LazyAttention: Efficient Retrieval-Augmented Generation with Deferred Positional Encoding
Pith reviewed 2026-06-28 07:02 UTC · model grok-4.3
The pith
LazyAttention defers positional encoding inside attention kernels to enable zero-copy KV cache reuse at arbitrary positions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
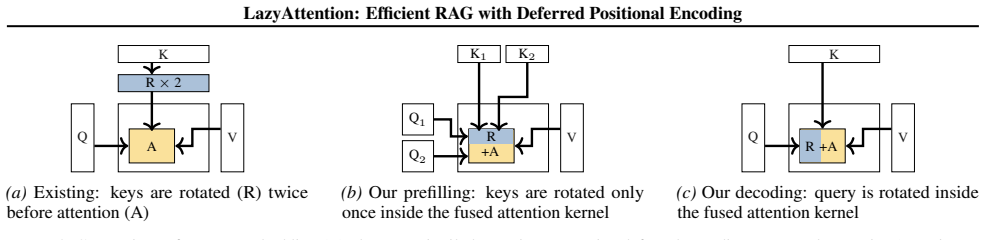
We introduce LazyAttention, a novel attention mechanism that kernelizes deferred positional encoding to enable zero-copy, position-agnostic KV reuse. By adjusting positional encoding within attention kernels on-the-fly, LazyAttention resolves the materialization bottleneck, allowing a single physical KV copy to serve multiple logical requests at arbitrary positions. Leveraging attention kernels tailored for prefilling and decoding, our system achieves significant efficiency improvements under skewed document distributions while maintaining comparable output quality.
What carries the argument
On-the-fly positional adjustment inside attention kernels that defers encoding until query time
If this is right
- A single physical KV copy can serve multiple logical requests at arbitrary positions without duplication.
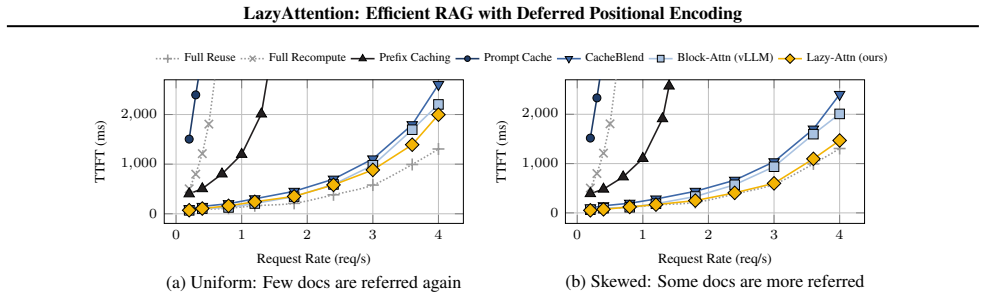
- TTFT drops by 1.37 times under skewed document distributions compared with Block-Attention.
- Inference throughput rises by 1.40 times while output quality stays comparable.
- Separate kernels for prefilling and decoding become practical because position handling is no longer tied to cache storage.
Where Pith is reading between the lines
- The same deferred-encoding pattern could be applied to other transformer layers that currently bake positional or segment information into stored activations.
- Multi-tenant serving systems could maintain far fewer distinct KV buffers when users request overlapping retrieved contexts at different offsets.
- If the kernel overhead remains low, the technique may extend to streaming or continuously updated retrieval settings where document order changes frequently.
Load-bearing premise
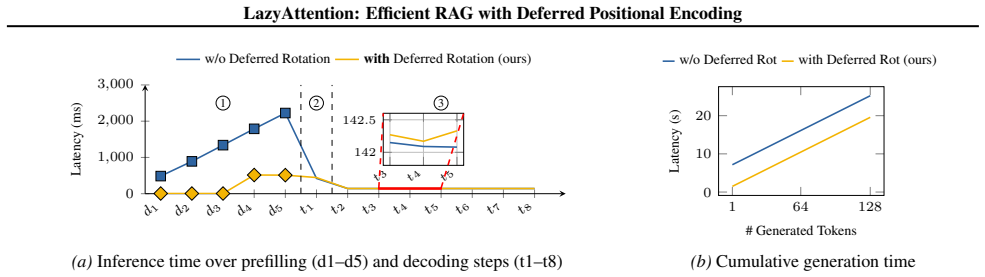
On-the-fly positional adjustment inside attention kernels adds negligible compute and leaves attention accuracy and numerical stability unchanged.
What would settle it
Run the same attention operation on identical KV pairs once with standard pre-materialized positional encodings and once with LazyAttention's on-the-fly adjustment, then compare both wall-clock time and output distribution divergence.
Figures


read the original abstract
Key-value (KV) caching accelerates inference of large language models (LLMs) by reusing past computations for generated tokens. Its importance becomes even greater in long-context applications such as retrieval-augmented generation (RAG) and in-context learning (ICL). However, conventional KV caching embeds positional information directly into the cache, limiting its reusability. Existing solutions either restrict reuse to prefixes or require expensive memory materialization for positional re-encoding. We introduce LazyAttention, a novel attention mechanism that kernelizes deferred positional encoding to enable zero-copy, position-agnostic KV reuse. By adjusting positional encoding within attention kernels on-the-fly, LazyAttention resolves the materialization bottleneck, allowing a single physical KV copy to serve multiple logical requests at arbitrary positions. Leveraging attention kernels tailored for prefilling and decoding, our system achieves significant efficiency improvements: under skewed document distributions, it reduces time-to-first-token (TTFT) by 1.37$\times$ and increases inference throughput by 1.40$\times$ compared to the state-of-the-art Block-Attention, while maintaining comparable output quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LazyAttention, a novel attention mechanism that kernelizes deferred positional encoding (e.g., via on-the-fly RoPE-style rotations) to enable zero-copy, position-agnostic reuse of a single physical KV cache across multiple logical requests at arbitrary positions. This is claimed to resolve the materialization bottleneck in conventional KV caching for RAG and ICL. The system reports 1.37× lower TTFT and 1.40× higher inference throughput versus Block-Attention under skewed document distributions, with comparable output quality, using tailored kernels for prefilling and decoding.
Significance. If the on-the-fly adjustment proves to incur negligible extra compute while preserving attention scores and numerical stability, the result would meaningfully advance efficient long-context inference by increasing KV-cache reusability without additional memory materialization. The empirical speedups, if reproducible with full experimental details, would represent a practical improvement over existing prefix-restricted or materialization-heavy baselines.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the reported 1.37× TTFT and 1.40× throughput gains are presented without baseline implementation details, error bars, hardware specifications, or ablation isolating the cost of on-the-fly positional adjustment versus pre-materialized encoding. This information is load-bearing for verifying whether the claimed gains over Block-Attention are supported or whether hidden kernel overheads offset them.
- [§3] §3 (LazyAttention Mechanism): the central claim that deferred positional encoding can be applied inside fused attention kernels at query time for arbitrary logical positions while adding only negligible FLOPs and preserving scores to within floating-point tolerance lacks a derivation, kernel pseudocode, or complexity analysis. Without this, it is impossible to confirm that the adjustment does not require per-token rotations or extra matrix multiplies that would shrink the reported efficiency gains.
minor comments (2)
- [§3] Notation for the deferred encoding operator and its integration with existing attention kernels (e.g., FlashAttention) should be defined more explicitly to aid reproducibility.
- [§3] The manuscript should include a clear statement of the exact RoPE (or equivalent) rotation formula used for on-the-fly adjustment and any assumptions about rotary embedding dimensions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the reproducibility and clarity of the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the reported 1.37× TTFT and 1.40× throughput gains are presented without baseline implementation details, error bars, hardware specifications, or ablation isolating the cost of on-the-fly positional adjustment versus pre-materialized encoding. This information is load-bearing for verifying whether the claimed gains over Block-Attention are supported or whether hidden kernel overheads offset them.
Authors: We agree these details are required for verification. In the revised manuscript we will expand §4 with hardware specifications (NVIDIA H100 GPUs), error bars from five independent runs, full baseline implementation details for Block-Attention, and a dedicated ablation that isolates the incremental FLOPs and latency of the on-the-fly positional adjustment versus pre-materialized RoPE. This will confirm the reported speedups are not offset by hidden overhead. revision: yes
-
Referee: [§3] §3 (LazyAttention Mechanism): the central claim that deferred positional encoding can be applied inside fused attention kernels at query time for arbitrary logical positions while adding only negligible FLOPs and preserving scores to within floating-point tolerance lacks a derivation, kernel pseudocode, or complexity analysis. Without this, it is impossible to confirm that the adjustment does not require per-token rotations or extra matrix multiplies that would shrink the reported efficiency gains.
Authors: We will revise §3 to include a concise derivation demonstrating equivalence to standard RoPE, kernel pseudocode for the fused prefilling and decoding kernels, and a complexity analysis showing the adjustment requires only O(d) additional operations per token (d = head dimension) with no extra matrix multiplies. The analysis will also confirm numerical stability within floating-point tolerance. revision: yes
Circularity Check
No circularity: empirical claims rest on kernel mechanism, not self-referential definitions or fitted predictions.
full rationale
The paper presents LazyAttention as an engineering innovation that kernelizes deferred positional encoding for zero-copy KV reuse. The abstract and description frame the TTFT/throughput gains as outcomes of on-the-fly adjustment inside attention kernels, without equations, parameter fits to data subsets, or self-citations that reduce the central claim to a tautology or renamed input. No load-bearing step equates a 'prediction' to its own construction; the derivation chain is self-contained as a proposed systems technique evaluated empirically against Block-Attention.
Axiom & Free-Parameter Ledger
invented entities (1)
-
LazyAttention mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , pages=
Large-scale Evaluation of Notebook Checkpointing with AI Agents , author=. Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , pages=
-
[2]
arXiv preprint arXiv:2507.05403 , year=
PBE Meets LLM: When Few Examples Aren't Few-Shot Enough , author=. arXiv preprint arXiv:2507.05403 , year=
-
[3]
2025 , url=
Junhao Hu and Wenrui Huang and Weidong Wang and Haoyi Wang and tiancheng hu and zhang qin and Hao Feng and Xusheng Chen and Yizhou Shan and Tao Xie , booktitle=. 2025 , url=
2025
-
[4]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[5]
T urbo RAG : Accelerating Retrieval-Augmented Generation with Precomputed KV Caches for Chunked Text
Lu, Songshuo and Wang, Hua and Rong, Yutian and Chen, Zhi and Tang, Yaohua. T urbo RAG : Accelerating Retrieval-Augmented Generation with Precomputed KV Caches for Chunked Text. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.334
-
[6]
InfiniGen: Efficient Generative Inference of Large Language Models with Dynamic
Wonbeom Lee and Jungi Lee and Junghwan Seo and Jaewoong Sim , editor =. InfiniGen: Efficient Generative Inference of Large Language Models with Dynamic. 18th. 2024 , url =
2024
-
[7]
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention , booktitle =
Jingyang Yuan and Huazuo Gao and Damai Dai and Junyu Luo and Liang Zhao and Zhengyan Zhang and Zhenda Xie and Yuxing Wei and Lean Wang and Zhiping Xiao and Yuqing Wang and Chong Ruan and Ming Zhang and Wenfeng Liang and Wangding Zeng , editor =. Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention , booktitle =. 2025 , url =
2025
-
[8]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[9]
Advances in Neural Information Processing Systems , volume=
Minicache: Kv cache compression in depth dimension for large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Model Tells You What to Discard: Adaptive
Suyu Ge and Yunan Zhang and Liyuan Liu and Minjia Zhang and Jiawei Han and Jianfeng Gao , booktitle=. Model Tells You What to Discard: Adaptive. 2024 , url=
2024
-
[11]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv e-prints , keywords =. doi:10.48550/arXiv.2403.05530 , archivePrefix =. 2403.05530 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.05530
-
[12]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[13]
16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22) , pages=
Orca: A distributed serving system for \ Transformer-Based \ generative models , author=. 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22) , pages=
-
[14]
Forty-first International Conference on Machine Learning,
Thomas Merth and Qichen Fu and Mohammad Rastegari and Mahyar Najibi , title =. Forty-first International Conference on Machine Learning,. 2024 , url =
2024
-
[15]
Prompt Cache: Modular Attention Reuse for Low-Latency Inference , booktitle =
In Gim and Guojun Chen and Seung. Prompt Cache: Modular Attention Reuse for Low-Latency Inference , booktitle =. 2024 , url =
2024
-
[16]
Proceedings of the Nineteenth European Conference on Computer Systems, EuroSys 2025, Rotterdam, March 30 - April 3, 2025 , publisher =
Jiayi Yao and Hanchen Li and Yuhan Liu and Siddhant Ray and Yihua Cheng and Qizheng Zhang and Kuntai Du and Shan Lu and Junchen Jiang , title =. Proceedings of the Nineteenth European Conference on Computer Systems, EuroSys 2025, Rotterdam, March 30 - April 3, 2025 , publisher =. 2025 , timestamp =
2025
-
[17]
OpenAI , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2303.08774 , eprinttype =. 2303.08774 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[18]
Chao Jin and Zili Zhang and Xuanlin Jiang and Fangyue Liu and Xin Liu and Xuanzhe Liu and Xin Jin , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2404.12457 , eprinttype =. 2404.12457 , timestamp =
-
[19]
Manning , title =
Parth Sarthi and Salman Abdullah and Aditi Tuli and Shubh Khanna and Anna Goldie and Christopher D. Manning , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[20]
Wikipedia (en) embedded with cohere.ai multilingual22-12 encoder , year =
-
[21]
The Thirteenth International Conference on Learning Representations , year=
Block-Attention for Efficient Prefilling , author=. The Thirteenth International Conference on Learning Representations , year=
-
[22]
2024 , note =
LangChain , howpublished =. 2024 , note =
2024
-
[23]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , booktitle =
Patrick Lewis and Ethan Perez and Aleksandra Piktus and Fabio Petroni and Vladimir Karpukhin and Naman Goyal and Heinrich K. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , booktitle =
-
[24]
23rd USENIX Conference on File and Storage Technologies (FAST 25) , year =
Ruoyu Qin and Zheming Li and Weiran He and Jialei Cui and Feng Ren and Mingxing Zhang and Yongwei Wu and Weimin Zheng and Xinran Xu , title =. 23rd USENIX Conference on File and Storage Technologies (FAST 25) , year =
-
[25]
and Zhang, Hao and Stoica, Ion , booktitle =
Woosuk Kwon and Zhuohan Li and Siyuan Zhuang and Ying Sheng and Lianmin Zheng and Cody Hao Yu and Joseph Gonzalez and Hao Zhang and Ion Stoica , editor =. Efficient Memory Management for Large Language Model Serving with PagedAttention , booktitle =. 2023 , url =. doi:10.1145/3600006.3613165 , timestamp =
-
[26]
Shapley Value Approximation Based on Complementary Contribution , year=
Sun, Qiheng and Zhang, Jiayao and Liu, Jinfei and Xiong, Li and Pei, Jian and Ren, Kui , journal=. Shapley Value Approximation Based on Complementary Contribution , year=
-
[27]
Thirty-seventh Conference on Neural Information Processing Systems , year=
H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[28]
The Twelfth International Conference on Learning Representations , year=
Efficient Streaming Language Models with Attention Sinks , author=. The Twelfth International Conference on Learning Representations , year=
-
[29]
Yuhong Li and Yingbing Huang and Bowen Yang and Bharat Venkitesh and Acyr Locatelli and Hanchen Ye and Tianle Cai and Patrick Lewis and Deming Chen , booktitle=. Snap. 2024 , url=
2024
-
[30]
2024 , eprint=
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling , author=. 2024 , eprint=
2024
-
[31]
2025 , eprint=
Ada-KV: Optimizing KV Cache Eviction by Adaptive Budget Allocation for Efficient LLM Inference , author=. 2025 , eprint=
2025
-
[32]
Not All Heads Matter: A Head-Level
Yu Fu and Zefan Cai and Abedelkadir Asi and Wayne Xiong and Yue Dong and Wen Xiao , booktitle=. Not All Heads Matter: A Head-Level. 2025 , url=
2025
-
[33]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[34]
2024 , eprint=
The Llama 3 Herd of Models , author =. 2024 , eprint=
2024
-
[35]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[36]
2024 , howpublished =
Anthropic , title =. 2024 , howpublished =
2024
-
[37]
Zhang, Jiayao and Sun, Qiheng and Liu, Jinfei and Xiong, Li and Pei, Jian and Ren, Kui , title =. Proc. ACM Manag. Data , month = may, articleno =. 2023 , issue_date =. doi:10.1145/3588728 , abstract =
-
[38]
Bai, Yushi and Lv, Xin and Zhang, Jiajie and Lyu, Hongchang and Tang, Jiankai and Huang, Zhidian and Du, Zhengxiao and Liu, Xiao and Zeng, Aohan and Hou, Lei and Dong, Yuxiao and Tang, Jie and Li, Juanzi. L ong B ench: A Bilingual, Multitask Benchmark for Long Context Understanding. Proceedings of the 62nd Annual Meeting of the Association for Computation...
-
[39]
Contribution to the Theory of Games , volume=
A value for n-person games , author=. Contribution to the Theory of Games , volume=
-
[40]
Scissorhands: Exploiting the Persistence of Importance Hypothesis for
Zichang Liu and Aditya Desai and Fangshuo Liao and Weitao Wang and Victor Xie and Zhaozhuo Xu and Anastasios Kyrillidis and Anshumali Shrivastava , booktitle=. Scissorhands: Exploiting the Persistence of Importance Hypothesis for. 2023 , url=
2023
-
[41]
RazorAttention: Efficient
Hanlin Tang and Yang Lin and Jing Lin and Qingsen Han and Shikuan Hong and Danning Ke and Yiwu Yao and Gongyi Wang , booktitle=. RazorAttention: Efficient. 2025 , url=
2025
-
[42]
DuoAttention: Efficient Long-Context
Guangxuan Xiao and Jiaming Tang and Jingwei Zuo and junxian guo and Shang Yang and Haotian Tang and Yao Fu and Song Han , booktitle=. DuoAttention: Efficient Long-Context. 2025 , url=
2025
-
[43]
The Thirteenth International Conference on Learning Representations , year=
Retrieval Head Mechanistically Explains Long-Context Factuality , author=. The Thirteenth International Conference on Learning Representations , year=
-
[44]
2019 , eprint=
Fast Transformer Decoding: One Write-Head is All You Need , author=. 2019 , eprint=
2019
-
[45]
FlashAttention: Fast and Memory-Efficient Exact Attention with
Tri Dao and Daniel Y Fu and Stefano Ermon and Atri Rudra and Christopher Re , booktitle=. FlashAttention: Fast and Memory-Efficient Exact Attention with. 2022 , url=
2022
-
[46]
Proceedings of the 29th Symposium on Operating Systems Principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th Symposium on Operating Systems Principles , pages=
-
[47]
A Unified Approach to Interpreting Model Predictions , url =
Lundberg, Scott M and Lee, Su-In , booktitle =. A Unified Approach to Interpreting Model Predictions , url =
-
[48]
Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics , pages =
Towards Efficient Data Valuation Based on the Shapley Value , author =. Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics , pages =. 2019 , editor =
2019
-
[49]
Journal of Machine Learning Research , year =
Rory Mitchell and Joshua Cooper and Eibe Frank and Geoffrey Holmes , title =. Journal of Machine Learning Research , year =
-
[50]
Xiaotie Deng and Christos H. Papadimitriou , title =. Math. Oper. Res. , volume =. 1994 , url =. doi:10.1287/MOOR.19.2.257 , timestamp =
-
[51]
Benchmarking Retrieval-Augmented Generation for Medicine
Xiong, Guangzhi and Jin, Qiao and Lu, Zhiyong and Zhang, Aidong. Benchmarking Retrieval-Augmented Generation for Medicine. Findings of the Association for Computational Linguistics ACL 2024. 2024
2024
-
[52]
Kalra, Rishi and Wu, Zekun and Gulley, Ayesha and Hilliard, Airlie and Guan, Xin and Koshiyama, Adriano and Treleaven, Philip Colin. H y PA - RAG : A Hybrid Parameter Adaptive Retrieval-Augmented Generation System for AI Legal and Policy Applications. Proceedings of the 1st Workshop on Customizable NLP: Progress and Challenges in Customizing NLP for a Dom...
-
[53]
Cell , volume=
Empowering biomedical discovery with AI agents , author=. Cell , volume=. 2024 , publisher=
2024
-
[54]
2024 USENIX Annual Technical Conference (USENIX ATC 24) , year =
Bin Gao and Zhuomin He and Puru Sharma and Qingxuan Kang and Djordje Jevdjic and Junbo Deng and Xingkun Yang and Zhou Yu and Pengfei Zuo , title =. 2024 USENIX Annual Technical Conference (USENIX ATC 24) , year =
2024
-
[55]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Fast Attention Over Long Sequences With Dynamic Sparse Flash Attention , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[56]
Retrieval Augmented Language Model Pre-Training , booktitle =
Kelvin Guu and Kenton Lee and Zora Tung and Panupong Pasupat and Ming. Retrieval Augmented Language Model Pre-Training , booktitle =. 2020 , url =
2020
-
[57]
Companion Proceedings of the
Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks , author=. Companion Proceedings of the. 2025 , timestamp =
2025
-
[58]
Retrieval-based Language Models and Applications , booktitle =
Akari Asai and Sewon Min and Zexuan Zhong and Danqi Chen , editor =. Retrieval-based Language Models and Applications , booktitle =. 2023 , url =. doi:10.18653/V1/2023.ACL-TUTORIALS.6 , timestamp =
-
[59]
Ori Ram and Yoav Levine and Itay Dalmedigos and Dor Muhlgay and Amnon Shashua and Kevin Leyton. In-Context Retrieval-Augmented Language Models , journal =. 2023 , url =. doi:10.1162/TACL\_A\_00605 , timestamp =
work page internal anchor Pith review doi:10.1162/tacl 2023
-
[60]
The Twelfth International Conference on Learning Representations,
Tri Dao , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[61]
Hao Che and Ye Tung and Zhijun Wang , title =. 2002 , url =. doi:10.1109/JSAC.2002.801752 , timestamp =
-
[62]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert and Jacob Morrison and Valentina Pyatkin and Shengyi Huang and Hamish Ivison and Faeze Brahman and Lester James V. Miranda and Alisa Liu and Nouha Dziri and Shane Lyu and Yuling Gu and Saumya Malik and Victoria Graf and Jena D. Hwang and Jiangjiang Yang and Ronan Le Bras and Oyvind Tafjord and Chris Wilhelm and Luca Soldaini and Noah A. Smi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.15124 2024
-
[63]
2022 , url=
NVIDIA Hopper Architecture In-Depth , author=. 2022 , url=
2022
-
[64]
Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps
Ho, Xanh and Duong Nguyen, Anh-Khoa and Sugawara, Saku and Aizawa, Akiko. Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps. Proceedings of the 28th International Conference on Computational Linguistics. 2020
2020
-
[65]
Sentence-BERT: Sentence embeddings using siamese BERT- networks
Reimers, Nils and Gurevych, Iryna. Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1410
-
[66]
2025 , eprint=
DeepSeek-V3 Technical Report , author=. 2025 , eprint=
2025
-
[67]
Fanxu Meng and Pingzhi Tang and Zengwei Yao and Xing Sun and Muhan Zhang , booktitle=. Trans. 2025 , url=
2025
-
[68]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek. DeepSeek-V2:. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2405.04434 , eprinttype =. 2405.04434 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.04434 2024
-
[69]
Ermo Hua and Che Jiang and Xingtai Lv and Kaiyan Zhang and Ning Ding and Youbang Sun and Biqing Qi and Yuchen Fan and Xuekai Zhu and Bowen Zhou , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2412.17739 , eprinttype =. 2412.17739 , timestamp =
-
[70]
Emily M. Bender and Timnit Gebru and Angelina McMillan. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? , booktitle =. 2021 , url =. doi:10.1145/3442188.3445922 , timestamp =
-
[71]
Ethical and social risks of harm from Language Models , journal =
Laura Weidinger and John Mellor and Maribeth Rauh and Conor Griffin and Jonathan Uesato and Po. Ethical and social risks of harm from Language Models , journal =. 2021 , url =. 2112.04359 , timestamp =
Pith/arXiv arXiv 2021
-
[72]
8th International Conference on Learning Representations,
Nikita Kitaev and Lukasz Kaiser and Anselm Levskaya , title =. 8th International Conference on Learning Representations,. 2020 , url =
2020
-
[73]
♫ M u S i Q ue: Multihop Questions via Single-hop Question Composition
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish. M u S i Q ue: Multihop Questions via Single-hop Question Composition. Transactions of the Association for Computational Linguistics. 2022. doi:10.1162/tacl_a_00475
-
[74]
Bogdan Gliwa and Iwona Mochol and Maciej Biesek and Aleksander Wawer , title =. CoRR , volume =. 2019 , url =. 1911.12237 , timestamp =
arXiv 2019
-
[75]
Multi-News: A Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model
Fabbri, Alexander and Li, Irene and She, Tianwei and Li, Suyi and Radev, Dragomir. Multi-News: A Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1102
-
[76]
Weld and Luke Zettlemoyer , editor =
Mandar Joshi and Eunsol Choi and Daniel S. Weld and Luke Zettlemoyer , editor =. TriviaQA:. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics,. 2017 , url =. doi:10.18653/V1/P17-1147 , timestamp =
-
[77]
The N arrative QA Reading Comprehension Challenge
Ko c isk \'y , Tom \'a s and Schwarz, Jonathan and Blunsom, Phil and Dyer, Chris and Hermann, Karl Moritz and Melis, G \'a bor and Grefenstette, Edward. The N arrative QA Reading Comprehension Challenge. Transactions of the Association for Computational Linguistics. 2018. doi:10.1162/tacl_a_00023
-
[78]
H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1259
-
[79]
Learning Dense Representations of Phrases at Scale , booktitle =
Jinhyuk Lee and Mujeen Sung and Jaewoo Kang and Danqi Chen , editor =. Learning Dense Representations of Phrases at Scale , booktitle =. 2021 , url =. doi:10.18653/V1/2021.ACL-LONG.518 , timestamp =
-
[80]
Gautier Izacard and Edouard Grave , editor =. Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering , booktitle =. 2021 , url =. doi:10.18653/V1/2021.EACL-MAIN.74 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.