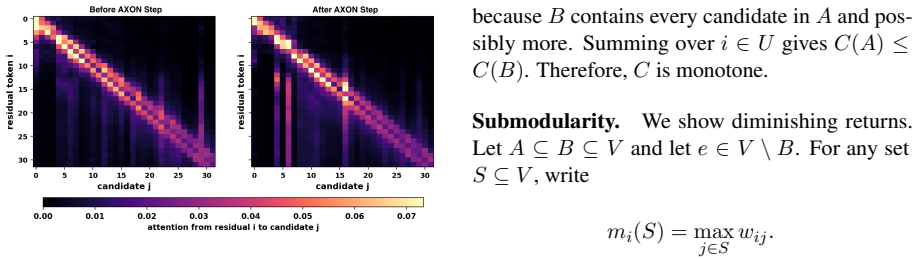
- domain assumption Transformer attention weights reflect token dependencies usable for selecting supportive anchors
invented entities (1)
-
AXON module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg
Spiffy: Multiplying diffusion llm accelera- tion via lossless speculative decoding.arXiv preprint arXiv:2509.18085. Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. 2021a. Structured denoising diffusion models in discrete state-spaces. Advances in neural information processing systems, 34:17981–17993. Jacob Austin, Augu...
Pith/arXiv arXiv 2026
-
[2]
Guided combinatorial algorithms for submodu- lar maximization.arXiv preprint arXiv:2405.05202. Yuxin Chen and Andreas Krause. 2013. Near-optimal batch mode active learning and adaptive submodular optimization. InInternational Conference on Ma- chine Learning, pages 160–168. PMLR. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukas...
arXiv 2013
-
[3]
Bumjun Kim, Dongjae Jeon, Moongyu Jeon, and Al- bert No
Accelerating diffusion llms via adaptive par- allel decoding.Advances in neural information pro- cessing systems, 38:52870–52888. Bumjun Kim, Dongjae Jeon, Moongyu Jeon, and Al- bert No. 2026a. Dependency-aware parallel decod- ing via attention for diffusion llms.arXiv preprint arXiv:2603.12996. Seo Hyun Kim, Sunwoo Hong, Hojung Jung, Youngrok Park, and S...
Pith/arXiv arXiv 2025
-
[4]
InInternational Conference on Machine Learning, pages 19274–19286
Fast inference from transformers via spec- ulative decoding. InInternational Conference on Machine Learning, pages 19274–19286. PMLR. Xiang Li, John Thickstun, Ishaan Gulrajani, Percy S Liang, and Tatsunori B Hashimoto. 2022. Diffusion- lm improves controllable text generation.Advances in neural information processing systems, 35:4328– 4343. Aaron Lou, Ch...
arXiv 2022
-
[5]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, and 1 others
d3llm: Ultra-fast diffusion llm using pseudo-trajectory distillation.arXiv preprint arXiv:2601.07568. Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, and 1 others. 2019. Language models are unsupervised multitask learn- ers.OpenAI blog, 1(8):9. Liran Ringel, Ameen Ali, and Yaniv Romano
arXiv 2019
-
[6]
Dependency-guided parallel decoding in dis- crete diffusion language models.arXiv preprint arXiv:2604.02560. Subham S Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexan- der Rush, and V olodymyr Kuleshov. 2024. Simple and effective masked diffusion language models.Ad- vances in Neural Information Processing System...
Pith/arXiv arXiv 2024
-
[7]
In Advances in Neural Information Processing Systems
Practical 0.385-approximation for submodular maximization subject to a cardinality constraint. In Advances in Neural Information Processing Systems. NeurIPS 2024. Xinyun Wang, Min Zhang, Sen Cui, Zhikang Chen, Bo Jiang, Kun Kuang, and Mingbao Lin. 2026. Re- versible diffusion decoding for diffusion language models.arXiv preprint arXiv:2602.00150. Qingyan ...
arXiv 2024
-
[8]
arXiv preprint arXiv:2508.15487
Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487. Shaorong Zhang, Longxuan Yu, Rob Brekelmans, Luhan Tang, Salman Asif, and Greg Ver Steeg. 2026. Generation order and parallel decoding in masked dif- fusion models: An information-theoretic perspective. arXiv preprint arXiv:2602.00286. Lifeng Zhou and Pratap Tokekar. 2022. Risk-aw...
Pith/arXiv arXiv 2026
-
[9]
re-masks suspicious commits to make ag- gressive drafts less risky, while RDD (Wang et al.,
-
[10]
DCD (Shu et al., 2026) replaces rigid block boundaries with a confidence-aware sliding window
rolls back previous blocks when the current block stalls. DCD (Shu et al., 2026) replaces rigid block boundaries with a confidence-aware sliding window. SlowFast (Wei et al., 2025) alternates between an exploratory stage that identifies stable high-confidence spans and an accelerated stage that decodes them in parallel. Each controls the risk, consequence...
2026
-
[11]
accepts many drafted reveals in parallel un- der a lossless distribution-preserving test. This is orthogonal to the commit-selection problem we address: systems methods make individual steps cheaper, while AXON changes the commit mask when the host decoder’s own rule leaves the resid- ual under-covered. The two compose, so we treat system acceleration as ...
2024
-
[12]
Coverage form.Facility-location (FL) C(t) FL(S) = P i∈U maxj∈S w(t) ij , in which each uncertain position draws its cover- age from the best-matching anchors within the selected set S, versus Graph-Cut (GC) C(t) GC(S) = P i∈U P j∈S w(t) ij , which instead sums each position’s affinity over all selected anchors
-
[13]
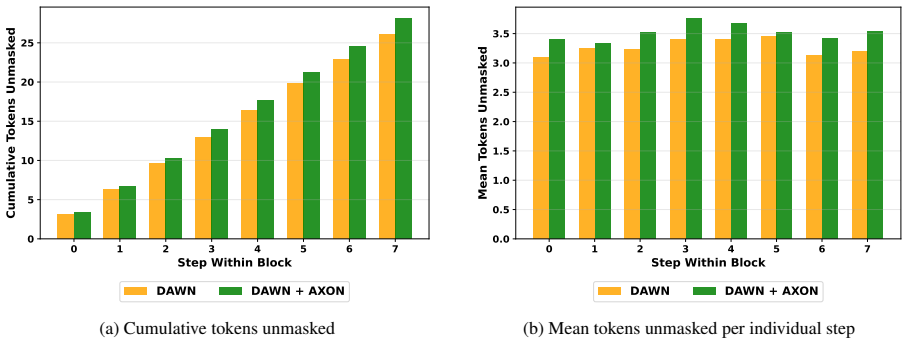
Monotonicity.The monotone objective Fmono(S) =C (t)(S) versus the non- monotone Fnonmono(S) =C (t)(S)−λ R(S) , where R(S) =P {j,k}⊆S qjk is a pairwise re- dundancy/conflict penalty over the selected set and its weight,λ≥0. 0 1 2 3 4 5 6 7 Step Within Block 0 5 10 15 20 25Cumulative Tokens Unmasked DAWN DAWN + AXON (a) Cumulative tokens unmasked 0 1 2 3 4 ...
2026
-
[14]
Following (Zhou et al., 2026), we assume that the model pθ is parametrized by a single layer transformer
2026
-
[15]
Under these assumptions, we can prove that, δi ≤βA is,(7) for a positive constantβ >0
We assume that the attention mapAdoes not change after revealing position s (similar to (Zhou et al., 2026) Assumption 3.1). Under these assumptions, we can prove that, δi ≤βA is,(7) for a positive constantβ >0. Discussion of bound.The upper bound in (7) motivates our use of attention as a measure for an- chor usefulness, and the inclusion of Aij in the s...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.